诊断性能
内容
诊断性能¶
理解分布式计算的性能可能很困难。这在一定程度上是由于影响性能的分布式计算机的许多组件:
计算时间
内存带宽
网络带宽
磁盘带宽
调度器开销
序列化成本
这种困难因这些成本信息分散在多台机器中而加剧,因此没有中心位置来收集数据以识别性能问题。
幸运的是,Dask 在执行过程中收集了各种诊断信息。它这样做既是为了向用户提供性能反馈,也是为了其自身的内部调度决策。观察这些反馈的主要地方是诊断仪表板。本文档描述了可用的各种性能信息以及如何访问它们。
任务开始和结束时间¶
工作者捕获与任务相关的时间。对于每个通过工作者的任务,我们记录以下各项的开始和停止时间:
序列化 (灰色)
从对等节点(红色)收集依赖项
收集本地数据的磁盘I/O(橙色)
执行时间(按任务着色)
观察这些时间的主要方式是通过调度器的 /status 页面上的任务流图,其中条形的颜色对应于上面列出的颜色。
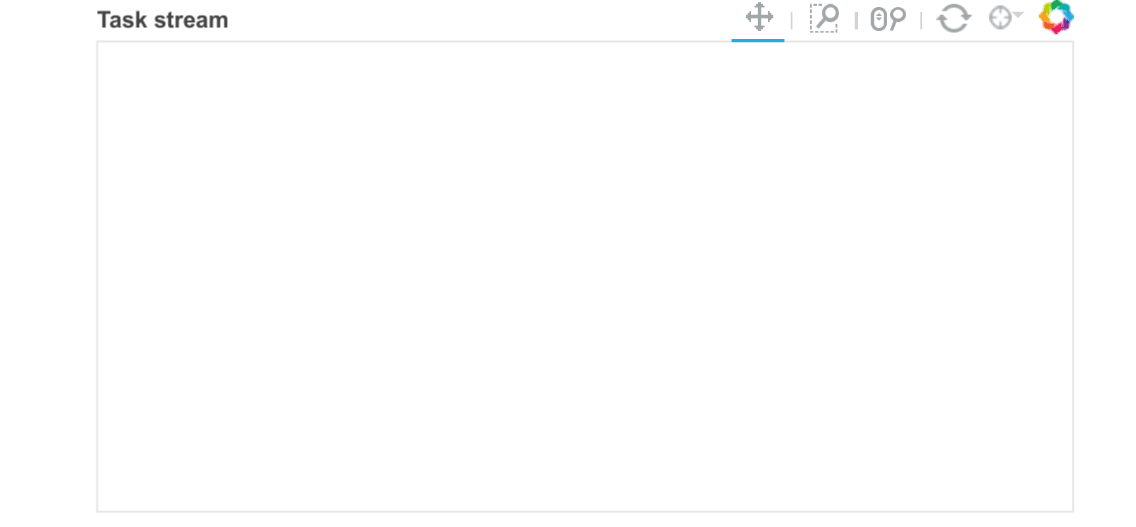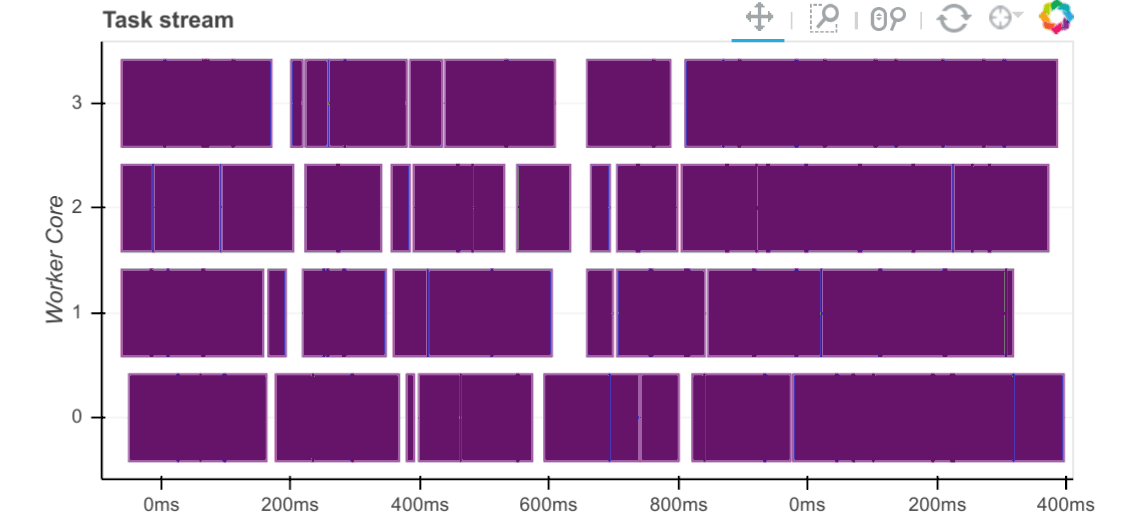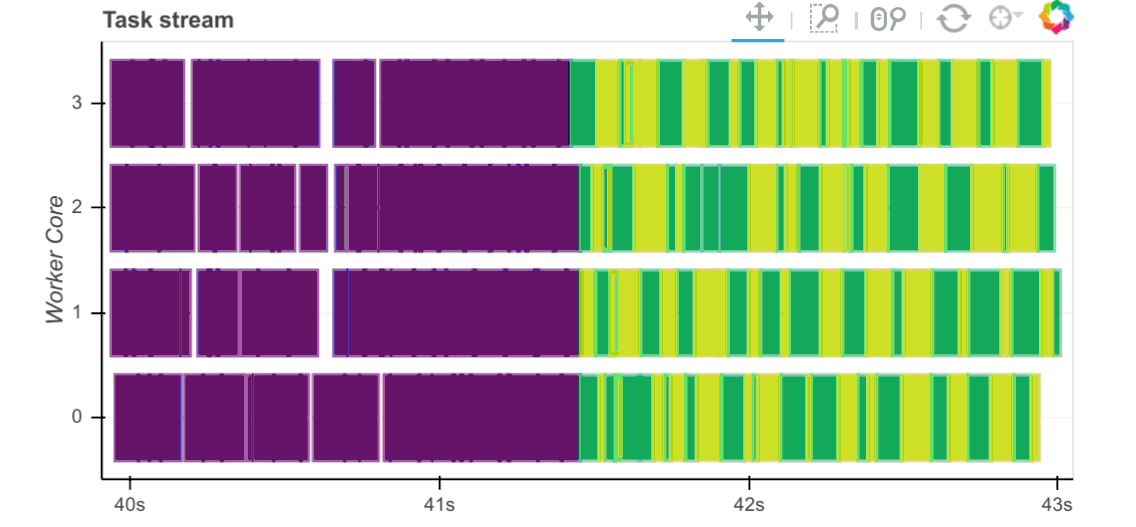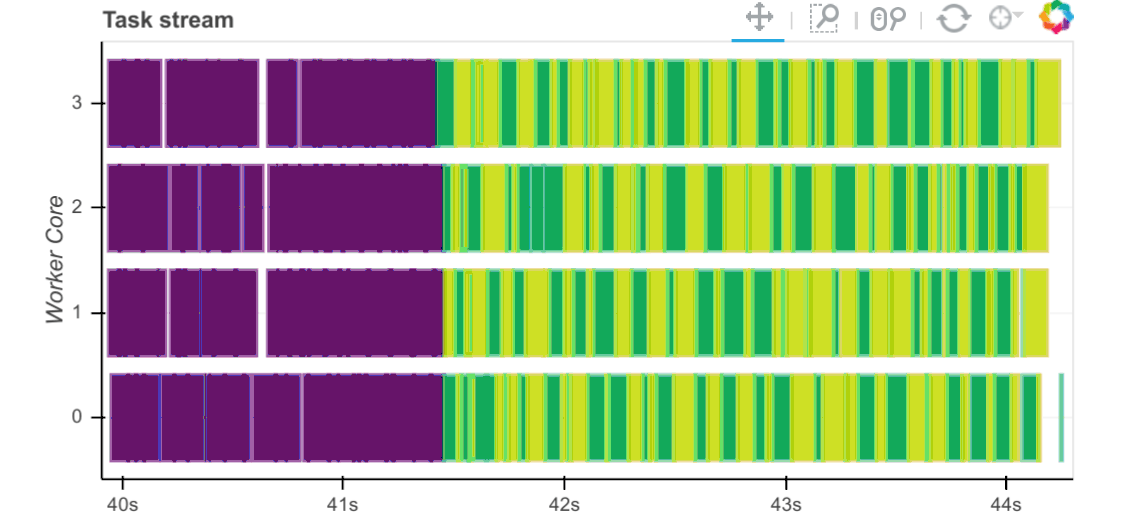
或者,如果你想对每个任务事件进行自己的诊断,你可能需要创建一个 调度器插件 。当任务从处理状态转换到内存或出错时,所有这些信息都将可用。
统计分析¶
对于单线程性能分析,Python 用户通常依赖标准库中的 CProfile 模块(Dask 开发者推荐使用 snakeviz 工具进行单线程性能分析)。不幸的是,标准的 CProfile 模块不适用于多线程或分布式计算。
为了解决这个问题,Dask 实现了自己的分布式 统计分析器。每 10 毫秒,每个工作进程检查其每个工作线程正在执行的操作。它捕获调用栈并将此栈添加到计数数据结构中。此计数数据结构每秒记录并清除一次,以便建立一段时间内的性能记录。
用户通常通过工作节点或调度器诊断仪表板上的 /profile 图表来观察这些数据。在调度器页面上,他们观察所有工作节点上所有线程的总聚合配置文件。点击配置文件中的任何条形图,用户可以放大该部分,这与大多数分析工具的典型操作一致。页面底部有一个时间线,允许用户选择不同的时间段。
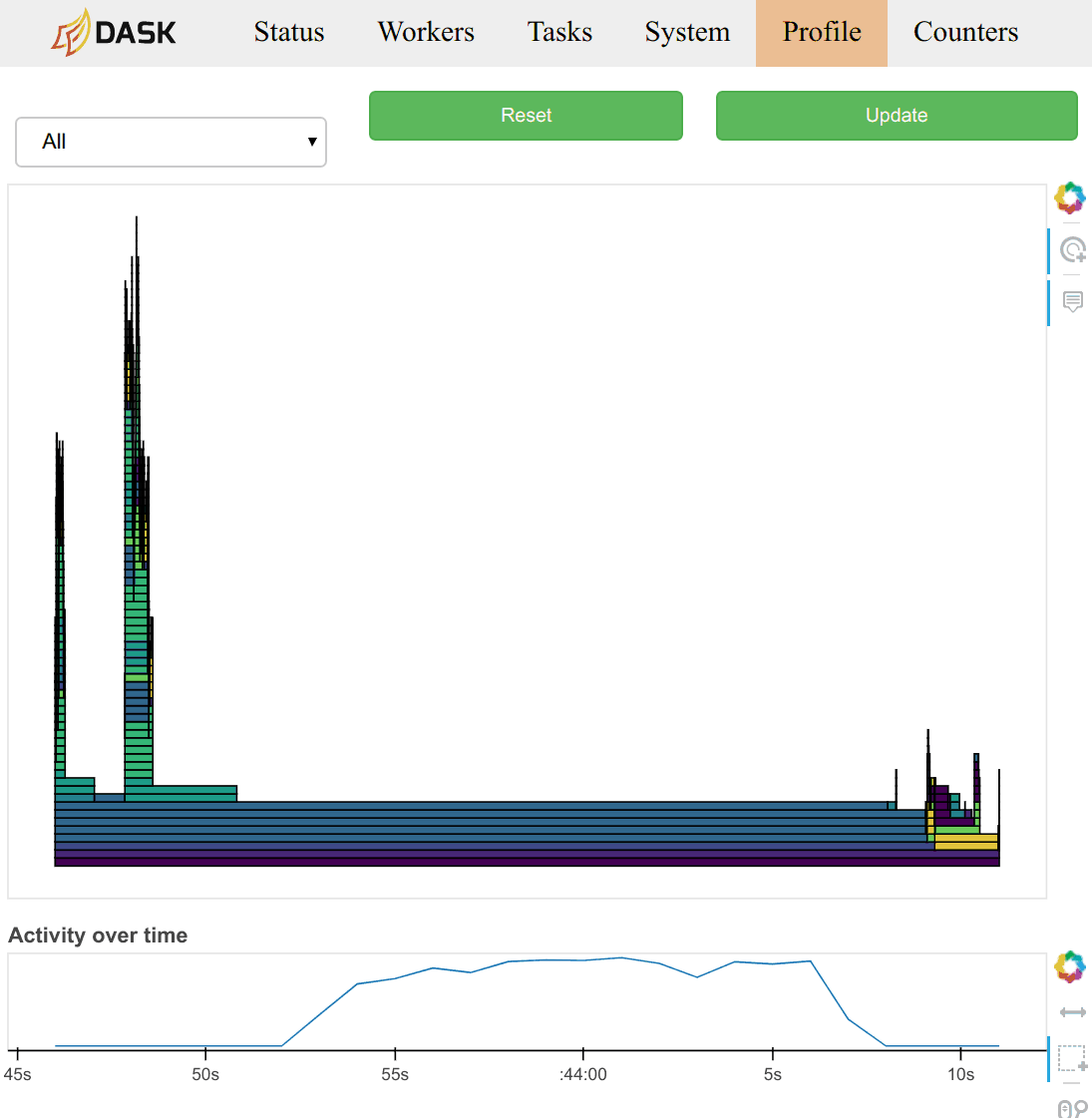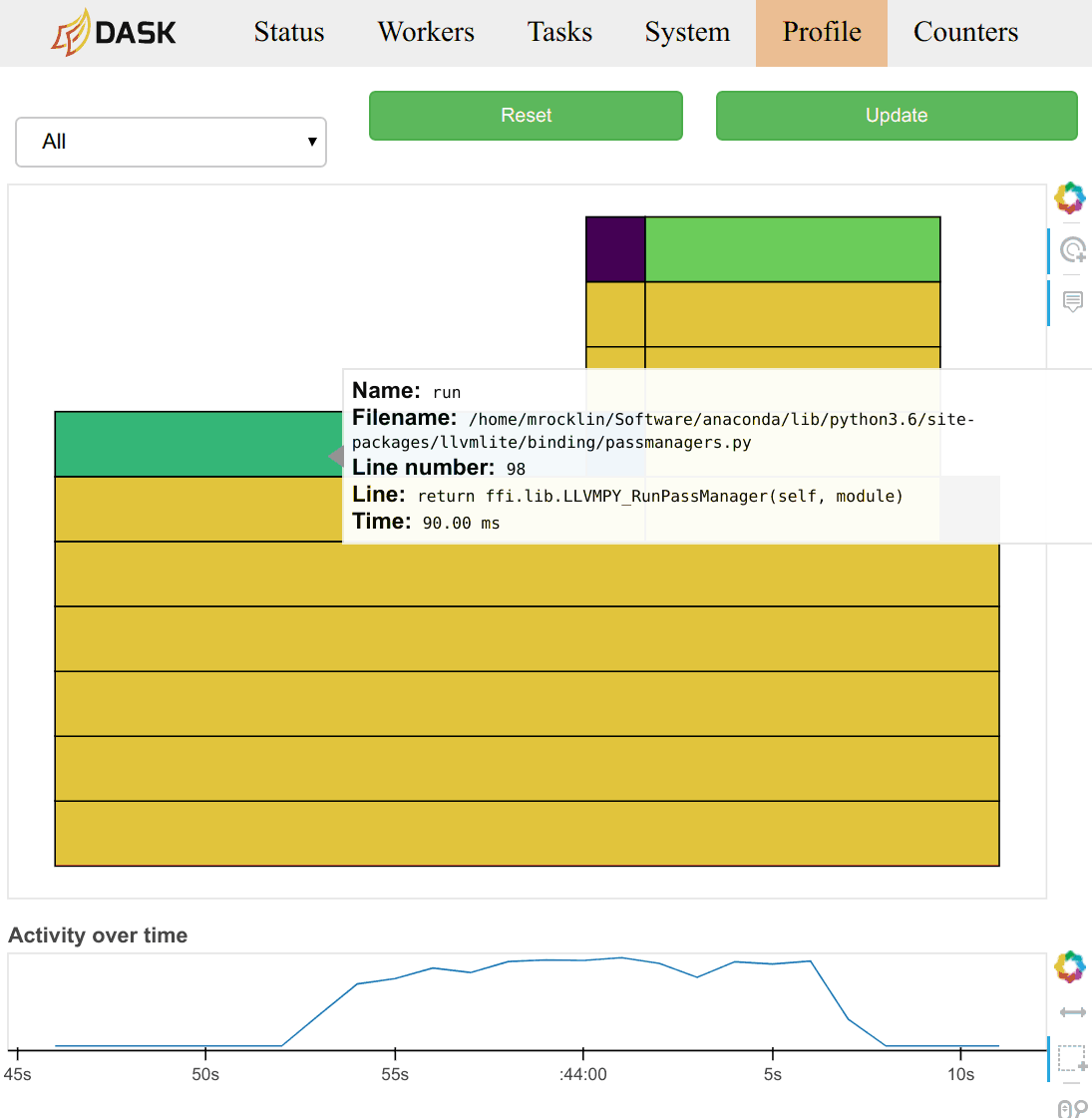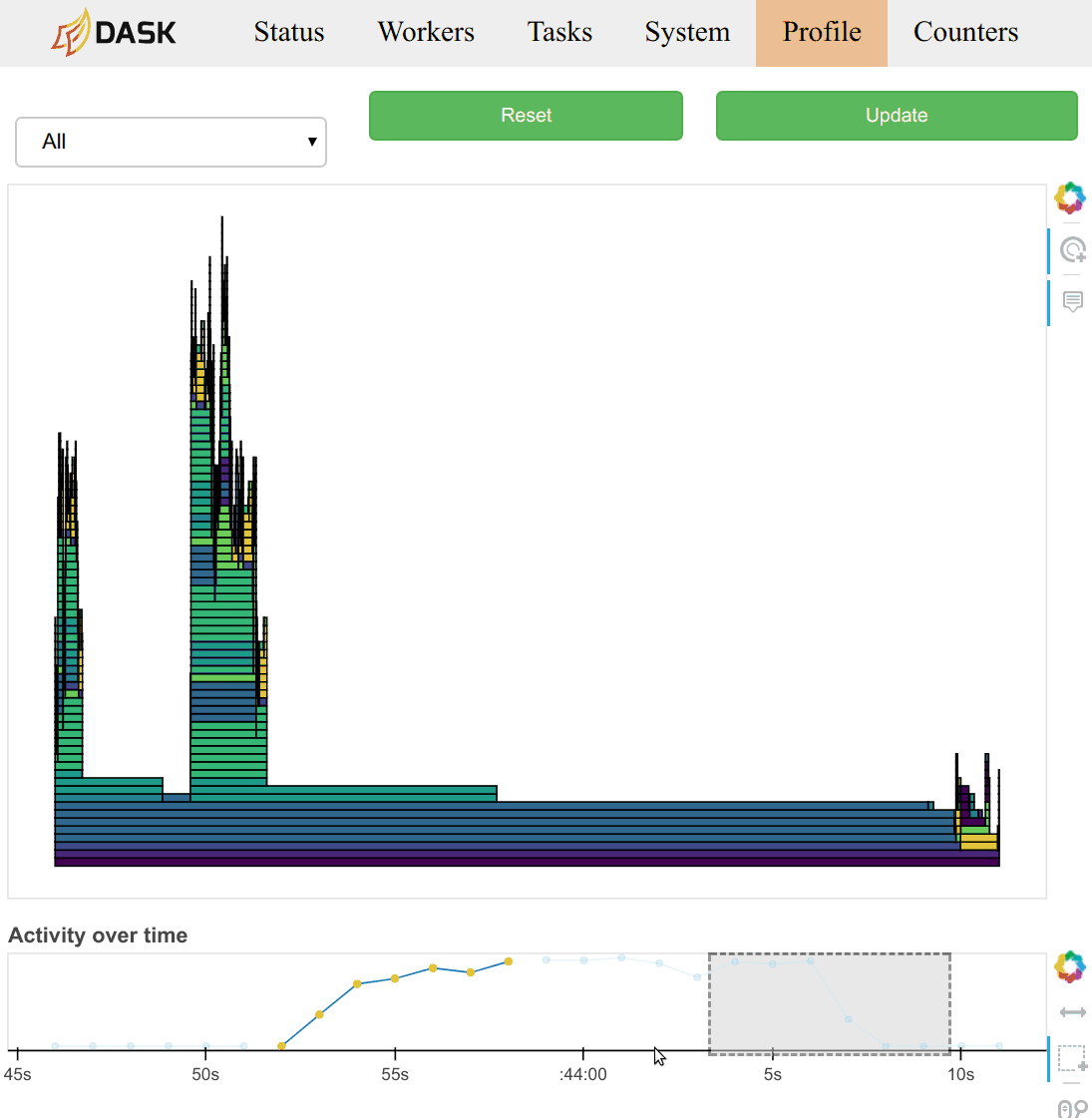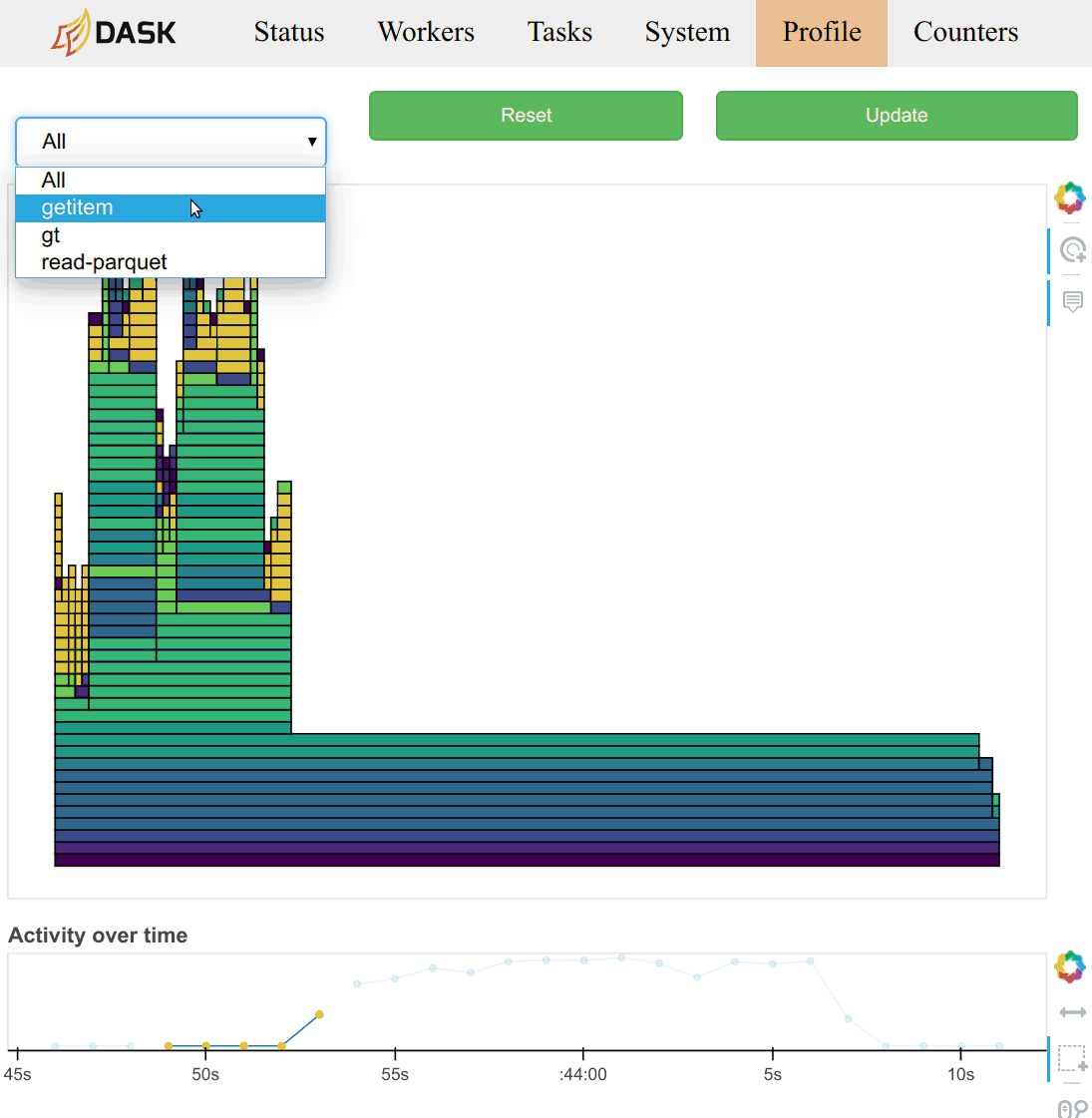
配置文件也按当时正在运行的任务进行分组。您可以从页面顶部的选择菜单中选择一个任务名称。您还可以点击 /status 页面上主任务流图中对应于任务的矩形。
用户也可以使用 Client.profile 函数直接查询这些数据。这将提供用于生成这些图表的原始数据结构。他们还可以传递一个文件名,直接将图表保存为HTML文件。请注意,这个文件需要从类似 python -m http.server 的网络服务器上提供才能可见。
10ms 和 1s 参数可以通过 config.yaml 文件中的 profile-interval 和 profile-cycle-interval 条目进行控制。
带宽¶
Dask workers 在 Worker.transfer_outgoing_log 和 Worker.transfer_incoming_log 属性中记录每一次传入和传出的传输,包括
传输的总字节数
压缩字节传输
开始/停止时间
键已移动
同行
这些信息通过 Worker 诊断仪表盘的 /status 页面提供给用户。你可以通过在 workers 上运行命令来明确捕获它们的状态:
client.run(lambda dask_worker: dask_worker.transfer_outgoing_log)
client.run(lambda dask_worker: dask_worker.transfer_incoming_log)
性能报告¶
在基准测试和/或性能分析时,用户可能希望记录特定的计算甚至整个工作流程。Dask可以将bokeh仪表板保存为包含任务流、工作线程配置文件、带宽等的静态HTML图。这是通过使用 distributed.performance_report 上下文管理器包装计算来完成的:
from dask.distributed import performance_report
with performance_report(filename="dask-report.html"):
## some dask computation
以下视频更详细地演示了 performance_report 上下文管理器:
关于时间的一点说明¶
不同的计算机维护着不同的时钟,这些时钟可能不完全匹配。为了解决这个问题,Dask调度器在每次响应工作节点的心跳时发送其当前时间。工作节点将其本地时间与此时间进行比较,以获得差异的估计。工作节点记录的所有时间都考虑了这种估计的延迟。这有所帮助,但仍然可能存在不精确的测量。
所有时间都是从调度器的角度出发的。
分析内存使用随时间的变化¶
您可能想知道随着计算的进行,集群范围内的内存使用情况如何随时间变化,或者同一算法的两种不同实现方式在内存使用方面有何比较。
这是通过使用 distributed.diagnostics.MemorySampler 上下文管理器包装一个计算来完成的:
from distributed import Client
from distributed.diagnostics import MemorySampler
client = Client(...)
ms = MemorySampler()
with ms.sample("collection 1"):
collection1.compute()
with ms.sample("collection 2"):
collection2.compute()
...
ms.plot(align=True)
示例输出:

- class distributed.diagnostics.MemorySampler[源代码]¶
每 <interval> 秒采样一次集群范围的内存使用情况。
用法
client = Client() ms = MemorySampler() with ms.sample("run 1"): <run first workflow> with ms.sample("run 2"): <run second workflow> ... ms.plot()
或使用异步客户端:
client = await Client(asynchronous=True) ms = MemorySampler() async with ms.sample("run 1"): <run first workflow> async with ms.sample("run 2"): <run second workflow> ... ms.plot()
- plot(*, align: bool = False, **kwargs: Any) Any[源代码]¶
绘制迄今为止收集的数据系列
- 参数
- 对齐bool (可选)
参见
to_pandas()- kwargs
直接传递给
pandas.DataFrame.plot()
- 返回
- sample(label: str | None = None, *, client: Client | None = None, measure: str = 'process', interval: float = 0.5) Any[源代码]¶
记录集群内存使用情况的上下文管理器。如果客户端是同步的,则它是同步的;如果客户端是异步的,则它是异步的。
样本记录在
self.samples[<标签>]中。- 参数
- 标签: str, 可选
标签用于记录在 self.samples 字典下的样本。默认:自动生成一个随机标签
- client: Client, 可选
用于连接调度器的客户端。默认:使用全局客户端
- measure: str, 可选
来自
distributed.scheduler.MemoryState的措施之一。默认值:采样进程内存- interval: float, 可选
采样间隔,以秒为单位。默认值:0.5