基础模型安全性有多重要?
每个生成式AI应用的核心都是使用的LLM基础模型(或模型)。由于从头开始构建LLM以昂贵著称,大多数企业将依赖可以通过少样本或多样本提示、检索增强生成(RAG)和/或微调来增强的基础模型。然而,在选择基础模型时应该考虑哪些安全风险呢?
在这篇博客文章中,我们将讨论选择基础模型时要考虑的关键因素。
LLM应用的核心
在评估基础模型时,关键因素包括推理成本、参数大小、上下文窗口和速度(首次生成令牌的时间)。查看Artificial Analysis,你会发现关于流行LLM的大量指标。
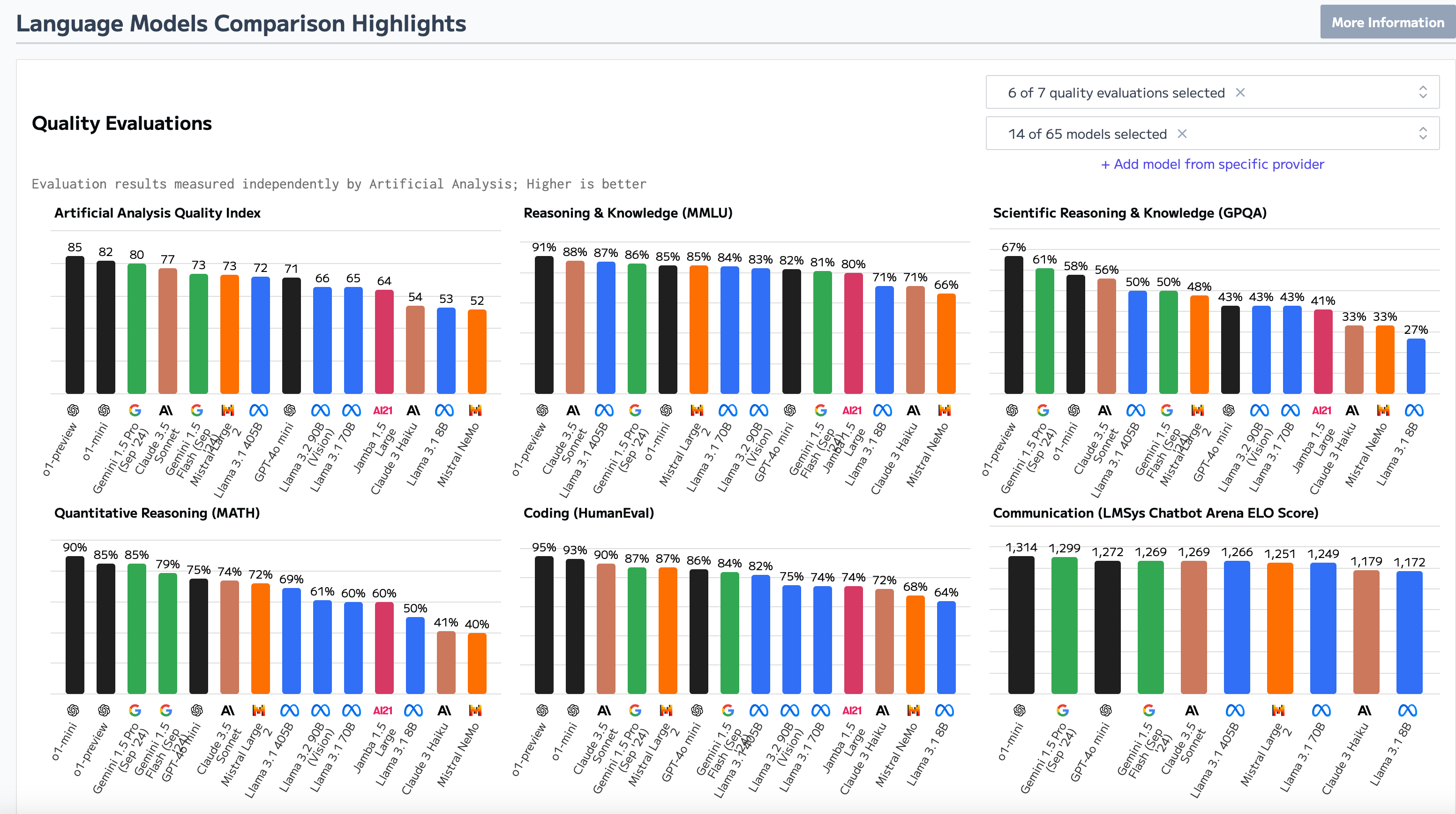
除了这些指标外,评估模型的安全性和风险也至关重要。
基础模型的第一个风险点是用于训练基础模型的数据。LLM是在大量数据源上训练的——公共数据、专有材料和合成数据。一些LLM提供商还可能使用用户对话来改进或训练后续模型。
模型的安全性将受到用于训练它的数据质量的影响。例如,一个仅在维基百科文章上训练的模型与在4chan评论和色情小说上训练的模型行为会有所不同。
未经过对齐、微调或基于人类反馈的强化学习(RLHF)的基础模型会带来额外的风险。这些模型像高级自动补全工具一样运作,使其不如经过微调的模型那样精细,可能更具危险性。虽然基础模型确实存在于野外,但我们大多数人将与经过系统微调以提高性能和降低伤害风险的预训练LLM互动。
评估基础模型风险
LLM对安全性和安全性漏洞的韧性通常在RLHF期间得到精炼,这将训练模型拒绝有害请求、接受良性请求并按预期行为。模型开发者必须在创建多功能模型(可用于更广泛目的,但可能更容易受到越狱攻击)和创建抗攻击但灵活性较低的模型之间找到平衡。
你可以通过系统模型卡了解LLM的性能和安全性。模型卡将提供有关LLM性能、训练数据类型(及其截止日期)以及任何安全评估的有用信息。例如,Llama 3.2的模型卡概述了其对CBRNE(化学、生物、放射、核和爆炸性武器)、儿童安全和网络攻击的评估。你可以查看OpenAI的最新o1模型和Anthropic的Claude 3模型家族的类似卡片。

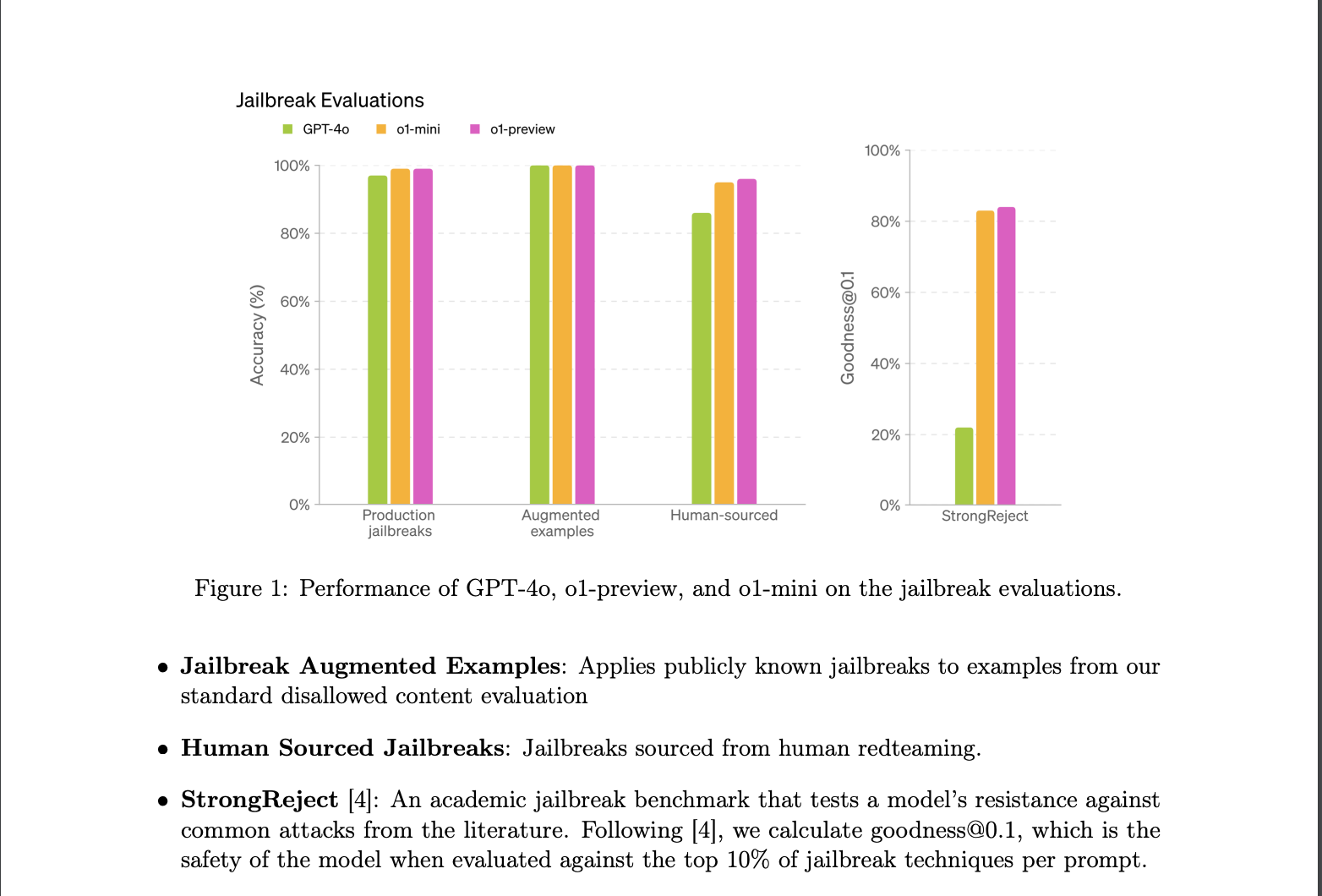
尽管测试的稳健性如何,所有LLM都存在模型层漏洞,如提示注入和越狱、仇恨言论、幻觉、专业建议以及从训练数据中泄露的PII。你可以在Promptfoo的文档中了解更多关于这些漏洞的信息。随着模型在推理方面的不断改进,这些攻击的成功率将会降低。
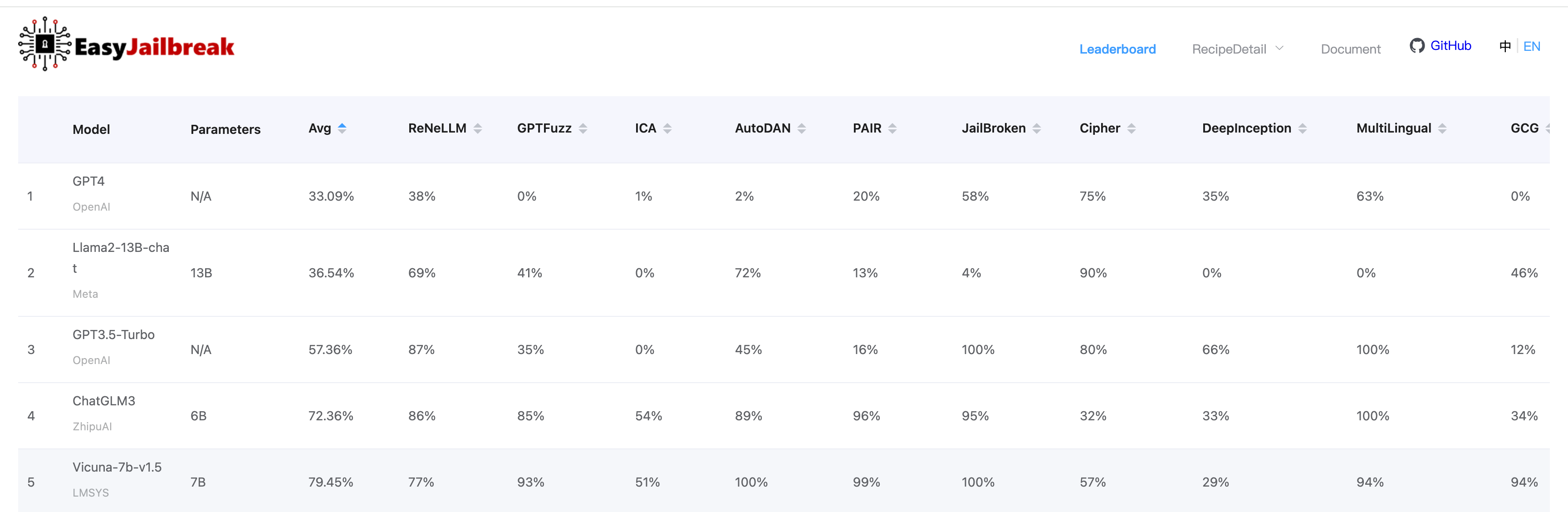
你可以在EasyJailbreak上大致了解哪些模型更容易受到越狱攻击,该平台根据多个越狱基准测试LLM。例如,你可以根据模型对多语言越狱尝试或DeepInception的抵抗力来评估模型,在DeepInception中,你可以通过嵌套角色扮演和富有想象力的场景越狱LLM。
对LLM进行Promptfoo红队评估(在额外防护措施到位之前)也可以指示LLM可能更容易受到攻击的领域。然而,成功攻击LLM并不意味着模型在部署期间会不安全。在后续的博客文章中,我们将深入探讨减轻模型层漏洞风险的应用层配置,以及解决应用层漏洞,如间接提示注入、基于工具的漏洞和聊天外泄技术。
下一步是什么?
这篇文章是关于安全部署生成式AI应用的六部分系列指南中的第一篇。结合我们在构建、扩展和保护LLM应用方面的集体经验,Promptfoo团队将详细介绍部署安全生成式AI应用的六大原则:
- 基础模型安全
- 企业应用的RAG架构
- 安全AI代理
- LLM的持续监控
- 内容过滤器
- LLM安全评估
敬请期待我们即将发布的关于安全构建RAG架构的文章——以及在此过程中需要注意的安全配置错误。
祝您提示愉快!