良好的性能指标
内容
良好的性能指标¶
备注
这是一个实验性功能,可能会在没有弃用周期的情况下迅速变化。
你可能想要调查你的 Dask 工作负载在哪些地方花费了大部分时间;不仅是在哪些任务上,还包括在执行这些任务时 做了什么。Dask 自动收集 细粒度的性能指标 来回答这个问题,通过将计算的端到端运行时间按任务分解,并且在每个任务中,按完成任务的一系列 活动 进行分解。
为了观察这些指标,你可以简单地
运行你的工作负载端到端
打开 Dask 仪表板(LocalCluster 的默认地址:http://localhost:8787)
选择
更多...->精细性能指标
或者,如果你使用的是 Jupyter Lab 并且安装了 dask-labextension,你可以直接将 Fine Performance Metrics 小部件拖到你的 Jupyter 仪表板上。
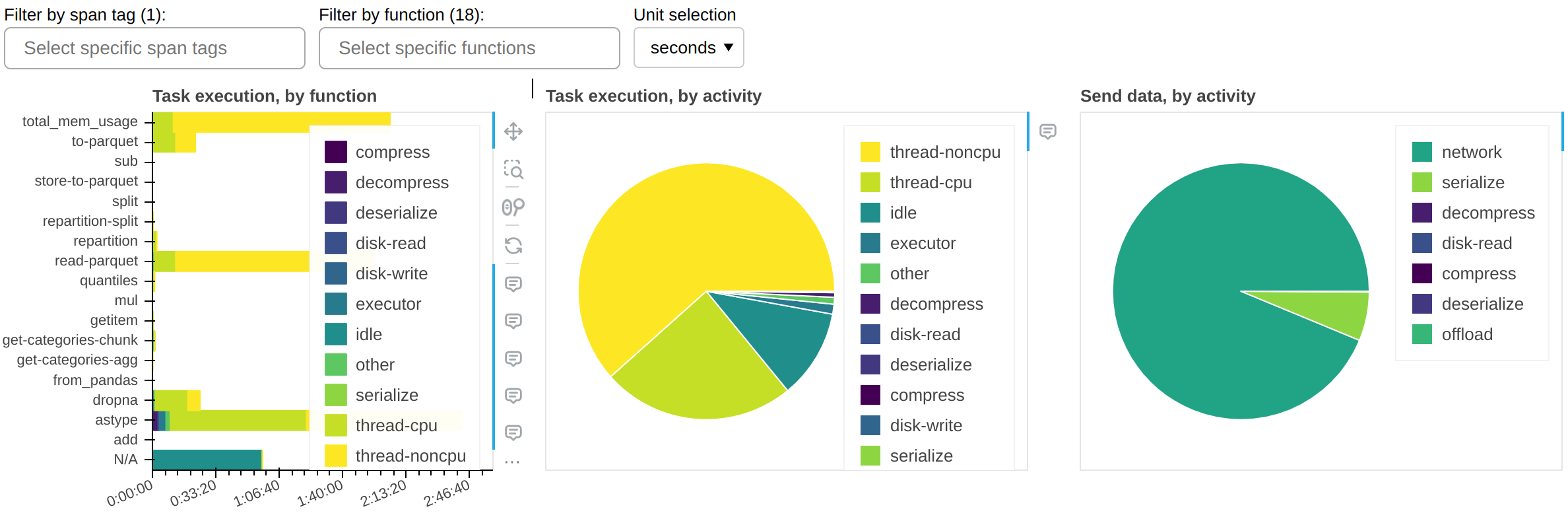
中央面板(任务执行,按活动)显示了集群在其时间上花费的*活动*,累积所有当前可见的函数。最重要的活动包括:
thread-cpu任务在工作者上运行时所花费的CPU时间。这通常是“好”时间;换句话说,如果你在一个CPU上串行运行工作负载,这就是你花费的时间——但在你的集群上可用的任意多个CPU上并行化了。
thread-noncpu在工作者上运行任务时,墙钟时间与CPU时间之间的差异。这通常是I/O时间、GPU时间、CPU争用或GIL争用。如果你在你的整体工作负载中观察到大量的这种情况,你可能希望按功能分解并隔离那些已知执行I/O或GPU活动的功能。
idle工作线程空闲但无任务运行的时间。这通常是由于工作负载无法充分利用集群上的所有线程、调度器与工作线程之间的网络延迟,或调度器上的CPU负载过高引起的。此度量不包括整个集群完全空闲时所花费的时间。
disk-read、disk-write、compress、decompress由于内存不足而导致的溢出/反溢出到磁盘所花费的时间。请参阅 Worker 内存管理。
executor,offload,other这是来自 Dask 代码的开销,通常可以忽略不计。然而,它可能会因 GIL 争用和 spill/unspill 活动而增加。
显示的总时间应大致等于工作负载的端到端运行时间,乘以集群上的线程数。
左侧面板(按功能划分的任务执行)显示与中央面板相同的信息,但按功能细分。
右侧面板(按活动发送数据)显示网络传输时间。请注意,大部分传输应与任务执行同时进行,因此可能不会产生影响。只有当您有非常大的 idle 时间时,才需要担心这一点。
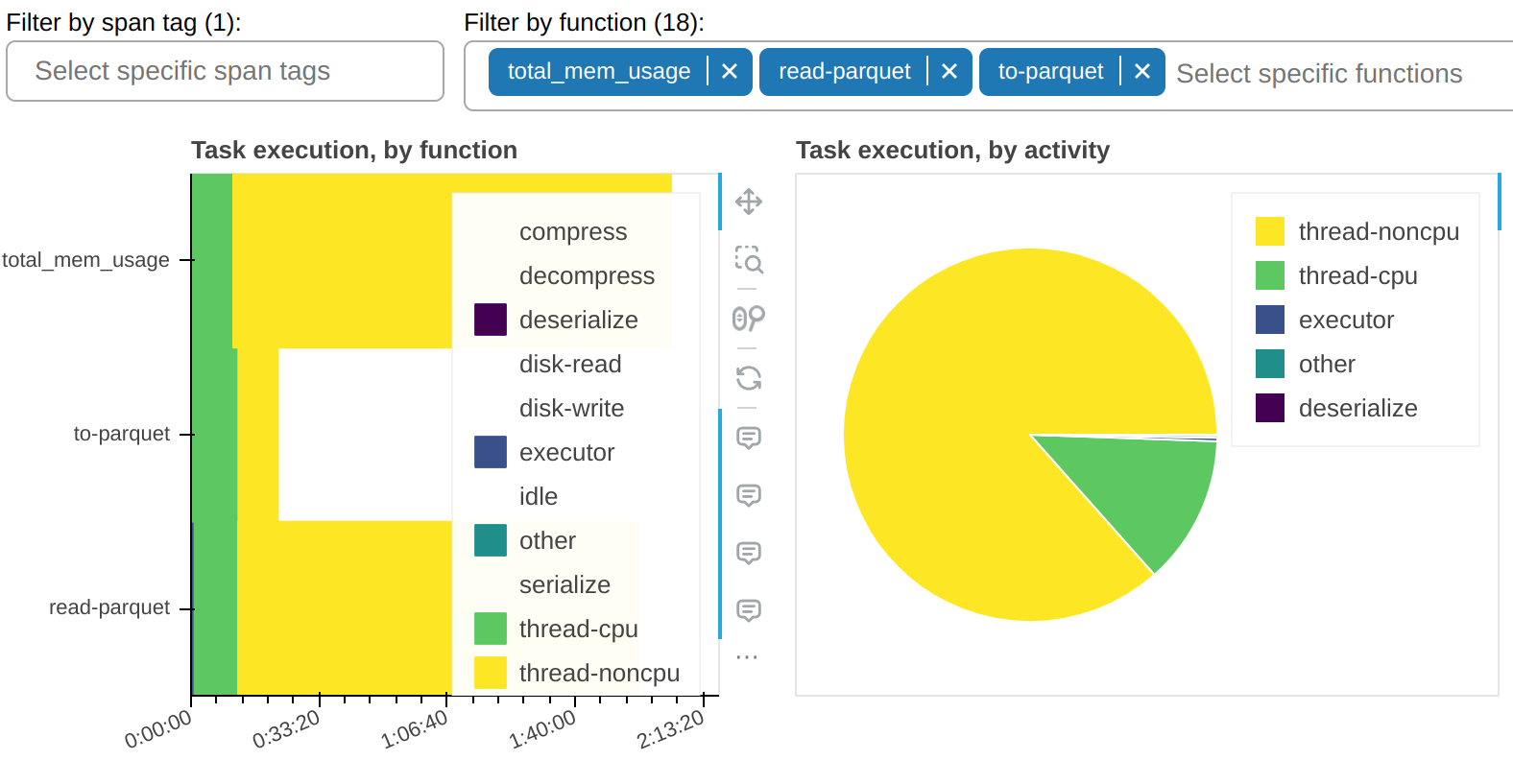
有一个过滤器允许你只显示选定的函数。在示例截图中,你可以观察到大部分 thread-noncpu 时间 - 正如预期的那样 - 集中在已知为 I/O 密集型的函数上。这里它们被单独列出:
以下是所有其他需要非平凡时间的函数:
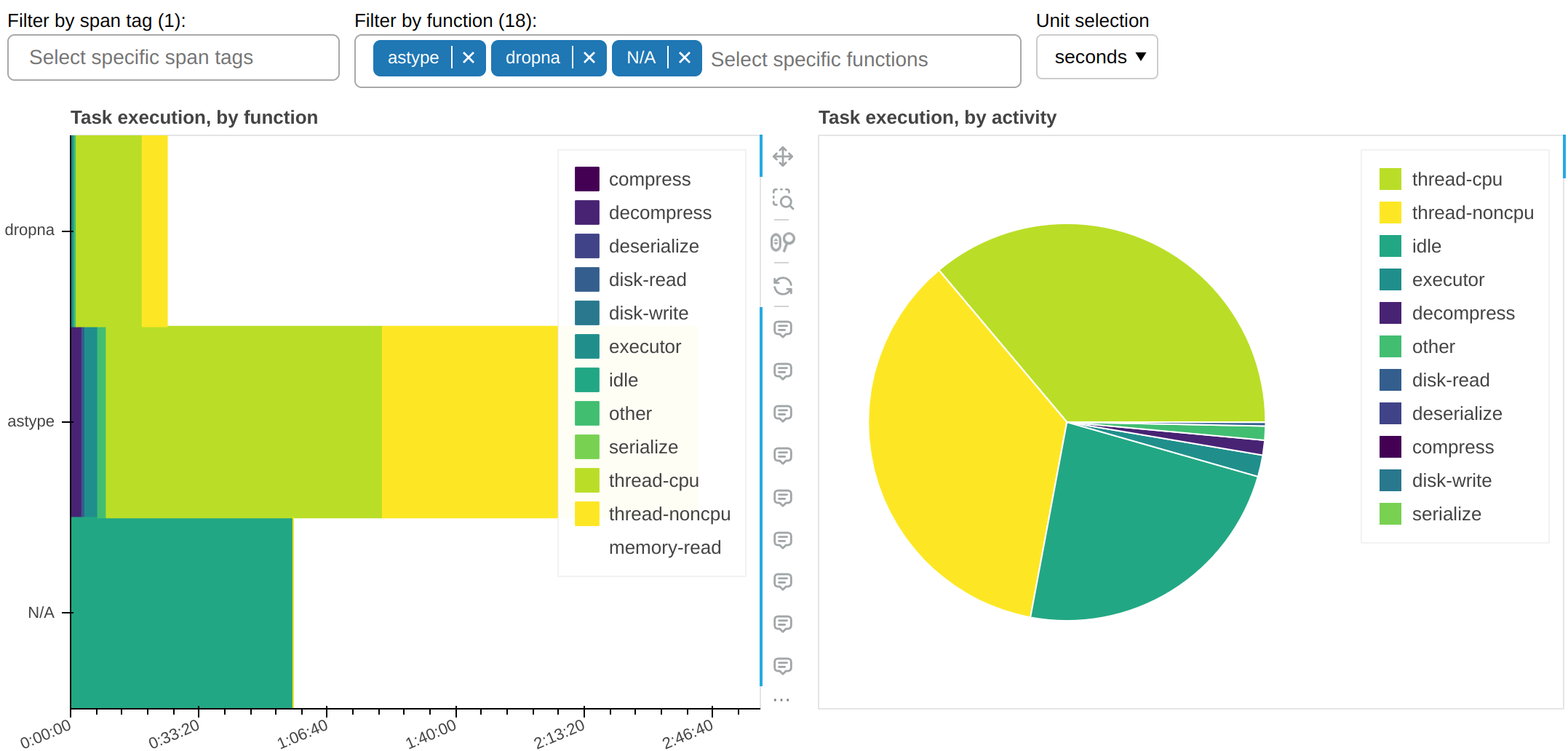
这告诉我们一个重要的信息:为什么 astype 这个纯CPU函数,会占用工人的线程大量时间,但却没有增加任何CPU时间?答案几乎可以肯定,是因为它没有正确释放GIL。
Fine Performance Metrics 收集的不仅仅是墙钟时间。我们可以将单位更改为字节:
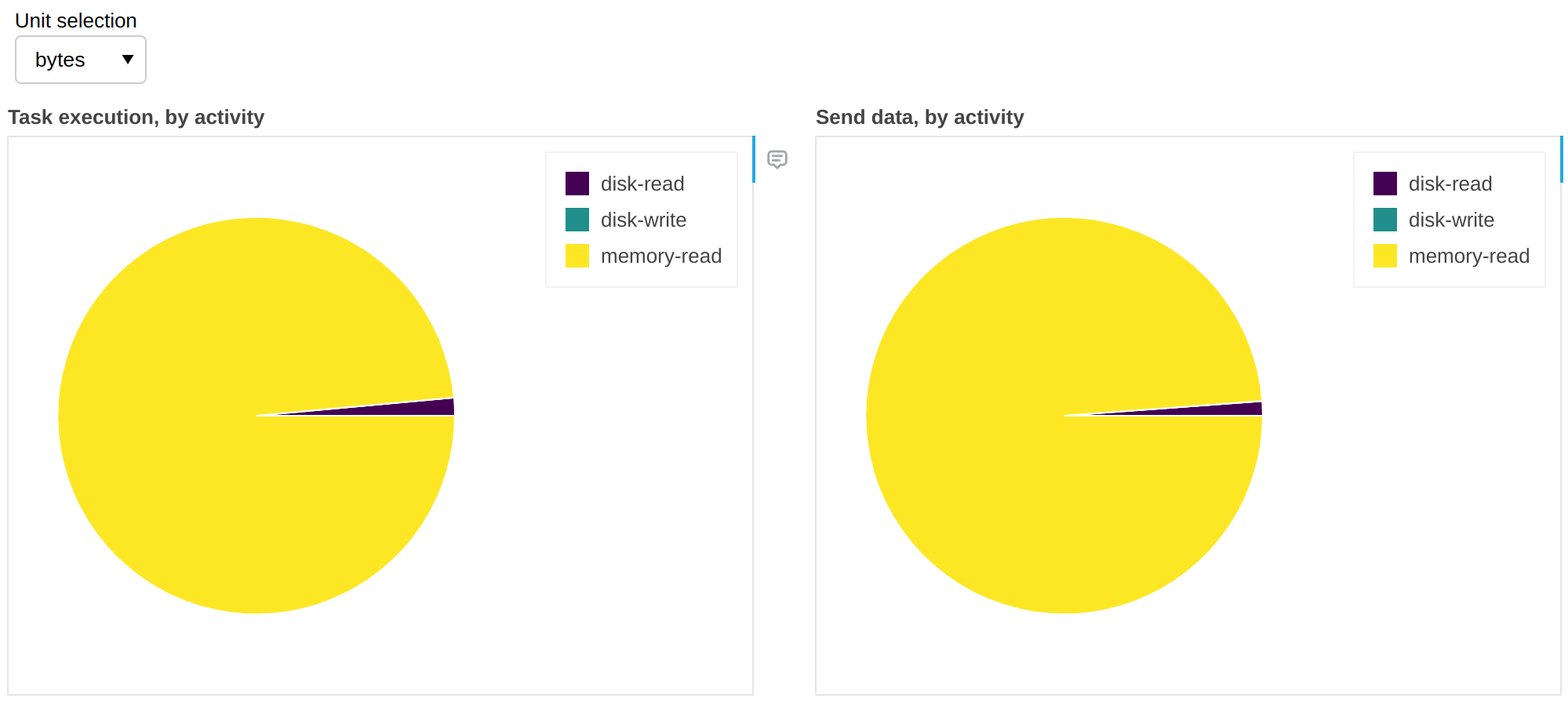
上述内容为我们提供了关于溢出/反溢出活动的见解(参见 Worker 内存管理)。在这个工作流程中,99% 的情况下有足够的 RAM 来容纳所有数据,因此没有必要从磁盘检索数据;换句话说,我们对 99% 的数据有 缓存命中,这意味着如果我们增加 RAM,我们不会获得任何好处,但如果我们减少 RAM,我们可能会开始看到速度下降。
任务前缀足够吗?¶
单独的任务前缀可能过于细粒度;反之,相同的前缀可能在工作流的非常不同的部分出现。你的代码库可能足够复杂,以至于不容易直接定位负责特定任务前缀的客户端代码。
跨度 允许你将这些指标分解为宏块(例如数据加载、预处理等)。
高级用户API¶
在大多数情况下,良好的性能指标可以正常工作;作为用户,您不需要更改客户端代码。
如果你在集群上运行自定义任务(例如通过 submit()、map_blocks() 或 map_partitions()),你可能希望自定义它们生成的指标。例如,你可能希望将 I/O 时间与 thread-noncpu 分开。
from distributed.metrics import context_meter
@context_meter.meter("I/O")
def read_some_files():
...
future = client.submit(read_some_files)
在上面的例子中,自定义函数 read_some_files 所花费的墙钟时间将被记录为“I/O”,这是一个完全任意的活动标签。
或者你可能只想这样标记一些时间:
def read_some_files():
with context_meter.meter("I/O"):
data = read_from_network(...)
return preprocess(data)
在上面的例子中,函数被分为一个I/O密集型阶段,read_from_network,和一个CPU密集型阶段,preprocess。distributed.metrics.context_meter.meter() 上下文管理器将记录 read_from_network 所花费的时间为 I/O,而 preprocess 所花费的时间仍将被记录为 thread-cpu 和 thread-noncpu 的混合(后者可能例如突出显示GIL争用)。
备注
The distributed.metrics.context_meter.meter() 上下文管理器包裹在运行在单个任务中的工作代码周围。如果用于装饰定义Dask图的客户端代码,它将不起作用。请参阅 跨度 了解相关内容。
最后,您可能希望报告一个不仅仅是挂钟时间的指标。例如,如果您正在从S3不频繁访问存储中读取数据,您可能希望跟踪它以了解您的支出:
def read_some_files():
data = read_from_network(...)
context_meter.digest_metric("S3 Infrequent Access", sizeof(data), "bytes")
return data
再次强调,“S3 不频繁访问”是一个完全任意的活动标签,而“字节”是一个完全任意的度量单位。
- distributed.metrics.context_meter.digest_metric(label: collections.abc.Hashable, value: float, unit: str) None¶
调用当前设置的上下文回调函数以处理任意定量指标。
- distributed.metrics.context_meter.meter(label: collections.abc.Hashable, unit: str = 'seconds', func: collections.abc.Callable[[], float] = <built-in function perf_counter>, floor: typing.Union[float, typing.Literal[False]] = 0.0) collections.abc.Iterator[distributed.metrics.MeterOutput]¶
一个方便的上下文管理器或装饰器,它在包装代码之前和之后调用 func(),计算差值,最后调用
digest_metric()。如果单位为’秒’,它还会减去在同一上下文中执行的任何其他
meter()或digest_metric()调用,这些调用的单位相同,以确保总数严格累加。
开发者规范¶
目标受众
本节仅对维护 Dask 或编写调度器扩展的开发者感兴趣,例如创建替代仪表板或长期存储指标。
收集了精细的性能指标:
在每个工作节点上
在调度器上,全局地
在 跨度 上
在工作节点上,它们通过 distributed.core.Server.digest_metric() 收集并存储在 Worker.digests_total 映射中。
它们以这种格式存储:
("执行", span_id, task_prefix, activity, unit): value("gather-dep", 活动, 单位): 值("获取数据", 活动, 单位): 值("memory-monitor", activity, unit): value
在每次心跳时,它们都会与调度器同步,并在 Scheduler.cumulative_worker_metrics 映射中填充,格式如下:
("execute", task_prefix, activity, unit): value("gather-dep", 活动, 单位): 值("获取数据", 活动, 单位): 值("memory-monitor", activity, unit): value
由于 execute 指标在这里没有 span_id,来自工作者的多条记录可能已在调度器上的单一条记录中被汇总。
可以在 Scheduler.extensions["spans"].spans[span_id].cumulative_worker_metrics 的 跨度 中找到 execute 指标,并按此格式进行细分:
("execute", task_prefix, activity, unit): value
注释¶
在
Worker.digests_total和Scheduler.cumulative_worker_metrics中,你还会发现与精细性能指标无关的键,这些键不一定是元组。由于自定义指标(见前一节),
activity将*大多数时候*是字符串,但*并非总是*如此。即使不考虑自定义指标,未来也可能添加更细粒度的活动,因此为它们实现硬编码测试从来都不是一个好主意。