
开始使用 InfluxDB 3 企业版
InfluxDB 3 企业版正在公开Alpha测试
InfluxDB 3 Enterprise 处于公开测试阶段,可供测试和反馈,但不适合生产环境使用。产品和该文档均处于不断完善中。我们欢迎并鼓励您分享您对Alpha版本的使用体验,并邀请您加入我们的公共频道以获取更新和分享反馈。
开始使用 InfluxDB 3 企业版
InfluxDB是一个旨在收集、处理、转化和存储事件和时间序列数据的数据库,特别适合需要实时摄取和快速查询响应时间,以构建用户界面、监控和自动化解决方案的使用案例。
常见的使用案例包括:
- 监控传感器数据
- 服务器监控
- 应用性能监控
- 网络监控
- 金融市场和交易分析
- 行为分析
InfluxDB针对近实时数据监控至关重要的场景进行了优化,查询需要快速返回,以支持用户体验,如仪表板和交互式用户界面。
InfluxDB 3 企业版是建立在 InfluxDB 3 核心之上的,InfluxDB 3 开源版本。核心的功能亮点包括:
- 无盘架构,支持对象存储(或无依赖的本地磁盘)
- 快速查询响应时间(最后值查询低于10毫秒,或不同元数据30毫秒)
- 用于插件和触发器的嵌入式Python虚拟机
- Parquet文件持久化
- 与 InfluxDB 1.x 和 2.x 写入 API 的兼容性
企业版本在核心功能的基础上增加了:
- 历史查询能力和单系列索引
- 高可用性
- 读取副本
- 增强的安全性(即将推出)
- 行级删除支持(即将推出)
- 集成的管理员用户界面(敬请期待)
本指南包含的内容
本指南涵盖企业版以及InfluxDB 3核心,包括以下主题:
安装和启动
InfluxDB 3 企业版在 Linux、 macOS 和 Windows 上运行。
要快速入门,下载并运行安装脚本 - 例如,使用 curl:
curl -O https://www.influxdata.com/d/install_influxdb3.sh \
&& sh install_influxdb3.sh enterprise
或者,下载并安装 构建工件:
- Linux | x86_64 | GNU • sha256
- Linux | x86_64 | MUSL • sha256
- Linux | ARM64 | GNU • sha256
- Linux | ARM64 | MUSL • sha256
- macOS | ARM64 • sha256
macOS Intel 版本即将推出。
下载并安装 InfluxDB 3 企业版 Windows (x86) 二进制文件 • sha256
docker pull quay.io/influxdb/influxdb3-enterprise:latest
每次合并到 InfluxDB 3 Enterprise main 分支时,构建的工件和镜像都会更新。
验证安装
安装完 InfluxDB 3 Enterprise 后,输入以下命令以验证安装是否成功:
influxdb3 --version
如果您的系统无法找到 influxdb3,那么请 source 配置文件 (例如,.bashrc,.zshrc) 供您的 shell 使用,例如:
source ~/.zshrc
启动 InfluxDB
要启动您的 InfluxDB 实例,请使用 influxdb3 serve 命令并提供以下信息:
--object-store: 指定要使用的对象存储类型。InfluxDB支持以下类型:本地文件系统 (file),memory, S3(以及兼容的服务,如Ceph或Minio) (s3), Google Cloud Storage (google), 和Azure Blob Storage (azure).--writer-id: 一个字符串标识符,用于确定服务器在配置的存储位置内的存储路径,在多节点 setup 中,用于引用该节点
以下示例展示了如何以不同的对象存储配置启动 InfluxDB 3:
# MEMORY
# Stores data in RAM; doesn't persist data
influxdb3 serve --writer-id=local01 --object-store=memory
# FILESYSTEM
# Provide the filesystem directory
influxdb3 serve \
--writer-id=local01 \
--object-store=file \
--data-dir ~/.influxdb3
要运行Docker镜像并将数据持久化到文件系统,挂载一个卷用于对象存储-例如,传递以下选项:
-v /path/on/host:/path/in/container: 将你的文件系统中的一个目录挂载到容器中--object-store file --data-dir /path/in/container: 使用挂载作为服务器存储
# FILESYSTEM USING DOCKER
# Create a mount
# Provide the mount path
docker run -it \
-v /path/on/host:/path/in/container \
quay.io/influxdb/influxdb3-enterprise:latest serve \
--writer-id my_host \
--object-store file \
--data-dir /path/in/container
# S3 (defaults to us-east-1 for region)
# Specify the Object store type and associated options
influxdb3 serve --writer-id=local01 --object-store=s3 --bucket=[BUCKET] --aws-access-key=[AWS ACCESS KEY] --aws-secret-access-key=[AWS SECRET ACCESS KEY]
# Minio/Open Source Object Store (Uses the AWS S3 API, with additional parameters)
# Specify the Object store type and associated options
influxdb3 serve --writer-id=local01 --object-store=s3 --bucket=[BUCKET] --aws-access-key=[AWS ACCESS KEY] --aws-secret-access-key=[AWS SECRET ACCESS KEY] --aws-endpoint=[ENDPOINT] --aws-allow-http
有关服务器选项的更多信息,请运行 influxdb3 serve --help。
停止Docker容器
目前,一个错误阻止使用 Ctrl-c 来停止 InfluxDB 3 容器。 使用 docker kill 命令来停止容器:
- 输入以下命令以查找容器 ID:
docker ps -a - 输入命令以停止容器:
docker kill <CONTAINER_ID>
许可
首次启动 InfluxDB 3 Enterprise 时,它会提示您输入一个邮箱地址以进行验证。您将收到一封带有验证链接的电子邮件。 经过验证后,许可证的创建、检索和应用将自动进行。
在alpha阶段,许可证有效期至2025年5月7日。
数据模型
数据库服务器包含逻辑数据库,这些数据库有表,这些表有列。与之前版本的InfluxDB相比,您可以将数据库视为v2中的bucket或v1中的db/retention_policy。table相当于measurement,它具有可以是tag(字符串字典)、int64、float64、uint64、bool或string类型的列,最后每个表都有一个time列,它是纳秒精度的时间戳。
在 InfluxDB 3 中,每个表都有一个主键——有序的标签集合和时间——用于其数据。这是所有创建的 Parquet 文件所使用的排序方式。当您通过显式调用或首次向表中写入数据来创建表时,它将主键设置为按到达顺序排列的标签。这个是不可改变的。尽管 InfluxDB 仍然是一个 写时模式 数据库,但表的标签列定义是不可改变的。
标签应该包含唯一的识别信息,如 sensor_id,或 building_id 或 trace_id。所有其他数据应保存在字段中。您将能够在以后为任何列(无论是字段还是标签)添加快速的最近 N 值和唯一值查找。
写入数据
InfluxDB是一个写时模式的数据库。您可以开始写入数据,InfluxDB会即时创建逻辑数据库、表和它们的模式。 在创建模式后,InfluxDB会在接受数据之前验证未来的写入请求。 随后的请求可以即时添加新的字段,但无法添加新的标签。
数据库有三个写入API端点,响应HTTP POST 请求:
/write?db=mydb&precision=ns/api/v2/write?bucket=mydb&precision=ns/api/v3/write_lp?db=mydb&precision=ns&accept_partial=true
InfluxDB 3 企业版提供了 /write 和 /api/v2/write 端点,以便与能够向以前版本的 InfluxDB 写入数据的客户端保持向后兼容。
然而,这些 API 与以前版本中的 API 在以下方面存在差异:
- 表中的标签(测量)是 不可变的
- 标签和字段在一个表中不能有相同的名称。
InfluxDB 3 企业版添加了 /api/v3/write_lp 端点,它接受与之前版本相同的行协议语法,并支持 ?accept_partial=<BOOLEAN> 参数,该参数
让您接受或拒绝部分写入(默认值为 true)。
以下代码块是行协议的一个示例,显示了表名后面跟着标签,这些标签是一个有序的、以逗号分隔的键/值对列表,其中值为字符串,后面是一个以逗号分隔的键/值对列表,表示字段,并以一个可选的时间戳结束。默认情况下,时间戳是纳秒纪元,但您可以通过precision查询参数指定不同的精度。
cpu,host=Alpha,region=us-west,application=webserver val=1i,usage_percent=20.5,status="OK"
cpu,host=Bravo,region=us-east,application=database val=2i,usage_percent=55.2,status="OK"
cpu,host=Charlie,region=us-west,application=cache val=3i,usage_percent=65.4,status="OK"
cpu,host=Bravo,region=us-east,application=database val=4i,usage_percent=70.1,status="Warn"
cpu,host=Bravo,region=us-central,application=database val=5i,usage_percent=80.5,status="OK"
cpu,host=Alpha,region=us-west,application=webserver val=6i,usage_percent=25.3,status="Warn"
如果您将前面的行协议保存到一个文件中(例如,server_data),那么您可以使用influxdb3 CLI来写入数据,例如:
influxdb3 write --database=mydb --file=server_data
以下示例显示了如何使用 curl 和 /api/3/write_lp HTTP 端点写入数据。为了显示接受和拒绝部分写入之间的区别,示例中的第 2 行包含了一个 float 字段的 string 值 (temp=hi)。
发生了部分行协议的写入
使用 accept_partial=true:
* upload completely sent off: 59 bytes
< HTTP/1.1 400 Bad Request
< transfer-encoding: chunked
< date: Wed, 15 Jan 2025 19:35:36 GMT
<
* Connection #0 to host localhost left intact
{"error":"partial write of line protocol occurred","data":[{"original_line":"dquote> home,room=Sunroom temp=hi","line_number":2,"error_message":"No fields were provided"}]}%
第 1 行已编写并可查询。
响应是一个HTTP错误 (400) 状态,响应主体包含 partial write of line protocol occurred 和关于问题行的详细信息。
解析失败,写入_lp 端点
使用 accept_partial=false:
> curl -v -XPOST "localhost:8181/api/v3/write_lp?db=sensors&precision=auto&accept_partial=false" \
--data-raw "home,room=Sunroom temp=96
dquote> home,room=Sunroom temp=hi"
< HTTP/1.1 400 Bad Request
< transfer-encoding: chunked
< date: Wed, 15 Jan 2025 19:28:27 GMT
<
* Connection #0 to host localhost left intact
{"error":"parsing failed for write_lp endpoint","data":{"original_line":"dquote> home,room=Sunroom temp=hi","line_number":2,"error_message":"No fields were provided"}}%
两行都没有写入数据库。 返回的是一个HTTP错误(400)状态,响应主体包含解析失败,针对write_lp端点及问题行的详细信息。
数据持久性
写入的数据进入WAL文件,每秒创建一次,以及一个可查询的内存缓冲区。随后,InfluxDB快照WAL并将数据持久化到对象存储中,作为Parquet文件。 我们在本指南后面会介绍无磁盘架构。
写请求在WAL刷新后返回
写入数据库的请求不会返回,直到WAL文件已经刷新到配置的对象存储中,默认情况下这发生在每秒一次。 单个写入请求可能不会快速完成,但您可以发出许多并发请求以获得更高的总吞吐量。 在未来,我们将添加一个API参数,使请求可以在不等待WAL刷新完成的情况下返回。
创建数据库或表
要创建一个没有写入数据的数据库,请使用create子命令,例如:
influxdb3 create database mydb
要了解有关子命令的更多信息,请使用 -h, --help 标志:
influxdb3 create -h
查询数据库
InfluxDB 3 现在支持原生 SQL 查询,除了 InfluxQL,这是一种为时间序列查询定制的类 SQL 语言。
Flux, 在 InfluxDB 2.0 中引入的语言,在 InfluxDB 3 中不被支持。
开始查询的最快方法是使用 influxdb3 CLI(它通过 HTTP2 使用 Flight SQL API)。
这个 query 子命令包括选项,以帮助确保查询正确的数据库并具有正确的权限。只有 --database 选项是必需的,但根据您的具体设置,您可能需要传递其他选项,例如主机、端口和令牌。
| 选项 | 描述 | 必需 |
|---|---|---|
--host | 要查询的服务器主机URL [默认: http://127.0.0.1:8181] | 否 |
--database | 要操作的数据库名称 | 是 |
--token | InfluxDB 3 企业服务器的身份验证令牌 | 否 |
--language | 提供的查询字符串的查询语言 [默认: sql] [可能值: sql, influxql] | 否 |
--format | 查询输出的格式 [默认: pretty] [可能的值: pretty, json, json_lines, csv, parquet] | 否 |
--output | 输出数据的路径 | 否 |
示例:在servers数据库上查询“SHOW TABLES”:
$ influxdb3 query --database=servers "SHOW TABLES"
+---------------+--------------------+--------------+------------+
| table_catalog | table_schema | table_name | table_type |
+---------------+--------------------+--------------+------------+
| public | iox | cpu | BASE TABLE |
| public | information_schema | tables | VIEW |
| public | information_schema | views | VIEW |
| public | information_schema | columns | VIEW |
| public | information_schema | df_settings | VIEW |
| public | information_schema | schemata | VIEW |
+---------------+--------------------+--------------+------------+
示例: 查询 cpu 表,限制为 10 行:
$ influxdb3 query --database=servers "SELECT DISTINCT usage_percent, time FROM cpu LIMIT 10"
+---------------+---------------------+
| usage_percent | time |
+---------------+---------------------+
| 63.4 | 2024-02-21T19:25:00 |
| 25.3 | 2024-02-21T19:06:40 |
| 26.5 | 2024-02-21T19:31:40 |
| 70.1 | 2024-02-21T19:03:20 |
| 83.7 | 2024-02-21T19:30:00 |
| 55.2 | 2024-02-21T19:00:00 |
| 80.5 | 2024-02-21T19:05:00 |
| 60.2 | 2024-02-21T19:33:20 |
| 20.5 | 2024-02-21T18:58:20 |
| 85.2 | 2024-02-21T19:28:20 |
+---------------+---------------------+
使用CLI查询InfluxQL
InfluxQL 是由 InfluxData 开发的一种类似于 SQL 的语言,具备针对利用和处理 InfluxDB 特定功能的特点。它与所有版本的 InfluxDB 兼容,使其成为不同 InfluxDB 安装之间互操作性的良好选择。
要使用 InfluxQL 查询,请输入 influxdb3 query 子命令,并在语言选项中指定 influxql,例如:
influxdb3 query --database=servers --lang=influxql "SELECT DISTINCT usage_percent FROM cpu WHERE time >= now() - 1d"
使用API查询
InfluxDB 3 支持 Flight (gRPC) API 和 HTTP API。要使用 HTTP API 查询数据库,请向 /api/v3/query_sql 或 /api/v3/query_influxql 端点发送请求。在请求中,在 db 参数中指定数据库名称,在 q 参数中指定查询。您可以在查询字符串中或在 JSON 对象内传递参数。
使用 format 参数来指定响应格式: pretty, jsonl, parquet, csv 和 json。 默认是 json。
示例:查询传递URL编码的参数
以下示例发送一个 HTTP GET 请求,包含一个 URL 编码的 SQL 查询:
curl -v "http://127.0.0.1:8181/api/v3/query_sql?db=servers&q=select+*+from+cpu+limit+5"
示例:传递JSON参数的查询
以下示例发送一个带有JSON负载参数的HTTP POST 请求:
curl http://127.0.0.1:8181/api/v3/query_sql \
--data '{"db": "server", "q": "select * from cpu limit 5"}'
使用Python客户端查询
使用 InfluxDB 3 Python 库与数据库交互并与您的应用程序集成。我们建议在您特定项目的 Python 虚拟环境中安装所需的包。
要开始,安装 influxdb3-python 包。
pip install influxdb3-python
在这里,您可以仅使用主机和**数据库名称连接到您的数据库。:
from influxdb_client_3 import InfluxDBClient3
client = InfluxDBClient3(
host='http://127.0.0.1:8181',
database='servers'
)
下面的示例展示了如何使用 SQL 查询,然后使用 PyArrow 探索模式并处理结果:
from influxdb_client_3 import InfluxDBClient3
client = InfluxDBClient3(
host='http://127.0.0.1:8181',
database='servers'
)
# Execute the query and return an Arrow table
table = client.query(
query="SELECT * FROM cpu LIMIT 10",
language="sql"
)
print("\n#### View Schema information\n")
print(table.schema)
print("\n#### Use PyArrow to read the specified columns\n")
print(table.column('usage_active'))
print(table.select(['host', 'usage_active']))
print(table.select(['time', 'host', 'usage_active']))
print("\n#### Use PyArrow compute functions to aggregate data\n")
print(table.group_by('host').aggregate([]))
print(table.group_by('cpu').aggregate([('time_system', 'mean')]))
有关Python客户端库的更多信息,请参阅influxdb3-python库在GitHub上的信息。
最后值缓存
InfluxDB 3 企业版支持 最后 N 个值缓存,该缓存将系列或列层次结构中的最后 N 个值存储在内存中。这使得数据库能够在 10 毫秒以内回答这些类型的查询。
您可以使用 influxdb3 CLI 创建一个最后值缓存。
Usage: $ influxdb3 create last-cache [OPTIONS] -d <DATABASE_NAME> -t <TABLE>
Options:
-h, --host <HOST_URL> URL of the running InfluxDB 3 server
-d, --database <DATABASE_NAME> The database to run the query against
--token <AUTH_TOKEN> The token for authentication
-t, --table <TABLE> The table for which the cache is created
--cache-name <CACHE_NAME> Give a name for the cache
--help Print help information
--key-columns <KEY_COLUMNS> Columns used as keys in the cache
--value-columns <VALUE_COLUMNS> Columns to store as values in the cache
--count <COUNT> Number of entries per unique key:column
--ttl <TTL> The time-to-live for entries (seconds)
您可以为每个时间序列创建一个最后值缓存,但要注意高基数表可能会占用过多内存。
创建此缓存的示例:
| 主机 | 应用程序 | 时间 | 使用百分比 | 状态 |
|---|---|---|---|---|
| Bravo | 数据库 | 2024-12-11T10:00:00 | 55.2 | 成功 |
| 查理 | 缓存 | 2024-12-11T10:00:00 | 65.4 | 正常 |
| 布拉沃 | 数据库 | 2024-12-11T10:01:00 | 70.1 | 警告 |
| Bravo | 数据库 | 2024-12-11T10:01:00 | 80.5 | 正常 |
| 阿尔法 | 网络服务器 | 2024-12-11T10:02:00 | 25.3 | 警告 |
influxdb3 create last-cache --database=servers --table=cpu --cache-name=cpuCache --key-columns=host,application --value-columns=usage_percent,status --count=5
查询最后值缓存
要利用LVC,请在您的查询中使用 last_cache() 函数调用它,例如:
influxdb3 query --database=servers "SELECT * FROM last_cache('cpu', 'cpuCache') WHERE host = 'Bravo;"
仅适用于SQL
最后值缓存只适用于SQL,而不适用于InfluxQL;SQL是默认语言。
删除最后值缓存
要移除最后值缓存,请使用以下命令:
influxdb3 delete last_cache [OPTIONS] -d <DATABASE_NAME> -t <TABLE> --cache-name <CACHE_NAME>
Options:
-h, --host <HOST_URL> Host URL of the running InfluxDB 3 server
-d, --database <DATABASE_NAME> The database to run the query against
--token <AUTH_TOKEN> The token for authentication
-t, --table <TABLE> The table for which the cache is being deleted
-n, --cache-name <CACHE_NAME> The name of the cache being deleted
--help Print help information
不同的值缓存
类似于最近值缓存,数据库可以在RAM中缓存表中单独列或列层级的不同值。这对于快速元数据查找很有用,查找时间可以在30毫秒以内返回。许多选项与最近值缓存类似。有关更多信息,请参见CLI输出:
influxdb3 create distinct_cache -h
Python 插件和处理引擎
处理引擎仅在Docker中工作
处理引擎目前仅在Docker x86环境中受支持。非Docker支持即将推出。引擎、API和开发者体验正在积极演进,可能会发生变化。请加入我们的 Discord 以获取更新和反馈。
InfluxDB 3处理引擎是一个嵌入式Python虚拟机,用于在数据库内运行代码以处理和转换数据。
插件
插件是一个与触发类型兼容的签名的Python函数。 influxdb3 create plugin命令将Python插件文件加载到服务器中。
触发器
在您将插件加载到 InfluxDB 3 服务器后,您可以创建一个或多个与该插件相关的触发器。
当您创建触发器时,您需要指定一个插件、一个数据库、可选的运行时参数,以及一个触发器规格,它指定 all_tables 或 table:my_table_name(用于过滤发送到插件的数据)。
当您 启用 触发器时,服务器会根据插件签名执行插件代码。
触发器类型
InfluxDB 3 提供以下类型的触发器:
- 在WAL刷新时: 每秒将一批写入数据发送到插件(可配置)。
目前仅支持WAL 刷新触发器,但更多功能正在开发中:
- 快照: 发送元数据到插件,以便对Parquet数据进行进一步处理或将信息发送到其他地方(例如,发送到Iceberg目录)。 尚不可用。
- 按计划进行: 按用户配置的计划执行插件,适用于数据收集和死者监控。 尚不可用。
- 按需: 将插件绑定到HTTP端点
/api/v3/plugins/<name>。 尚未可用。 插件接收HTTP请求头和内容,然后可以解析、处理,并将数据发送到数据库或第三方服务。
测试、创建和触发插件代码
处理引擎仅在Docker中工作
处理引擎目前仅在Docker x86环境中受支持。非Docker支持即将推出。引擎、API和开发者体验正在积极演进,可能会发生变化。请加入我们的 Discord 以获取更新和反馈。
示例:用于WAL刷新 的Python插件
# This is the basic structure for Python plugin code that runs in the
# InfluxDB 3 Processing engine.
# When creating a trigger, you can provide runtime arguments to your plugin,
# allowing you to write generic code that uses variables such as monitoring
thresholds, environment variables, and host names.
#
# Use the following exact signature to define a function for the WAL flush
# trigger.
# When you create a trigger for a WAL flush plugin, you specify the database
# and tables that the plugin receives written data from on every WAL flush
# (default is once per second).
def process_writes(influxdb3_local, table_batches, args=None):
# here you can see logging. for now this won't do anything, but soon
# we'll capture this so you can query it from system tables
if args and "arg1" in args:
influxdb3_local.info("arg1: " + args["arg1"])
# here we're using arguments provided at the time the trigger was set up
# to feed into paramters that we'll put into a query
query_params = {"host": "foo"}
# here's an example of executing a parameterized query. Only SQL is supported.
# It will query the database that the trigger is attached to by default. We'll
# soon have support for querying other DBs.
query_result = influxdb3_local.query("SELECT * FROM cpu where host = '$host'", query_params)
# the result is a list of Dict that have the column name as key and value as
# value. If you run the WAL test plugin with your plugin against a DB that
# you've written data into, you'll be able to see some results
influxdb3_local.info("query result: " + str(query_result))
# this is the data that is sent when the WAL is flushed of writes the server
# received for the DB or table of interest. One batch for each table (will
# only be one if triggered on a single table)
for table_batch in table_batches:
# here you can see that the table_name is available.
influxdb3_local.info("table: " + table_batch["table_name"])
# example to skip the table we're later writing data into
if table_batch["table_name"] == "some_table":
continue
# and then the individual rows, which are Dict with keys of the column names and values
for row in table_batch["rows"]:
influxdb3_local.info("row: " + str(row))
# this shows building a line of LP to write back to the database. tags must go first and
# their order is important and must always be the same for each individual table. Then
# fields and lastly an optional time, which you can see in the next example below
line = LineBuilder("some_table")\
.tag("tag1", "tag1_value")\
.tag("tag2", "tag2_value")\
.int64_field("field1", 1)\
.float64_field("field2", 2.0)\
.string_field("field3", "number three")
# this writes it back (it actually just buffers it until the completion of this function
# at which point it will write everything back that you put in)
influxdb3_local.write(line)
# here's another example, but with us setting a nanosecond timestamp at the end
other_line = LineBuilder("other_table")
other_line.int64_field("other_field", 1)
other_line.float64_field("other_field2", 3.14)
other_line.time_ns(1302)
# and you can see that we can write to any DB in the server
influxdb3_local.write_to_db("mytestdb", other_line)
# just some log output as an example
influxdb3_local.info("done")
在服务器上测试插件
使用 InfluxDB 3 安全地测试插件,在加载之前,不会接触到已写入的数据。在插件测试期间:
- 插件执行的查询针对您发送请求的服务器。
- 写入不会发送到服务器,而是返回给你。
要测试一个插件,请执行以下操作:
创建一个 插件目录 –例如,
/path/to/.influxdb/plugins将插件目录提供给Docker容器(例如,使用绑定挂载)
运行Docker命令以 启动服务器,并包含
--plugin-dir选项以及您的插件目录路径。将前面的示例代码保存到插件目录中的一个插件文件中。如果您还没有在示例中向表中写入数据,请注释掉查询的行。
要运行测试,请输入以下命令和选项:
--lp或--file: 要测试的行协议- 可选:
--input-arguments: 用于您的插件代码的逗号分隔的<KEY>=<VALUE>参数列表
influxdb3 test wal_plugin \ --lp <INPUT_LINE_PROTOCOL> \ --input-arguments "arg1=foo,arg2=bar" --database <DATABASE_NAME> \ <PLUGIN_FILENAME>
该命令使用测试数据运行插件代码,将数据传递给插件代码,然后返回插件结果。
您可以快速查看插件的行为,它将写入数据库的数据以及任何错误。
然后,您可以编辑插件目录中的Python代码,并重新运行测试。
服务器会为每个对test API的请求重新加载文件。
有关更多信息,请参见 influxdb3 test wal_plugin 或运行 influxdb3 test wal_plugin -h。
在服务器插件目录中有插件代码,并且测试成功后,您准备好创建一个插件和一个触发器在服务器上运行。
示例:测试、创建和运行插件
以下示例展示了如何测试一个插件,然后创建该插件并触发:
# Test and create a plugin
# Requires:
# - A database named `mydb` with a table named `foo`
# - A Python plugin file named `test.py`
# Test a plugin
influxdb3 test wal_plugin \
--lp="my_measure,tag1=asdf f1=1.0 123" \
-d mydb \
--input-arguments="arg1=hello,arg2=world" \
test.py
# Create a plugin to run
influxdb3 create plugin \
-d mydb \
--code-filename="/path/to/.influxdb3/plugins/test.py" \
test_plugin
# Create a trigger that runs the plugin
influxdb3 create trigger \
-d mydb \
--plugin=test_plugin \
--trigger-spec="table:foo" \
--trigger-arguments="arg1=hello,arg2=world" \
trigger1
在创建了插件和触发器后,输入以下命令来启用触发器并在您写入数据时运行插件:
influxdb3 enable trigger --database mydb trigger1
有关更多信息,请参见以下内容:
无盘架构
InfluxDB 3能够仅使用对象存储操作,而不需要本地附加磁盘。虽然它可以仅使用不带依赖关系的磁盘,但在没有磁盘的情况下操作的能力是此版本的新功能。下图展示了数据写入数据库的路径。
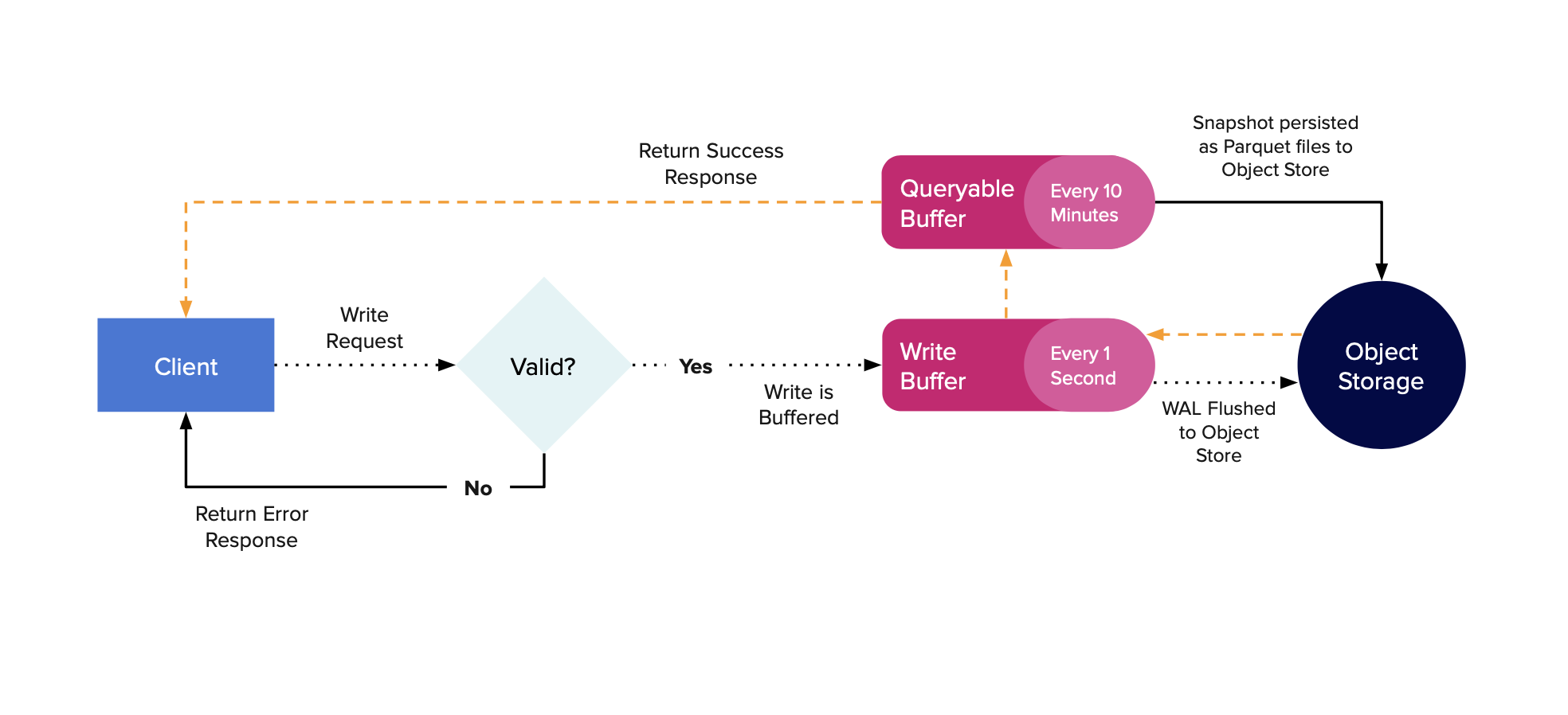
当写请求到达服务器时,它们会被解析、验证,并放入一个内存中的WAL缓冲区。该缓冲区默认每秒刷新一次(可通过配置更改),这将创建一个WAL文件。一旦数据被刷新到磁盘,它会被放入一个可查询的内存缓冲区,然后将响应发送回客户端,表示写入成功。现在该数据将显示在对服务器的查询中。
InfluxDB 定期快照 WAL,以持久化可查询缓冲区中的最旧数据,从而允许服务器删除旧的 WAL 文件。默认情况下,服务器将保留最多 900 个 WAL 文件(15 分钟的数据)并尝试持久化最旧的 10 分钟,保留最近的 5 分钟。
当数据在可查询的缓冲区外被持久化时,它被放入配置的对象存储中作为Parquet文件。这些文件也被放入内存缓存中,以便对最近持久化数据的查询不必去对象存储。
多服务器设置
InfluxDB 3 企业版旨在支持多节点设置,以实现高可用性、读取副本和根据使用案例灵活的实现。
高可用性
企业在架构上具有灵活性,为您提供了配置多个协同工作的服务器以实现高可用性(HA)和高性能的选项。基于无盘引擎并利用对象存储,HA 设置确保了如果一个节点失败,您仍然可以继续从次级节点读取和写入。
两个节点的设置是基本高可用性的最低要求,两个节点都具有读写权限。
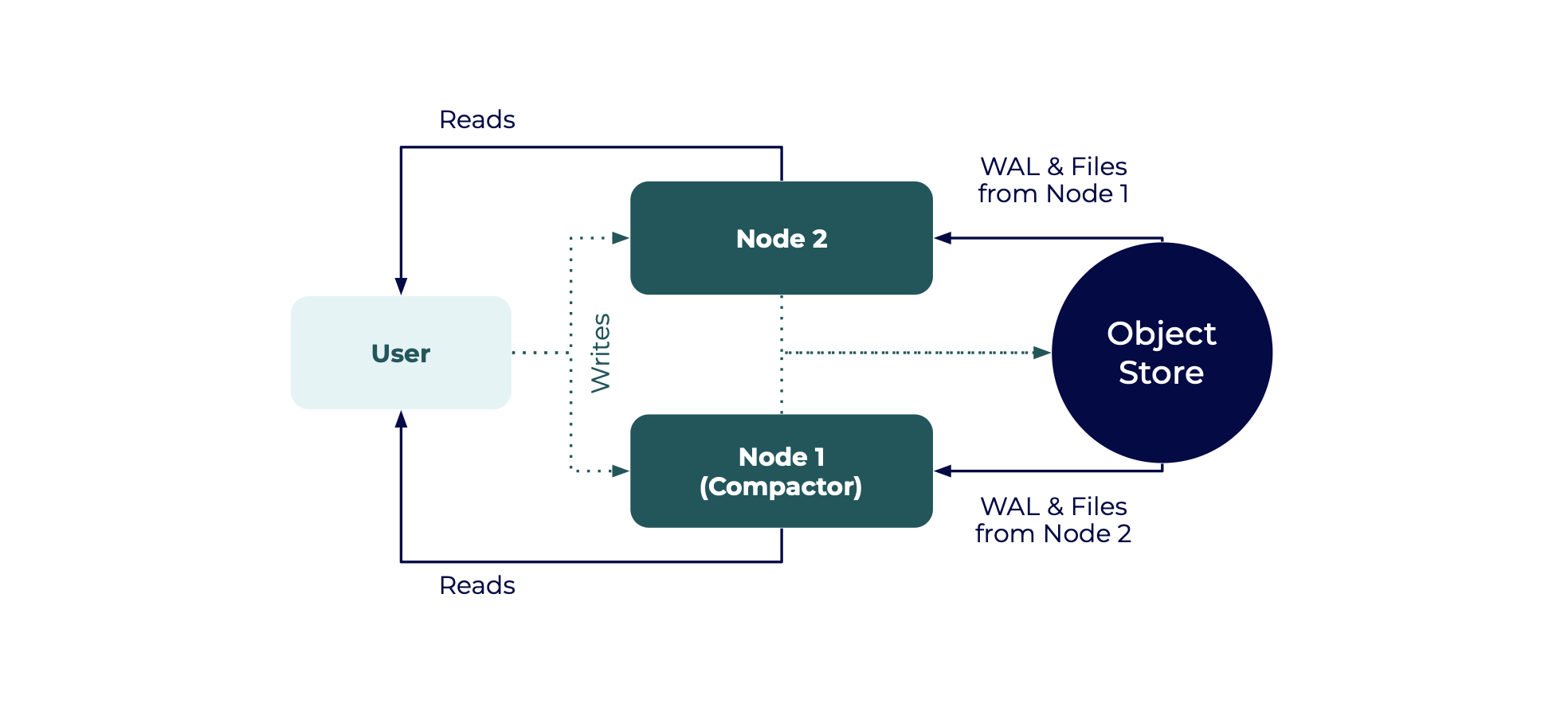
在基本的高可用性设置中:
- 两个节点都向同一个对象存储写入数据,并且都处理查询
- 节点1和节点2是读取副本,它们相互读取对方的对象存储目录
- 其中一个节点被指定为压缩节点
只能指定一个节点作为压缩器。压缩的数据是为一个写入者和多个读取者准备的。
以下示例展示了如何配置和启动两个节点以进行基本的HA设置。 示例命令传递以下选项:
--read-from-writer-ids: 使节点成为一个 只读副本,该副本会检查对象存储以获取来自其他节点的数据--compactor-id: 激活节点的压缩器。只有一个节点可以运行压缩--run-compactions: 确保压缩器运行压缩过程
## NODE 1
# Example variables
# writer-id: 'host01'
# bucket: 'influxdb-3-enterprise-storage'
# compactor-id: 'c01'
influxdb3 serve --writer-id=host01 --read-from-writer-ids=host02 --compactor-id=c01 --run-compactions --object-store=s3 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8181 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>
## NODE 2
# Example variables
# writer-id: 'host02'
# bucket: 'influxdb-3-enterprise-storage'
influxdb3 serve --writer-id=host02 --read-from-writer-ids=host01 --object-store=s3 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8282
--aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>
在节点启动后,查询任一节点都会返回两个节点的数据,并且 NODE 1 进行压缩。要将节点添加到此设置中,请启动更多的读取副本:
influxdb3 serve --read-from-writer-ids=host01,host02 [...OPTIONS]
要运行此设置进行测试,您可以在不同的终端中启动节点,并为每个节点传递不同的 --http-bind 值 - 例如:
# In terminal 1
influxdb3 serve --writer-id=host01 --http-bind=http://127.0.0.1:8181 [...OPTIONS]
# In terminal 2
influxdb3 serve --writer-id=host01 --http-bind=http://127.0.0.1:8181 [...OPTIONS]
具有专用压缩器的高可用性
在 InfluxDB 3 中,数据压缩是更为计算密集的操作之一。为了确保您的读写节点不会因压缩工作而减慢速度,请为所有节点设置一个仅用于压缩的节点,以确保一致且高效的性能。

以下示例展示了如何设置具有专用压缩节点的高可用性(HA):
启动两个读写节点作为读副本,类似于上一个例子,并传递
--compactor-id选项,带有一个专用的压缩器ID(您将在下一步中进行配置)。## NODE 1 — Writer/Reader Node #1 # Example variables # writer-id: 'host01' # bucket: 'influxdb-3-enterprise-storage' influxdb3 serve --writer-id=host01 --compactor-id=c01 --read-from-writer-ids=host02 --object-store=s3 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8181 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>## NODE 2 — Writer/Reader Node #2 # Example variables # writer-id: 'host02' # bucket: 'influxdb-3-enterprise-storage' influxdb3 serve --writer-id=host02 --compactor-id=c01 --read-from-writer-ids=host01 --object-store=s3 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8282 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>启动专用压实节点,使用以下选项:
--mode=compactor: 确保节点仅运行压缩。--compaction-hosts: 指定要进行压缩的主机的以逗号分隔的列表。
**不要包含 replicas (--read-from-writer-ids) 参数,因为这个节点不复制数据。
## NODE 3 — Compactor Node
# Example variables
# writer-id: 'host03'
# bucket: 'influxdb-3-enterprise-storage'
# compactor-id: 'c01'
influxdb3 serve --writer-id=host03 --mode=compactor --compactor-id=c01 --compaction-hosts=host01,host02 --run-compactions --object-store=s3 --bucket=influxdb-3-enterprise-storage --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>
通过读副本和专用压缩器实现高可用性
对于管理时间序列数据非常稳健有效的设置,您可以同时运行摄取节点和只读节点,以及一个专用的压缩节点。

开始为导入启动写入节点。企业并不指定只写模式,因此将它们分配为
read_write模式。为了实现工作负载隔离的好处,您将向这些读写节点仅发送 写入请求。稍后,您将配置 只读 节点。## NODE 1 — Writer Node #1 # Example variables # writer-id: 'host01' # bucket: 'influxdb-3-enterprise-storage' influxdb3 serve --writer-id=host01 --mode=read_write --object-store=s3 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8181 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>## NODE 2 — Writer Node #2 # Example variables # writer-id: 'host02' # bucket: 'influxdb-3-enterprise-storage' Usage: $ influxdb3 serve --writer-id=host02 --mode=read_write --object-store=s3 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8282 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>启动专用的压缩节点 (
--mode=compactor),并确保它在指定的compaction-hosts上运行压缩。## NODE 3 — Compactor Node # Example variables # writer-id: 'host03' # bucket: 'influxdb-3-enterprise-storage' influxdb3 serve --writer-id=host03 --mode=compactor --compaction-hosts=host01,host02 --run-compactions --object-store=s3 --bucket=influxdb-3-enterprise-storage --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>最后,将查询节点启动为 只读。
包含以下选项:--mode=read: 将节点设置为只读--read-from-writer-ids=host01,host02: 从中读取数据的主机ID的逗号分隔列表
## NODE 4 — Read Node #1 # Example variables # writer-id: 'host04' # bucket: 'influxdb-3-enterprise-storage' influxdb3 serve --writer-id=host04 --mode=read --object-store=s3 --read-from-writer-ids=host01,host02 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8383 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>## NODE 5 — Read Node #2 # Example variables # writer-id: 'host05' # bucket: 'influxdb-3-enterprise-storage' influxdb3 serve --writer-id=host05 --mode=read --object-store=s3 --read-from-writer-ids=host01,host02 --bucket=influxdb-3-enterprise-storage --http-bind=0.0.0.0:8484 --aws-access-key-id=<AWS_ACCESS_KEY_ID> --aws-secret-access-key=<AWS_SECRET_ACCESS_KEY>
恭喜你,你已经建立了一个强大的工作负载隔离方案,使用 InfluxDB 3 企业版。
编写和查询多节点设置
如果您在单实例设置中运行 InfluxDB 3 Enterprise,写入和查询与 InfluxDB 3 Enterprise 相同。 您可以使用默认端口 8181 进行任何写入或查询,而无需更改任何命令。
指定写入和查询的主机
要从这个多节点、隔离的架构中受益,请指定主机:
- 在写入请求中,指定一个用于 仅写 的主机
- 在查询请求中,指定一个指定为 _read-only 的主机
当运行多个本地实例进行测试,或者在生产中运行独立节点时,指定主机可以确保写入和查询被路由到正确的实例。如果您在本地运行并在8181(默认端口)上提供实例,则不需要指定主机。
# Example variables on a query
# HTTP-bound Port: 8585
Usage: $ influxdb3 query --host=http://127.0.0.1:8585 -d <DATABASE> "<QUERY>"
文件索引设置
为了加速特定查询的性能,您可以定义用于索引的非主键,这有助于提高单系列查询的性能。此功能仅在企业版中可用,而在核心版中不可用。
创建文件索引
# Example variables on a query
# HTTP-bound Port: 8585
influxdb3 file-index create --host=http://127.0.0.1:8585 -d <DATABASE> -t <TABLE> <COLUMNS>
删除文件索引
influxdb3 file-index delete --host=http://127.0.0.1:8585 -d <DATABASE> -t <TABLE>