用户#
欢迎阅读 Jupyter AI 的用户文档。
如果您有兴趣为 Jupyter AI 做出贡献,请参阅我们的 贡献者指南。
如果您希望构建增强 Jupyter AI 的应用程序,请参阅 开发者指南。
前提条件#
您可以在任何能够运行支持的 Python 版本(从 3.8 到 3.12)的系统上运行 Jupyter AI,包括最新的 Windows、macOS 和 Linux 版本。
如果您使用 conda,可以通过运行以下命令在您的环境中安装 Python 3.12:
conda install python=3.12
jupyter_ai 包提供了 JupyterLab 中的实验室扩展和用户界面,依赖于 JupyterLab 4。如果无法在您的环境中升级到 JupyterLab 4,您应该安装 jupyter_ai v1.x 版本。更多详情请参阅“安装”部分。
Attention
JupyterLab 3 已于 2024 年 5 月 15 日达到维护结束日期。因此,我们将不再将新功能向后移植到支持 JupyterLab 3 的 v1 分支。对于关键问题的修复仍将向后移植至 2024 年 12 月 31 日。如果您仍在使用 JupyterLab 3,我们强烈建议您尽快升级到 JupyterLab 4。更多信息请参阅 Jupyter 博客上的 JupyterLab 3 维护结束。
您可以使用 pip 或 conda 安装 JupyterLab。
通过
pip:
# 如果需要 JupyterLab 3,请将 4.0 更改为 3.0
pip install jupyterlab~=4.0
通过
conda:
# 如果需要 JupyterLab 3,请将 4.0 更改为 3.0
conda config --add channels conda-forge
conda config --set channel_priority strict
conda install jupyterlab~=4.0
您还可以在 Jupyter Notebook 7.2+ 中使用 Jupyter AI。要安装 Jupyter Notebook 7.2:
通过
pip:
pip install notebook~=7.2
通过
conda:
conda install notebook~=7.2
Note
要在 Jupyter Notebook 中激活聊天界面,请点击“视图 > 左侧边栏 > 显示 Jupyter AI 聊天”。
jupyter_ai_magics 包仅提供 IPython 魔法功能,不依赖于 JupyterLab 或 jupyter_ai。您可以在不安装 jupyterlab 或 jupyter_ai 的情况下安装 jupyter_ai_magics。如果您同时安装了 jupyter_ai_magics 和 jupyter_ai,您应该确保两者的版本相同,以避免错误。
Jupyter AI 内部使用 Pydantic v1,并且应该与 Pydantic 版本 1 或版本 2 兼容。为了兼容性,使用 Pydantic V2 的开发者应使用 pydantic.v1 包导入类。有关开发者如何使用 v1 以避免在代码中混合使用 v1 和 v2 类的建议,请参阅 LangChain Pydantic 迁移计划。
安装#
通过 pip 安装#
要安装 JupyterLab 扩展,您可以运行:
pip install jupyter-ai
您可能需要安装第三方包,例如,为了使用某些模型提供者和某些文件格式与 Jupyter AI。要处理所有支持的使用场景,您可以安装所有依赖项,这将使您能够访问 jupyter-ai 当前支持的所有模型。要安装所有依赖项,请运行以下命令,然后重新启动 JupyterLab:
pip install jupyter-ai[all]
jupyter-ai 的最新主要版本 v2 仅支持 JupyterLab 4。如果您需要支持 JupyterLab 3,您应该安装 jupyter-ai v1 版本:
pip install jupyter-ai~=1.0
如果您不使用 JupyterLab,并且只想安装 Jupyter AI 的 %%ai 魔法功能,您可以运行:
$ pip install jupyter-ai-magics
jupyter-ai 依赖于 jupyter-ai-magics,因此安装 jupyter-ai 会自动安装 jupyter-ai-magics。
通过 pip 或 conda 在 Conda 环境中安装(推荐)#
我们强烈建议在独立的 Conda 环境中安装 JupyterLab 和 Jupyter AI,以避免覆盖您现有 Python 环境中的 Python 包。
首先,安装 conda 并创建一个使用 Python 3.12 的环境:
$ conda create -n jupyter-ai python=3.12
$ conda activate jupyter-ai
然后,使用 conda 在此 Conda 环境中安装 JupyterLab 和 Jupyter AI。
$ conda install -c conda-forge jupyter-ai # 或者,
$ conda install conda-forge::jupyter-ai
在启动带有 Jupyter AI 的 JupyterLab 时,请确保首先激活 Conda 环境:
conda activate jupyter-ai
jupyter lab
卸载#
如果您使用 pip 安装了 Jupyter AI,要移除扩展,请运行:
$ pip uninstall jupyter-ai
或者
$ pip uninstall jupyter-ai-magics
如果您使用 conda 安装了 Jupyter AI,您可以通过运行以下命令移除它:
$ conda remove jupyter-ai
或者
$ conda remove jupyter-ai-magics
Jupyter AI 支持多种模型提供商和模型。要使用特定的提供商与 Jupyter AI,您必须安装其 Python 包并在您的环境中或聊天界面中设置其 API 密钥(或其他凭证)。
Jupyter AI 支持以下模型提供商:
提供商 |
提供商 ID |
环境变量 |
Python 包 |
|---|---|---|---|
AI21 |
|
|
|
Anthropic |
|
|
|
Anthropic (聊天) |
|
|
|
Bedrock |
|
N/A |
|
Bedrock (聊天) |
|
N/A |
|
Bedrock (自定义/预置) |
|
N/A |
|
Cohere |
|
|
|
ERNIE-Bot |
|
|
|
Gemini |
|
|
|
GPT4All |
|
N/A |
|
Hugging Face Hub |
|
|
|
MistralAI |
|
|
|
NVIDIA |
|
|
|
OpenAI |
|
|
|
OpenAI (聊天) |
|
|
|
SageMaker 端点 |
|
N/A |
|
上述环境变量名称也是设置聊天界面时使用的设置键名称。如果为某个提供商列出了多个变量,则所有变量都必须指定。
要使用 Bedrock 模型,您需要访问 Bedrock 服务,并且需要通过 boto3 进行身份验证。更多信息请参见 Amazon Bedrock 主页。
您需要 pillow Python 包来使用 Hugging Face Hub 的文本到图像模型。
您可以在 https://huggingface.co/models 找到 Hugging Face 的模型列表。
要使用 NVIDIA 模型,请在 NVIDIA NGC 服务 上创建一个免费账户,该服务托管 AI 解决方案目录、容器、模型等。导航到目录 > AI 基础模型,并选择一个带有 API 端点的模型。点击模型详情页上的“API”,然后点击“生成密钥”。保存此密钥,并将其设置为环境变量 NVIDIA_API_KEY 以访问任何模型端点。
SageMaker 端点名称是在您部署模型时创建的。更多信息请参见 SageMaker 文档中的 “创建您的端点并部署您的模型”。
要使用 SageMaker 的模型,您需要通过 boto3 进行身份验证。
例如,要使用 OpenAI 模型,请使用聊天界面设置面板选择 OpenAI 语言模型:
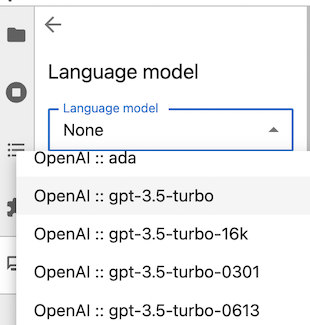
然后,在“API 密钥”部分输入您的 API 密钥。
Attention
模型提供商可能会向用户收取 API 使用费用。Jupyter AI 用户需对其发起的 API 请求所产生的所有费用负责。在使用 Jupyter AI 提交请求之前,请查看您的模型提供商的定价信息。
聊天界面#
开始使用 Jupyter AI 的最简单方法是使用聊天界面。
Attention
聊天界面将数据发送给由第三方托管的生成式AI模型。请查看您的模型提供商的隐私政策,以了解它可能如何使用您发送给它的数据。查看其定价模型,以便您了解在使用聊天界面时的付款义务。
启动JupyterLab后,点击左侧边栏中的新“聊天”图标以打开聊天界面。如果您愿意,可以右键点击面板图标并将其移动到另一侧。
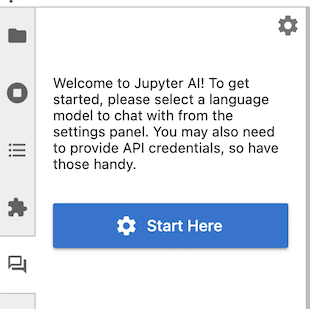
首次打开聊天界面时,Jupyter AI会询问您希望使用哪种模型作为语言模型和嵌入模型。一旦您做出选择,界面可能会显示一个或多个设置键的文本框。
语言模型和嵌入模型
用户可以选择一个语言模型,并可选地选择一个嵌入模型。您应该选择其中一个,以便能够使用聊天界面的全部功能。
语言模型 在聊天面板中响应用户的留言。它接受一个提示并生成一个响应。语言模型通常是预训练的;它们可以直接使用,但它们的训练集存在偏见和不完整,用户在使用聊天界面时需要意识到这些偏见。
嵌入模型 在学习和询问本地数据时使用。这些模型可以将您的数据(包括文档和源代码文件)转换为向量,这些向量可以帮助Jupyter AI构建提示以供语言模型使用。
您的语言模型和嵌入模型不需要由同一家供应商提供,但您需要为每个使用的模型提供商提供身份验证凭据。
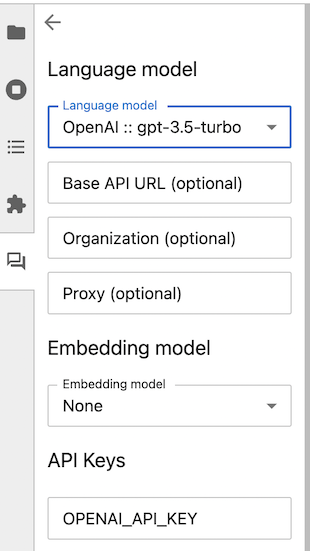
在使用聊天界面之前,您需要为您选择的模型提供商提供API密钥。将您的密钥粘贴或输入到提供的框中。
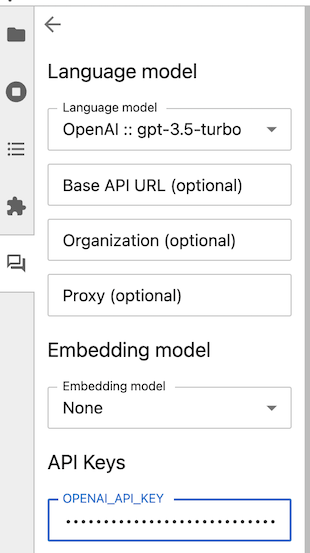
一旦设置了所有必要的密钥,点击Jupyter AI侧边栏左上角的“返回”(左箭头)按钮。聊天界面现在出现,并附带可用的/(斜杠)命令的帮助菜单,您可以使用底部的消息框提问。
![]()
您可以从默认模板自定义聊天界面的模板。步骤如下:
在当前目录中创建一个新的
config.py文件,内容为您希望在帮助消息中看到的内容,通过编辑以下模板:
c.AiExtension.help_message_template = """
Sup. I'm {persona_name}. 这是一个自定义的帮助消息。
以下是您可以使用的斜杠命令。用不用...我不在乎。
{slash_commands_list}
""".strip()
使用以下命令启动JupyterLab:
jupyter lab --config=config.py
新的帮助消息将代替默认消息使用,如下所示
![]()
要撰写消息,请在聊天界面底部的文本框中输入内容,然后按ENTER发送。您可以按SHIFT+ENTER添加新行。(这些是默认的键绑定;您可以在聊天设置面板中更改它们。)一旦发送消息,您应该会看到Jupyternaut(Jupyter AI聊天机器人)的响应。
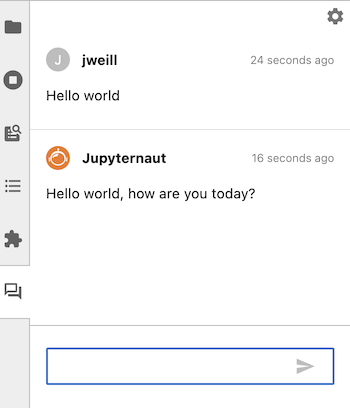
聊天后端会记住您对话中的最后两次交流,并将它们传递给语言模型。您可以提出后续问题,而无需重复之前的对话信息。以下是一个带有后续问题的聊天对话示例:
初始问题#
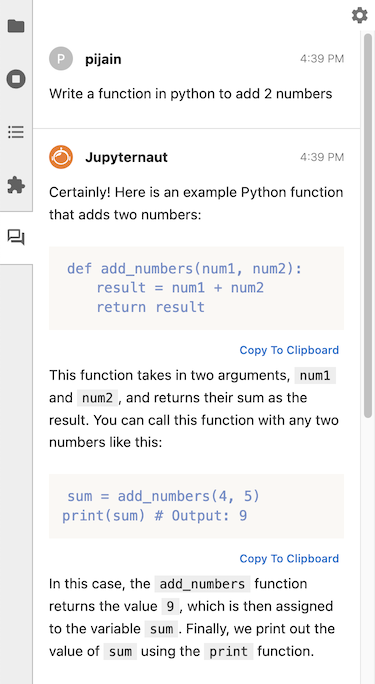
后续问题#
Amazon Bedrock 使用#
Jupyter AI 支持在 AWS 上使用托管于 Amazon Bedrock 的语言模型。首先,请确保您已通过 boto3 SDK 使用存储在 default 配置文件中的凭证进行 AWS 身份验证。有关如何进行此操作的指导,请参阅 boto3 文档。
如需更详细的流程,请参阅 使用 Amazon Bedrock 与 Jupyter AI。
Bedrock 支持多家语言模型提供商,如 AI21 Labs、Amazon、Anthropic、Cohere、Meta 和 Mistral AI。要使用任何受支持提供商的基础模型,请确保在 Amazon Bedrock 中启用它们,这可以通过 AWS 控制台完成。如果您打算在文档上使用检索增强生成(RAG),还应在 Bedrock 中选择嵌入模型以及语言补全模型。
现在,您可以从聊天界面中的 Completion model 下拉菜单中选择一个 Bedrock 模型。如果将使用 RAG,则同样从 Bedrock 模型中选择一个嵌入模型。以下是这些选择的示例:
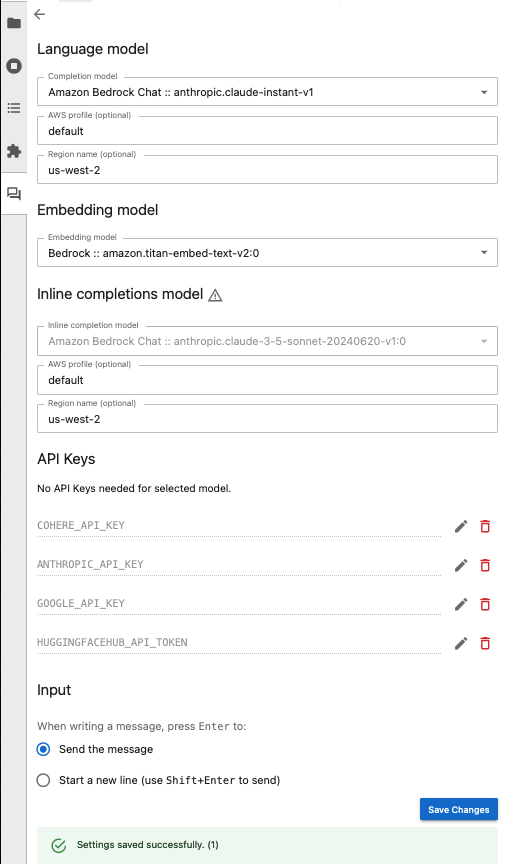
如果您的提供商需要 API 密钥,请在相应提供商的输入框中输入。确保点击 Save Changes 以确保输入内容已保存。
Bedrock 还允许从头开始训练自定义模型或从基础模型进行微调。Jupyter AI 支持在聊天面板中使用其 arn(Amazon 资源名称)调用自定义模型。界面如下所示:
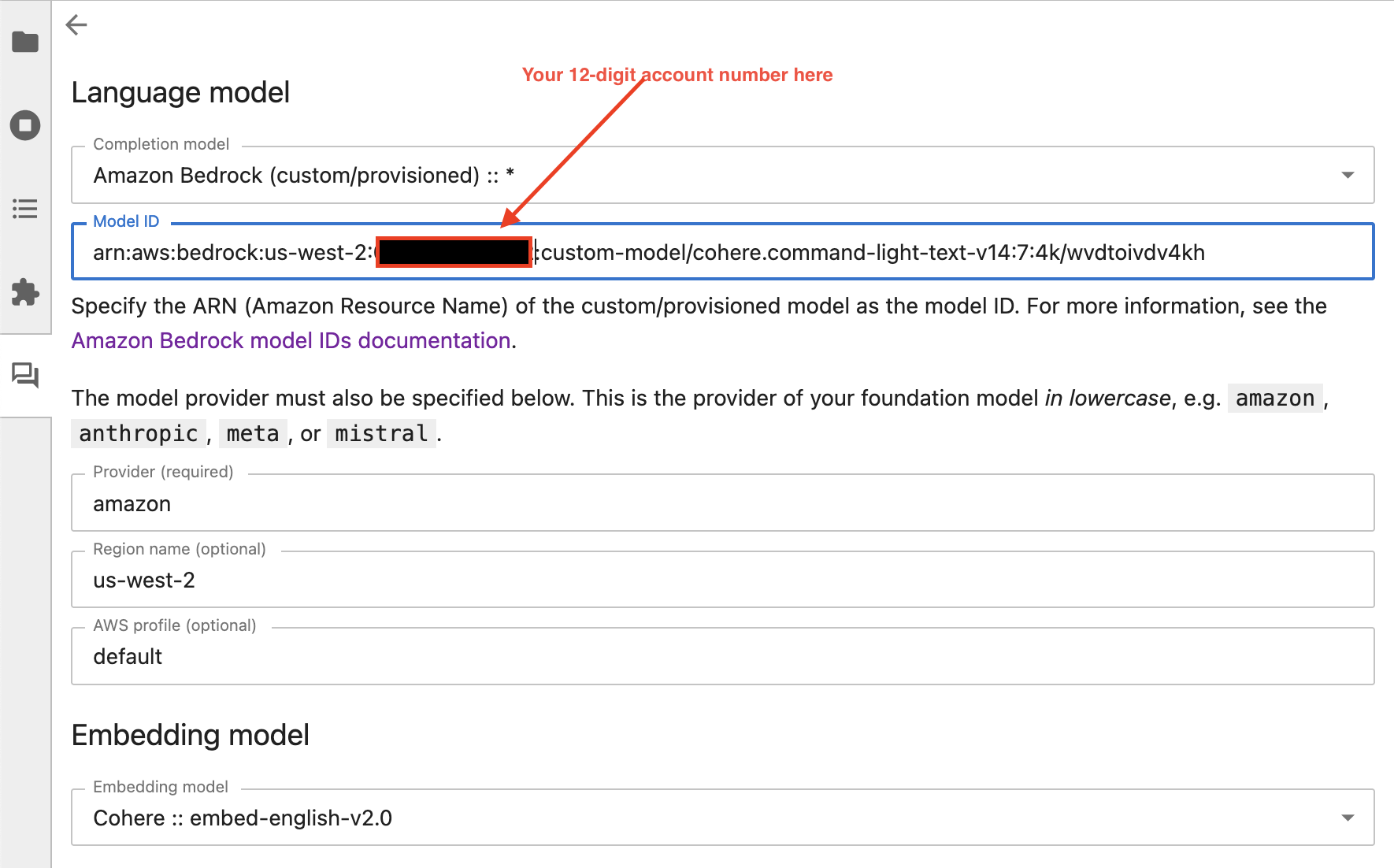
如需详细流程,请参阅 使用 Amazon Bedrock 与 Jupyter AI。
SageMaker 端点使用#
Jupyter AI 支持使用 JSON 模式的 SageMaker 端点托管的语言模型。第一步是通过 boto3 SDK 进行 AWS 身份验证,并将凭证存储在 default 配置文件中。有关如何进行此操作的指导,请参阅 boto3 文档。
在设置面板中选择 SageMaker 提供商时,您将看到以下界面:
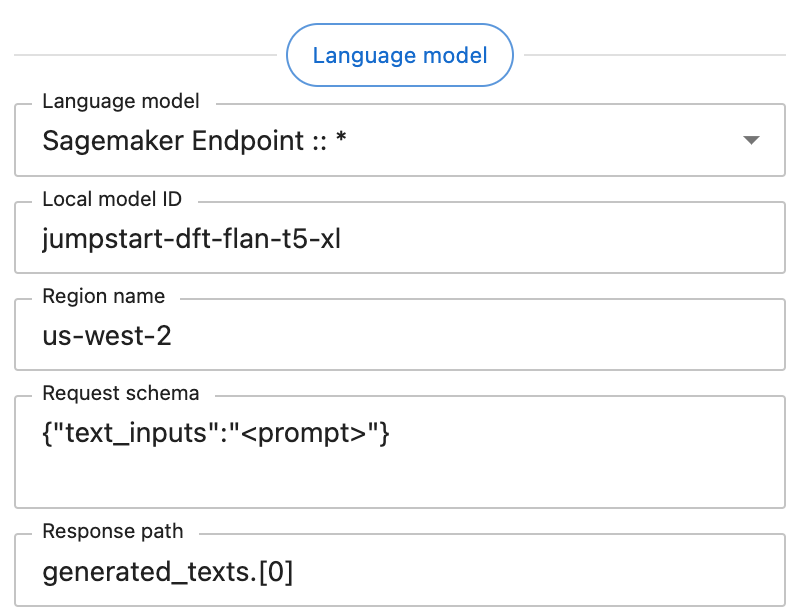
“Language model”下的每个附加字段都是必需的。这些字段应包含以下数据:
Endpoint name: 您的端点名称。可以从以下 URL 在 AWS 控制台中检索:
https://<region>.console.aws.amazon.com/sagemaker/home?region=<region>#/endpoints。Region name: SageMaker 端点所在的 AWS 区域,例如
us-west-2。Request schema: 端点期望的 JSON 对象,提示将替换为与字符串字面量
"<prompt>"匹配的任何值。在此示例中,请求模式{"text_inputs":"<prompt>"}生成一个 JSON 对象,提示存储在text_inputs键下。Response path: 一个 JSONPath 字符串,用于从端点的 JSON 响应中检索语言模型的输出。在此示例中,端点返回一个具有模式
{"generated_texts":["<output>"]}的对象,因此响应路径为generated_texts.[0]。
GPT4All 使用(早期阶段)#
目前,我们提供对 GPT4All 的实验性支持。首先,决定您将使用哪些模型。我们目前提供以下 GPT4All 模型:
模型名称 |
模型大小 |
模型 bin URL |
|---|---|---|
|
7.6 GB |
|
|
3.8 GB |
|
|
3.8 GB |
|
|
3.8 GB |
|
|
3.8 GB |
|
|
3.9 GB |
|
|
6.9 GB |
|
|
6.9 GB |
|
|
6.9 GB |
|
|
3.5 GB |
|
|
1.8 GB |
|
|
8.4 GB |
|
|
3.6 GB |
|
|
44 MB |
|
|
3.8 GB |
|
请注意,每个模型都有其自己的许可证,用户有责任自行验证其使用是否符合许可证要求。您可以在GPT4All官方网站上找到许可证详情。
首先,创建一个文件夹来存储模型文件。
mkdir ~/.cache/gpt4all
对于您使用的每个模型,您都需要运行以下命令
curl -LO --output-dir ~/.cache/gpt4all "<model-bin-url>"
,其中<model-bin-url>应替换为托管模型二进制文件的相应URL(在双引号内)。重启服务器后,上一步中安装的GPT4All模型应该可以在聊天界面中使用。
GPT4All支持仍处于早期阶段,因此在使用过程中可能会遇到一些错误。我们的团队仍在积极改进对本地托管模型的支持。
Ollama 使用#
要开始使用,请按照Ollama网站上的说明设置ollama并在本地下载模型。要选择一个模型,请在设置面板中输入模型名称,例如deepseek-coder-v2。
询问笔记本中的内容#
Jupyter AI的聊天界面可以在您的提示中包含笔记本的一部分内容。
Warning
当您选择在消息中包含所选内容时,这可能会增加请求中的令牌数量,从而可能导致请求成本增加。在发出大型请求之前,请查看您的模型提供商的成本政策。
在突出显示笔记本的一部分后,在聊天面板中勾选“包含所选内容”,输入您的消息,然后发送消息。您的传出消息将包含您的所选内容。
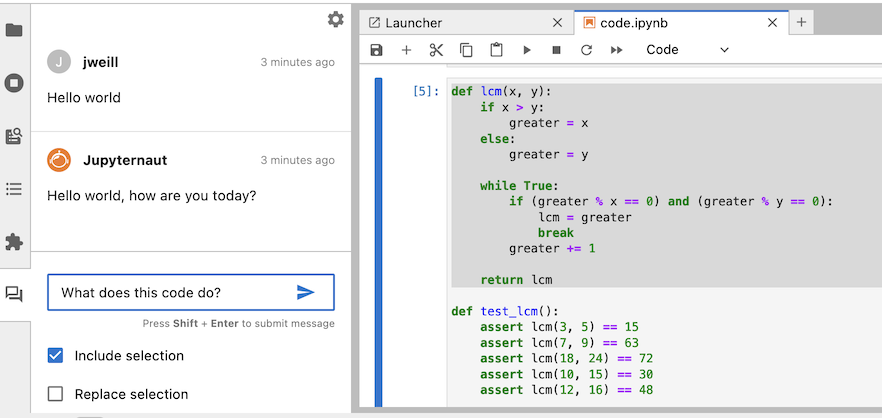
在您的消息下方,您将看到Jupyternaut的回复。
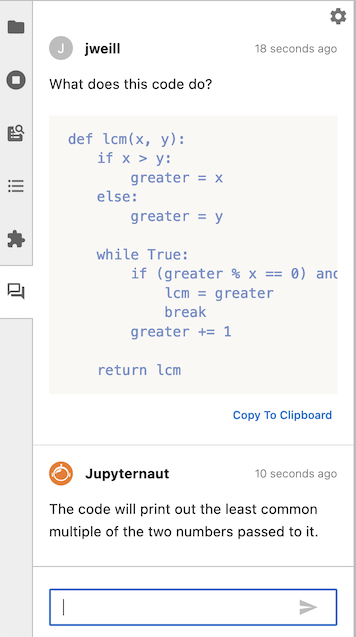
您可以将Jupyternaut的回复复制到剪贴板,以便将其粘贴到笔记本或其他任何应用程序中。您还可以在发送消息之前点击“替换所选内容”,选择用Jupyternaut的回复替换所选内容。
Warning
当您替换所选内容时,数据会在Jupyter AI发送对您消息的回复后立即写入。在运行任何生成的代码之前,请仔细检查。
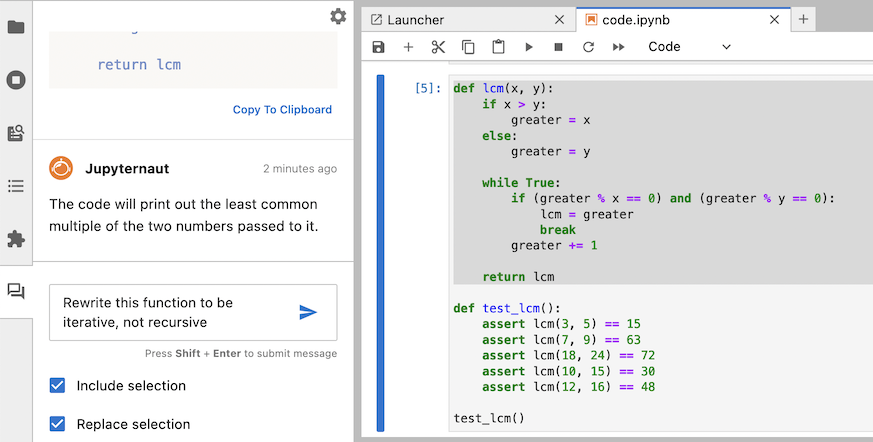
Jupyternaut发送回复后,您的笔记本将立即更新,所选内容将被替换为回复。您也可以在聊天面板中看到回复。
生成新笔记本#
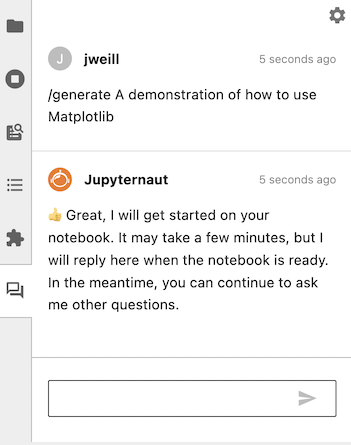
您可以使用Jupyter AI根据文本提示生成整个笔记本。要开始,请打开聊天面板,并发送以/generate开头的消息。
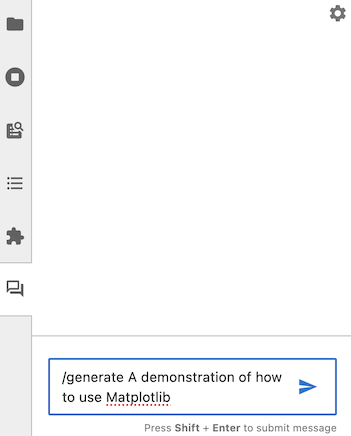
生成笔记本可能需要相当长的时间,因此Jupyter AI会立即回复您的消息,同时继续工作。在此期间,您可以继续向它提出其他问题。
 class=”screenshot” />
class=”screenshot” />
Note
特别是如果你的提示很详细,生成你的笔记本可能需要几分钟时间。在此期间,你仍然可以像往常一样使用 JupyterLab 和 Jupyter AI。在 Jupyter AI 工作时,请不要关闭你的 JupyterLab 实例。
当 Jupyter AI 完成生成你的笔记本后,它会向你发送另一条消息,其中包含它生成的文件名。然后你可以使用文件浏览器打开这个文件。
Warning
生成的笔记本可能包含错误,并且在运行其中包含的代码时可能会产生意外的副作用。请在运行之前仔细检查所有生成的代码。
学习本地数据#
使用 /learn 命令,你可以教 Jupyter AI 关于本地数据的知识,以便 Jupyternaut 在回答你的问题时可以包含这些数据。这些本地数据使用你在设置面板中选择的嵌入模型进行嵌入。
Warning
如果你使用的是第三方托管的嵌入模型,请在向嵌入模型发送任何机密、敏感或特权数据之前,查看你的模型提供商的政策。
例如,要教 Jupyter AI 关于一个充满文档的文件夹,可以运行 /learn docs/。当 Jupyter AI 在本地向量数据库中索引这些文档时,你会收到一个响应。
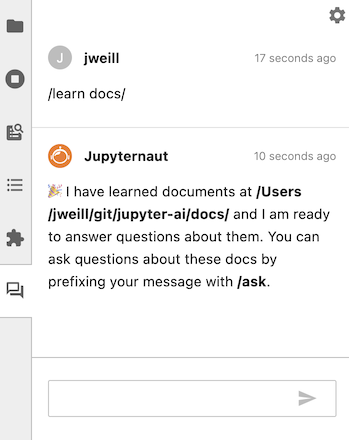
/learn 命令还支持 Unix shell 风格的通配符匹配。这允许对学习进行细粒度的文件选择。例如,要仅学习所有目录中的笔记本,可以使用 /learn **/*.ipynb,你的基础(或首选目录,如果已设置)中的所有笔记本都将被索引,而其他文件扩展名将被忽略。
Warning
某些模式可能会导致 /learn 运行得更慢。例如,/learn ** 可能会导致多次遍历目录以搜索文件。
然后你可以使用 /ask 来专门询问你用 /learn 教给 Jupyter AI 的数据。
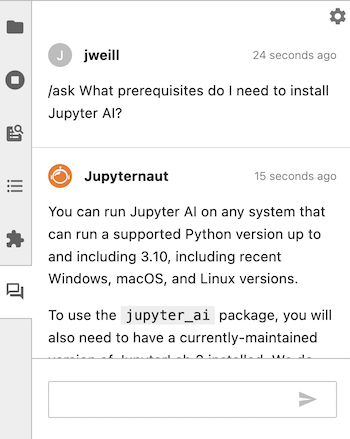
要清除本地向量数据库,可以运行 /learn -d,Jupyter AI 将忘记从你的 /learn 命令中学到的所有信息。
使用 /learn 命令时,某些模型在自定义块大小和块重叠值下工作得更好。要覆盖默认值,请使用 -c 或 --chunk-size 选项以及 -o 或 --chunk-overlap 选项。
# 默认块大小和块重叠
/learn <directory>
# 块大小为 500,块重叠为 50
/learn -c 500 -o 50 <directory>
# 块大小为 1000,块重叠为 200
/learn --chunk-size 1000 --chunk-overlap 200 <directory>
默认情况下,/learn 不会读取名为 node_modules、lib 或 build 的目录,也不会读取隐藏文件或隐藏目录,其中文件或目录名称以 . 开头。要强制 /learn 读取所有目录中的所有支持文件类型,请使用 -a 或 --all-files 选项。
# 不从隐藏文件、隐藏目录或 node_modules、lib、build 目录中学习
/learn <directory>
# 从所有支持的文件中学习
/learn -a <directory>
支持的文件类型#
Jupyter AI 只能从具有以下文件扩展名的文件中学习:
.py
.md
.R
.Rmd
.jl
.sh
.ipynb
.js
.ts
.jsx
.tsx
.txt
.html
.pdf
.tex
学习 arXiv 文件#
/learn 命令还提供了从 arXiv 仓库下载和处理论文的功能。你需要安装 arxiv Python 包才能使用此功能。运行 pip install arxiv 来安装 arxiv 包。
/learn -r arxiv 2404.18558
导出聊天记录#
使用 /export 命令将当前会话的聊天记录导出到一个名为 chat_history-YYYY-MM-DD-HH-mm-ss.md 的 Markdown 文件中。你也可以使用 /export <file_name> 指定文件名。每次导出都将包含会话中到该点的所有聊天记录。
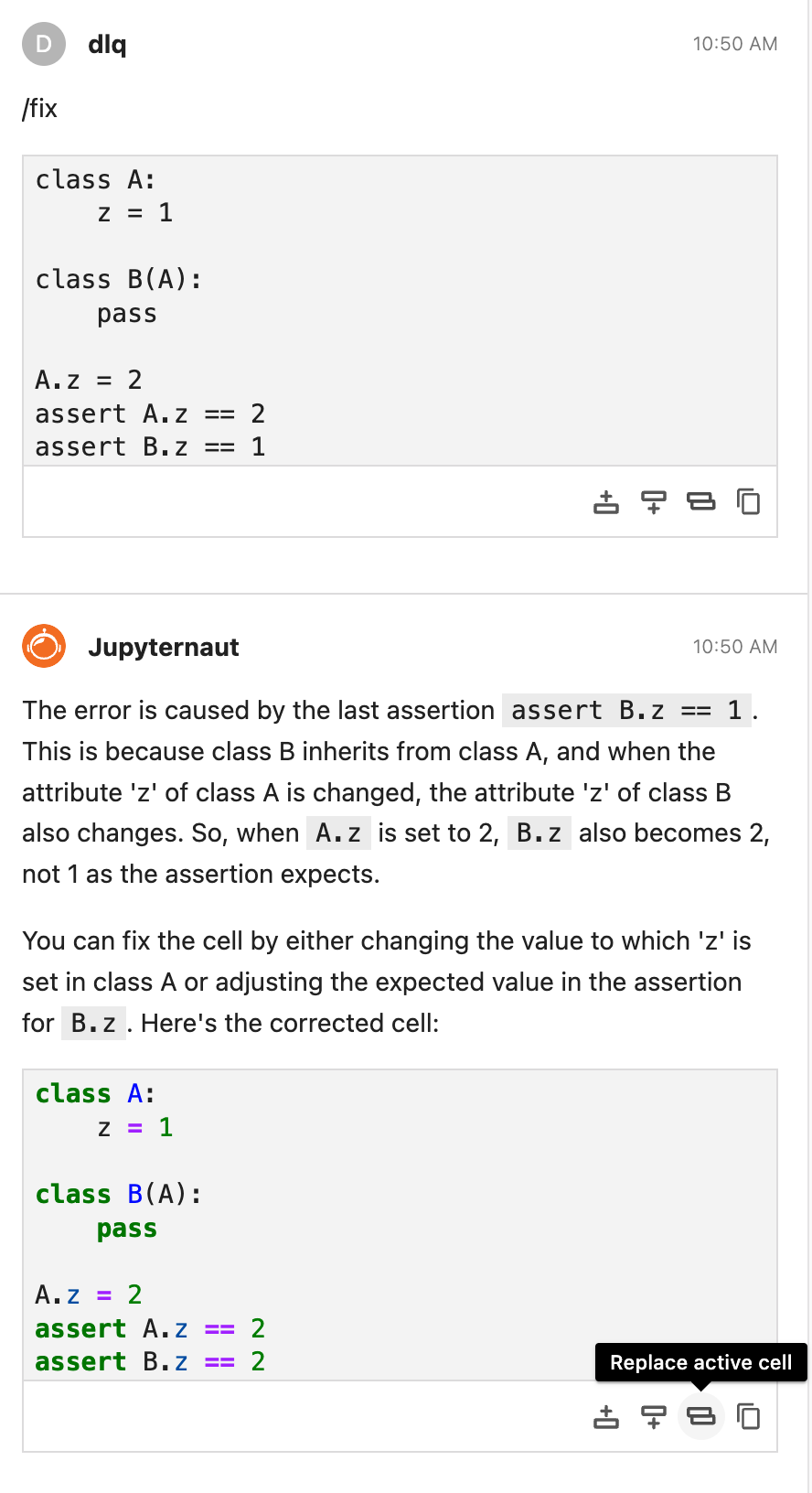
修复带有错误的代码单元格#
/fix 命令可用于修复 Jupyter 笔记本文件中带有错误输出的任何代码单元格。首先,在聊天输入中输入 /fix。然后 Jupyter AI 会提示你选择一个带有错误输出的单元格,然后再发送请求。

然后点击一个带有错误输出的代码单元格。一个蓝色条应立即出现在代码单元格的左侧。

在此之后,聊天输入框右侧的“发送”按钮将被启用,您可以使用鼠标或键盘向 Jupyternaut 发送 /fix。代码单元格及其关联的错误输出将自动包含在消息中。完成后,Jupyternaut 将回复建议的代码,该代码应修复错误。您可以使用每个代码块下方的操作工具栏快速替换失败的单元格内容。
其他聊天命令#
要开始新的对话,请使用 /clear 命令。这将清除聊天面板并重置模型的记忆。
%ai 和 %%ai 魔法命令#
Jupyter AI 也可以通过 Jupyter AI 魔法在笔记本中使用。本节提供了如何有效使用 Jupyter AI 魔法的指导。本节中的示例基于 Jupyter AI 示例笔记本。
如果您已经安装了 jupyter_ai,魔法包 jupyter_ai_magics 会自动安装。否则,请在终端中运行
pip install jupyter_ai_magics
来安装魔法包。
在向 AI 模型发送第一个提示之前,请通过在笔记本单元格或 IPython shell 中运行以下代码来加载 IPython 扩展:
%load_ext jupyter_ai_magics
此命令不应产生任何输出。
Note
如果您使用的是远程内核,例如在 Amazon SageMaker Studio 中,上述命令将抛出错误。您需要单独在远程内核上安装魔法包,即使您已经在服务器环境中安装了 jupyter_ai_magics。在笔记本中,运行
%pip install jupyter_ai_magics
并重新运行 %load_ext jupyter_ai_magics。
扩展加载后,您可以运行 %%ai 单元魔法命令和 %ai 行魔法命令。运行 %%ai help 或 %ai help 以获取语法帮助。您还可以将 --help 作为参数传递给任何行魔法命令(例如,%ai list --help)以了解命令的作用及其使用方法。
选择提供者和模型#
%%ai 单元魔法允许您使用给定的提示调用您选择的语言模型。模型通过 全局模型 ID 标识,这是一个具有语法 <provider-id>:<local-model-id> 的字符串,其中 <provider-id> 是提供者的 ID,<local-model-id> 是该提供者范围内的模型 ID。提示从单元格的第二行开始。
例如,要将文本提示发送到提供者 anthropic 和模型 ID claude-v1.2,请将以下代码输入单元格并运行它:
%%ai anthropic:claude-v1.2
写一首关于 C++ 的诗。
我们目前支持以下语言模型提供者:
ai21anthropicanthropic-chatbedrockbedrock-chatbedrock-customcoherehuggingface_hubnvidia-chatopenaiopenai-chatsagemaker-endpoint
配置默认模型#
要配置默认模型,您可以使用 IPython 的 %config 魔法:
%config AiMagics.default_language_model = "anthropic:claude-v1.2"
然后,后续的魔法可以在不输入模型的情况下调用:
%%ai
写一首关于 C++ 的诗。
您可以通过在 ipython_config.py 中指定 c.AiMagics.default_language_model 来为所有笔记本配置默认模型,例如:
c.AiMagics.default_language_model = "anthropic:claude-v1.2"
ipython_config.py 文件的位置记录在 IPython 配置参考 中。
列出可用模型#
Jupyter AI 还包括多个子命令,可以通过 %ai 行 魔法调用。Jupyter AI 使用子命令在保持调用语言模型的简洁语法的同时,在笔记本中提供额外的实用工具。
%ai list 子命令打印可用提供者和模型的列表。一些提供者在他们的 API 中明确列出了支持的模型。然而,其他提供者,如 Hugging Face Hub,缺乏定义明确的可用模型列表。在这种情况下,最好查阅提供者的上游文档。例如,Hugging Face 网站 包含模型列表。
您可以选择性地将提供者 ID 作为 %ai list 的位置参数,以获取一个提供者提供的所有模型。例如,%ai list openai 将仅显示 openai 提供者提供的模型。
缩写语法#
如果您的模型 ID 仅与一个提供者关联,您可以省略 provider-id 和
从第一行的冒号开始。例如,因为 ai21 是 j2-jumbo-instruct 模型的唯一提供者,你可以给出完整的提供者和模型,
%%ai ai21:j2-jumbo-instruct
编写一些 JavaScript 代码,将 "hello world" 打印到控制台。
或者只给出模型,
%%ai j2-jumbo-instruct # 推断 AI21 提供者
编写一些 JavaScript 代码,将 "hello world" 打印到控制台。
格式化输出#
默认情况下,Jupyter AI 假设模型将输出 markdown,因此 %%ai 命令的输出将默认格式化为 markdown。你可以使用 -f 或 --format 参数来覆盖此设置。有效的格式包括:
codeimage(仅适用于 Hugging Face Hub 的文本到图像模型)markdownmathhtmljsontext
例如,要强制命令的输出被解释为 HTML,你可以运行:
%%ai anthropic:claude-v1.2 -f html
使用 SVG 创建一个带有黑色边框和白色填充的正方形。
以下单元格将生成 IPython 的 Math 格式输出,在网页浏览器中看起来像是正确排版的方程式。
%%ai chatgpt -f math
生成 LaTeX 中的二维热方程,并用 `$$` 包围。不要包含解释。
此提示将在输入单元格下方生成代码单元格输出。
Warning
请在运行或分发生成式 AI 模型生成的任何代码之前进行审查。 响应提示得到的代码可能会有负面副作用,并且可能包含对不存在的(幻觉)API 的调用。
%%ai chatgpt -f code
一个计算两个整数的最小公倍数的函数,以及一个运行最小公倍数函数的 5 个测试用例的函数
配置上下文中包含的历史记录量#
默认情况下,新的提示上下文中包含两个之前的 Human/AI 消息交换。你可以使用 IPython 的 %config 魔法来更改此设置,例如:
%config AiMagics.max_history = 4
请注意,旧消息仍然保留在本地内存中,因此在提高 max_history 值后,它们将被包含在下一个提示的上下文中。
你可以通过在 ipython_config.py 中指定 c.AiMagics.max_history traitlet 来为所有笔记本配置此值,例如:
c.AiMagics.max_history = 4
清除聊天历史记录#
你可以运行 %ai reset 行魔法命令来清除聊天历史记录。执行此操作后,之前运行的魔法命令将不再作为请求的上下文添加。
%ai reset
在提示中插入变量#
使用大括号语法,你可以在提示中包含变量和其他 Python 表达式。这使你可以使用 IPython 内核已知的代码执行提示,但这些代码不在当前单元格中。
例如,我们可以在一个笔记本单元格中设置一个变量:
poet = "Walt Whitman"
然后,我们可以在后面的单元格中使用相同的变量执行 %%ai 命令:
%%ai chatgpt
以 {poet} 的风格写一首诗
当此单元格运行时,{poet} 将被插值为 Walt Whitman,或者插值为 poet 在那时被赋的任何值。
你可以使用特殊的 In 和 Out 列表与插值语法来解释位于 Jupyter 笔记本其他位置的代码。例如,如果你在一个单元格中运行以下代码,并且其输入被分配给 In[11]:
for i in range(0, 5):
print(i)
然后你可以在 %%ai 魔法命令中引用 In[11],它将被替换为相关代码:
%%ai cohere:command-xlarge-nightly
请解释以下代码:
--
{In[11]}
你也可以使用特殊的 Out 列表,使用相同的索引引用单元格的输出。
%%ai cohere:command-xlarge-nightly
编写代码以生成以下输出:
--
{Out[11]}
Jupyter AI 还添加了特殊的 Err 列表,它使用与 In 和 Out 相同的索引。例如,如果你在 In[3] 中运行代码并产生错误,该错误将被捕获在 Err[3] 中,以便你可以使用如下提示请求解释:
%%ai chatgpt
解释以下 Python 错误:
--
{Err[3]}
你使用的 AI 模型将尝试解释该错误。你也可以编写一个提示,使用 In 和 Err 来尝试让 AI 模型纠正你的代码:
%%ai chatgpt --format code
以下 Python 代码:
--
{In[3]}
--
产生了以下 Python 错误:
--
{Err[3]}
--
编写一个不会产生该错误的新版本代码。
作为解释错误的快捷方式,你可以使用 %ai error 命令,它将使用你选择的模型解释最近的错误。
%ai error anthropic:claude-v1.2
创建和管理别名#
你可以使用 %ai register 命令为模型创建别名。例如,命令:
%ai register claude anthropic:claude-v1.2
将注册别名 claude,使其指向 anthropic 提供者的 claude-v1.2 模型。然后,您可以像使用其他模型名称一样使用此别名:
%%ai claude
写一首关于C++的诗。
您还可以定义一个自定义的 LangChain 链:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
… 然后使用 %ai register 为其命名:
%ai register companyname chain
您可以使用 %ai update 命令更改别名的目标:
%ai update claude anthropic:claude-instant-v1.0
您可以使用 %ai delete 命令删除别名:
%ai delete claude
您可以通过运行 %ai list 命令查看所有别名的列表。
别名的名称可以包含 ASCII 字母(大写和小写)、数字、连字符、下划线和句点。它们不能包含冒号。它们也不能覆盖内置命令 — 运行 %ai help 以获取这些命令的列表。
别名必须引用模型或 LLMChain 对象;它们不能引用其他别名。
要自定义启动时的别名,您可以在 ipython_config.py 中设置 c.AiMagics.aliases 属性,例如:
c.AiMagics.aliases = {
"my_custom_alias": "my_provider:my_model"
}
ipython_config.py 文件的位置记录在 IPython 配置参考 中。
使用 SageMaker 端点与魔法命令#
您可以使用魔法命令与使用 Amazon SageMaker 托管的模型。
首先,确保在启动 JupyterLab 之前或在 JupyterLab 中使用 %env 魔法命令设置了 AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY 环境变量。有关环境变量的更多信息,请参阅 AWS 文档中的 配置 AWS CLI 的环境变量。
Jupyter AI 支持使用 JSON 模式的 SageMaker 端点托管的语言模型。通过 boto3 SDK 与 AWS 进行身份验证,并将凭据存储在 default 配置文件中。有关如何执行此操作的指导可以在 boto3 文档 中找到。
您需要在 SageMaker 中部署一个模型,然后将其作为模型名称提供(如 sagemaker-endpoint:my-model-name)。请参阅 如何部署 JumpStart 模型的文档。
所有 SageMaker 端点请求都需要您指定 --region-name、--request-schema 和 --response-path 选项。下面的示例假设您已部署了一个名为 jumpstart-dft-hf-text2text-flan-t5-xl 的模型。
%%ai sagemaker-endpoint:jumpstart-dft-hf-text2text-flan-t5-xl --region-name=us-east-1 --request-schema={"text_inputs":"<prompt>"} --response-path=generated_texts.[0] -f code
Write Python code to print "Hello world"
--region-name 参数设置为模型部署的 AWS 区域代码,在本例中为 us-east-1。
--request-schema 参数是端点期望作为输入的 JSON 对象,其中提示将被替换为任何匹配字符串字面量 "<prompt>" 的值。例如,请求模式 {"text_inputs":"<prompt>"} 将提交一个 JSON 对象,提示存储在 text_inputs 键下。
--response-path 选项是一个 JSONPath 字符串,用于从端点的 JSON 响应中检索语言模型的输出。例如,如果您的端点返回一个模式为 {"generated_texts":["<output>"]} 的对象,其响应路径为 generated_texts.[0]。
配置#
您可以指定一个允许列表,仅允许特定列表中的提供者,或指定一个阻止列表,以阻止某些提供者。
配置默认模型和 API 密钥#
此配置允许设置默认的语言和嵌入模型及其对应的 API 密钥。这些值为用户提供了一个起点,因此他们不必选择模型和 API 密钥,但是,他们在设置面板中选择的值将优先于这些值。
指定默认语言模型
jupyter lab --AiExtension.default_language_model=bedrock-chat:anthropic.claude-v2
指定默认嵌入模型
jupyter lab --AiExtension.default_embeddings_model=bedrock:amazon.titan-embed-text-v1
指定默认 API 密钥
jupyter lab --AiExtension.default_api_keys={'OPENAI_API_KEY': 'sk-abcd'}
此配置允许在设置面板中屏蔽特定的提供商。 此列表优先于下一节中的允许列表。
jupyter lab --AiExtension.blocked_providers=openai
要在阻止列表中阻止多个提供商,请重复运行时配置。
jupyter lab --AiExtension.blocked_providers=openai --AiExtension.blocked_providers=ai21
允许列表提供商#
此配置允许在设置面板中过滤提供商列表,仅限于允许列表中的一组提供商。
jupyter lab --AiExtension.allowed_providers=openai
要在允许列表中允许多个提供商,请重复运行时配置。
jupyter lab --AiExtension.allowed_providers=openai --AiExtension.allowed_providers=ai21
聊天记忆大小#
此配置允许设置模型在生成响应时用作上下文的聊天交流次数。
一次聊天交流对应于用户查询消息及其AI响应,这算作两条消息。 k表示一次聊天交流,即两条消息。 k的默认值为2,对应于4条消息。
例如,如果我们希望默认记忆为4次交流,则在启动Jupyter Lab时使用以下命令行调用:
jupyter lab --AiExtension.default_max_chat_history=4
模型参数#
此配置允许指定任意参数,这些参数会被解包并传递给提供商类。这对于传递影响模型响应生成的参数(如模型调整)非常有用。这也是传递某些提供商/模型所需的定制属性的合适位置。
接受的值是一个字典,顶级键为模型ID(provider:model_id),值应为任意字典,该字典会被解包并按原样传递给提供商类。
作为启动选项配置#
在此示例中,当选择ai21.j2-mid-v1模型时,bedrock提供商将使用model_kwargs的值创建。
jupyter lab --AiExtension.model_parameters bedrock:ai21.j2-mid-v1='{"model_kwargs":{"maxTokens":200}}'
注意使用单引号包围字典以转义双引号。这在某些shell中是必需的。上述操作将生成以下LLM类。
BedrockProvider(model_kwargs={"maxTokens":200}, ...)
以下是另一个示例,当选择claude-2模型时,anthropic提供商将使用max_tokens和temperature的值创建。
jupyter lab --AiExtension.model_parameters anthropic:claude-2='{"max_tokens":1024,"temperature":0.9}'
上述操作将生成以下LLM类。
AnthropicProvider(max_tokens=1024, temperature=0.9, ...)
要在命令行中为多个模型传递多组模型参数,可以将它们作为--AiExtension.model_parameters的附加参数追加,如下所示。
jupyter lab \
--AiExtension.model_parameters bedrock:ai21.j2-mid-v1='{"model_kwargs":{"maxTokens":200}}' \
--AiExtension.model_parameters anthropic:claude-2='{"max_tokens":1024,"temperature":0.9}'
然而,对于更复杂的配置,我们强烈建议您在专用配置文件中指定。我们将在下一节中描述如何操作。
作为配置文件配置#
此配置也可以在json格式的配置文件中指定。
以下是配置bedrock提供商为ai21.j2-mid-v1模型的示例。
{
"AiExtension": {
"model_parameters": {
"bedrock:ai21.j2-mid-v1": {
"model_kwargs": {
"maxTokens": 200
}
}
}
}
}
有几种方法可以让JupyterLab选择此配置。
第一种选择是将此配置保存在文件中,并在启动时使用--config或-c选项指定文件路径。
jupyter lab --config <config-file-path>
第二种选择是将配置文件放在JupyterLab扫描配置文件的位置。在这种情况下,文件应命名为jupyter_jupyter_ai_config.json。您可以通过运行jupyter --paths命令找到这些路径,并从config部分选择一个路径。
以下是运行jupyter --paths命令的示例。
(jupyter-ai-lab4) ➜ jupyter --paths
config:
/opt/anaconda3/envs/jupyter-ai-lab4/etc/jupyter
/Users/3coins/.jupyter
/Users/3coins/.local/etc/jupyter
/usr/3coins/etc/jupyter
/etc/jupyter
data:
/opt/anaconda3/envs/jupyter-ai-lab4/share/jupyter
/Users/3coins/Library/Jupyter
/Users/3coins/.local/share/jupyter
/usr/local/share/jupyter
/usr/share/jupyter
runtime:
/Users/3coins/Library/Jupyter/runtime