自动语音识别使用CTC
作者: Mohamed Reda Bouadjenek 和 Ngoc Dung Huynh
创建日期: 2021/09/26
最后修改日期: 2021/09/26
描述: 训练一个基于CTC的自动语音识别模型。

介绍
语音识别是计算机科学和计算语言学的一个跨学科子领域,开发使计算机能够识别和翻译口语为文本的方法和技术。它也被称为自动语音识别(ASR),计算机语音识别或语音转文本(STT)。它结合了计算机科学、语言学和计算机工程领域的知识和研究。
本演示展示了如何结合2D CNN、RNN和连接主义时序分类(CTC)损失来构建ASR。CTC是一种用于训练深度神经网络的算法,适用于语音识别、手写识别和其他序列问题。当我们不知道输入如何与输出对齐(转录中的字符如何与音频对齐)时,会使用CTC。我们创建的模型类似于 DeepSpeech2。
我们将使用来自 LibriVox 项目的LJSpeech数据集。它由一个讲者朗读7本非小说书籍的短音频片段组成。
我们将使用词错误率(WER)来评估模型的质量。WER是通过统计识别单词序列中发生的替换、插入和删除的数量来计算的。将该数字除以原始所说单词的总数,结果即为WER。要获取WER评分,您需要安装 jiwer包。您可以使用以下命令行:
pip install jiwer
参考文献:
设置
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
from IPython import display
from jiwer import wer
加载LJSpeech数据集
让我们下载LJSpeech 数据集。该数据集包含13,100个音频文件,格式为wav,存储在/wavs/文件夹中。每个音频文件的标签(转录)是存储在metadata.csv文件中的字符串。字段如下:
- ID:对应的.way文件的名称
- 转录:阅读者所说的单词(UTF-8)
- 标准化转录:将数字、序数和货币单位扩展为完整单词的转录(UTF-8)。
在本演示中,我们将使用“标准化转录”字段。
每个音频文件都是单声道16位PCM WAV,采样率为22,050 Hz。
data_url = "https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2"
data_path = keras.utils.get_file("LJSpeech-1.1", data_url, untar=True)
wavs_path = data_path + "/wavs/"
metadata_path = data_path + "/metadata.csv"
# 读取元数据文件并解析
metadata_df = pd.read_csv(metadata_path, sep="|", header=None, quoting=3)
metadata_df.columns = ["file_name", "transcription", "normalized_transcription"]
metadata_df = metadata_df[["file_name", "normalized_transcription"]]
metadata_df = metadata_df.sample(frac=1).reset_index(drop=True)
metadata_df.head(3)
| file_name | normalized_transcription | |
|---|---|---|
| 0 | LJ029-0199 | On November eighteen the Dallas City Council a... |
| 1 | LJ028-0237 | with orders to march into the town by the bed ... |
| 2 | LJ009-0116 | On the following day the capital convicts, who... |
我们现在将数据拆分为训练集和验证集。
split = int(len(metadata_df) * 0.90)
df_train = metadata_df[:split]
df_val = metadata_df[split:]
print(f"训练集的大小: {len(df_train)}")
print(f"验证集的大小: {len(df_val)}")
训练集的大小: 11790
验证集的大小: 1310
预处理
我们首先准备要使用的词汇表。
# 转录中接受的字符集。
characters = [x for x in "abcdefghijklmnopqrstuvwxyz'?! "]
# 字符映射到整数
char_to_num = keras.layers.StringLookup(vocabulary=characters, oov_token="")
# 将整数映射回原始字符
num_to_char = keras.layers.StringLookup(
vocabulary=char_to_num.get_vocabulary(), oov_token="", invert=True
)
print(
f"词汇表为: {char_to_num.get_vocabulary()} "
f"(大小 ={char_to_num.vocabulary_size()})"
)
词汇表为: ['', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'", '?', '!', ' '] (大小 =31)
接下来,我们创建描述对数据集每个元素应用的转换的函数。
# 一个整数标量张量。窗口长度(以样本为单位)。
frame_length = 256
# 一个整数标量张量。步进样本的数量。
frame_step = 160
# 一个整数标量张量。要应用的FFT大小。
# 如果未提供,则使用包含frame_length的最小2的幂。
fft_length = 384
def encode_single_sample(wav_file, label):
###########################################
## 处理音频
##########################################
# 1. 读取wav文件
file = tf.io.read_file(wavs_path + wav_file + ".wav")
# 2. 解码wav文件
audio, _ = tf.audio.decode_wav(file)
audio = tf.squeeze(audio, axis=-1)
# 3. 更改类型为浮点数
audio = tf.cast(audio, tf.float32)
# 4. 获取声谱图
spectrogram = tf.signal.stft(
audio, frame_length=frame_length, frame_step=frame_step, fft_length=fft_length
)
# 5. 我们只需要幅度,可以通过应用tf.abs获得
spectrogram = tf.abs(spectrogram)
spectrogram = tf.math.pow(spectrogram, 0.5)
# 6. 归一化
means = tf.math.reduce_mean(spectrogram, 1, keepdims=True)
stddevs = tf.math.reduce_std(spectrogram, 1, keepdims=True)
spectrogram = (spectrogram - means) / (stddevs + 1e-10)
###########################################
## 处理标签
##########################################
# 7. 将标签转换为小写
label = tf.strings.lower(label)
# 8. 拆分标签
label = tf.strings.unicode_split(label, input_encoding="UTF-8")
# 9. 将标签中的字符映射到数字
label = char_to_num(label)
# 10. 返回字典,因为我们的模型期望两个输入
return spectrogram, label
创建 Dataset 对象
我们创建一个 tf.data.Dataset 对象,该对象以输入中出现的相同顺序提供转换后的元素。
batch_size = 32
# 定义训练数据集
train_dataset = tf.data.Dataset.from_tensor_slices(
(list(df_train["file_name"]), list(df_train["normalized_transcription"]))
)
train_dataset = (
train_dataset.map(encode_single_sample, num_parallel_calls=tf.data.AUTOTUNE)
.padded_batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# 定义验证数据集
validation_dataset = tf.data.Dataset.from_tensor_slices(
(list(df_val["file_name"]), list(df_val["normalized_transcription"]))
)
validation_dataset = (
validation_dataset.map(encode_single_sample, num_parallel_calls=tf.data.AUTOTUNE)
.padded_batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
可视化数据
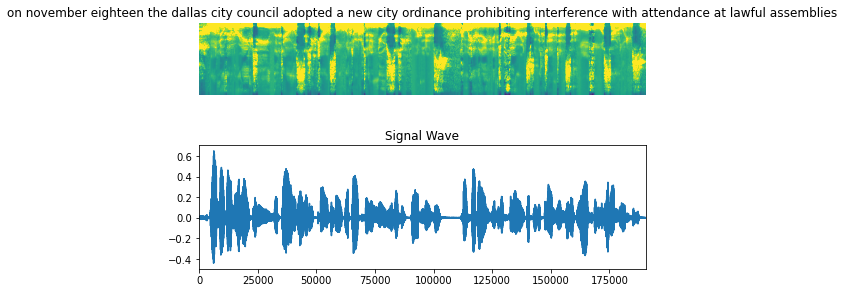
让我们可视化数据集中一个例子,包括音频片段、声谱图和相应的标签。
fig = plt.figure(figsize=(8, 5))
for batch in train_dataset.take(1):
spectrogram = batch[0][0].numpy()
spectrogram = np.array([np.trim_zeros(x) for x in np.transpose(spectrogram)])
label = batch[1][0]
# 声谱图
label = tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
ax = plt.subplot(2, 1, 1)
ax.imshow(spectrogram, vmax=1)
ax.set_title(label)
ax.axis("off")
# wav文件
file = tf.io.read_file(wavs_path + list(df_train["file_name"])[0] + ".wav")
audio, _ = tf.audio.decode_wav(file)
audio = audio.numpy()
ax = plt.subplot(2, 1, 2)
plt.plot(audio)
ax.set_title("信号波形")
ax.set_xlim(0, len(audio))
display.display(display.Audio(np.transpose(audio), rate=16000))
plt.show()
模型
我们首先定义CTC损失函数。
def CTCLoss(y_true, y_pred):
# 计算训练时的损失值
batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64")
input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64")
label_length = tf.cast(tf.shape(y_true)[1], dtype="int64")
input_length = input_length * tf.ones(shape=(batch_len, 1), dtype="int64")
label_length = label_length * tf.ones(shape=(batch_len, 1), dtype="int64")
loss = keras.backend.ctc_batch_cost(y_true, y_pred, input_length, label_length)
return loss
我们现在定义我们的模型。我们将定义一个类似于 DeepSpeech2的模型。
def build_model(input_dim, output_dim, rnn_layers=5, rnn_units=128):
"""类似于DeepSpeech2的模型。"""
# 模型输入
input_spectrogram = layers.Input((None, input_dim), name="input")
# 扩展维度以使用2D CNN。
x = layers.Reshape((-1, input_dim, 1), name="expand_dim")(input_spectrogram)
# 卷积层 1
x = layers.Conv2D(
filters=32,
kernel_size=[11, 41],
strides=[2, 2],
padding="same",
use_bias=False,
name="conv_1",
)(x)
x = layers.BatchNormalization(name="conv_1_bn")(x)
x = layers.ReLU(name="conv_1_relu")(x)
# 卷积层 2
x = layers.Conv2D(
filters=32,
kernel_size=[11, 21],
strides=[1, 2],
padding="same",
use_bias=False,
name="conv_2",
)(x)
x = layers.BatchNormalization(name="conv_2_bn")(x)
x = layers.ReLU(name="conv_2_relu")(x)
# 重新调整结果体积以输入RNN层
x = layers.Reshape((-1, x.shape[-2] * x.shape[-1]))(x)
# RNN层
for i in range(1, rnn_layers + 1):
recurrent = layers.GRU(
units=rnn_units,
activation="tanh",
recurrent_activation="sigmoid",
use_bias=True,
return_sequences=True,
reset_after=True,
name=f"gru_{i}",
)
x = layers.Bidirectional(
recurrent, name=f"bidirectional_{i}", merge_mode="concat"
)(x)
if i < rnn_layers:
x = layers.Dropout(rate=0.5)(x)
# 全连接层
x = layers.Dense(units=rnn_units * 2, name="dense_1")(x)
x = layers.ReLU(name="dense_1_relu")(x)
x = layers.Dropout(rate=0.5)(x)
# 分类层
output = layers.Dense(units=output_dim + 1, activation="softmax")(x)
# 模型
model = keras.Model(input_spectrogram, output, name="DeepSpeech_2")
# 优化器
opt = keras.optimizers.Adam(learning_rate=1e-4)
# 编译模型并返回
model.compile(optimizer=opt, loss=CTCLoss)
return model
# 获取模型
model = build_model(
input_dim=fft_length // 2 + 1,
output_dim=char_to_num.vocabulary_size(),
rnn_units=512,
)
model.summary(line_length=110)
模型: "DeepSpeech_2"
______________________________________________________________________________________________________________
层 (类型) 输出形状 参数 #
==============================================================================================================
输入 (输入层) [(无, 无, 193)] 0
扩展维度 (重塑) (无, 无, 193, 1) 0
卷积_1 (卷积2D) (无, 无, 97, 32) 14432
卷积_1_bn (批归一化) (无, 无, 97, 32) 128
卷积_1_relu (ReLU) (无, 无, 97, 32) 0
卷积_2 (卷积2D) (无, 无, 49, 32) 236544
卷积_2_bn (批归一化) (无, 无, 49, 32) 128
卷积_2_relu (ReLU) (无, 无, 49, 32) 0
重塑 (重塑) (无, 无, 1568) 0
双向_1 (双向) (无, 无, 1024) 6395904
丢弃 (丢弃) (无, 无, 1024) 0
双向_2 (双向) (无, 无, 1024) 4724736
丢弃_1 (丢弃) (无, 无, 1024) 0
双向_3 (双向) (无, 无, 1024) 4724736
丢弃_2 (丢弃) (无, 无, 1024) 0
双向_4 (双向) (无, 无, 1024) 4724736
丢弃_3 (丢弃) (无, 无, 1024) 0
双向_5 (双向) (无, 无, 1024) 4724736
全连接_1 (全连接) (无, 无, 1024) 1049600
全连接_1_relu (ReLU) (无, 无, 1024) 0
丢弃_4 (丢弃) (无, 无, 1024) 0
全连接 (全连接) (无, 无, 32) 32800
==============================================================================================================
总参数: 26,628,480
可训练参数: 26,628,352
不可训练参数: 128
______________________________________________________________________________________________________________
</div>
---
## 训练与评估
```python
# 一个用于解码网络输出的实用函数
def decode_batch_predictions(pred):
input_len = np.ones(pred.shape[0]) * pred.shape[1]
# 使用贪心搜索。对于复杂任务,可以使用束搜索
results = keras.backend.ctc_decode(pred, input_length=input_len, greedy=True)[0][0]
# 遍历结果并返回文本
output_text = []
for result in results:
result = tf.strings.reduce_join(num_to_char(result)).numpy().decode("utf-8")
output_text.append(result)
return output_text
# 一个回调类,用于在训练期间输出一些转录
class CallbackEval(keras.callbacks.Callback):
"""在每个纪元结束后显示一批输出。"""
def __init__(self, dataset):
super().__init__()
self.dataset = dataset
def on_epoch_end(self, epoch: int, logs=None):
predictions = []
targets = []
for batch in self.dataset:
X, y = batch
batch_predictions = model.predict(X)
batch_predictions = decode_batch_predictions(batch_predictions)
predictions.extend(batch_predictions)
for label in y:
label = (
tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
)
targets.append(label)
wer_score = wer(targets, predictions)
print("-" * 100)
print(f"词错误率: {wer_score:.4f}")
print("-" * 100)
for i in np.random.randint(0, len(predictions), 2):
print(f"目标 : {targets[i]}")
print(f"预测 : {predictions[i]}")
print("-" * 100)
# 定义纪元数。
epochs = 1
# 回调函数,用于检查验证集上的转录。
validation_callback = CallbackEval(validation_dataset)
# 训练模型
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=epochs,
callbacks=[validation_callback],
)
369/369 [==============================] - ETA: 0s - loss: 302.4755----------------------------------------------------------------------------------------------------
词错误率: 1.0000
----------------------------------------------------------------------------------------------------
目标 : special agent lyndal l shaneyfelt a photography expert with the fbi
预测 : s
----------------------------------------------------------------------------------------------------
目标 : dissolved in water the sugar is transported down delicate tubes chiefly in the growing bark region of the stem
预测 : sss
----------------------------------------------------------------------------------------------------
369/369 [==============================] - 407s 1s/step - loss: 302.4755 - val_loss: 252.1534
# 让我们检查更多验证样本上的结果
predictions = []
targets = []
for batch in validation_dataset:
X, y = batch
batch_predictions = model.predict(X)
batch_predictions = decode_batch_predictions(batch_predictions)
predictions.extend(batch_predictions)
for label in y:
label = tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
targets.append(label)
wer_score = wer(targets, predictions)
print("-" * 100)
print(f"词错误率: {wer_score:.4f}")
print("-" * 100)
for i in np.random.randint(0, len(predictions), 5):
print(f"目标 : {targets[i]}")
print(f"预测 : {predictions[i]}")
print("-" * 100)
- 目标 : sir thomas overbury 无疑是被 lord rochester 在詹姆斯一世统治期间毒死的
- 预测 : cer thomas overbery 无疑是被 lordrochester 在詹姆斯一世统治期间毒死的
- 目标 : 委员会似乎还没有理解 newgate 只能被更换得当
- 预测 : 委员会似乎还没有理解 newgate 只能被 proberly 更换
- 目标 : 但仍然没有对该罪行执行死刑,并且在一千八百三十二年
- 预测 : 但仍然没有对该罪行执行死刑,并且在一千八百三十二年