英语发音识别使用迁移学习
作者: Fadi Badine
创建日期: 2022/04/16
最后修改: 2022/04/16
描述: 使用Yamnet进行特征提取,训练模型以分类英国和爱尔兰口音。

介绍
以下示例演示如何使用特征提取来训练模型,以分类音频波中说的英语口音。
与从零开始训练模型不同,迁移学习使我们能够利用现有的最先进的深度学习模型,并将其用作特征提取器。
我们的过程:
- 使用预训练的TF Hub模型(Yamnet),并将其应用于tf.data管道的一部分,该管道将音频文件转换为特征向量。
- 在特征向量上训练密集模型。
- 使用训练好的模型对新的音频文件进行推断。
注意:
- 我们需要安装TensorFlow IO,以便将音频文件重新采样为Yamnet模型要求的16 kHz。
- 在测试部分,使用ffmpeg将mp3文件转换为wav。
您可以使用以下命令安装TensorFlow IO:
!pip install -U -q tensorflow_io
配置
SEED = 1337
EPOCHS = 100
BATCH_SIZE = 64
VALIDATION_RATIO = 0.1
MODEL_NAME = "uk_irish_accent_recognition"
# 数据集下载的位置。
# 默认情况下(None),keras.utils.get_file将使用~/.keras/作为CACHE_DIR
CACHE_DIR = None
# 数据集的位置
URL_PATH = "https://www.openslr.org/resources/83/"
# 包含音频文件的数据集压缩文件列表
zip_files = {
0: "irish_english_male.zip",
1: "midlands_english_female.zip",
2: "midlands_english_male.zip",
3: "northern_english_female.zip",
4: "northern_english_male.zip",
5: "scottish_english_female.zip",
6: "scottish_english_male.zip",
7: "southern_english_female.zip",
8: "southern_english_male.zip",
9: "welsh_english_female.zip",
10: "welsh_english_male.zip",
}
# 我们看到每种口音有2个压缩文件(爱尔兰口音除外):
# - 一个男性发言者
# - 一个女性发言者
# 然而,我们将使用一个性别无关的数据集。
# 性别无关类别列表
gender_agnostic_categories = [
"ir", # 爱尔兰
"mi", # 中部地区
"no", # 北方
"sc", # 苏格兰
"so", # 南方
"we", # 威尔士
]
class_names = [
"爱尔兰",
"中部地区",
"北方",
"苏格兰",
"南方",
"威尔士",
"不是发言",
]
导入
import os
import io
import csv
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
from tensorflow import keras
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from IPython.display import Audio
# 设置所有随机种子,以获得可重复的结果
keras.utils.set_random_seed(SEED)
# 下载数据集的位置
DATASET_DESTINATION = os.path.join(CACHE_DIR if CACHE_DIR else "~/.keras/", "datasets")
Yamnet模型
Yamnet是一个音频事件分类器,训练于AudioSet数据集,以预测来自AudioSet本体的音频事件。它在TensorFlow Hub上可用。
Yamnet接受一个16 kHz采样率的音频样本的1-D张量。 作为输出,该模型返回一个3元组:
- 形状为
(N, 521)的分数,表示521个类别的分数。 - 形状为
(N, 1024)的嵌入。 - 整个音频帧的对数梅尔谱图。
我们将使用嵌入,即从音频样本中提取的特征,作为密集模型的输入。
有关Yamnet的更多详细信息,请参阅其TensorFlow Hub页面。
yamnet_model = hub.load("https://tfhub.dev/google/yamnet/1")
数据集
使用的数据集是 众包的高质量英国和爱尔兰英语方言语音数据集, 其中包含总共17,877个高质量音频wav文件。
该数据集包括来自120名自我认定为南英格兰、中部、北英格兰、威尔士、苏格兰和爱尔兰的母语发言者的31小时以上的录音。
有关更多信息,请参阅上述链接或以下论文: 英国群岛英语口音的开源多说话者语料库
下载数据
# CSV file that contains information about the dataset. For each entry, we have:
# - ID
# - wav file name
# - transcript
line_index_file = keras.utils.get_file(
fname="line_index_file", origin=URL_PATH + "line_index_all.csv"
)
# Download the list of compressed files that contain the audio wav files
for i in zip_files:
fname = zip_files[i].split(".")[0]
url = URL_PATH + zip_files[i]
zip_file = keras.utils.get_file(fname=fname, origin=url, extract=True)
os.remove(zip_file)
从 https://www.openslr.org/resources/83/line_index_all.csv 下载数据
1990656/1986139 [==============================] - 1s 0us/step
1998848/1986139 [==============================] - 1s 0us/step
从 https://www.openslr.org/resources/83/irish_english_male.zip 下载数据
164536320/164531638 [==============================] - 9s 0us/step
164544512/164531638 [==============================] - 9s 0us/step
从 https://www.openslr.org/resources/83/midlands_english_female.zip 下载数据
103088128/103085118 [==============================] - 6s 0us/step
103096320/103085118 [==============================] - 6s 0us/step
从 https://www.openslr.org/resources/83/midlands_english_male.zip 下载数据
166838272/166833961 [==============================] - 9s 0us/step
166846464/166833961 [==============================] - 9s 0us/step
从 https://www.openslr.org/resources/83/northern_english_female.zip 下载数据
314990592/314983063 [==============================] - 15s 0us/step
314998784/314983063 [==============================] - 15s 0us/step
从 https://www.openslr.org/resources/83/northern_english_male.zip 下载数据
817774592/817772034 [==============================] - 39s 0us/step
817782784/817772034 [==============================] - 39s 0us/step
从 https://www.openslr.org/resources/83/scottish_english_female.zip 下载数据
351444992/351443880 [==============================] - 17s 0us/step
351453184/351443880 [==============================] - 17s 0us/step
从 https://www.openslr.org/resources/83/scottish_english_male.zip 下载数据
620257280/620254118 [==============================] - 30s 0us/step
620265472/620254118 [==============================] - 30s 0us/step
从 https://www.openslr.org/resources/83/southern_english_female.zip 下载数据
1636704256/1636701939 [==============================] - 77s 0us/step
1636712448/1636701939 [==============================] - 77s 0us/step
从 https://www.openslr.org/resources/83/southern_english_male.zip 下载数据
1700962304/1700955740 [==============================] - 79s 0us/step
1700970496/1700955740 [==============================] - 79s 0us/step
从 https://www.openslr.org/resources/83/welsh_english_female.zip 下载数据
595689472/595683538 [==============================] - 29s 0us/step
595697664/595683538 [==============================] - 29s 0us/step
从 https://www.openslr.org/resources/83/welsh_english_male.zip 下载数据
757653504/757645790 [==============================] - 37s 0us/step
757661696/757645790 [==============================] - 37s 0us/step
将数据加载到数据框中
在3列(ID、文件名和转录文本)中,我们只对文件名列感兴趣,以便读取音频文件。 我们将忽略其他两个。
dataframe = pd.read_csv(
line_index_file, names=["id", "filename", "transcript"], usecols=["filename"]
)
dataframe.head()
| filename | |
|---|---|
| 0 | wef_12484_01482829612 |
| 1 | wef_12484_01345932698 |
| 2 | wef_12484_00999757777 |
| 3 | wef_12484_00036278823 |
| 4 | wef_12484_00458512623 |
现在让我们通过以下方式预处理数据集:
- 调整文件名(去除前导空格并为文件名添加“.wav”扩展名)。
- 使用文件名的前两个字符创建标签,这表示口音。
- 随机打乱样本。
# The purpose of this function is to preprocess the dataframe by applying the following:
# - Cleaning the filename from a leading space
# - Generating a label column that is gender agnostic i.e.
# welsh english male and welsh english female for example are both labeled as
# welsh english
# - Add extension .wav to the filename
# - Shuffle samples
def preprocess_dataframe(dataframe):
# Remove leading space in filename column
dataframe["filename"] = dataframe.apply(lambda row: row["filename"].strip(), axis=1)
# Create gender agnostic labels based on the filename first 2 letters
dataframe["label"] = dataframe.apply(
lambda row: gender_agnostic_categories.index(row["filename"][:2]), axis=1
)
# Add the file path to the name
dataframe["filename"] = dataframe.apply(
lambda row: os.path.join(DATASET_DESTINATION, row["filename"] + ".wav"), axis=1
)
# Shuffle the samples
dataframe = dataframe.sample(frac=1, random_state=SEED).reset_index(drop=True)
return dataframe
dataframe = preprocess_dataframe(dataframe)
dataframe.head()
| 文件名 | 标签 | |
|---|---|---|
| 0 | /root/.keras/datasets/som_03853_01027933689.wav | 4 |
| 1 | /root/.keras/datasets/som_04310_01833253760.wav | 4 |
| 2 | /root/.keras/datasets/sof_06136_01210700905.wav | 4 |
| 3 | /root/.keras/datasets/som_02484_00261230384.wav | 4 |
| 4 | /root/.keras/datasets/nom_06136_00616878975.wav | 2 |
准备训练和验证集
让我们通过创建训练和验证集来划分样本。
split = int(len(dataframe) * (1 - VALIDATION_RATIO))
train_df = dataframe[:split]
valid_df = dataframe[split:]
print(
f"我们有 {train_df.shape[0]} 个训练样本和 {valid_df.shape[0]} 个验证样本"
)
我们有 16089 个训练样本和 1788 个验证样本
准备 TensorFlow 数据集
接下来,我们需要创建一个 tf.data.Dataset。
这是通过创建一个 dataframe_to_dataset 函数来完成的,该函数执行以下操作:
- 使用文件名和标签创建数据集。
- 通过调用另一个函数
filepath_to_embeddings获取 Yamnet 嵌入。 - 应用缓存、重新洗牌并设置批处理大小。
filepath_to_embeddings 执行以下操作:
- 加载音频文件。
- 将音频重采样为 16 kHz。
- 从 Yamnet 模型生成得分和嵌入。
- 由于 Yamnet 为每个音频文件生成多个样本,
该函数还会为所有
score=0(语音)的生成样本复制标签, 而将其他样本的标签设置为 '其他',表示该音频片段不是语音,我们不会将其标记为口音之一。
下面的 load_16k_audio_file 是从以下教程复制的
使用 YAMNet 进行环境声音分类的迁移学习
@tf.function
def load_16k_audio_wav(filename):
# 读取文件内容
file_content = tf.io.read_file(filename)
# 解码音频波形
audio_wav, sample_rate = tf.audio.decode_wav(file_content, desired_channels=1)
audio_wav = tf.squeeze(audio_wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
# 重采样为 16k
audio_wav = tfio.audio.resample(audio_wav, rate_in=sample_rate, rate_out=16000)
return audio_wav
def filepath_to_embeddings(filename, label):
# 加载 16k 音频波
audio_wav = load_16k_audio_wav(filename)
# 获取音频嵌入和得分。
# 嵌入是使用迁移学习提取的音频特征
# 而得分将用于识别不是语音的时间段
# 然后将收集到一个特定的新类别 '其他'
scores, embeddings, _ = yamnet_model(audio_wav)
# 嵌入的数量以了解需要重复标签多少次
embeddings_num = tf.shape(embeddings)[0]
labels = tf.repeat(label, embeddings_num)
# 将不是语音的时间段的标签更改为新的类别 '其他'
labels = tf.where(tf.argmax(scores, axis=1) == 0, label, len(class_names) - 1)
# 使用独热编码以便使用 AUC
return (embeddings, tf.one_hot(labels, len(class_names)))
def dataframe_to_dataset(dataframe, batch_size=64):
dataset = tf.data.Dataset.from_tensor_slices(
(dataframe["filename"], dataframe["label"])
)
dataset = dataset.map(
lambda x, y: filepath_to_embeddings(x, y),
num_parallel_calls=tf.data.experimental.AUTOTUNE,
).unbatch()
return dataset.cache().batch(batch_size).prefetch(tf.data.AUTOTUNE)
train_ds = dataframe_to_dataset(train_df)
valid_ds = dataframe_to_dataset(valid_df)
构建模型
我们使用的模型由以下部分组成:
- 一个输入层,它是 Yamnet 分类器的嵌入输出。
- 4 个稠密隐藏层和 4 个 dropout 层。
- 一层输出稠密层。
模型的超参数是使用 KerasTuner 选择的。
keras.backend.clear_session()
def build_and_compile_model():
inputs = keras.layers.Input(shape=(1024), name="embedding")
x = keras.layers.Dense(256, activation="relu", name="dense_1")(inputs)
x = keras.layers.Dropout(0.15, name="dropout_1")(x)
x = keras.layers.Dense(384, activation="relu", name="dense_2")(x)
x = keras.layers.Dropout(0.2, name="dropout_2")(x)
x = keras.layers.Dense(192, activation="relu", name="dense_3")(x)
x = keras.layers.Dropout(0.25, name="dropout_3")(x)
x = keras.layers.Dense(384, activation="relu", name="dense_4")(x)
x = keras.layers.Dropout(0.2, name="dropout_4")(x)
outputs = keras.layers.Dense(len(class_names), activation="softmax", name="ouput")(
x
)
model = keras.Model(inputs=inputs, outputs=outputs, name="accent_recognition")
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=1.9644e-5),
loss=keras.losses.CategoricalCrossentropy(),
metrics=["accuracy", keras.metrics.AUC(name="auc")],
)
return model
model = build_and_compile_model()
model.summary()
模型: "accent_recognition"
_________________________________________________________________
层 (类型) 输出形状 参数 #
=================================================================
embedding (输入层) [(None, 1024)] 0
dense_1 (密集层) (None, 256) 262400
dropout_1 (丢弃层) (None, 256) 0
dense_2 (密集层) (None, 384) 98688
dropout_2 (丢弃层) (None, 384) 0
dense_3 (密集层) (None, 192) 73920
dropout_3 (丢弃层) (None, 192) 0
dense_4 (密集层) (None, 384) 74112
dropout_4 (丢弃层) (None, 384) 0
ouput (密集层) (None, 7) 2695
=================================================================
总参数: 511,815
可训练参数: 511,815
不可训练参数: 0
_________________________________________________________________
类别权重计算
由于数据集相当不平衡,我们将在训练过程中使用 class_weight 参数。
获取类别权重有点棘手,因为尽管我们知道每个类别的音频文件数量,但这并不代表该类别的样本数量,因为 Yamnet 将每个音频文件转换为多个每个 0.96 秒的音频样本。因此,每个音频文件将被拆分为与其长度成正比的多个样本。
因此,要获取这些权重,我们必须在通过 Yamnet 进行预处理后计算每个类别的样本数量。
class_counts = tf.zeros(shape=(len(class_names),), dtype=tf.int32)
for x, y in iter(train_ds):
class_counts = class_counts + tf.math.bincount(
tf.cast(tf.math.argmax(y, axis=1), tf.int32), minlength=len(class_names)
)
class_weight = {
i: tf.math.reduce_sum(class_counts).numpy() / class_counts[i].numpy()
for i in range(len(class_counts))
}
print(class_weight)
{0: 50.430241233524, 1: 30.668481548699333, 2: 7.322956917409988, 3: 8.125175301518611, 4: 2.4034894333226657, 5: 6.4197296356095865, 6: 8.613175890922992}
回调
我们使用 Keras 回调以便于:
- 一旦验证 AUC 停止改善就停止训练。
- 保存最佳模型。
- 调用 TensorBoard 以便后续查看训练和验证日志。
early_stopping_cb = keras.callbacks.EarlyStopping(
monitor="val_auc", patience=10, restore_best_weights=True
)
model_checkpoint_cb = keras.callbacks.ModelCheckpoint(
MODEL_NAME + ".h5", monitor="val_auc", save_best_only=True
)
tensorboard_cb = keras.callbacks.TensorBoard(
os.path.join(os.curdir, "logs", model.name)
)
callbacks = [early_stopping_cb, model_checkpoint_cb, tensorboard_cb]
训练
history = model.fit(
train_ds,
epochs=EPOCHS,
validation_data=valid_ds,
class_weight=class_weight,
callbacks=callbacks,
verbose=2,
)
Epoch 1/100
3169/3169 - 131s - loss: 10.6145 - accuracy: 0.3426 - auc: 0.7585 - val_loss: 1.3781 - val_accuracy: 0.4084 - val_auc: 0.8118 - 131s/epoch - 41ms/step
Epoch 2/100
3169/3169 - 12s - loss: 9.3787 - accuracy: 0.3957 - auc: 0.8055 - val_loss: 1.3291 - val_accuracy: 0.4470 - val_auc: 0.8294 - 12s/epoch - 4ms/step
Epoch 3/100
3169/3169 - 13s - loss: 8.9948 - accuracy: 0.4216 - auc: 0.8212 - val_loss: 1.3144 - val_accuracy: 0.4497 - val_auc: 0.8340 - 13s/epoch - 4ms/step
Epoch 4/100
3169/3169 - 13s - loss: 8.7682 - accuracy: 0.4327 - auc: 0.8291 - val_loss: 1.3052 - val_accuracy: 0.4515 - val_auc: 0.8368 - 13s/epoch - 4ms/step
Epoch 5/100
3169/3169 - 12s - loss: 8.6352 - accuracy: 0.4375 - auc: 0.8328 - val_loss: 1.2993 - val_accuracy: 0.4482 - val_auc: 0.8377 - 12s/epoch - 4ms/step
Epoch 6/100
3169/3169 - 12s - loss: 8.5149 - accuracy: 0.4421 - auc: 0.8367 - val_loss: 1.2930 - val_accuracy: 0.4462 - val_auc: 0.8398 - 12s/epoch - 4ms/step
Epoch 7/100
3169/3169 - 12s - loss: 8.4321 - accuracy: 0.4438 - auc: 0.8393 - val_loss: 1.2881 - val_accuracy: 0.4460 - val_auc: 0.8412 - 12s/epoch - 4ms/step
Epoch 8/100
3169/3169 - 12s - loss: 8.3385 - accuracy: 0.4459 - auc: 0.8413 - val_loss: 1.2730 - val_accuracy: 0.4503 - val_auc: 0.8450 - 12s/epoch - 4ms/step
Epoch 9/100
3169/3169 - 12s - loss: 8.2704 - accuracy: 0.4478 - auc: 0.8434 - val_loss: 1.2718 - val_accuracy: 0.4486 - val_auc: 0.8451 - 12s/epoch - 4ms/step
Epoch 10/100
3169/3169 - 12s - loss: 8.2023 - accuracy: 0.4489 - auc: 0.8455 - val_loss: 1.2714 - val_accuracy: 0.4450 - val_auc: 0.8450 - 12s/epoch - 4ms/step
Epoch 11/100
3169/3169 - 12s - loss: 8.1402 - accuracy: 0.4504 - auc: 0.8474 - val_loss: 1.2616 - val_accuracy: 0.4496 - val_auc: 0.8479 - 12s/epoch - 4ms/step
Epoch 12/100
3169/3169 - 12s - loss: 8.0935 - accuracy: 0.4521 - auc: 0.8488 - val_loss: 1.2569 - val_accuracy: 0.4503 - val_auc: 0.8494 - 12s/epoch - 4ms/step
Epoch 13/100
3169/3169 - 12s - loss: 8.0281 - accuracy: 0.4541 - auc: 0.8507 - val_loss: 1.2537 - val_accuracy: 0.4516 - val_auc: 0.8505 - 12s/epoch - 4ms/step
Epoch 14/100
3169/3169 - 12s - loss: 7.9817 - accuracy: 0.4540 - auc: 0.8519 - val_loss: 1.2584 - val_accuracy: 0.4478 - val_auc: 0.8496 - 12s/epoch - 4ms/step
Epoch 15/100
3169/3169 - 12s - loss: 7.9342 - accuracy: 0.4556 - auc: 0.8534 - val_loss: 1.2469 - val_accuracy: 0.4515 - val_auc: 0.8526 - 12s/epoch - 4ms/step
Epoch 16/100
3169/3169 - 12s - loss: 7.8945 - accuracy: 0.4560 - auc: 0.8545 - val_loss: 1.2332 - val_accuracy: 0.4574 - val_auc: 0.8564 - 12s/epoch - 4ms/step
Epoch 17/100
3169/3169 - 12s - loss: 7.8461 - accuracy: 0.4585 - auc: 0.8560 - val_loss: 1.2406 - val_accuracy: 0.4534 - val_auc: 0.8545 - 12s/epoch - 4ms/step
Epoch 18/100
3169/3169 - 12s - loss: 7.8091 - accuracy: 0.4604 - auc: 0.8570 - val_loss: 1.2313 - val_accuracy: 0.4574 - val_auc: 0.8570 - 12s/epoch - 4ms/step
Epoch 19/100
3169/3169 - 12s - loss: 7.7604 - accuracy: 0.4605 - auc: 0.8583 - val_loss: 1.2342 - val_accuracy: 0.4563 - val_auc: 0.8565 - 12s/epoch - 4ms/step
Epoch 20/100
3169/3169 - 13s - loss: 7.7205 - accuracy: 0.4624 - auc: 0.8596 - val_loss: 1.2245 - val_accuracy: 0.4619 - val_auc: 0.8594 - 13s/epoch - 4ms/step
Epoch 21/100
3169/3169 - 12s - loss: 7.6892 - accuracy: 0.4637 - auc: 0.8605 - val_loss: 1.2264 - val_accuracy: 0.4576 - val_auc: 0.8587 - 12s/epoch - 4ms/step
Epoch 22/100
3169/3169 - 12s - loss: 7.6396 - accuracy: 0.4636 - auc: 0.8614 - val_loss: 1.2180 - val_accuracy: 0.4632 - val_auc: 0.8614 - 12s/epoch - 4ms/step
Epoch 23/100
3169/3169 - 12s - loss: 7.5927 - accuracy: 0.4672 - auc: 0.8627 - val_loss: 1.2127 - val_accuracy: 0.4630 - val_auc: 0.8626 - 12s/epoch - 4ms/step
Epoch 24/100
3169/3169 - 13s - loss: 7.5766 - accuracy: 0.4666 - auc: 0.8632 - val_loss: 1.2112 - val_accuracy: 0.4636 - val_auc: 0.8632 - 13s/epoch - 4ms/step
Epoch 25/100
3169/3169 - 12s - loss: 7.5511 - accuracy: 0.4678 - auc: 0.8644 - val_loss: 1.2096 - val_accuracy: 0.4664 - val_auc: 0.8641 - 12s/epoch - 4ms/step
Epoch 26/100
3169/3169 - 12s - loss: 7.5108 - accuracy: 0.4679 - auc: 0.8648 - val_loss: 1.2033 - val_accuracy: 0.4664 - val_auc: 0.8652 - 12s/epoch - 4ms/step
Epoch 27/100
3169/3169 - 12s - loss: 7.4751 - accuracy: 0.4692 - auc: 0.8659 - val_loss: 1.2050 - val_accuracy: 0.4668 - val_auc: 0.8653 - 12s/epoch - 4ms/step
Epoch 28/100
3169/3169 - 12s - loss: 7.4332 - accuracy: 0.4704 - auc: 0.8668 - val_loss: 1.2004 - val_accuracy: 0.4688 - val_auc: 0.8665 - 12s/epoch - 4ms/step
Epoch 29/100
3169/3169 - 12s - loss: 7.4195 - accuracy: 0.4709 - auc: 0.8675 - val_loss: 1.2037 - val_accuracy: 0.4665 - val_auc: 0.8654 - 12s/epoch - 4ms/step
Epoch 30/100
3169/3169 - 12s - loss: 7.3719 - accuracy: 0.4718 - auc: 0.8683 - val_loss: 1.1979 - val_accuracy: 0.4694 - val_auc: 0.8674 - 12s/epoch - 4ms/step
Epoch 31/100
3169/3169 - 12s - loss: 7.3513 - accuracy: 0.4728 - auc: 0.8690 - val_loss: 1.2030 - val_accuracy: 0.4662 - val_auc: 0.8661 - 12s/epoch - 4ms/step
Epoch 32/100
3169/3169 - 12s - loss: 7.3218 - accuracy: 0.4738 - auc: 0.8697 - val_loss: 1.1982 - val_accuracy: 0.4689 - val_auc: 0.8673 - 12s/epoch - 4ms/step
Epoch 33/100
3169/3169 - 12s - loss: 7.2744 - accuracy: 0.4750 - auc: 0.8708 - val_loss: 1.1921 - val_accuracy: 0.4715 - val_auc: 0.8688 - 12s/epoch - 4ms/step
Epoch 34/100
3169/3169 - 12s - loss: 7.2520 - accuracy: 0.4765 - auc: 0.8715 - val_loss: 1.1935 - val_accuracy: 0.4717 - val_auc: 0.8685 - 12s/epoch - 4ms/step
Epoch 35/100
3169/3169 - 12s - loss: 7.2214 - accuracy: 0.4769 - auc: 0.8721 - val_loss: 1.1940 - val_accuracy: 0.4688 - val_auc: 0.8681 - 12s/epoch - 4ms/step
Epoch 36/100
3169/3169 - 12s - loss: 7.1789 - accuracy: 0.4798 - auc: 0.8732 - val_loss: 1.1796 - val_accuracy: 0.4733 - val_auc: 0.8717 - 12s/epoch - 4ms/step
Epoch 37/100
3169/3169 - 12s - loss: 7.1520 - accuracy: 0.4813 - auc: 0.8739 - val_loss: 1.1844 - val_accuracy: 0.4738 - val_auc: 0.8709 - 12s/epoch - 4ms/step
Epoch 38/100
3169/3169 - 12s - loss: 7.1393 - accuracy: 0.4813 - auc: 0.8743 - val_loss: 1.1785 - val_accuracy: 0.4753 - val_auc: 0.8721 - 12s/epoch - 4ms/step
Epoch 39/100
3169/3169 - 12s - loss: 7.1081 - accuracy: 0.4821 - auc: 0.8749 - val_loss: 1.1792 - val_accuracy: 0.4754 - val_auc: 0.8723 - 12s/epoch - 4ms/step
Epoch 40/100
3169/3169 - 12s - loss: 7.0664 - accuracy: 0.4831 - auc: 0.8758 - val_loss: 1.1829 - val_accuracy: 0.4719 - val_auc: 0.8716 - 12s/epoch - 4ms/step
Epoch 41/100
3169/3169 - 12s - loss: 7.0625 - accuracy: 0.4831 - auc: 0.8759 - val_loss: 1.1831 - val_accuracy: 0.4737 - val_auc: 0.8716 - 12s/epoch - 4ms/step
Epoch 42/100
3169/3169 - 12s - loss: 7.0190 - accuracy: 0.4845 - auc: 0.8767 - val_loss: 1.1886 - val_accuracy: 0.4689 - val_auc: 0.8705 - 12s/epoch - 4ms/step
Epoch 43/100
3169/3169 - 13s - loss: 7.0000 - accuracy: 0.4839 - auc: 0.8770 - val_loss: 1.1720 - val_accuracy: 0.4776 - val_auc: 0.8744 - 13s/epoch - 4ms/step
Epoch 44/100
3169/3169 - 12s - loss: 6.9733 - accuracy: 0.4864 - auc: 0.8777 - val_loss: 1.1704 - val_accuracy: 0.4772 - val_auc: 0.8745 - 12s/epoch - 4ms/step
Epoch 45/100
3169/3169 - 12s - loss: 6.9480 - accuracy: 0.4872 - auc: 0.8784 - val_loss: 1.1695 - val_accuracy: 0.4767 - val_auc: 0.8747 - 12s/epoch - 4ms/step
Epoch 46/100
3169/3169 - 12s - loss: 6.9208 - accuracy: 0.4880 - auc: 0.8789 - val_loss: 1.1687 - val_accuracy: 0.4792 - val_auc: 0.8753 - 12s/epoch - 4ms/step
Epoch 47/100
3169/3169 - 12s - loss: 6.8756 - accuracy: 0.4902 - auc: 0.8800 - val_loss: 1.1667 - val_accuracy: 0.4785 - val_auc: 0.8755 - 12s/epoch - 4ms/step
Epoch 48/100
3169/3169 - 12s - loss: 6.8618 - accuracy: 0.4902 - auc: 0.8801 - val_loss: 1.1714 - val_accuracy: 0.4781 - val_auc: 0.8752 - 12s/epoch - 4ms/step
Epoch 49/100
3169/3169 - 12s - loss: 6.8411 - accuracy: 0.4916 - auc: 0.8807 - val_loss: 1.1676 - val_accuracy: 0.4793 - val_auc: 0.8756 - 12s/epoch - 4ms/step
Epoch 50/100
3169/3169 - 12s - loss: 6.8144 - accuracy: 0.4922 - auc: 0.8812 - val_loss: 1.1622 - val_accuracy: 0.4784 - val_auc: 0.8767 - 12s/epoch - 4ms/step
Epoch 51/100
3169/3169 - 12s - loss: 6.7880 - accuracy: 0.4931 - auc: 0.8819 - val_loss: 1.1591 - val_accuracy: 0.4844 - val_auc: 0.8780 - 12s/epoch - 4ms/step
Epoch 52/100
3169/3169 - 12s - loss: 6.7653 - accuracy: 0.4932 - auc: 0.8823 - val_loss: 1.1579 - val_accuracy: 0.4808 - val_auc: 0.8776 - 12s/epoch - 4ms/step
Epoch 53/100
3169/3169 - 12s - loss: 6.7188 - accuracy: 0.4961 - auc: 0.8832 - val_loss: 1.1526 - val_accuracy: 0.4845 - val_auc: 0.8791 - 12s/epoch - 4ms/step
Epoch 54/100
3169/3169 - 12s - loss: 6.6964 - accuracy: 0.4969 - auc: 0.8836 - val_loss: 1.1571 - val_accuracy: 0.4843 - val_auc: 0.8788 - 12s/epoch - 4ms/step
Epoch 55/100
3169/3169 - 12s - loss: 6.6855 - accuracy: 0.4981 - auc: 0.8841 - val_loss: 1.1595 - val_accuracy: 0.4825 - val_auc: 0.8781 - 12s/epoch - 4ms/step
Epoch 56/100
3169/3169 - 12s - loss: 6.6555 - accuracy: 0.4969 - auc: 0.8843 - val_loss: 1.1470 - val_accuracy: 0.4852 - val_auc: 0.8806 - 12s/epoch - 4ms/step
Epoch 57/100
3169/3169 - 13s - loss: 6.6346 - accuracy: 0.4992 - auc: 0.8852 - val_loss: 1.1487 - val_accuracy: 0.4884 - val_auc: 0.8804 - 13s/epoch - 4ms/step
Epoch 58/100
3169/3169 - 12s - loss: 6.5984 - accuracy: 0.5002 - auc: 0.8854 - val_loss: 1.1496 - val_accuracy: 0.4879 - val_auc: 0.8806 - 12s/epoch - 4ms/step
Epoch 59/100
3169/3169 - 12s - loss: 6.5793 - accuracy: 0.5004 - auc: 0.8858 - val_loss: 1.1430 - val_accuracy: 0.4899 - val_auc: 0.8818 - 12s/epoch - 4ms/step
Epoch 60/100
3169/3169 - 12s - loss: 6.5508 - accuracy: 0.5009 - auc: 0.8862 - val_loss: 1.1375 - val_accuracy: 0.4918 - val_auc: 0.8829 - 12s/epoch - 4ms/step
Epoch 61/100
3169/3169 - 12s - loss: 6.5200 - accuracy: 0.5026 - auc: 0.8870 - val_loss: 1.1413 - val_accuracy: 0.4919 - val_auc: 0.8824 - 12s/epoch - 4ms/step
Epoch 62/100
3169/3169 - 12s - loss: 6.5148 - accuracy: 0.5043 - auc: 0.8871 - val_loss: 1.1446 - val_accuracy: 0.4889 - val_auc: 0.8814 - 12s/epoch - 4ms/step
Epoch 63/100
3169/3169 - 12s - loss: 6.4885 - accuracy: 0.5044 - auc: 0.8881 - val_loss: 1.1382 - val_accuracy: 0.4918 - val_auc: 0.8826 - 12s/epoch - 4ms/step
Epoch 64/100
3169/3169 - 12s - loss: 6.4309 - accuracy: 0.5053 - auc: 0.8883 - val_loss: 1.1425 - val_accuracy: 0.4885 - val_auc: 0.8822 - 12s/epoch - 4ms/step
Epoch 65/100
3169/3169 - 12s - loss: 6.4270 - accuracy: 0.5071 - auc: 0.8891 - val_loss: 1.1425 - val_accuracy: 0.4926 - val_auc: 0.8826 - 12s/epoch - 4ms/step
Epoch 66/100
3169/3169 - 12s - loss: 6.4116 - accuracy: 0.5069 - auc: 0.8892 - val_loss: 1.1418 - val_accuracy: 0.4900 - val_auc: 0.8823 - 12s/epoch - 4ms/step
Epoch 67/100
3169/3169 - 12s - loss: 6.3855 - accuracy: 0.5069 - auc: 0.8896 - val_loss: 1.1360 - val_accuracy: 0.4942 - val_auc: 0.8838 - 12s/epoch - 4ms/step
Epoch 68/100
3169/3169 - 12s - loss: 6.3426 - accuracy: 0.5094 - auc: 0.8905 - val_loss: 1.1360 - val_accuracy: 0.4931 - val_auc: 0.8836 - 12s/epoch - 4ms/step
Epoch 69/100
3169/3169 - 12s - loss: 6.3108 - accuracy: 0.5102 - auc: 0.8910 - val_loss: 1.1364 - val_accuracy: 0.4946 - val_auc: 0.8839 - 12s/epoch - 4ms/step
Epoch 70/100
3169/3169 - 12s - loss: 6.3049 - accuracy: 0.5105 - auc: 0.8909 - val_loss: 1.1246 - val_accuracy: 0.4984 - val_auc: 0.8862 - 12s/epoch - 4ms/step
Epoch 71/100
3169/3169 - 12s - loss: 6.2819 - accuracy: 0.5105 - auc: 0.8918 - val_loss: 1.1338 - val_accuracy: 0.4965 - val_auc: 0.8848 - 12s/epoch - 4ms/step
Epoch 72/100
3169/3169 - 12s - loss: 6.2571 - accuracy: 0.5109 - auc: 0.8918 - val_loss: 1.1305 - val_accuracy: 0.4962 - val_auc: 0.8852 - 12s/epoch - 4ms/step
Epoch 73/100
3169/3169 - 12s - loss: 6.2476 - accuracy: 0.5126 - auc: 0.8922 - val_loss: 1.1235 - val_accuracy: 0.4981 - val_auc: 0.8865 - 12s/epoch - 4ms/step
Epoch 74/100
3169/3169 - 13s - loss: 6.2087 - accuracy: 0.5137 - auc: 0.8930 - val_loss: 1.1252 - val_accuracy: 0.5015 - val_auc: 0.8866 - 13s/epoch - 4ms/step
Epoch 75/100
3169/3169 - 12s - loss: 6.1919 - accuracy: 0.5150 - auc: 0.8932 - val_loss: 1.1210 - val_accuracy: 0.5012 - val_auc: 0.8872 - 12s/epoch - 4ms/step
Epoch 76/100
3169/3169 - 12s - loss: 6.1675 - accuracy: 0.5167 - auc: 0.8938 - val_loss: 1.1194 - val_accuracy: 0.5038 - val_auc: 0.8879 - 12s/epoch - 4ms/step
Epoch 77/100
3169/3169 - 12s - loss: 6.1344 - accuracy: 0.5173 - auc: 0.8944 - val_loss: 1.1366 - val_accuracy: 0.4944 - val_auc: 0.8845 - 12s/epoch - 4ms/step
Epoch 78/100
3169/3169 - 12s - loss: 6.1222 - accuracy: 0.5170 - auc: 0.8946 - val_loss: 1.1273 - val_accuracy: 0.4975 - val_auc: 0.8861 - 12s/epoch - 4ms/step
Epoch 79/100
3169/3169 - 12s - loss: 6.0835 - accuracy: 0.5197 - auc: 0.8953 - val_loss: 1.1268 - val_accuracy: 0.4994 - val_auc: 0.8866 - 12s/epoch - 4ms/step
Epoch 80/100
3169/3169 - 13s - loss: 6.0967 - accuracy: 0.5182 - auc: 0.8951 - val_loss: 1.1287 - val_accuracy: 0.5024 - val_auc: 0.8863 - 13s/epoch - 4ms/step
Epoch 81/100
3169/3169 - 12s - loss: 6.0538 - accuracy: 0.5210 - auc: 0.8958 - val_loss: 1.1287 - val_accuracy: 0.4983 - val_auc: 0.8860 - 12s/epoch - 4ms/step
Epoch 82/100
3169/3169 - 12s - loss: 6.0255 - accuracy: 0.5209 - auc: 0.8964 - val_loss: 1.1180 - val_accuracy: 0.5054 - val_auc: 0.8885 - 12s/epoch - 4ms/step
Epoch 83/100
3169/3169 - 12s - loss: 5.9945 - accuracy: 0.5209 - auc: 0.8966 - val_loss: 1.1102 - val_accuracy: 0.5068 - val_auc: 0.8897 - 12s/epoch - 4ms/step
Epoch 84/100
3169/3169 - 12s - loss: 5.9736 - accuracy: 0.5232 - auc: 0.8972 - val_loss: 1.1121 - val_accuracy: 0.5051 - val_auc: 0.8896 - 12s/epoch - 4ms/step
Epoch 85/100
3169/3169 - 12s - loss: 5.9699 - accuracy: 0.5228 - auc: 0.8973 - val_loss: 1.1190 - val_accuracy: 0.5038 - val_auc: 0.8887 - 12s/epoch - 4ms/step
Epoch 86/100
3169/3169 - 12s - loss: 5.9586 - accuracy: 0.5232 - auc: 0.8975 - val_loss: 1.1147 - val_accuracy: 0.5049 - val_auc: 0.8891 - 12s/epoch - 4ms/step
Epoch 87/100
3169/3169 - 12s - loss: 5.9343 - accuracy: 0.5239 - auc: 0.8978 - val_loss: 1.1220 - val_accuracy: 0.5027 - val_auc: 0.8883 - 12s/epoch - 4ms/step
Epoch 88/100
3169/3169 - 12s - loss: 5.8928 - accuracy: 0.5256 - auc: 0.8987 - val_loss: 1.1123 - val_accuracy: 0.5111 - val_auc: 0.8902 - 12s/epoch - 4ms/step
Epoch 89/100
3169/3169 - 12s - loss: 5.8686 - accuracy: 0.5257 - auc: 0.8989 - val_loss: 1.1118 - val_accuracy: 0.5064 - val_auc: 0.8901 - 12s/epoch - 4ms/step
Epoch 90/100
3169/3169 - 12s - loss: 5.8582 - accuracy: 0.5277 - auc: 0.8995 - val_loss: 1.1055 - val_accuracy: 0.5098 - val_auc: 0.8913 - 12s/epoch - 4ms/step
Epoch 91/100
3169/3169 - 12s - loss: 5.8352 - accuracy: 0.5280 - auc: 0.8996 - val_loss: 1.1036 - val_accuracy: 0.5088 - val_auc: 0.8916 - 12s/epoch - 4ms/step
Epoch 92/100
3169/3169 - 12s - loss: 5.8186 - accuracy: 0.5274 - auc: 0.8999 - val_loss: 1.1128 - val_accuracy: 0.5066 - val_auc: 0.8901 - 12s/epoch - 4ms/step
Epoch 93/100
3169/3169 - 12s - loss: 5.8003 - accuracy: 0.5278 - auc: 0.9002 - val_loss: 1.1047 - val_accuracy: 0.5076 - val_auc: 0.8912 - 12s/epoch - 4ms/step
Epoch 94/100
3169/3169 - 12s - loss: 5.7763 - accuracy: 0.5297 - auc: 0.9008 - val_loss: 1.1205 - val_accuracy: 0.5042 - val_auc: 0.8891 - 12s/epoch - 4ms/step
Epoch 95/100
3169/3169 - 12s - loss: 5.7656 - accuracy: 0.5280 - auc: 0.9006 - val_loss: 1.1119 - val_accuracy: 0.5051 - val_auc: 0.8904 - 12s/epoch - 4ms/step
Epoch 96/100
3169/3169 - 12s - loss: 5.7510 - accuracy: 0.5304 - auc: 0.9012 - val_loss: 1.1095 - val_accuracy: 0.5083 - val_auc: 0.8912 - 12s/epoch - 4ms/step
Epoch 97/100
3169/3169 - 12s - loss: 5.7480 - accuracy: 0.5302 - auc: 0.9013 - val_loss: 1.1021 - val_accuracy: 0.5091 - val_auc: 0.8922 - 12s/epoch - 4ms/step
Epoch 98/100
3169/3169 - 12s - loss: 5.7046 - accuracy: 0.5310 - auc: 0.9019 - val_loss: 1.1050 - val_accuracy: 0.5097 - val_auc: 0.8920 - 12s/epoch - 4ms/step
Epoch 99/100
3169/3169 - 12s - loss: 5.7046 - accuracy: 0.5324 - auc: 0.9022 - val_loss: 1.0983 - val_accuracy: 0.5136 - val_auc: 0.8930 - 12s/epoch - 4ms/step
Epoch 100/100
3169/3169 - 12s - loss: 5.6727 - accuracy: 0.5335 - auc: 0.9026 - val_loss: 1.1125 - val_accuracy: 0.5039 - val_auc: 0.8907 - 12s/epoch - 4ms/step
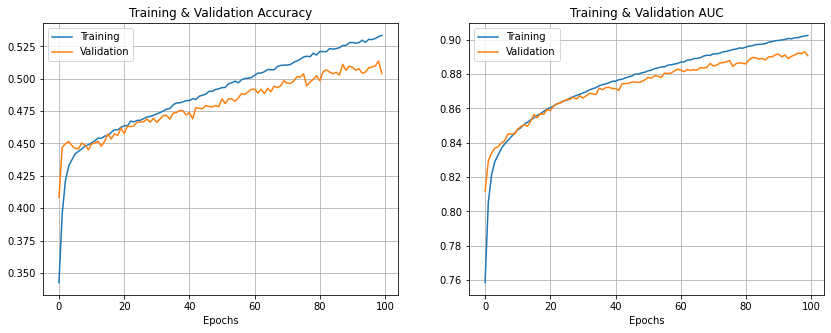
结果
让我们绘制训练和验证的 AUC 和准确率。
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(14, 5))
axs[0].plot(range(EPOCHS), history.history["accuracy"], label="训练")
axs[0].plot(range(EPOCHS), history.history["val_accuracy"], label="验证")
axs[0].set_xlabel("轮次")
axs[0].set_title("训练与验证准确率")
axs[0].legend()
axs[0].grid(True)
axs[1].plot(range(EPOCHS), history.history["auc"], label="训练")
axs[1].plot(range(EPOCHS), history.history["val_auc"], label="验证")
axs[1].set_xlabel("轮次")
axs[1].set_title("训练与验证 AUC")
axs[1].legend()
axs[1].grid(True)
plt.show()
评估
train_loss, train_acc, train_auc = model.evaluate(train_ds)
valid_loss, valid_acc, valid_auc = model.evaluate(valid_ds)
3169/3169 [==============================] - 10s 3ms/step - loss: 1.0117 - accuracy: 0.5423 - auc: 0.9079
349/349 [==============================] - 1s 3ms/step - loss: 1.1125 - accuracy: 0.5039 - auc: 0.8907
让我们尝试将我们的模型性能与 Yamnet 的表现进行比较,使用其中一种 Yamnet 度量(d-prime)。 Yamnet 的 d-prime 值为 2.318。 让我们检查我们模型的性能。
# 以下函数从 AUC 计算 d-prime 分数
def d_prime(auc):
standard_normal = stats.norm()
d_prime = standard_normal.ppf(auc) * np.sqrt(2.0)
return d_prime
print(
"训练 d-prime: {0:.3f}, 验证 d-prime: {1:.3f}".format(
d_prime(train_auc), d_prime(valid_auc)
)
)
训练 d-prime: 1.878, 验证 d-prime: 1.740
我们可以看到模型获得了以下结果:
| 结果 | 训练 | 验证 |
|---|---|---|
| 准确率 | 54% | 51% |
| AUC | 0.91 | 0.89 |
| d-prime | 1.882 | 1.740 |
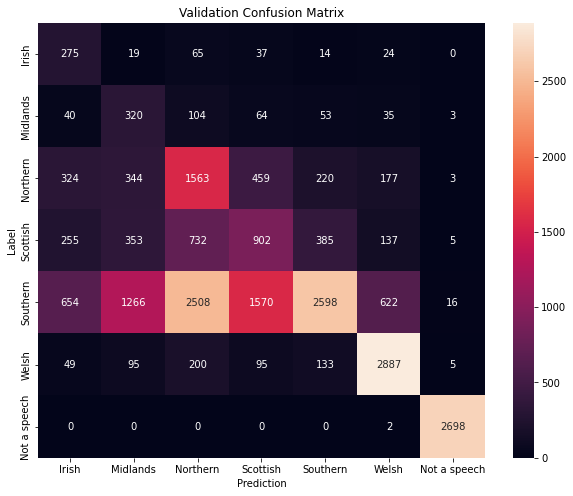
混淆矩阵
现在让我们绘制验证数据集的混淆矩阵。
混淆矩阵让我们看到每个类别不仅有多少样本被正确分类, 还看到了这些样本与其他类别的混淆情况。
它使我们能够计算每个类别的精确率和召回率。
# 创建 x 和 y 张量
x_valid = None
y_valid = None
for x, y in iter(valid_ds):
if x_valid is None:
x_valid = x.numpy()
y_valid = y.numpy()
else:
x_valid = np.concatenate((x_valid, x.numpy()), axis=0)
y_valid = np.concatenate((y_valid, y.numpy()), axis=0)
# 生成预测
y_pred = model.predict(x_valid)
# 计算混淆矩阵
confusion_mtx = tf.math.confusion_matrix(
np.argmax(y_valid, axis=1), np.argmax(y_pred, axis=1)
)
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(
confusion_mtx, xticklabels=class_names, yticklabels=class_names, annot=True, fmt="g"
)
plt.xlabel("预测")
plt.ylabel("标签")
plt.title("验证混淆矩阵")
plt.show()
精确率和召回率
对于每一个类别:
- 召回率是正确分类样本的比例,即它显示该特定类别模型能够检测到多少样本。 它是对角元素与该行所有元素之和的比例。
- 精确率显示分类器的准确性。它是被预测为属于该类的样本中正确预测样本的比例。 它是对角元素与该列所有元素之和的比例。
for i, label in enumerate(class_names):
precision = confusion_mtx[i, i] / np.sum(confusion_mtx[:, i])
recall = confusion_mtx[i, i] / np.sum(confusion_mtx[i, :])
print(
"{0:15} 精确率:{1:.2f}%; 召回率:{2:.2f}%".format(
label, precision * 100, recall * 100
)
)
Irish 精确率:17.22%; 召回率:63.36%
Midlands 精确率:13.35%; 召回率:51.70%
Northern 精确率:30.22%; 召回率:50.58%
Scottish 精确率:28.85%; 召回率:32.57%
Southern 精确率:76.34%; 召回率:28.14%
Welsh 精确率:74.33%; 召回率:83.34%
Not a speech 精确率:98.83%; 召回率:99.93%
在测试数据上运行推理
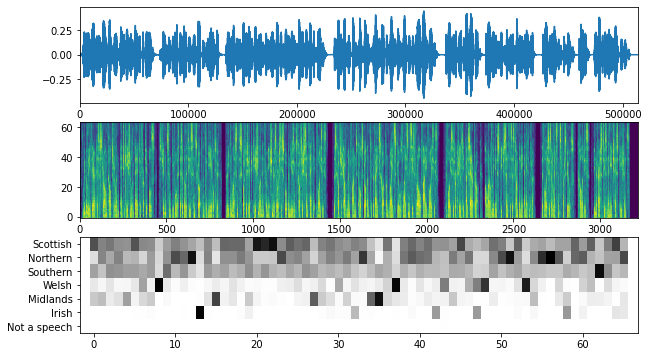
现在让我们对单个音频文件进行测试。 让我们检查这个来自 The Scottish Voice 的示例。
我们将:
- 下载 mp3 文件。
- 将其转换为 16k wav 文件。
- 在 wav 文件上运行模型。
- 绘制结果。
filename = "audio-sample-Stuart"
url = "https://www.thescottishvoice.org.uk/files/cm/files/"
if os.path.exists(filename + ".wav") == False:
print(f"从 {url} 下载 {filename}.mp3")
command = f"wget {url}{filename}.mp3"
os.system(command)
print(f"将 mp3 转换为 wav 并重采样为 16 kHZ")
command = (
f"ffmpeg -hide_banner -loglevel panic -y -i {filename}.mp3 -acodec "
f"pcm_s16le -ac 1 -ar 16000 {filename}.wav"
)
os.system(command)
filename = filename + ".wav"
从 https://www.thescottishvoice.org.uk/files/cm/files/ 下载 audio-sample-Stuart.mp3
将 mp3 转换为 wav,并重采样到 16 kHZ
下面的函数 yamnet_class_names_from_csv 是从这个 Yamnet Notebook 复制并做了非常小的修改。
def yamnet_class_names_from_csv(yamnet_class_map_csv_text):
"""返回与得分向量对应的类别名称列表。"""
yamnet_class_map_csv = io.StringIO(yamnet_class_map_csv_text)
yamnet_class_names = [
name for (class_index, mid, name) in csv.reader(yamnet_class_map_csv)
]
yamnet_class_names = yamnet_class_names[1:] # 跳过 CSV 头
return yamnet_class_names
yamnet_class_map_path = yamnet_model.class_map_path().numpy()
yamnet_class_names = yamnet_class_names_from_csv(
tf.io.read_file(yamnet_class_map_path).numpy().decode("utf-8")
)
def calculate_number_of_non_speech(scores):
number_of_non_speech = tf.math.reduce_sum(
tf.where(tf.math.argmax(scores, axis=1, output_type=tf.int32) != 0, 1, 0)
)
return number_of_non_speech
def filename_to_predictions(filename):
# 加载 16k 的音频波形
audio_wav = load_16k_audio_wav(filename)
# 获取音频嵌入和得分。
scores, embeddings, mel_spectrogram = yamnet_model(audio_wav)
print(
"在 {} 个样本中,{} 个不是语音".format(
scores.shape[0], calculate_number_of_non_speech(scores)
)
)
# 用嵌入作为输入预测口音识别模型的输出
predictions = model.predict(embeddings)
return audio_wav, predictions, mel_spectrogram
让我们在音频文件上运行模型:
audio_wav, predictions, mel_spectrogram = filename_to_predictions(filename)
infered_class = class_names[predictions.mean(axis=0).argmax()]
print(f"主要口音是: {infered_class} 英语")
在 66 个样本中,0 个不是语音
主要口音是: 苏格兰英语
请听音频
Audio(audio_wav, rate=16000)
下面的函数是从这个 Yamnet notebook 复制并调整以满足我们的需要。
该函数绘制以下内容:
- 音频波形
- Mel 谱图
- 每个时间步骤的预测
plt.figure(figsize=(10, 6))
# 绘制波形。
plt.subplot(3, 1, 1)
plt.plot(audio_wav)
plt.xlim([0, len(audio_wav)])
# 绘制模型返回的对数 Mel 谱图。
plt.subplot(3, 1, 2)
plt.imshow(
mel_spectrogram.numpy().T, aspect="auto", interpolation="nearest", origin="lower"
)
# 绘制并标记前 N 个得分最高类别的模型输出分数。
mean_predictions = np.mean(predictions, axis=0)
top_class_indices = np.argsort(mean_predictions)[::-1]
plt.subplot(3, 1, 3)
plt.imshow(
predictions[:, top_class_indices].T,
aspect="auto",
interpolation="nearest",
cmap="gray_r",
)
# patch_padding = (PATCH_WINDOW_SECONDS / 2) / PATCH_HOP_SECONDS
# 来自模型文档的值
patch_padding = (0.025 / 2) / 0.01
plt.xlim([-patch_padding - 0.5, predictions.shape[0] + patch_padding - 0.5])
# 标记前 N 类。
yticks = range(0, len(class_names), 1)
plt.yticks(yticks, [class_names[top_class_indices[x]] for x in yticks])
_ = plt.ylim(-0.5 + np.array([len(class_names), 0]))