WGAN-GP与R-GCN生成小分子图
作者: akensert
创建日期: 2021/06/30
最后修改: 2021/06/30
描述: 完整实现WGAN-GP与R-GCN以生成新颖分子。

介绍
在本教程中,我们实现了一个图的生成模型,并使用它来生成新颖的分子。
动机:新药的开发(分子)可能非常耗时和昂贵。使用深度学习模型可以缓解寻找良好候选药物的过程,通过预测已知分子的性质(例如,溶解度、毒性、对目标蛋白的亲和力等)。由于可能的分子数量庞大,我们搜索/探索分子的空间仅是整个空间的一部分。因此,实施能够学习生成新分子的生成模型是相当有利的(这些分子在其他情况下将永远未被探索)。
参考文献(实现)
本教程中的实现基于/受到 MolGAN论文和DeepChem的 基础MolGAN的启发。
进一步阅读(生成模型)
最近对分子图的生成模型的实现还包括 Mol-CycleGAN, GraphVAE和 JT-VAE。有关生成对抗网络的更多信息,请参见 GAN, WGAN和WGAN-GP。
设置
安装RDKit
RDKit是用C++和Python编写的化学信息学和机器学习软件的集合。在本教程中,RDKit用于方便和高效地将 SMILES转换为 分子对象,然后从中获取原子和键的集合。
SMILES以ASCII字符串的形式表达给定分子的结构。 SMILES字符串是一个紧凑编码,对于较小的分子来说,相对易于人类阅读。将分子编码为字符串既减轻了数据库和/或网络搜索给定分子的负担,又便利了搜索。RDKit使用算法 准确地将给定的SMILES转换为分子对象,然后可以用来计算大量的分子性质/特征。
注意,RDKit通常通过Conda安装。 然而,得益于 rdkit_platform_wheels,rdkit现在(为了本教程的方便)可以轻松通过pip安装,如下所示:
pip -q install rdkit-pypi
并且为了方便可视化分子对象,需要安装Pillow:
pip -q install Pillow
导入包
from rdkit import Chem, RDLogger
from rdkit.Chem.Draw import IPythonConsole, MolsToGridImage
import numpy as np
import tensorflow as tf
from tensorflow import keras
RDLogger.DisableLog("rdApp.*")
数据集
本教程中使用的数据集是一个 量子力学数据集(QM9),来自 MoleculeNet。尽管数据集中包含许多特征和标签列,但我们将只关注 SMILES 列。QM9数据集是生成图的一个很好的入门数据集,因为在一个分子中找到的重(非氢)原子的最大数量仅为九。
csv_path = tf.keras.utils.get_file(
"qm9.csv", "https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/qm9.csv"
)
data = []
with open(csv_path, "r") as f:
for line in f.readlines()[1:]:
data.append(line.split(",")[1])
# 让我们看看数据集中的一个分子
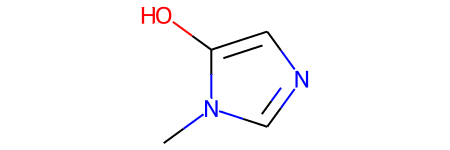
smiles = data[1000]
print("SMILES:", smiles)
molecule = Chem.MolFromSmiles(smiles)
print("重原子数量:", molecule.GetNumHeavyAtoms())
molecule
SMILES: Cn1cncc1O
重原子数量: 7
定义辅助函数
这些辅助函数将有助于将SMILES转换为图形以及将图形转换为分子对象。
表示分子图。分子可以自然地表示为无向图 G = (V, E),其中 V 是顶点(原子)的集合,E 是边(键)的集合。对于此实现,每个图(分子)将被表示为邻接张量 A,它编码了原子对的存在/不存在及其一热编码的键类型,拉伸了一个额外的维度,以及特征张量 H,对每个原子进行一热编码其原子类型。注意,由于氢原子可以通过RDKit推断,因此氢原子被排除在 A 和 H 之外,以便于建模。
atom_mapping = {
"C": 0,
0: "C",
"N": 1,
1: "N",
"O": 2,
2: "O",
"F": 3,
3: "F",
}
bond_mapping = {
"SINGLE": 0,
0: Chem.BondType.SINGLE,
"DOUBLE": 1,
1: Chem.BondType.DOUBLE,
"TRIPLE": 2,
2: Chem.BondType.TRIPLE,
"AROMATIC": 3,
3: Chem.BondType.AROMATIC,
}
NUM_ATOMS = 9 # 原子的最大数量
ATOM_DIM = 4 + 1 # 原子类型的数量
BOND_DIM = 4 + 1 # 键类型的数量
LATENT_DIM = 64 # 潜在空间的大小
def smiles_to_graph(smiles):
# 将SMILES转换为分子对象
molecule = Chem.MolFromSmiles(smiles)
# 初始化邻接和特征张量
adjacency = np.zeros((BOND_DIM, NUM_ATOMS, NUM_ATOMS), "float32")
features = np.zeros((NUM_ATOMS, ATOM_DIM), "float32")
# 遍历分子中的每个原子
for atom in molecule.GetAtoms():
i = atom.GetIdx()
atom_type = atom_mapping[atom.GetSymbol()]
features[i] = np.eye(ATOM_DIM)[atom_type]
# 遍历一跳邻居
for neighbor in atom.GetNeighbors():
j = neighbor.GetIdx()
bond = molecule.GetBondBetweenAtoms(i, j)
bond_type_idx = bond_mapping[bond.GetBondType().name]
adjacency[bond_type_idx, [i, j], [j, i]] = 1
# 没有键的地方,最后一个通道加1(表示“非键”)
# 注意:通道优先
adjacency[-1, np.sum(adjacency, axis=0) == 0] = 1
# 没有原子的地方,最后一列加1(表示“非原子”)
features[np.where(np.sum(features, axis=1) == 0)[0], -1] = 1
return adjacency, features
def graph_to_molecule(graph):
# 解包图形
adjacency, features = graph
# RWMol是一个旨在被编辑的分子对象
molecule = Chem.RWMol()
# 删除“无原子”和没有键的原子
keep_idx = np.where(
(np.argmax(features, axis=1) != ATOM_DIM - 1)
& (np.sum(adjacency[:-1], axis=(0, 1)) != 0)
)[0]
features = features[keep_idx]
adjacency = adjacency[:, keep_idx, :][:, :, keep_idx]
# 向分子中添加原子
for atom_type_idx in np.argmax(features, axis=1):
atom = Chem.Atom(atom_mapping[atom_type_idx])
_ = molecule.AddAtom(atom)
# 在分子中添加原子之间的键;基于[symmetric]邻接张量的上三角
(bonds_ij, atoms_i, atoms_j) = np.where(np.triu(adjacency) == 1)
for (bond_ij, atom_i, atom_j) in zip(bonds_ij, atoms_i, atoms_j):
if atom_i == atom_j or bond_ij == BOND_DIM - 1:
continue
bond_type = bond_mapping[bond_ij]
molecule.AddBond(int(atom_i), int(atom_j), bond_type)
# 对分子进行清理;有关清理的更多信息,请参见
# https://www.rdkit.org/docs/RDKit_Book.html#molecular-sanitization
flag = Chem.SanitizeMol(molecule, catchErrors=True)
# 我们要严格。如果清理失败,返回None
if flag != Chem.SanitizeFlags.SANITIZE_NONE:
return None
return molecule
# 测试辅助函数
graph_to_molecule(smiles_to_graph(smiles))
生成训练集
为了节省训练时间,我们只使用QM9数据集的十分之一。
adjacency_tensor, feature_tensor = [], []
for smiles in data[::10]:
adjacency, features = smiles_to_graph(smiles)
adjacency_tensor.append(adjacency)
feature_tensor.append(features)
adjacency_tensor = np.array(adjacency_tensor)
feature_tensor = np.array(feature_tensor)
print("adjacency_tensor.shape =", adjacency_tensor.shape)
print("feature_tensor.shape =", feature_tensor.shape)
adjacency_tensor.shape = (13389, 5, 9, 9)
feature_tensor.shape = (13389, 9, 5)
模型
这个想法是通过WGAN-GP实现一个生成器网络和一个判别器网络,最终生成一个可以生成小型新颖分子(小图)的生成器网络。
生成器网络需要能够将一个向量z映射(对于批次中的每个示例)到一个3-D邻接张量(A)和2-D特征张量(H)。为此,z首先会经过一个全连接网络,输出将进一步经过两个独立的全连接网络。每个全连接网络将输出(对于批次中的每个示例)一个经过tanh激活的向量,随后通过reshape和softmax以匹配多维邻接/特征张量的形式。
由于判别器网络将接收来自生成器或训练集的图(A,H)作为输入,我们需要实现图卷积层,以便对图进行操作。这意味着输入到判别器网络的图将首先经过图卷积层,然后经过一个平均池化层,最后是几个全连接层。最终输出应为一个标量(对于批次中的每个示例),表示相关输入的“真实度”(在这种情况下是“假”或“真实”分子)。
图生成器
def GraphGenerator(
dense_units, dropout_rate, latent_dim, adjacency_shape, feature_shape,
):
z = keras.layers.Input(shape=(LATENT_DIM,))
# 通过一个或多个全连接层进行传播
x = z
for units in dense_units:
x = keras.layers.Dense(units, activation="tanh")(x)
x = keras.layers.Dropout(dropout_rate)(x)
# 将前一层的输出 (x) 映射到 [连续的] 邻接张量 (x_adjacency)
x_adjacency = keras.layers.Dense(tf.math.reduce_prod(adjacency_shape))(x)
x_adjacency = keras.layers.Reshape(adjacency_shape)(x_adjacency)
# 对最后两个维度进行对称化
x_adjacency = (x_adjacency + tf.transpose(x_adjacency, (0, 1, 3, 2))) / 2
x_adjacency = keras.layers.Softmax(axis=1)(x_adjacency)
# 将前一层的输出 (x) 映射到 [连续的] 特征张量 (x_features)
x_features = keras.layers.Dense(tf.math.reduce_prod(feature_shape))(x)
x_features = keras.layers.Reshape(feature_shape)(x_features)
x_features = keras.layers.Softmax(axis=2)(x_features)
return keras.Model(inputs=z, outputs=[x_adjacency, x_features], name="Generator")
generator = GraphGenerator(
dense_units=[128, 256, 512],
dropout_rate=0.2,
latent_dim=LATENT_DIM,
adjacency_shape=(BOND_DIM, NUM_ATOMS, NUM_ATOMS),
feature_shape=(NUM_ATOMS, ATOM_DIM),
)
generator.summary()
Model: "Generator"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 64)] 0
__________________________________________________________________________________________________
dense (Dense) (None, 128) 8320 input_1[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 128) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 256) 33024 dropout[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 256) 0 dense_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 512) 131584 dropout_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 512) 0 dense_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 405) 207765 dropout_2[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, 5, 9, 9) 0 dense_3[0][0]
__________________________________________________________________________________________________
tf.compat.v1.transpose (TFOpLam (None, 5, 9, 9) 0 reshape[0][0]
__________________________________________________________________________________________________
tf.__operators__.add (TFOpLambd (None, 5, 9, 9) 0 reshape[0][0]
tf.compat.v1.transpose[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 45) 23085 dropout_2[0][0]
__________________________________________________________________________________________________
tf.math.truediv (TFOpLambda) (None, 5, 9, 9) 0 tf.__operators__.add[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 9, 5) 0 dense_4[0][0]
__________________________________________________________________________________________________
softmax (Softmax) (None, 5, 9, 9) 0 tf.math.truediv[0][0]
__________________________________________________________________________________________________
softmax_1 (Softmax) (None, 9, 5) 0 reshape_1[0][0]
==================================================================================================
总参数: 403,778
可训练参数: 403,778
不可训练参数: 0
__________________________________________________________________________________________________
</div>
### 图判别器
**图卷积层**。 [关系图卷积层](https://arxiv.org/abs/1703.06103) 实现了非线性变换的邻域聚合。我们可以这样定义这些层:
`H^{l+1} = σ(D^{-1} @ A @ H^{l+1} @ W^{l})`
其中 `σ` 表示非线性变换(通常为 ReLU 激活),`A` 为邻接张量,`H^{l}` 为 `l:th` 层的特征张量,`D^{-1}` 为 `A` 的逆对角度数张量,`W^{l}` 为 `l:th` 层的可训练权重张量。具体来说,对于每种键类型(关系),度数张量在对角线中表示附着在每个原子上的键的数量。注意,在本教程中,`D^{-1}` 被省略,原因有两个:(1)如何在生成器生成的连续邻接张量上应用这种归一化并不明显,和 (2)没有归一化的 WGAN 性能似乎也很好。此外,与 [原始论文](https://arxiv.org/abs/1703.06103) 相比,没有定义自环,因为我们不想训练生成器来预测“自我键合”。
```python
class RelationalGraphConvLayer(keras.layers.Layer):
def __init__(
self,
units=128,
activation="relu",
use_bias=False,
kernel_initializer="glorot_uniform",
bias_initializer="zeros",
kernel_regularizer=None,
bias_regularizer=None,
**kwargs
):
super().__init__(**kwargs)
self.units = units
self.activation = keras.activations.get(activation)
self.use_bias = use_bias
self.kernel_initializer = keras.initializers.get(kernel_initializer)
self.bias_initializer = keras.initializers.get(bias_initializer)
self.kernel_regularizer = keras.regularizers.get(kernel_regularizer)
self.bias_regularizer = keras.regularizers.get(bias_regularizer)
def build(self, input_shape):
bond_dim = input_shape[0][1]
atom_dim = input_shape[1][2]
self.kernel = self.add_weight(
shape=(bond_dim, atom_dim, self.units),
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
trainable=True,
name="W",
dtype=tf.float32,
)
if self.use_bias:
self.bias = self.add_weight(
shape=(bond_dim, 1, self.units),
initializer=self.bias_initializer,
regularizer=self.bias_regularizer,
trainable=True,
name="b",
dtype=tf.float32,
)
self.built = True
def call(self, inputs, training=False):
adjacency, features = inputs
# 从邻居聚合信息
x = tf.matmul(adjacency, features[:, None, :, :])
# 应用线性变换
x = tf.matmul(x, self.kernel)
if self.use_bias:
x += self.bias
# 减少键类型维度
x_reduced = tf.reduce_sum(x, axis=1)
# 应用非线性变换
return self.activation(x_reduced)
def GraphDiscriminator(
gconv_units, dense_units, dropout_rate, adjacency_shape, feature_shape
):
adjacency = keras.layers.Input(shape=adjacency_shape)
features = keras.layers.Input(shape=feature_shape)
# 通过一个或多个图卷积层传播
features_transformed = features
for units in gconv_units:
features_transformed = RelationalGraphConvLayer(units)(
[adjacency, features_transformed]
)
# 将分子的 2-D 表示减少为 1-D
x = keras.layers.GlobalAveragePooling1D()(features_transformed)
# 通过一个或多个密集连接层进行传播
for units in dense_units:
x = keras.layers.Dense(units, activation="relu")(x)
x = keras.layers.Dropout(dropout_rate)(x)
# 对于每个分子,输出一个表达
# 输入分子的“真实程度”的标量值
x_out = keras.layers.Dense(1, dtype="float32")(x)
return keras.Model(inputs=[adjacency, features], outputs=x_out)
discriminator = GraphDiscriminator(
gconv_units=[128, 128, 128, 128],
dense_units=[512, 512],
dropout_rate=0.2,
adjacency_shape=(BOND_DIM, NUM_ATOMS, NUM_ATOMS),
feature_shape=(NUM_ATOMS, ATOM_DIM),
)
discriminator.summary()
模型: "model"
__________________________________________________________________________________________________
层 (类型) 输出形状 参数 # 连接到
==================================================================================================
input_2 (输入层) [(None, 5, 9, 9)] 0
__________________________________________________________________________________________________
input_3 (输入层) [(None, 9, 5)] 0
__________________________________________________________________________________________________
relational_graph_conv_layer (关系图卷积层) (None, 9, 128) 3200 input_2[0][0]
input_3[0][0]
__________________________________________________________________________________________________
relational_graph_conv_layer_1 (关系图卷积层) (None, 9, 128) 81920 input_2[0][0]
relational_graph_conv_layer[0][0]
__________________________________________________________________________________________________
relational_graph_conv_layer_2 (关系图卷积层) (None, 9, 128) 81920 input_2[0][0]
relational_graph_conv_layer_1[0][
__________________________________________________________________________________________________
relational_graph_conv_layer_3 (关系图卷积层) (None, 9, 128) 81920 input_2[0][0]
relational_graph_conv_layer_2[0][
__________________________________________________________________________________________________
global_average_pooling1d (全局平均池化层) (None, 128) 0 relational_graph_conv_layer_3[0][
__________________________________________________________________________________________________
dense_5 (密集层) (None, 512) 66048 global_average_pooling1d[0][0]
__________________________________________________________________________________________________
dropout_3 (丢弃层) (None, 512) 0 dense_5[0][0]
__________________________________________________________________________________________________
dense_6 (密集层) (None, 512) 262656 dropout_3[0][0]
__________________________________________________________________________________________________
dropout_4 (丢弃层) (None, 512) 0 dense_6[0][0]
__________________________________________________________________________________________________
dense_7 (密集层) (None, 1) 513 dropout_4[0][0]
==================================================================================================
总参数量: 578,177
可训练参数: 578,177
不可训练参数: 0
__________________________________________________________________________________________________
class GraphWGAN(keras.Model):
def __init__(
self,
generator,
discriminator,
discriminator_steps=1,
generator_steps=1,
gp_weight=10,
**kwargs
):
super().__init__(**kwargs)
self.generator = generator
self.discriminator = discriminator
self.discriminator_steps = discriminator_steps
self.generator_steps = generator_steps
self.gp_weight = gp_weight
self.latent_dim = self.generator.input_shape[-1]
def compile(self, optimizer_generator, optimizer_discriminator, **kwargs):
super().compile(**kwargs)
self.optimizer_generator = optimizer_generator
self.optimizer_discriminator = optimizer_discriminator
self.metric_generator = keras.metrics.Mean(name="loss_gen")
self.metric_discriminator = keras.metrics.Mean(name="loss_dis")
def train_step(self, inputs):
if isinstance(inputs[0], tuple):
inputs = inputs[0]
graph_real = inputs
self.batch_size = tf.shape(inputs[0])[0]
# 训练判别器一个或多个步骤
for _ in range(self.discriminator_steps):
z = tf.random.normal((self.batch_size, self.latent_dim))
with tf.GradientTape() as tape:
graph_generated = self.generator(z, training=True)
loss = self._loss_discriminator(graph_real, graph_generated)
grads = tape.gradient(loss, self.discriminator.trainable_weights)
self.optimizer_discriminator.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
self.metric_discriminator.update_state(loss)
# 训练生成器一个或多个步骤
for _ in range(self.generator_steps):
z = tf.random.normal((self.batch_size, self.latent_dim))
with tf.GradientTape() as tape:
graph_generated = self.generator(z, training=True)
loss = self._loss_generator(graph_generated)
grads = tape.gradient(loss, self.generator.trainable_weights)
self.optimizer_generator.apply_gradients(
zip(grads, self.generator.trainable_weights)
)
self.metric_generator.update_state(loss)
return {m.name: m.result() for m in self.metrics}
def _loss_discriminator(self, graph_real, graph_generated):
logits_real = self.discriminator(graph_real, training=True)
logits_generated = self.discriminator(graph_generated, training=True)
loss = tf.reduce_mean(logits_generated) - tf.reduce_mean(logits_real)
loss_gp = self._gradient_penalty(graph_real, graph_generated)
return loss + loss_gp * self.gp_weight
def _loss_generator(self, graph_generated):
logits_generated = self.discriminator(graph_generated, training=True)
return -tf.reduce_mean(logits_generated)
def _gradient_penalty(self, graph_real, graph_generated):
# 解压图
adjacency_real, features_real = graph_real
adjacency_generated, features_generated = graph_generated
# 生成插值图(adjacency_interp 和 features_interp)
alpha = tf.random.uniform([self.batch_size])
alpha = tf.reshape(alpha, (self.batch_size, 1, 1, 1))
adjacency_interp = (adjacency_real * alpha) + (1 - alpha) * adjacency_generated
alpha = tf.reshape(alpha, (self.batch_size, 1, 1))
features_interp = (features_real * alpha) + (1 - alpha) * features_generated
# 计算插值图的 logits
with tf.GradientTape() as tape:
tape.watch(adjacency_interp)
tape.watch(features_interp)
logits = self.discriminator(
[adjacency_interp, features_interp], training=True
)
# 计算相对于插值图的梯度
grads = tape.gradient(logits, [adjacency_interp, features_interp])
# 计算梯度惩罚
grads_adjacency_penalty = (1 - tf.norm(grads[0], axis=1)) ** 2
grads_features_penalty = (1 - tf.norm(grads[1], axis=2)) ** 2
return tf.reduce_mean(
tf.reduce_mean(grads_adjacency_penalty, axis=(-2, -1))
+ tf.reduce_mean(grads_features_penalty, axis=(-1))
)
wgan = GraphWGAN(generator, discriminator, discriminator_steps=1)
wgan.compile(
optimizer_generator=keras.optimizers.Adam(5e-4),
optimizer_discriminator=keras.optimizers.Adam(5e-4),
)
wgan.fit([adjacency_tensor, feature_tensor], epochs=10, batch_size=16)
纪元 1/10
837/837 [==============================] - 197s 226ms/step - loss_gen: 2.4626 - loss_dis: -4.3158
纪元 2/10
837/837 [==============================] - 188s 225ms/step - loss_gen: 1.2832 - loss_dis: -1.3941
纪元 3/10
837/837 [==============================] - 199s 237ms/step - loss_gen: 0.6742 - loss_dis: -1.2663
纪元 4/10
837/837 [==============================] - 187s 224ms/step - loss_gen: 0.5090 - loss_dis: -1.6628
纪元 5/10
837/837 [==============================] - 187s 223ms/step - loss_gen: 0.3686 - loss_dis: -1.4759
纪元 6/10
837/837 [==============================] - 199s 237ms/step - loss_gen: 0.6925 - loss_dis: -1.5122
纪元 7/10
837/837 [==============================] - 194s 232ms/step - loss_gen: 0.3966 - loss_dis: -1.5041
纪元 8/10
837/837 [==============================] - 195s 233ms/step - loss_gen: 0.3595 - loss_dis: -1.6277
纪元 9/10
837/837 [==============================] - 194s 232ms/step - loss_gen: 0.5862 - loss_dis: -1.7277
纪元 10/10
837/837 [==============================] - 185s 221ms/step - loss_gen: -0.1642 - loss_dis: -1.5273
<keras.callbacks.History at 0x7ff8daed3a90>
def sample(generator, batch_size):
z = tf.random.normal((batch_size, LATENT_DIM))
graph = generator.predict(z)
# 获取独热编码的邻接张量
adjacency = tf.argmax(graph[0], axis=1)
adjacency = tf.one_hot(adjacency, depth=BOND_DIM, axis=1)
# 从邻接中移除潜在的自环
adjacency = tf.linalg.set_diag(adjacency, tf.zeros(tf.shape(adjacency)[:-1]))
# 获取独热编码的特征张量
features = tf.argmax(graph[1], axis=2)
features = tf.one_hot(features, depth=ATOM_DIM, axis=2)
return [
graph_to_molecule([adjacency[i].numpy(), features[i].numpy()])
for i in range(batch_size)
]
molecules = sample(wgan.generator, batch_size=48)
MolsToGridImage(
[m for m in molecules if m is not None][:25], molsPerRow=5, subImgSize=(150, 150)
)