内存高效的推荐系统嵌入
作者: Khalid Salama
创建日期: 2021/02/15
最后修改: 2023/11/15
描述: 使用组合和混合维度的嵌入创建内存高效的推荐模型。

介绍
此示例演示了两种技术,旨在通过减少嵌入表的大小来构建内存高效的推荐模型,而不牺牲模型的有效性:
- 商数-余数技巧,由Hao-Jun Michael Shi等人提出, 通过减少需要存储的嵌入向量数量,尽管没有显式定义,每个项目仍能产生独特的嵌入向量。
- 混合维度嵌入,由Antonio Ginart等人提出, 通过存储具有混合维度的嵌入向量,其中不太受欢迎的项目具有降低维度的嵌入。
我们使用Movielens数据集的1M版本。 该数据集包含约100万条来自6000个用户对4000部电影的评分。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
from zipfile import ZipFile
from urllib.request import urlretrieve
import numpy as np
import pandas as pd
import tensorflow as tf
import keras
from keras import layers
from keras.layers import StringLookup
import matplotlib.pyplot as plt
准备数据
下载和处理数据
urlretrieve("http://files.grouplens.org/datasets/movielens/ml-1m.zip", "movielens.zip")
ZipFile("movielens.zip", "r").extractall()
ratings_data = pd.read_csv(
"ml-1m/ratings.dat",
sep="::",
names=["user_id", "movie_id", "rating", "unix_timestamp"],
)
ratings_data["movie_id"] = ratings_data["movie_id"].apply(lambda x: f"movie_{x}")
ratings_data["user_id"] = ratings_data["user_id"].apply(lambda x: f"user_{x}")
ratings_data["rating"] = ratings_data["rating"].apply(lambda x: float(x))
del ratings_data["unix_timestamp"]
print(f"用户数量: {len(ratings_data.user_id.unique())}")
print(f"电影数量: {len(ratings_data.movie_id.unique())}")
print(f"评分数量: {len(ratings_data.index)}")
/var/folders/8n/8w8cqnvj01xd4ghznl11nyn000_93_/T/ipykernel_33554/2288473197.py:4: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
ratings_data = pd.read_csv(
用户数量: 6040
电影数量: 3706
评分数量: 1000209
创建训练和验证数据集分割
random_selection = np.random.rand(len(ratings_data.index)) <= 0.85
train_data = ratings_data[random_selection]
eval_data = ratings_data[~random_selection]
train_data.to_csv("train_data.csv", index=False, sep="|", header=False)
eval_data.to_csv("eval_data.csv", index=False, sep="|", header=False)
print(f"训练数据分割: {len(train_data.index)}")
print(f"验证数据分割: {len(eval_data.index)}")
print("训练和验证数据文件已保存。")
训练数据分割: 850573
验证数据分割: 149636
训练和验证数据文件已保存。
定义数据集元数据和超参数
csv_header = list(ratings_data.columns)
user_vocabulary = list(ratings_data.user_id.unique())
movie_vocabulary = list(ratings_data.movie_id.unique())
target_feature_name = "rating"
learning_rate = 0.001
batch_size = 128
num_epochs = 3
base_embedding_dim = 64
训练和评估模型
def get_dataset_from_csv(csv_file_path, batch_size=128, shuffle=True):
return tf.data.experimental.make_csv_dataset(
csv_file_path,
batch_size=batch_size,
column_names=csv_header,
label_name=target_feature_name,
num_epochs=1,
header=False,
field_delim="|",
shuffle=shuffle,
)
def run_experiment(model):
# 编译模型。
model.compile(
optimizer=keras.optimizers.Adam(learning_rate),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.MeanAbsoluteError(name="mae")],
)
# 读取训练数据。
train_dataset = get_dataset_from_csv("train_data.csv", batch_size)
# 读取测试数据。
eval_dataset = get_dataset_from_csv("eval_data.csv", batch_size, shuffle=False)
# 用训练数据拟合模型。
history = model.fit(
train_dataset,
epochs=num_epochs,
validation_data=eval_dataset,
)
return history
实验 1:基线协同过滤模型
实现嵌入编码器
def embedding_encoder(vocabulary, embedding_dim, num_oov_indices=0, name=None):
return keras.Sequential(
[
StringLookup(
vocabulary=vocabulary, mask_token=None, num_oov_indices=num_oov_indices
),
layers.Embedding(
input_dim=len(vocabulary) + num_oov_indices, output_dim=embedding_dim
),
],
name=f"{name}_embedding" if name else None,
)
实现基线模型
def create_baseline_model():
# 接收用户作为输入。
user_input = layers.Input(name="user_id", shape=(), dtype=tf.string)
# 获取用户嵌入。
user_embedding = embedding_encoder(
vocabulary=user_vocabulary, embedding_dim=base_embedding_dim, name="user"
)(user_input)
# 接收电影作为输入。
movie_input = layers.Input(name="movie_id", shape=(), dtype=tf.string)
# 获取嵌入。
movie_embedding = embedding_encoder(
vocabulary=movie_vocabulary, embedding_dim=base_embedding_dim, name="movie"
)(movie_input)
# 计算用户与电影嵌入之间的点积相似性。
logits = layers.Dot(axes=1, name="dot_similarity")(
[user_embedding, movie_embedding]
)
# 转换为评分尺度。
prediction = keras.activations.sigmoid(logits) * 5
# 创建模型。
model = keras.Model(
inputs=[user_input, movie_input], outputs=prediction, name="baseline_model"
)
return model
baseline_model = create_baseline_model()
baseline_model.summary()
/Users/fchollet/Library/Python/3.10/lib/python/site-packages/numpy/core/numeric.py:2468: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
return bool(asarray(a1 == a2).all())
模型: "baseline_model"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ user_id │ (None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ movie_id │ (None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ user_embedding │ (None, 64) │ 386,560 │ user_id[0][0] │ │ (顺序) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ movie_embedding │ (None, 64) │ 237,184 │ movie_id[0][0] │ │ (顺序) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ dot_similarity │ (无, 1) │ 0 │ user_embedding[0][0… │ │ (点积) │ │ │ movie_embedding[0][… │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ sigmoid (Sigmoid) │ (无, 1) │ 0 │ dot_similarity[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ multiply (乘法) │ (无, 1) │ 0 │ sigmoid[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
总参数: 623,744 (2.38 MB)
可训练参数: 623,744 (2.38 MB)
非可训练参数: 0 (0.00 B)
注意可训练参数的数量是 623,744
history = run_experiment(baseline_model)
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("模型损失")
plt.ylabel("损失")
plt.xlabel("时期")
plt.legend(["训练", "评估"], loc="upper left")
plt.show()
Epoch 1/3
6629/Unknown 17s 3ms/step - loss: 1.4095 - mae: 0.9668
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/contextlib.py:153: UserWarning: Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches. You may need to use the `.repeat()` function when building your dataset.
self.gen.throw(typ, value, traceback)
6646/6646 ━━━━━━━━━━━━━━━━━━━━ 18s 3ms/step - loss: 1.4087 - mae: 0.9665 - val_loss: 0.9032 - val_mae: 0.7438
Epoch 2/3
6646/6646 ━━━━━━━━━━━━━━━━━━━━ 17s 3ms/step - loss: 0.8296 - mae: 0.7193 - val_loss: 0.7807 - val_mae: 0.6976
Epoch 3/3
6646/6646 ━━━━━━━━━━━━━━━━━━━━ 17s 3ms/step - loss: 0.7305 - mae: 0.6744 - val_loss: 0.7446 - val_mae: 0.6808

实验 2: 内存高效模型
实现商余嵌入作为一层
商余技术的工作方式如下。对于一组词汇和嵌入大小
embedding_dim,我们不创建一个 vocabulary_size X embedding_dim 的嵌入表格,
而是创建 两个 num_buckets X embedding_dim 的嵌入表格,其中 num_buckets
远小于 vocabulary_size。
针对给定项 index 的嵌入通过以下步骤生成:
- 计算
quotient_index为index // num_buckets。 - 计算
remainder_index为index % num_buckets。 - 使用
quotient_index从第一个嵌入表查找quotient_embedding。 - 使用
remainder_index从第二个嵌入表查找remainder_embedding。 - 返回
quotient_embedding*remainder_embedding。
该技术不仅减少了需要存储和训练的嵌入向量的数量,
但也为每个项目生成一个大小为 embedding_dim 的唯一嵌入向量。
注意 q_embedding 和 r_embedding 可以通过其他操作组合,比如 Add 和 Concatenate。
class QREmbedding(keras.layers.Layer):
def __init__(self, vocabulary, embedding_dim, num_buckets, name=None):
super().__init__(name=name)
self.num_buckets = num_buckets
self.index_lookup = StringLookup(
vocabulary=vocabulary, mask_token=None, num_oov_indices=0
)
self.q_embeddings = layers.Embedding(
num_buckets,
embedding_dim,
)
self.r_embeddings = layers.Embedding(
num_buckets,
embedding_dim,
)
def call(self, inputs):
# 获取项目索引。
embedding_index = self.index_lookup(inputs)
# 获取商索引。
quotient_index = tf.math.floordiv(embedding_index, self.num_buckets)
# 获取余数索引。
remainder_index = tf.math.floormod(embedding_index, self.num_buckets)
# 使用商索引查找 quotient_embedding。
quotient_embedding = self.q_embeddings(quotient_index)
# 使用余数索引查找 remainder_embedding。
remainder_embedding = self.r_embeddings(remainder_index)
# 使用乘法作为组合操作
return quotient_embedding * remainder_embedding
实现混合维度嵌入作为一层
在混合维度嵌入技术中,我们对频繁查询的项目训练全维度的嵌入向量,而对不太频繁的项目训练降低维度的嵌入向量,并加一个投影权重矩阵将低维嵌入转换为全维度。
更精确地说,我们定义了频率相似的项目的块。对于每个块,创建一个 block_vocab_size X block_embedding_dim 的嵌入表和一个 block_embedding_dim X full_embedding_dim 的投影权重矩阵。注意,如果 block_embedding_dim 等于 full_embedding_dim,则投影权重矩阵变为单位矩阵。通过以下步骤为给定批次的项目 indices 生成嵌入:
- 对于每个块,使用
indices查找block_embedding_dim的嵌入向量,并将它们投影到full_embedding_dim。 - 如果项目索引不属于给定块,则返回一个缺失嵌入。每个块将返回一个
batch_size X full_embedding_dim的张量。 - 对每个块返回的嵌入应用掩码,以将缺失嵌入转换为零向量。也就是说,对于批次中的每个项目,从所有块嵌入返回单个非零嵌入向量。
- 从块中检索到的嵌入使用求和组合,生成最终的
batch_size X full_embedding_dim张量。
class MDEmbedding(keras.layers.Layer):
def __init__(
self, blocks_vocabulary, blocks_embedding_dims, base_embedding_dim, name=None
):
super().__init__(name=name)
self.num_blocks = len(blocks_vocabulary)
# 创建词汇到块的查找。
keys = []
values = []
for block_idx, block_vocab in enumerate(blocks_vocabulary):
keys.extend(block_vocab)
values.extend([block_idx] * len(block_vocab))
self.vocab_to_block = tf.lookup.StaticHashTable(
tf.lookup.KeyValueTensorInitializer(keys, values), default_value=-1
)
self.block_embedding_encoders = []
self.block_embedding_projectors = []
# 创建块嵌入编码器和投影器。
for idx in range(self.num_blocks):
vocabulary = blocks_vocabulary[idx]
embedding_dim = blocks_embedding_dims[idx]
block_embedding_encoder = embedding_encoder(
vocabulary, embedding_dim, num_oov_indices=1
)
self.block_embedding_encoders.append(block_embedding_encoder)
if embedding_dim == base_embedding_dim:
self.block_embedding_projectors.append(layers.Lambda(lambda x: x))
else:
self.block_embedding_projectors.append(
layers.Dense(units=base_embedding_dim)
)
def call(self, inputs):
# 获取每个输入项的块索引。
block_indicies = self.vocab_to_block.lookup(inputs)
# 将输出嵌入初始化为零。
embeddings = tf.zeros(shape=(tf.shape(inputs)[0], base_embedding_dim))
# 从块生成嵌入。
for idx in range(self.num_blocks):
# 查找当前块的嵌入。
block_embeddings = self.block_embedding_encoders[idx](inputs)
# 将嵌入投影到 base_embedding_dim。
block_embeddings = self.block_embedding_projectors[idx](block_embeddings)
# 创建一个掩码以过滤掉不属于当前块的项的嵌入。
mask = tf.expand_dims(tf.cast(block_indicies == idx, tf.dtypes.float32), 1)
# 将不属于当前块的项的嵌入设置为零。
block_embeddings = block_embeddings * mask
# 将块嵌入添加到最终嵌入中。
embeddings += block_embeddings
return embeddings
实现内存高效的模型
在本实验中,我们将使用商-余数技术来减少用户嵌入的大小,并使用混合维度技术来减少电影嵌入的大小。
虽然在论文中,使用了阿尔法幂法则来确定每个块的嵌入维度,但我们只是根据电影受欢迎程度的直方图可视化来设置块的数量和每个块的嵌入维度。
movie_frequencies = ratings_data["movie_id"].value_counts()
movie_frequencies.hist(bins=10)
<Axes: >
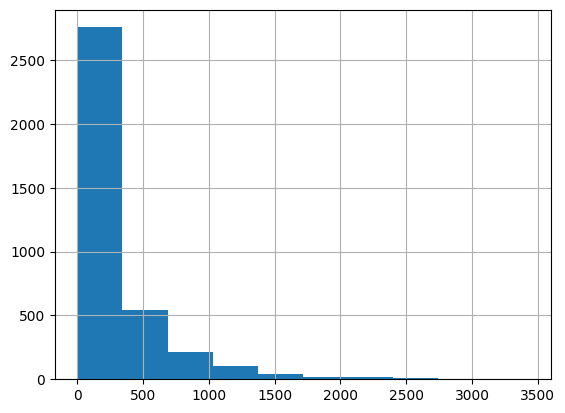
您可以看到我们可以将电影分成三个块,并分别为它们分配64、32和16个嵌入维度。欢迎尝试不同的块数量和维度。
sorted_movie_vocabulary = list(movie_frequencies.keys())
movie_blocks_vocabulary = [
sorted_movie_vocabulary[:400], # 高人气电影块
sorted_movie_vocabulary[400:1700], # 普通人气电影块
sorted_movie_vocabulary[1700:], # 低人气电影块
]
movie_blocks_embedding_dims = [64, 32, 16]
user_embedding_num_buckets = len(user_vocabulary) // 50
def create_memory_efficient_model():
# 将用户作为输入。
user_input = layers.Input(name="user_id", shape=(), dtype="string")
# 获取用户嵌入。
user_embedding = QREmbedding(
vocabulary=user_vocabulary,
embedding_dim=base_embedding_dim,
num_buckets=user_embedding_num_buckets,
name="user_embedding",
)(user_input)
# 将电影作为输入。
movie_input = layers.Input(name="movie_id", shape=(), dtype="string")
# 获取嵌入。
movie_embedding = MDEmbedding(
blocks_vocabulary=movie_blocks_vocabulary,
blocks_embedding_dims=movie_blocks_embedding_dims,
base_embedding_dim=base_embedding_dim,
name="movie_embedding",
)(movie_input)
# 计算用户和电影嵌入之间的点积相似度。
logits = layers.Dot(axes=1, name="dot_similarity")(
[user_embedding, movie_embedding]
)
# 转换为评分尺度。
prediction = keras.activations.sigmoid(logits) * 5
# 创建模型。
model = keras.Model(
inputs=[user_input, movie_input], outputs=prediction, name="baseline_model"
)
return model
memory_efficient_model = create_memory_efficient_model()
memory_efficient_model.summary()
/Users/fchollet/Library/Python/3.10/lib/python/site-packages/numpy/core/numeric.py:2468: FutureWarning: 元素逐个比较失败;返回标量,但将来会执行逐个比较
return bool(asarray(a1 == a2).all())
模型: "baseline_model"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数数量 ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ user_id │ (None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ movie_id │ (None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ user_embedding │ (无, 64) │ 15,360 │ user_id[0][0] │ │ (QREmbedding) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ movie_embedding │ (无, 64) │ 102,608 │ movie_id[0][0] │ │ (MDEmbedding) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ dot_similarity │ (无, 1) │ 0 │ user_embedding[0][0… │ │ (Dot) │ │ │ movie_embedding[0][… │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ sigmoid_1 (Sigmoid) │ (无, 1) │ 0 │ dot_similarity[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ multiply_1 │ (无, 1) │ 0 │ sigmoid_1[0][0] │ │ (乘法) │ │ │ │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
总参数: 117,968 (460.81 KB)
可训练参数: 117,968 (460.81 KB)
不可训练参数: 0 (0.00 B)
注意,可训练参数的数量是117,968,远少于基线模型中的参数数量的5倍。
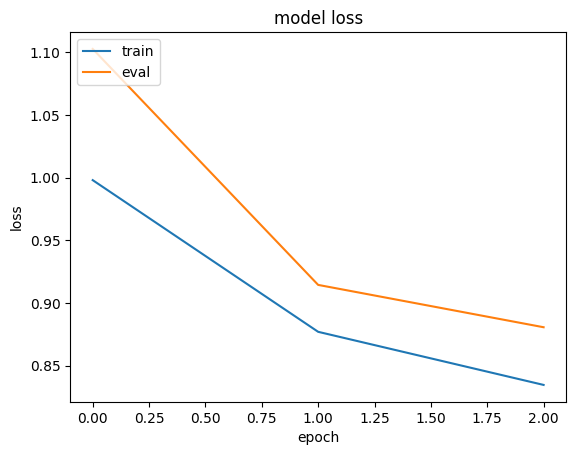
history = run_experiment(memory_efficient_model)
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("模型损失")
plt.ylabel("损失")
plt.xlabel("纪元")
plt.legend(["训练", "评估"], loc="upper left")
plt.show()
Epoch 1/3
6622/未知 6s 891微秒/步骤 - 损失: 1.1938 - 平均绝对误差: 0.8780
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/contextlib.py:153: 用户警告: 您的输入数据已耗尽;中断训练。确保您的数据集或生成器可以生成至少 `steps_per_epoch * epochs` 批次。您可能需要在构建数据集时使用 `.repeat()` 函数。
self.gen.throw(typ, value, traceback)
6646/6646 ━━━━━━━━━━━━━━━━━━━━ 7s 992微秒/步骤 - 损失: 1.1931 - 平均绝对误差: 0.8777 - 验证损失: 1.1027 - 验证平均绝对误差: 0.8179
Epoch 2/3
6646/6646 ━━━━━━━━━━━━━━━━━━━━ 7s 1毫秒/步骤 - 损失: 0.8908 - 平均绝对误差: 0.7488 - 验证损失: 0.9144 - 验证平均绝对误差: 0.7549
Epoch 3/3
6646/6646 ━━━━━━━━━━━━━━━━━━━━ 7s 980微秒/步骤 - 损失: 0.8419 - 平均绝对误差: 0.7278 - 验证损失: 0.8806 - 验证平均绝对误差: 0.7419