大规模多标签文本分类
作者: Sayak Paul, Soumik Rakshit
创建日期: 2020/09/25
最后修改: 2020/12/23
描述: 实现大规模多标签文本分类模型。

介绍
在这个例子中,我们将构建一个多标签文本分类器,以预测arXiv论文的主题领域,这些主题领域来自它们的摘要。此类分类器对于像OpenReview这样的会议提交门户非常有用。给定一篇论文摘要,门户可以提供论文最佳归属领域的建议。
该数据集是通过使用arXiv Python库收集的,该库为原始arXiv API提供了一个封装。要了解有关数据收集过程的更多信息,请参考this notebook。此外,您还可以在Kaggle上找到该数据集。
导入
from tensorflow.keras import layers
from tensorflow import keras
import tensorflow as tf
from sklearn.model_selection import train_test_split
from ast import literal_eval
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
进行探索性数据分析
在这一部分,我们首先将数据集加载到pandas数据框中,然后进行一些基本的探索性数据分析(EDA)。
arxiv_data = pd.read_csv(
"https://github.com/soumik12345/multi-label-text-classification/releases/download/v0.2/arxiv_data.csv"
)
arxiv_data.head()
| 标题 | 摘要 | 术语 | |
|---|---|---|---|
| 0 | 关于语义立体匹配的调查/语义... | 立体匹配是广泛使用的技术之一... | ['cs.CV', 'cs.LG'] |
| 1 | 未来人工智能:指导原则和共识重... | 近年来人工智能的进步... | ['cs.CV', 'cs.AI', 'cs.LG'] |
| 2 | 强制硬区域的互一致性... | 在本文中,我们提出了一种新颖的互一致性... | ['cs.CV', 'cs.AI'] |
| 3 | 半监督的参数解耦策略... | 一致性训练已被证明是一种先进的方法... | ['cs.CV'] |
| 4 | 室内背景-前景分割... | 为确保自动驾驶的安全,相关... | ['cs.CV', 'cs.LG'] |
我们的文本特征位于summaries列,而它们相应的标签位于terms中。正如您所注意到的,特定条目与多个类别相关联。
print(f"数据集中有 {len(arxiv_data)} 行。")
数据集中有 51774 行。
现实世界的数据是噪声的。最常观察到的噪声来源之一是数据重复。这里我们注意到,初始数据集中大约有13k个重复条目。
total_duplicate_titles = sum(arxiv_data["titles"].duplicated())
print(f"有 {total_duplicate_titles} 个重复标题。")
有 12802 个重复标题。
在进一步处理之前,我们删除这些条目。
arxiv_data = arxiv_data[~arxiv_data["titles"].duplicated()]
print(f"去重后的数据集中有 {len(arxiv_data)} 行。")
# 有一些术语的出现次数低至1。
print(sum(arxiv_data["terms"].value_counts() == 1))
# 有多少个唯一术语?
print(arxiv_data["terms"].nunique())
去重后的数据集中有 38972 行。
2321
3157
观察到,在3,157个唯一的terms组合中,有2,321条记录的出现次数最低。为了准备我们的训练、验证和测试集,并进行stratification,我们需要删除这些术语。
# 过滤稀有术语。
arxiv_data_filtered = arxiv_data.groupby("terms").filter(lambda x: len(x) > 1)
arxiv_data_filtered.shape
(36651, 3)
将字符串标签转换为字符串列表
初始标签以原始字符串形式表示。在这里,我们将它们转换为List[str]以获得更紧凑的表示。
arxiv_data_filtered["terms"] = arxiv_data_filtered["terms"].apply(
lambda x: literal_eval(x)
)
arxiv_data_filtered["terms"].values[:5]
array([list(['cs.CV', 'cs.LG']), list(['cs.CV', 'cs.AI', 'cs.LG']),
list(['cs.CV', 'cs.AI']), list(['cs.CV']),
list(['cs.CV', 'cs.LG'])], dtype=object)
使用分层拆分以应对类别不平衡
该数据集存在class imbalance problem问题。因此,为了获得公正的评估结果,我们需要确保数据集的抽样具有分层性。要了解更多关于处理类别不平衡问题的不同策略,您可以参考this tutorial。有关使用不平衡数据进行分类的端到端演示,请参见Imbalanced classification: credit card fraud detection。
test_split = 0.1
# 初始训练和测试拆分。
train_df, test_df = train_test_split(
arxiv_data_filtered,
test_size=test_split,
stratify=arxiv_data_filtered["terms"].values,
)
# 将测试集进一步拆分为验证集
# 和新测试集。
val_df = test_df.sample(frac=0.5)
test_df.drop(val_df.index, inplace=True)
print(f"训练集中的行数: {len(train_df)}")
print(f"验证集中的行数: {len(val_df)}")
print(f"测试集中的行数: {len(test_df)}")
训练集中的行数: 32985
验证集中的行数: 1833
测试集中的行数: 1833
多标签二值化
现在我们使用StringLookup层对标签进行预处理。
terms = tf.ragged.constant(train_df["terms"].values)
lookup = tf.keras.layers.StringLookup(output_mode="multi_hot")
lookup.adapt(terms)
vocab = lookup.get_vocabulary()
def invert_multi_hot(encoded_labels):
"""将单个多热编码标签反转为词汇表术语的元组。"""
hot_indices = np.argwhere(encoded_labels == 1.0)[..., 0]
return np.take(vocab, hot_indices)
print("词汇表:\n")
print(vocab)
词汇表:
['[UNK]', '计算机视觉', '机器学习', '统计学习', '人工智能', '电子信息与电力系统', '机器人', '计算语言学', '网络与图形', '计算机视觉与图形', '最优控制', '信号处理', '图形处理', '信号与信息', '多媒体', '系统', '信息检索', '计算机应用', '系统与设备', '人机交互', '信息论', '信息技术', '数据挖掘', '计算机图形学', '应用概率', '抽样分布', '统计推断', '元分析', '自动化系统', '系统设计', '生物信息学', '生物物理', '数据科学', '图表', '计算几何', '软件工程', '网络与信息', '分类与数据压缩', '组合数学', '化学物理', '数据库', '生物统计', '编程语言', '逻辑', '凝聚态物理', '68T45', '概率论', '计算物理', '图形与图像', '计算机应用', '系统工程', '金融经济学', '统计力学', '68T05', '量子物理', '动力系统', '数据分析', '计算机网络', '兴趣', '社会物理', '光学', '数据挖掘', '经济学', '生物信息学', '生物医学', '天体物理', '68T10', '信号与系统', '地球物理', '流体动力学', '组合优化', '应用数学', '信息技术', '68T01', '数值计算', '金融', '非线性动力学', '计算机科学', '68T07', '金融数学', '计算机教育', '密码学', '数据结构', '信息检索', '投资组合', '金融学', '生物数学', '机器人技术', '非线性系统', '信号处理与图像', '69T99', '数学', '68Q32', '62H30', '风险管理', '投资管理', '生物技术', '非线性控制', '数学逻辑', '数学分析', '高能物理', '凝聚态物理', '68T30', 'I.4.6; I.4.8', 'I.4.4', 'I.4.3', 'I.4.0', 'I.2; J.2', 'I.2; I.2.6; I.2.7', 'I.2.7', 'I.2.6; I.5.4', 'I.2.6; I.2.9', 'I.2.6; I.2.7; H.3.1; H.3.3', 'I.2.6; I.2.10', 'I.2.6, I.5.4', 'I.2.1; J.3', 'I.2.10; I.5.1; I.4.8', 'I.2.10; I.4.8; I.5.4', 'I.2.10; I.2.6', 'I.2.1', 'H.3.1; I.2.6; I.2.7', 'H.3.1; H.3.3; I.2.6; I.2.7', 'G.3', 'F.2.2; I.2.7', 'E.5; E.4; E.2; H.1.1; F.1.1; F.1.3', '68Txx', '62H99', '62H35', '14J60(主要) 14F05, 14J26(次要)']
在这里,我们将从标签池中分离出单个唯一类,然后使用这些信息用0和1表示给定的标签集。以下是一个示例。
sample_label = train_df["terms"].iloc[0]
print(f"原始标签: {sample_label}")
label_binarized = lookup([sample_label])
print(f"标签二进制表示: {label_binarized}")
原始标签: ['cs.LG', 'cs.CV', 'eess.IV']
标签二进制表示: [[0. 1. 1. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0.]]
数据预处理和 tf.data.Dataset 对象
我们首先获取序列长度的百分位估计。目的将在稍后变得清晰。
train_df["summaries"].apply(lambda x: len(x.split(" "))).describe()
count 32985.000000
mean 156.497105
std 41.528225
min 5.000000
25% 128.000000
50% 154.000000
75% 183.000000
max 462.000000
Name: summaries, dtype: float64
请注意,50%的摘要长度为154(您可能会根据分割得到不同的数字)。因此,任何接近该值的数字都是最大序列长度的一个足够好的近似值。
现在,我们实现实用工具来准备我们的数据集。
max_seqlen = 150
batch_size = 128
padding_token = "<pad>"
auto = tf.data.AUTOTUNE
def make_dataset(dataframe, is_train=True):
labels = tf.ragged.constant(dataframe["terms"].values)
label_binarized = lookup(labels).numpy()
dataset = tf.data.Dataset.from_tensor_slices(
(dataframe["summaries"].values, label_binarized)
)
dataset = dataset.shuffle(batch_size * 10) if is_train else dataset
return dataset.batch(batch_size)
现在我们可以准备 tf.data.Dataset 对象。
train_dataset = make_dataset(train_df, is_train=True)
validation_dataset = make_dataset(val_df, is_train=False)
test_dataset = make_dataset(test_df, is_train=False)
数据集预览
text_batch, label_batch = next(iter(train_dataset))
for i, text in enumerate(text_batch[:5]):
label = label_batch[i].numpy()[None, ...]
print(f"摘要: {text}")
print(f"标签: {invert_multi_hot(label[0])}")
print(" ")
摘要:b"在本文中,我们展示了如何使用卫星图像来提高住房价格估计模型的准确性。通过转移来自在ImageNet上预训练的Inception-v3模型的学习,使用洛杉矶县的物业评估数据集,我们能够比仅使用房屋非图像特征的两个基线模型提高~10%的R平方值。"
标签:['cs.LG' 'stat.ML']
摘要:b'从数据流中学习在数据挖掘、机器学习和人工智能领域越来越重要。数据流文献的一个主要关注点是设计可以处理概念漂移的方法,这是一个生成分布随时间变化的挑战。大多数文献中的一个普遍假设是,实例在流中是独立分布的。在这项工作中,我们展示了在概念漂移的情况下,这一假设是矛盾的,概念漂移的存在必然意味着时间依赖性;因此某种形式的时间序列。这对模型设计和部署有重要的影响。我们探讨并强调这些影响,并展示基于Hoeffding树的集合方法,在流中学习非常流行,但并不自然适合在漂移\\emph{内}进行学习;并且在这种情况下只能以破坏性适应的显著计算成本执行。另一方面,我们开发和参数化了梯度下降方法,并演示了它们如何实现\\emph{连续}适应,且没有明确的漂移检测机制,在准确性和效率方面提供了重大优势。根据我们的理论讨论和实证观察,我们概述了一系列在概念漂移流中部署方法的建议。'
标签:['cs.LG' 'stat.ML']
摘要:b"随着强化学习(RL)在解决复杂任务中取得更多成功,需要更加小心确保RL研究是可重现的,以及此处的算法可以轻松、公平地进行最小偏差比较。然而,由于算法固有的方差、环境的随机性以及众多(可能未报告的)超参数,RL结果的可重现性恰恰非常困难。在这项工作中,我们调查了导致研究不可重复的诸多问题以及如何管理这些问题。我们进一步展示了如何利用严格和标准化的评估方法,以简化不同算法的文档、评估和公平比较过程,我们强调选择正确的测量指标以及对结果进行适当统计的重要性,以免偏见地报告结果。"
标签:['cs.LG' 'stat.ML' 'cs.AI' 'cs.RO']
摘要:b'估计图像之间的密集对应关系是一项长期存在的图像理解任务。最近的工作引入卷积神经网络(CNN)来提取高层特征图,并通过特征匹配找到对应关系。然而,高层特征图的空间分辨率低,因此无法提供足够准确和细致的特征来区分对应匹配的类内变化。为了解决这个问题,我们通过在不同尺度上动态选择特征来生成鲁棒特征。为了解决特征选择中的两个关键问题,即选择多少和选择哪些尺度的特征,我们将特征选择过程框架化为一个序列马尔可夫决策过程(MDP),并引入一种使用强化学习(RL)的最佳选择策略。我们定义了一个图像匹配的RL环境,其中每个动作要么需要新特征,要么通过参考匹配得分来终止选择过程。深度神经网络被纳入我们的方法中并用于决策制作。实验结果表明,我们的方法在三个基准数据集上实现了与最先进的方法相当/优越的性能,展示了我们的特征选择策略的有效性。'
标签:['cs.CV']
摘要:b'密集重建通常包含错误,之前的工作迄今为止通过使用高质量传感器和对输出进行正则化来最小化这些错误。然而,错误仍然存在。本文提出了一种机器学习技术来识别三维(3D)网格中的错误。除了简单地识别错误,我们的方法还量化了在查看场景时深度估计错误的大小和方向。这使我们能够提高重建的准确性。我们训练了一个合适的深度网络架构,使用两种3D网格:高质量激光重建和较低质量立体图像重建。该网络预测相较于高质量重建的较低质量重建中的错误量,仅通过其输入查看前者。我们通过校正从3D模型提取的二维(2D)逆深度图像来评估我们的方法,并展示我们的工作使这些深度重建的质量提高了多达相对10% RMSE。'
标签:['cs.CV' 'cs.RO']
向量化
在将数据输入模型之前,我们需要对其进行向量化(以数值形式表示)。
为此,我们将使用
TextVectorization 层。
它可以作为您主模型的一部分运行,从而使模型不参与核心
预处理逻辑。这大大减少了推理过程中的训练/服务偏差的可能性。
我们首先计算摘要中存在的唯一单词的数量。
# 来源: https://stackoverflow.com/a/18937309/7636462
vocabulary = set()
train_df["summaries"].str.lower().str.split().apply(vocabulary.update)
vocabulary_size = len(vocabulary)
print(vocabulary_size)
153338
我们现在创建我们的向量化层,并将其 map() 到之前创建的 tf.data.Dataset 中。
text_vectorizer = layers.TextVectorization(
max_tokens=vocabulary_size, ngrams=2, output_mode="tf_idf"
)
# `TextVectorization` 层需要根据我们的训练集中的词汇进行调整。
with tf.device("/CPU:0"):
text_vectorizer.adapt(train_dataset.map(lambda text, label: text))
train_dataset = train_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
validation_dataset = validation_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
test_dataset = test_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
一批原始文本将首先通过 TextVectorization 层,生成它们的整数表示。内部,TextVectorization 层将首先从序列创建二元组,然后使用
TF-IDF 表示它们。输出表示将被传递到负责文本分类的浅层模型。
要了解有关 TextVectorizer 的其他可能配置,请参阅
官方文档。
注意:将 max_tokens 参数设置为预先计算的词汇大小不是必需的。
创建文本分类模型
我们将保持模型简单——它将是一个小的全连接层堆栈,非线性激活函数为 ReLU。
def make_model():
shallow_mlp_model = keras.Sequential(
[
layers.Dense(512, activation="relu"),
layers.Dense(256, activation="relu"),
layers.Dense(lookup.vocabulary_size(), activation="sigmoid"),
] # 稍后我们会详细解释为什么使用“sigmoid”。
)
return shallow_mlp_model
训练模型
我们将使用二元交叉熵损失来训练模型。这是因为标签不是不相交的。对于给定的摘要,我们可能有多个类别。因此,我们将 预测任务分为一系列多个二元分类问题。这也是我们将模型中分类层的激活函数保持为 sigmoid 的原因。研究人员还使用其他损失函数和激活函数的组合。例如,在 Exploring the Limits of Weakly Supervised Pretraining 中, Mahajan 等使用了 softmax 激活函数和交叉熵损失来训练他们的模型。
在多标签分类中可以使用几种评估指标。 为了使此代码示例更简洁,我们决定使用 二元准确率指标。 要了解为什么使用此指标,我们可以参考这个 pull-request。 还有其他适合多标签分类的指标,例如 F1 分数 或 汉明损失。
epochs = 20
shallow_mlp_model = make_model()
shallow_mlp_model.compile(
loss="binary_crossentropy", optimizer="adam", metrics=["binary_accuracy"]
)
history = shallow_mlp_model.fit(
train_dataset, validation_data=validation_dataset, epochs=epochs
)
def plot_result(item):
plt.plot(history.history[item], label=item)
plt.plot(history.history["val_" + item], label="val_" + item)
plt.xlabel("Epochs")
plt.ylabel(item)
plt.title("Train and Validation {} Over Epochs".format(item), fontsize=14)
plt.legend()
plt.grid()
plt.show()
plot_result("loss")
plot_result("binary_accuracy")
第1纪元/20
258/258 [==============================] - 87s 332ms/步 - 损失: 0.0326 - 二进制准确率: 0.9893 - 验证损失: 0.0189 - 验证二进制准确率: 0.9943
第2纪元/20
258/258 [==============================] - 100s 387ms/步 - 损失: 0.0033 - 二进制准确率: 0.9990 - 验证损失: 0.0271 - 验证二进制准确率: 0.9940
第3纪元/20
258/258 [==============================] - 99s 384ms/步 - 损失: 7.8393e-04 - 二进制准确率: 0.9999 - 验证损失: 0.0328 - 验证二进制准确率: 0.9939
第4纪元/20
258/258 [==============================] - 109s 421ms/步 - 损失: 3.0132e-04 - 二进制准确率: 1.0000 - 验证损失: 0.0366 - 验证二进制准确率: 0.9939
第5纪元/20
258/258 [==============================] - 105s 405ms/步 - 损失: 1.6006e-04 - 二进制准确率: 1.0000 - 验证损失: 0.0399 - 验证二进制准确率: 0.9939
第6纪元/20
258/258 [==============================] - 107s 414ms/步 - 损失: 1.2400e-04 - 二进制准确率: 1.0000 - 验证损失: 0.0412 - 验证二进制准确率: 0.9939
第7纪元/20
258/258 [==============================] - 110s 425ms/步 - 损失: 7.7131e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0439 - 验证二进制准确率: 0.9940
第8纪元/20
258/258 [==============================] - 105s 405ms/步 - 损失: 5.5611e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0446 - 验证二进制准确率: 0.9940
第9纪元/20
258/258 [==============================] - 103s 397ms/步 - 损失: 4.5994e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0454 - 验证二进制准确率: 0.9940
第10纪元/20
258/258 [==============================] - 105s 405ms/步 - 损失: 3.5126e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0472 - 验证二进制准确率: 0.9939
第11纪元/20
258/258 [==============================] - 109s 422ms/步 - 损失: 2.9927e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0466 - 验证二进制准确率: 0.9940
第12纪元/20
258/258 [==============================] - 133s 516ms/步 - 损失: 2.5748e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0484 - 验证二进制准确率: 0.9940
第13纪元/20
258/258 [==============================] - 129s 497ms/步 - 损失: 4.3529e-05 - 二进制准确率: 1.0000 - 验证损失: 0.0500 - 验证二进制准确率: 0.9940
第14纪元/20
258/258 [==============================] - 158s 611ms/步 - 损失: 8.1068e-04 - 二进制准确率: 0.9998 - 验证损失: 0.0377 - 验证二进制准确率: 0.9936
第15纪元/20
258/258 [==============================] - 144s 558ms/步 - 损失: 0.0016 - 二进制准确率: 0.9995 - 验证损失: 0.0418 - 验证二进制准确率: 0.9935
第16纪元/20
258/258 [==============================] - 131s 506ms/步 - 损失: 0.0018 - 二进制准确率: 0.9995 - 验证损失: 0.0479 - 验证二进制准确率: 0.9931
第17纪元/20
258/258 [==============================] - 127s 491ms/步 - 损失: 0.0012 - 二进制准确率: 0.9997 - 验证损失: 0.0521 - 验证二进制准确率: 0.9931
第18纪元/20
258/258 [==============================] - 153s 594ms/步 - 损失: 6.3144e-04 - 二进制准确率: 0.9998 - 验证损失: 0.0549 - 验证二进制准确率: 0.9934
第19纪元/20
258/258 [==============================] - 142s 550ms/步 - 损失: 3.1753e-04 - 二进制准确率: 0.9999 - 验证损失: 0.0589 - 验证二进制准确率: 0.9934
第20纪元/20
258/258 [==============================] - 153s 594ms/步 - 损失: 2.0258e-04 - 二进制准确率: 1.0000 - 验证损失: 0.0585 - 验证二进制准确率: 0.9933
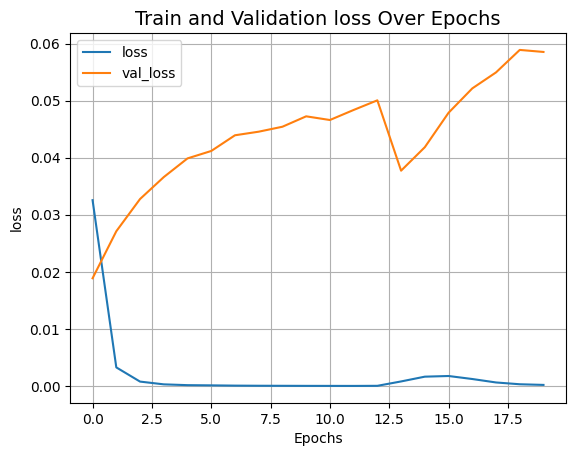
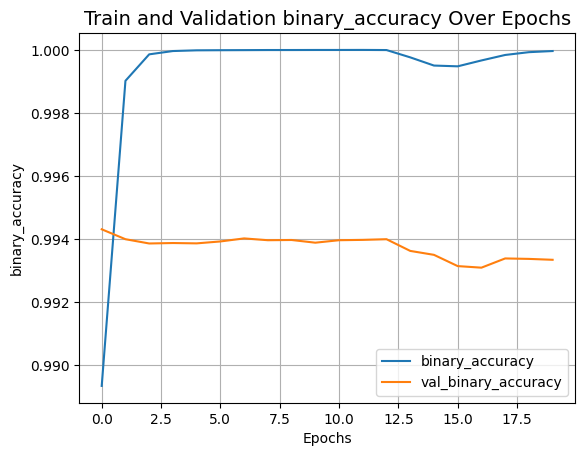
在训练过程中,我们注意到损失值初期急剧下降随后逐渐衰减。
评估模型
_, binary_acc = shallow_mlp_model.evaluate(test_dataset)
print(f"测试集的分类准确率: {round(binary_acc * 100, 2)}%.")
15/15 [==============================] - 3s 196ms/step - loss: 0.0580 - binary_accuracy: 0.9933
测试集的分类准确率: 99.33%。
训练后的模型给我们提供了约99%的评估准确率。
推理
Keras 提供的
预处理层的一个重要特性
是可以被包含在 tf.keras.Model 中。我们将通过将 text_vectorization 层
包含在 shallow_mlp_model 上来导出一个推理模型。这将允许我们的推理模型直接处理原始字符串。
注意 在训练期间,最好将这些预处理层作为数据输入管道的一部分,而不是模型,以避免为硬件加速器带来瓶颈。这也允许进行异步数据处理。
# 创建一个推理模型。
model_for_inference = keras.Sequential([text_vectorizer, shallow_mlp_model])
# 创建一个小的数据集用于演示推理。
inference_dataset = make_dataset(test_df.sample(100), is_train=False)
text_batch, label_batch = next(iter(inference_dataset))
predicted_probabilities = model_for_inference.predict(text_batch)
# 执行推理。
for i, text in enumerate(text_batch[:5]):
label = label_batch[i].numpy()[None, ...]
print(f"摘要: {text}")
print(f"标签: {invert_multi_hot(label[0])}")
predicted_proba = [proba for proba in predicted_probabilities[i]]
top_3_labels = [
x
for _, x in sorted(
zip(predicted_probabilities[i], lookup.get_vocabulary()),
key=lambda pair: pair[0],
reverse=True,
)
][:3]
print(f"预测标签: ({', '.join([label for label in top_3_labels])})")
print(" ")
4/4 [==============================] - 0s 62ms/step
摘要:b'我们研究了在大型Transformer模型中,使用哈希对不同输入使用不同参数的稀疏层的训练。特别地,我们修改了前馈层,以便根据当前令牌对所有序列中的令牌哈希到不同的权重集。我们表明,这一过程要么优于,要么与学习路由混合专家方法(如Switch Transformers和BASE Layers)具有竞争力,同时无需路由参数或额外的目标函数项,如负载平衡损失,也不需要复杂的分配算法。我们研究了不同哈希技术、哈希大小和输入特征的性能,并表明,注重最局部特征的平衡和随机哈希效果最好,相比于学习聚类或使用长距离上下文。我们表明我们的方法在大语言建模与对话任务以及下游微调任务中表现良好。'
标签:['cs.LG' 'cs.CL']
预测标签: (cs.LG, cs.CL, stat.ML)
摘要:b'我们提出了第一种能够使用从手机随意捕捉的照片/视频逼真重建可变形场景的方法。我们的方法通过优化一个额外的连续体积变形场,使每个观测点扭曲到一个规范化的5D NeRF,从而增强了神经辐射场(NeRF)。我们观察到这些类似NeRF的变形场容易陷入局部最小值,因此提出了一种粗到细的优化方法,适用于基于坐标的模型,使得优化更为稳健。通过将几何处理和物理仿真的原则适配到类似NeRF的模型中,我们提出了一种变形场的弹性正则化,进一步提高了稳健性。我们表明我们的方法能将随意捕获的自拍照片/视频转换为可变形的NeRF模型,从任意视点进行主题的逼真渲染,称之为“nerfies”。我们通过使用带有两个手机的设备收集时间同步数据,以相同姿势在不同视点下生成训练/验证图像。我们表明我们的方法能忠实重建非刚性变形场景,并以高保真度重现未见视角。'
标签:['cs.CV' 'cs.GR']
预测标签: (cs.CV, cs.GR, cs.RO)
摘要:b'我们提出联合学习多视角几何和同一物体实例视图之间的扭曲,以实现稳健的跨视图物体检测。多视角物体实例检测的难点在于视角变化、光照条件、相邻物体的高度相似性以及尺度的强变异性。通过将不同视图下的物体检测和实例重新识别转变为一个联合学习任务,我们能够将图像外观和几何软约束纳入一个可端对端学习的多视角检测过程。我们在一个新构建的大型城市物体街景全景数据集上验证了我们的方法,并显示出与各基线相比的卓越性能。我们的贡献有三:一个可公开获取的大规模多视角实例检测和重新识别数据集;一个专门为多视角实例检测定制的标注工具;以及一种新颖的整体多视角实例检测和重新识别方法,联合建模了视图间的几何和外观。'
标签:['cs.CV' 'cs.LG' 'stat.ML']
预测标签: (cs.CV, cs.RO, cs.MM)
摘要:b'学习图卷积网络(GCNs)是一个新兴领域,旨在将深度学习推广到任意非规则领域。大多数现有的GCNs遵循邻域聚合方案,其中节点的表示是通过使用平均或排序操作递归地聚合其邻近节点的表示获得的。然而,这些操作要么是不适定的,要么不足以具备判别能力,或会增加训练参数数量,从而增加计算复杂性和过拟合风险。在本文中,我们介绍了一种新颖的GCN框架,它在复制核希尔伯特空间(RKHS)中实现空间图卷积。这样可以通过隐式核表示设计高维和更具判别性的卷积图滤波器,而无需增加训练参数的数量。我们GCN模型的特殊性还在于其能够在不显式对齐学习到的图滤波器的感受野与输入图的节点的情况下实现卷积,从而使卷积对置换不敏感并且定义明确。在对骨架动作识别的挑战任务进行的实验中,我们显示了所提方法相对不同基线的优越性,以及相关工作。'
标签:['cs.CV']
预测标签: (cs.LG, cs.CV, cs.NE)
摘要:b'递归元强化学习(meta-RL)代理是使用递归神经网络(RNN)“学习学习算法”的代理。在预先指定的任务分布上训练后,代理RNN的学习权重被认为通过其活动动态实现了一种高效的学习算法,这使得代理能够快速解决从同一分布中采样的新任务。然而,由于这些代理的黑箱性质,它们的工作方式尚未完全理解。在这项研究中,我们通过使用部分可观测马尔可夫决策过程(POMDP)框架重新表述元强化学习问题,从而阐明这些代理的内部工作机制。我们假设所学习的活动动态充当这样的代理的信念状态。一些示范实验表明这一假设是正确的,并且递归元强化学习代理可以被视为在由多个相关任务组成的部分可观测环境中学习最优行动的代理。这种观点有助于理解它们的失败情况以及文献中报告的一些有趣的基于模型的结果。'
标签:['cs.LG' 'cs.AI']
预测标签: (stat.ML, cs.LG, cs.AI)
预测结果虽然不是很理想,但对于我们这样的简单模型来说也不算差。我们可以通过考虑单词顺序的模型(如LSTM)或甚至使用Transformers的模型(Vaswani et al.)来提升性能。
致谢
我们要感谢 Matt Watson 帮助我们解决多标签二值化部分,并将处理后的标签逆转化为原始形式。
感谢 Cingis Kratochvil 提出的建议,并通过二元准确度扩展了这个代码示例。