多模态蕴涵
作者: Sayak Paul
创建日期: 2021/08/08
最后修改日期: 2021/08/15
描述: 训练一个多模态模型以预测蕴涵关系。

引言
在这个例子中,我们将构建和训练一个模型来预测多模态蕴涵。我们将使用Google Research最近推出的 多模态蕴涵数据集。
什么是多模态蕴涵?
在社交媒体平台上,为了审核和管理内容,我们可能希望实时找到以下问题的答案:
- 给定的信息是否与其他信息相矛盾?
- 给定的信息是否暗示其他信息?
在自然语言处理(NLP)中,这个任务被称为分析_文本蕴涵_。然而,这仅适用于信息来自文本内容的情况。 实际上,信息往往不仅来自文本内容,而是来自文本、图像、音频、视频等多种模态的组合。 _多模态蕴涵_就是将文本蕴涵扩展到多种新的输入模态。
需求
这个示例需要TensorFlow 2.5或更高版本。此外,BERT模型还需要TensorFlow Hub和 TensorFlow Text(Devlin et al.)。可以使用以下命令安装这些库:
!pip install -q tensorflow_text
导入库
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import os
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from tensorflow import keras
定义标签映射
label_map = {"Contradictory": 0, "Implies": 1, "NoEntailment": 2}
收集数据集
原始数据集可在 这里找到。 它包含托管在Twitter照片存储系统上的图像的URL,该系统称为 Photo Blob Storage(简称PBS)。 我们将使用下载的图像以及原始数据集中的附加数据。感谢 Nilabhra Roy Chowdhury为准备图像数据所做的工作。
image_base_path = keras.utils.get_file(
"tweet_images",
"https://github.com/sayakpaul/Multimodal-Entailment-Baseline/releases/download/v1.0.0/tweet_images.tar.gz",
untar=True,
)
读取数据集并应用基本预处理
df = pd.read_csv(
"https://github.com/sayakpaul/Multimodal-Entailment-Baseline/raw/main/csvs/tweets.csv"
)
df.sample(10)
| id_1 | text_1 | image_1 | id_2 | text_2 | image_2 | label | |
|---|---|---|---|---|---|---|---|
| 291 | 1330800194863190016 | #KLM1167 (B738): #AMS (Amsterdam) to #HEL (Van... | http://pbs.twimg.com/media/EnfzuZAW4AE236p.png | 1378695438480588802 | #CKK205 (B77L): #PVG (Shanghai) to #AMS (Amste... | http://pbs.twimg.com/media/EyIcMexXEAE6gia.png | NoEntailment |
| 37 | 1366581728312057856 | Friends, interested all go to have a look!\n@j... | http://pbs.twimg.com/media/EvcS1v4UcAEEXPO.jpg | 1373810535066570759 | Friends, interested all go to have a look!\n@f... | http://pbs.twimg.com/media/ExDBZqwVIAQ4LWk.jpg | Contradictory |
| 315 | 1352551603258052608 | #WINk Drops I have earned today🚀\n\nToday:1/22... | http://pbs.twimg.com/media/EsTdcLLVcAIiFKT.jpg | 1354636016234098688 | #WINk Drops I have earned today☀\n\nToday:1/28... | http://pbs.twimg.com/media/EsyhK-qU0AgfMAH.jpg | NoEntailment |
| 761 | 1379795999493853189 | #buythedip Ready to FLY even HIGHER #pennysto... | http://pbs.twimg.com/media/EyYFJCzWgAMfTrT.jpg | 1380190250144792576 | #buythedip Ready to FLY even HIGHER #pennysto... | http://pbs.twimg.com/media/Eydrt0ZXAAMmbfv.jpg | NoEntailment |
| 146 | 1340185132293099523 | I know sometimes I am weird to you.\n\nBecause... | http://pbs.twimg.com/media/EplLRriWwAAJ2AE.jpg | 1359755419883814913 | I put my sword down and get on my knees to swe... | http://pbs.twimg.com/media/Et7SWWeWYAICK-c.jpg | NoEntailment |
| 1351 | 1381256604926967813 | Finally completed the skin rendering. Will sta... | http://pbs.twimg.com/media/Eys1j7NVIAgF-YF.jpg | 1381630932092784641 | Hair rendering. Will finish the hair by tomorr... | http://pbs.twimg.com/media/EyyKAoaUUAElm-e.jpg | NoEntailment |
| 368 | 1371883298805403649 | 📉 $LINK Number of Receiving Addresses (7d MA) ... | http://pbs.twimg.com/media/EwnoltOWEAAS4mG.jpg | 1373216720974979072 | 📉 $LINK Number of Receiving Addresses (7d MA) ... | http://pbs.twimg.com/media/Ew6lVGYXEAE6Ugi.jpg | NoEntailment |
| 1112 | 1377679115159887873 | April is National Distracted Driving Awareness... | http://pbs.twimg.com/media/Ex5_u7UVIAARjQ2.jpg | 1379075258448281608 | April is Distracted Driving Awareness Month. ... | http://pbs.twimg.com/media/EyN1YjpWUAMc5ak.jpg | NoEntailment |
| 264 | 1330727515741167619 | ♥️Verse Of The Day♥️\n.\n#VerseOfTheDay #Quran... | http://pbs.twimg.com/media/EnexnydXIAYuI11.jpg | 1332623263495819264 | ♥️Verse Of The Day♥️\n.\n#VerseOfTheDay #Quran... | http://pbs.twimg.com/media/En5ty1VXUAATALP.jpg | NoEntailment |
| 865 | 1377784616275296261 | No white picket fence can keep us in. #TBT 200... | http://pbs.twimg.com/media/Ex7fzouWQAITAq8.jpg | 1380175915804672012 | Sometimes you just need to change your altitud... | http://pbs.twimg.com/media/EydernQXIAk2g5v.jpg | NoEntailment |
我们感兴趣的列如下:
text_1image_1text_2image_2label
蕴涵任务被公式化为以下内容:
给定成对的 (text_1, image_1) 和 (text_2, image_2),它们是否蕴涵(或不蕴涵或矛盾)彼此?
我们已经下载了图像。image_1下载为文件名 id1,而 image2下载为文件名 id2。在下一步中,我们将为 df 添加两列 - image_1 和 image_2 的文件路径。
images_one_paths = []
images_two_paths = []
for idx in range(len(df)):
current_row = df.iloc[idx]
id_1 = current_row["id_1"]
id_2 = current_row["id_2"]
extentsion_one = current_row["image_1"].split(".")[-1]
extentsion_two = current_row["image_2"].split(".")[-1]
image_one_path = os.path.join(image_base_path, str(id_1) + f".{extentsion_one}")
image_two_path = os.path.join(image_base_path, str(id_2) + f".{extentsion_two}")
images_one_paths.append(image_one_path)
images_two_paths.append(image_two_path)
df["image_1_path"] = images_one_paths
df["image_2_path"] = images_two_paths
# 创建另一列,包含字符串标签的整数 ID。
df["label_idx"] = df["label"].apply(lambda x: label_map[x])
数据集可视化
def visualize(idx):
current_row = df.iloc[idx]
image_1 = plt.imread(current_row["image_1_path"])
image_2 = plt.imread(current_row["image_2_path"])
text_1 = current_row["text_1"]
text_2 = current_row["text_2"]
label = current_row["label"]
plt.subplot(1, 2, 1)
plt.imshow(image_1)
plt.axis("off")
plt.title("图像一")
plt.subplot(1, 2, 2)
plt.imshow(image_1)
plt.axis("off")
plt.title("图像二")
plt.show()
print(f"文本一: {text_1}")
print(f"文本二: {text_2}")
print(f"标签: {label}")
random_idx = np.random.choice(len(df))
visualize(random_idx)
random_idx = np.random.choice(len(df))
visualize(random_idx)

文本一: 朋友们,有兴趣的都去看看吧!
@ThePartyGoddess @OurLadyAngels @BJsWholesale @Richard_Jeni @FashionLavidaG @RapaRooski @DMVTHING @DeMarcoReports @LobidaFo @DeMarcoMorgan https://t.co/cStULl7y7G
文本二: 朋友们,有兴趣的都去看看吧!
@smittyses @CYosabel @crum_7 @CrumDarrell @ElymalikU @jenloarn @SoCodiePrevost @roblowry82 @Crummy_14 @CSchmelzenbach https://t.co/IZphLTNzgl
标签: 矛盾的

文本一: 👟 开球 @ MARDEN SPORTS COMPLEX
我们已经在第6轮的比赛中开始了!
📺: @Foxtel, @kayosports
📱: My Football Live 应用程序 https://t.co/wHSpvQaoGC
#WLeague #ADLvMVC #AUFC #MVFC https://t.co/3Smp8KXm8W
文本二: 👟 开球 @ MARSDEN SPORTS COMPLEX
我们在阳光明媚的阿德莱德开始了!
📺: @Foxtel, @kayosports
📱: My Football Live 应用程序 https://t.co/wHSpvQaoGC
#ADLvCBR #WLeague #AUFC #UnitedAlways https://t.co/fG1PyLQXM4
标签: 无蕴含
训练/测试划分
该数据集存在 类别不平衡问题。 我们可以在以下单元中确认这一点。
df["label"].value_counts()
无蕴含 1182
蕴含 109
矛盾 109
名称: label, dtype: int64
为了考虑这一点,我们将进行分层划分。
# 10% 用于测试
train_df, test_df = train_test_split(
df, test_size=0.1, stratify=df["label"].values, random_state=42
)
# 5% 用于验证
train_df, val_df = train_test_split(
train_df, test_size=0.05, stratify=train_df["label"].values, random_state=42
)
print(f"总训练示例: {len(train_df)}")
print(f"总验证示例: {len(val_df)}")
print(f"总测试示例: {len(test_df)}")
总训练示例: 1197
总验证示例: 63
总测试示例: 140
数据输入管道
TensorFlow Hub 提供 BERT系列模型的多样性。 每个模型都有一个 相应的预处理层。您可以通过 这个资源了解更多关于这些模型及其 预处理层的信息。
为了缩短本示例的运行时间,我们将使用一个较小的原始 BERT 模型的变体。
# 定义 TF Hub 的 BERT 编码器和其预处理器的路径
bert_model_path = (
"https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1"
)
bert_preprocess_path = "https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3"
我们的文本预处理代码主要来自 这个教程。 我们鼓励您查看该教程以了解更多关于输入 预处理的信息。
def make_bert_preprocessing_model(sentence_features, seq_length=128):
"""返回将字符串特征映射到BERT输入的模型。
参数:
sentence_features: 一个包含字符串特征名称的列表。
seq_length: 一个定义BERT输入序列长度的整数。
返回:
一个Keras模型,可以在字符串Tensor的列表或字典上调用
(顺序或名称由sentence_features给出),并返回一个用于BERT输入的Tensor字典。
"""
input_segments = [
tf.keras.layers.Input(shape=(), dtype=tf.string, name=ft)
for ft in sentence_features
]
# 将文本分词为词片。
bert_preprocess = hub.load(bert_preprocess_path)
tokenizer = hub.KerasLayer(bert_preprocess.tokenize, name="tokenizer")
segments = [tokenizer(s) for s in input_segments]
# 可选: 以智能方式修剪段以适应seq_length。
# 简单情况(像这个例子)可以跳过这一步,让
# 下一步应用默认的截断,达到大致相等的长度。
truncated_segments = segments
# 打包输入。细节(开始/结束令牌id,输出tensor的字典)
# 依赖于模型,因此从SavedModel中加载。
packer = hub.KerasLayer(
bert_preprocess.bert_pack_inputs,
arguments=dict(seq_length=seq_length),
name="packer",
)
model_inputs = packer(truncated_segments)
return keras.Model(input_segments, model_inputs)
bert_preprocess_model = make_bert_preprocessing_model(["text_1", "text_2"])
keras.utils.plot_model(bert_preprocess_model, show_shapes=True, show_dtype=True)
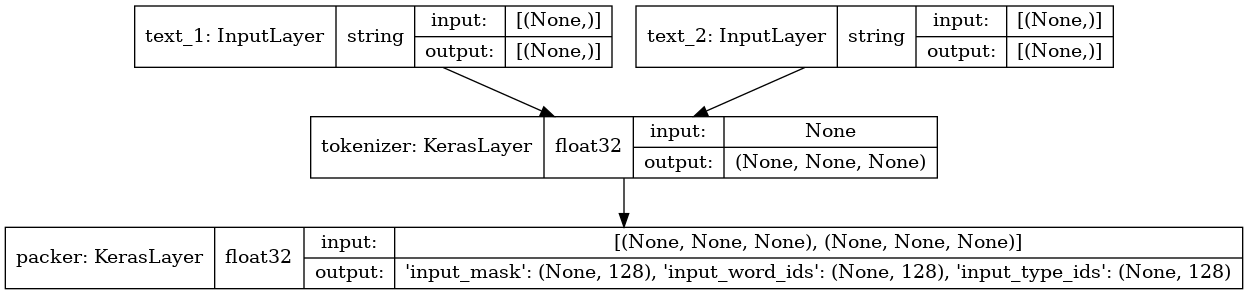
对示例输入运行预处理器
idx = np.random.choice(len(train_df))
row = train_df.iloc[idx]
sample_text_1, sample_text_2 = row["text_1"], row["text_2"]
print(f"Text 1: {sample_text_1}")
print(f"Text 2: {sample_text_2}")
test_text = [np.array([sample_text_1]), np.array([sample_text_2])]
text_preprocessed = bert_preprocess_model(test_text)
print("Keys : ", list(text_preprocessed.keys()))
print("Shape Word Ids : ", text_preprocessed["input_word_ids"].shape)
print("Word Ids : ", text_preprocessed["input_word_ids"][0, :16])
print("Shape Mask : ", text_preprocessed["input_mask"].shape)
print("Input Mask : ", text_preprocessed["input_mask"][0, :16])
print("Shape Type Ids : ", text_preprocessed["input_type_ids"].shape)
print("Type Ids : ", text_preprocessed["input_type_ids"][0, :16])
Text 1: Renewables met 97% of Scotland's electricity demand in 2020!!!!
https://t.co/wi5c9UFAUF https://t.co/arcuBgh0BP
Text 2: Renewables met 97% of Scotland's electricity demand in 2020 https://t.co/SrhyqPnIkU https://t.co/LORgvTM7Sn
Keys : ['input_mask', 'input_word_ids', 'input_type_ids']
Shape Word Ids : (1, 128)
Word Ids : tf.Tensor(
[ 101 13918 2015 2777 5989 1003 1997 3885 1005 1055 6451 5157
1999 12609 999 999], shape=(16,), dtype=int32)
Shape Mask : (1, 128)
Input Mask : tf.Tensor([1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1], shape=(16,), dtype=int32)
Shape Type Ids : (1, 128)
Type Ids : tf.Tensor([0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0], shape=(16,), dtype=int32)
我们现在将从数据框创建 tf.data.Dataset 对象。
注意文本输入将在数据输入管道的一部分中进行预处理。但是,预处理模块也可以作为其对应的 BERT 模型的一部分。这有助于减少训练/服务的偏差,并使我们的模型能够处理原始文本输入。请遵循 这个教程 了解如何将预处理模块直接纳入模型。
def dataframe_to_dataset(dataframe):
columns = ["image_1_path", "image_2_path", "text_1", "text_2", "label_idx"]
dataframe = dataframe[columns].copy()
labels = dataframe.pop("label_idx")
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
ds = ds.shuffle(buffer_size=len(dataframe))
return ds
预处理工具
resize = (128, 128)
bert_input_features = ["input_word_ids", "input_type_ids", "input_mask"]
def preprocess_image(image_path):
extension = tf.strings.split(image_path)[-1]
image = tf.io.read_file(image_path)
if extension == b"jpg":
image = tf.image.decode_jpeg(image, 3)
else:
image = tf.image.decode_png(image, 3)
image = tf.image.resize(image, resize)
return image
def preprocess_text(text_1, text_2):
text_1 = tf.convert_to_tensor([text_1])
text_2 = tf.convert_to_tensor([text_2])
output = bert_preprocess_model([text_1, text_2])
output = {feature: tf.squeeze(output[feature]) for feature in bert_input_features}
return output
def preprocess_text_and_image(sample):
image_1 = preprocess_image(sample["image_1_path"])
image_2 = preprocess_image(sample["image_2_path"])
text = preprocess_text(sample["text_1"], sample["text_2"])
return {"image_1": image_1, "image_2": image_2, "text": text}
创建最终数据集
batch_size = 32
auto = tf.data.AUTOTUNE
def prepare_dataset(dataframe, training=True):
ds = dataframe_to_dataset(dataframe)
if training:
ds = ds.shuffle(len(train_df))
ds = ds.map(lambda x, y: (preprocess_text_and_image(x), y)).cache()
ds = ds.batch(batch_size).prefetch(auto)
return ds
train_ds = prepare_dataset(train_df)
validation_ds = prepare_dataset(val_df, False)
test_ds = prepare_dataset(test_df, False)
模型构建工具
我们的最终模型将接受两个图像及其文本对应的数据。尽管图像将直接输入模型,但文本输入将首先进行预处理,然后再输入模型。下面是这种方法的可视化示例:

该模型由以下元素组成:
- 图像的独立编码器。我们将使用在 ImageNet-1k 数据集上预训练的 ResNet50V2。
- 图像的独立编码器。将使用预训练的 BERT。
提取个体嵌入后,它们将被投影到相同的空间。最后,它们的投影将被拼接并输入最终分类层。 这是一个多类分类问题,涉及以下类别:
- 无蕴含
- 蕴含
- 矛盾
project_embeddings()、create_vision_encoder() 和 create_text_encoder() 工具来自 这个示例。
投影工具
def project_embeddings(
embeddings, num_projection_layers, projection_dims, dropout_rate
):
projected_embeddings = keras.layers.Dense(units=projection_dims)(embeddings)
for _ in range(num_projection_layers):
x = tf.nn.gelu(projected_embeddings)
x = keras.layers.Dense(projection_dims)(x)
x = keras.layers.Dropout(dropout_rate)(x)
x = keras.layers.Add()([projected_embeddings, x])
projected_embeddings = keras.layers.LayerNormalization()(x)
return projected_embeddings
视觉编码器工具
def create_vision_encoder(
num_projection_layers, projection_dims, dropout_rate, trainable=False
):
# 加载预训练的 ResNet50V2 模型,作为基础编码器使用。
resnet_v2 = keras.applications.ResNet50V2(
include_top=False, weights="imagenet", pooling="avg"
)
# 设置基础编码器的可训练性。
for layer in resnet_v2.layers:
layer.trainable = trainable
# 接收图像作为输入。
image_1 = keras.Input(shape=(128, 128, 3), name="image_1")
image_2 = keras.Input(shape=(128, 128, 3), name="image_2")
# 对输入图像进行预处理。
preprocessed_1 = keras.applications.resnet_v2.preprocess_input(image_1)
preprocessed_2 = keras.applications.resnet_v2.preprocess_input(image_2)
# 使用 resnet_v2 模型生成图像的嵌入并将它们拼接在一起。
embeddings_1 = resnet_v2(preprocessed_1)
embeddings_2 = resnet_v2(preprocessed_2)
embeddings = keras.layers.Concatenate()([embeddings_1, embeddings_2])
# 对模型产生的嵌入进行投影。
outputs = project_embeddings(
embeddings, num_projection_layers, projection_dims, dropout_rate
)
# 创建视觉编码器模型。
return keras.Model([image_1, image_2], outputs, name="vision_encoder")
文本编码器工具
def create_text_encoder(
num_projection_layers, projection_dims, dropout_rate, trainable=False
):
# 加载预训练的 BERT 模型,作为基础编码器使用。
bert = hub.KerasLayer(bert_model_path, name="bert",)
# 设置基础编码器的可训练性。
bert.trainable = trainable
# 接收文本作为输入。
bert_input_features = ["input_type_ids", "input_mask", "input_word_ids"]
inputs = {
feature: keras.Input(shape=(128,), dtype=tf.int32, name=feature)
for feature in bert_input_features
}
# 使用 BERT 模型生成预处理文本的嵌入。
embeddings = bert(inputs)["pooled_output"]
# 对模型产生的嵌入进行投影。
outputs = project_embeddings(
embeddings, num_projection_layers, projection_dims, dropout_rate
)
# 创建文本编码器模型。
return keras.Model(inputs, outputs, name="text_encoder")
多模态模型工具
def create_multimodal_model(
num_projection_layers=1,
projection_dims=256,
dropout_rate=0.1,
vision_trainable=False,
text_trainable=False,
):
# 接收图像作为输入。
image_1 = keras.Input(shape=(128, 128, 3), name="image_1")
image_2 = keras.Input(shape=(128, 128, 3), name="image_2")
# 接收文本作为输入。
bert_input_features = ["input_type_ids", "input_mask", "input_word_ids"]
text_inputs = {
feature: keras.Input(shape=(128,), dtype=tf.int32, name=feature)
for feature in bert_input_features
}
# 创建编码器。
vision_encoder = create_vision_encoder(
num_projection_layers, projection_dims, dropout_rate, vision_trainable
)
text_encoder = create_text_encoder(
num_projection_layers, projection_dims, dropout_rate, text_trainable
)
# 获取嵌入投影。
vision_projections = vision_encoder([image_1, image_2])
text_projections = text_encoder(text_inputs)
# 拼接投影,并通过分类层传递。
concatenated = keras.layers.Concatenate()([vision_projections, text_projections])
outputs = keras.layers.Dense(3, activation="softmax")(concatenated)
return keras.Model([image_1, image_2, text_inputs], outputs)
multimodal_model = create_multimodal_model()
keras.utils.plot_model(multimodal_model, show_shapes=True)

您还可以通过将 plot_model() 的 expand_nested 参数设置为 True 来检查各个编码器的结构。鼓励您尝试不同的超参数来构建此模型并
观察最终性能受到的影响。
编译并训练模型
multimodal_model.compile(
optimizer="adam", loss="sparse_categorical_crossentropy", metrics="accuracy"
)
history = multimodal_model.fit(train_ds, validation_data=validation_ds, epochs=10)
第 1 轮/共 10 轮
38/38 [==============================] - 49s 789ms/步 - 损失: 1.0014 - 准确率: 0.8229 - 验证损失: 0.5514 - 验证准确率: 0.8571
第 2 轮/共 10 轮
38/38 [==============================] - 3s 90ms/步 - 损失: 0.4019 - 准确率: 0.8814 - 验证损失: 0.5866 - 验证准确率: 0.8571
第 3 轮/共 10 轮
38/38 [==============================] - 3s 90ms/步 - 损失: 0.3557 - 准确率: 0.8897 - 验证损失: 0.5929 - 验证准确率: 0.8571
第 4 轮/共 10 轮
38/38 [==============================] - 3s 91ms/步 - 损失: 0.2877 - 准确率: 0.9006 - 验证损失: 0.6272 - 验证准确率: 0.8571
第 5 轮/共 10 轮
38/38 [==============================] - 3s 91ms/步 - 损失: 0.1796 - 准确率: 0.9398 - 验证损失: 0.8545 - 验证准确率: 0.8254
第 6 轮/共 10 轮
38/38 [==============================] - 3s 91ms/步 - 损失: 0.1292 - 准确率: 0.9566 - 验证损失: 1.2276 - 验证准确率: 0.8413
第 7 轮/共 10 轮
38/38 [==============================] - 3s 91ms/步 - 损失: 0.1015 - 准确率: 0.9666 - 验证损失: 1.2914 - 验证准确率: 0.7778
第 8 轮/共 10 轮
38/38 [==============================] - 3s 92ms/步 - 损失: 0.1253 - 准确率: 0.9524 - 验证损失: 1.1944 - 验证准确率: 0.8413
第 9 轮/共 10 轮
38/38 [==============================] - 3s 92ms/步 - 损失: 0.3064 - 准确率: 0.9131 - 验证损失: 1.2162 - 验证准确率: 0.8095
第 10 轮/共 10 轮
38/38 [==============================] - 3s 92ms/步 - 损失: 0.2212 - 准确率: 0.9248 - 验证损失: 1.1080 - 验证准确率: 0.8413
评估模型
_, acc = multimodal_model.evaluate(test_ds)
print(f"Accuracy on the test set: {round(acc * 100, 2)}%.")
5/5 [==============================] - 6s 1s/步 - 损失: 0.8390 - 准确率: 0.8429
测试集准确率: 84.29%。
关于训练的附加说明
引入正则化:
训练日志表明,模型开始过拟合,并可能从正则化中受益。Dropout (Srivastava et al.) 是一种简单而强大的正则化技术,我们可以在模型中使用它。 但我们该如何在这里应用它?
我们可以在模型的不同层之间引入 Dropout (keras.layers.Dropout)。
但这还有另外一种方法。我们的模型期望来自两种不同数据模式的输入。
如果在推断过程中某种模式缺失怎么办?为了考虑这一点,
我们可以在它们被连接之前引入 Dropout 到各自的投影中:
vision_projections = keras.layers.Dropout(rate)(vision_projections)
text_projections = keras.layers.Dropout(rate)(text_projections)
concatenated = keras.layers.Concatenate()([vision_projections, text_projections])
关注重要内容:
图像的所有部分是否都与其文本对应部分同等相关?可能并非如此。 为了使我们的模型仅关注与其对应文本部分良好相关的图像中最重要的片段,我们可以使用“交叉注意力”:
# 嵌入。
vision_projections = vision_encoder([image_1, image_2])
text_projections = text_encoder(text_inputs)
# 交叉注意力(Luong 风格)。
query_value_attention_seq = keras.layers.Attention(use_scale=True, dropout=0.2)(
[vision_projections, text_projections]
)
# 连接。
concatenated = keras.layers.Concatenate()([vision_projections, text_projections])
contextual = keras.layers.Concatenate()([concatenated, query_value_attention_seq])
要查看这一过程,请参阅 这个笔记本。
处理类别不平衡:
该数据集存在类别不平衡问题。调查上述模型的混淆矩阵发现,它在少数类上的表现较差。如果我们使用加权损失,训练将更具指导性。您可以查看 这个笔记本 ,该笔记本在模型训练期间考虑了类别不平衡。
仅使用文本输入:
此外,如果我们只为蕴含任务引入文本输入,会怎样?由于在社交媒体平台遇到的文本输入的性质,仅使用文本输入会影响最终性能。 在类似的训练设置下,仅使用文本输入我们在同一测试集上达到了 67.14% 的 top-1 准确率。有关详细信息,请参阅 这个笔记本。
最后,这里有一个表格比较不同方法在蕴含任务上的表现:
| 类型 | 标准
交叉熵 | 加权损失
交叉熵 | 焦点损失 |
|:—: |:—: |:—: |:—: |
| 多模态 | 77.86% | 67.86% | 86.43% |
| 仅文本 | 67.14% | 11.43% | 37.86% |
你可以查看 这个仓库 了解更多关于如何进行实验以获得这些数字的信息。
最后的备注
- 我们在这个例子中使用的架构对于可用于训练的数据点数量来说过于庞大。它将从更多数据中受益。
- 我们使用了原始 BERT 模型的小型变体。使用更大变体的可能性很高,这将改善这种性能。TensorFlow Hub 提供了 许多不同的 BERT 模型供你试验。
- 我们保持了预训练模型的冻结。在多模态蕴含任务上微调它们可能会导致更好的性能。
- 我们为多模态蕴含任务构建了一个简单的基准模型。提出了多种方法来解决蕴含问题。 这个演示文稿 来自 识别多模态蕴含 教程提供了全面的概述。
你可以使用在 Hugging Face Hub 托管的训练模型,并在 Hugging Face Spaces 上尝试演示。