多项选择任务与迁移学习
作者: Md Awsafur Rahman
创建日期: 2023/09/14
最后修改: 2023/09/14
描述: 使用预训练的 NLP 模型进行多项选择任务。

介绍
在本示例中,我们将演示如何通过微调预训练的 DebertaV3 模型来执行 多项选择 任务。在此任务中,提供多个候选答案以及上下文,模型训练以选择正确答案,而不同于问答任务。我们将使用 SWAG 数据集来演示此示例。
设置
import keras_nlp
import keras
import tensorflow as tf # 仅用于 tf.data。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
数据集
在本示例中,我们将使用 SWAG 数据集进行多项选择任务。
!wget "https://github.com/rowanz/swagaf/archive/refs/heads/master.zip" -O swag.zip
!unzip -q swag.zip
--2023-11-13 20:05:24-- https://github.com/rowanz/swagaf/archive/refs/heads/master.zip
正在解析 github.com (github.com)... 192.30.255.113
正在连接到 github.com (github.com)|192.30.255.113|:443... 已连接。
发送 HTTP 请求,等待响应... 302 找到
位置: https://codeload.github.com/rowanz/swagaf/zip/refs/heads/master [跟随]
--2023-11-13 20:05:25-- https://codeload.github.com/rowanz/swagaf/zip/refs/heads/master
正在解析 codeload.github.com (codeload.github.com)... 20.29.134.24
正在连接到 codeload.github.com (codeload.github.com)|20.29.134.24|:443... 已连接。
发送 HTTP 请求,等待响应... 200 正常
长度:未指定 [application/zip]
正在保存到: ‘swag.zip’
swag.zip [ <=> ] 19.94M 4.25MB/s in 4.7s
2023-11-13 20:05:30 (4.25 MB/s) - ‘swag.zip’ 已保存 [20905751]
!ls swagaf-master/data
README.md test.csv train.csvtrain_full.csvval.csv val_full.csv
配置
class CFG:
preset = "deberta_v3_extra_small_en" # 预训练模型名称
sequence_length = 200 # 输入序列长度
seed = 42 # 随机种子
epochs = 5 # 训练轮数
batch_size = 8 # 批量大小
augment = True # 增强(随机选项)
可重复性
设置随机种子的值,以在每次运行中产生类似的结果。
keras.utils.set_random_seed(CFG.seed)
元数据
- train.csv - 将用于训练。
sent1和sent2:这些字段显示句子的起始部分,如果你将两者结合在一起,就得到了startphrase字段。ending_<i>:建议句子可能的结束方式,但只有其中一个是正确的。 *label:识别正确的句子结束。
- val.csv - 与
train.csv类似,但将用于验证。
# 训练数据
train_df = pd.read_csv(
"swagaf-master/data/train.csv", index_col=0
) # 将 CSV 文件读取到 DataFrame
train_df = train_df.sample(frac=0.02)
print("# 训练数据: {:,}".format(len(train_df)))
# 验证数据
valid_df = pd.read_csv(
"swagaf-master/data/val.csv", index_col=0
) # 将 CSV 文件读取到 DataFrame
valid_df = valid_df.sample(frac=0.02)
print("# 验证数据: {:,}".format(len(valid_df)))
# 训练数据: 1,471
# 验证数据: 400
选项上下文化
我们的方法是向模型提供问题和答案对,而不是为所有五个选项提供一个单一的问题。在实践中,这意味着对于这五个选项,我们将向模型提供相同的一组五个问题与每个相应的答案选择结合(例如,(Q + A),(Q + B),等等)。这一类比类似于在考试期间多次复习一个问题,以促进对问题的更深入理解。
值得注意的是,在 SWAG 数据集的上下文中,问题是句子的开头,而选项是句子的可能结束。
# 定义一个函数,根据提示和选项创建选项
def make_options(row):
row["options"] = [
f"{row.startphrase}\n{row.ending0}", # 选项 0
f"{row.startphrase}\n{row.ending1}", # 选项 1
f"{row.startphrase}\n{row.ending2}", # 选项 2
f"{row.startphrase}\n{row.ending3}",
] # 选项 3
return row
应用make_options函数到数据框的每一行
train_df = train_df.apply(make_options, axis=1)
valid_df = valid_df.apply(make_options, axis=1)
预处理
它的功能: 预处理器将输入字符串转换为一个包含预处理张量的字典(token_ids,padding_mask)。这个过程从标记化开始,将输入字符串转换为标记 ID 的序列。
为什么重要: 原始文本数据复杂且难以建模,因为它的高维性。通过将文本转换为紧凑的标记集,例如将"The quick brown fox"转换为["the", "qu", "##ick", "br", "##own", "fox"],我们简化了数据。许多模型依赖特殊标记和附加张量来理解输入。这些标记有助于划分输入并识别填充等任务。通过填充使所有序列长度相同可以提高计算效率,使后续步骤更顺畅。
访问以下页面以获取 KerasNLP 中可用的预处理和标记器层: - 预处理 - 标记器
preprocessor = keras_nlp.models.DebertaV3Preprocessor.from_preset(
preset=CFG.preset, # 模型名称
sequence_length=CFG.sequence_length, # 最大序列长度,较短时将进行填充
)
现在,让我们检查一下预处理层的输出形状。层的输出形状可以表示为 $(num_choices, sequence_length)$。
outs = preprocessor(train_df.options.iloc[0]) # 处理第一行的选项
# 显示每个处理后输出的形状
for k, v in outs.items():
print(k, ":", v.shape)
CUDA 后端初始化失败:发现 CUDA 版本 12010,但 JAX 是针对较新版本 12020 构建的。安装的 CUDA 版本必须至少与 JAX 构建时的版本一样新。(设置 TF_CPP_MIN_LOG_LEVEL=0 并重新运行以获取更多信息。)
token_ids : (4, 200)
padding_mask : (4, 200)
我们将使用preprocessing_fn函数通过dataset.map(preprocessing_fn)方法转换每个文本选项。
def preprocess_fn(text, label=None):
text = preprocessor(text) # 预处理文本
return (
(text, label) if label is not None else text
) # 返回处理后的文本和标签(如果可用)
增强
在这个笔记本中,我们将尝试一种有趣的增强技术,option_shuffle。因为我们一次向模型提供一个选项,所以我们可以引入选项顺序的洗牌。例如,选项[A, C, E, D, B]将重新排序为[D, B, A, E, C]。这个做法将帮助模型专注于选项本身的内容,而不是受到其位置的影响。
注意: 尽管option_shuffle函数是用纯 TensorFlow 编写的,但它可以与任何后端(例如 JAX、PyTorch)一起使用,因为它只在与 Keras 3 例程兼容的tf.data.Dataset管道中使用。
def option_shuffle(options, labels, prob=0.50, seed=None):
if tf.random.uniform([]) > prob: # 洗牌概率检查
return options, labels
# 按相同顺序洗牌选项和标签的索引
indices = tf.random.shuffle(tf.range(tf.shape(options)[0]), seed=seed)
# 洗牌选项和标签
options = tf.gather(options, indices)
labels = tf.gather(labels, indices)
return options, labels
在以下函数中,我们将合并所有增强功能以应用于文本。这些增强将使用dataset.map(augment_fn)方法应用于数据。
def augment_fn(text, label=None):
text, label = option_shuffle(text, label, prob=0.5) # 洗牌选项
return (text, label) if label is not None else text
数据加载器
下面的代码使用tf.data.Dataset设置了一个强大的数据流管道以进行数据处理。tf.data的显著特点包括简化管道构建能力和以序列表示组件的能力。
def build_dataset(
texts,
labels=None,
batch_size=32,
cache=False,
augment=False,
repeat=False,
shuffle=1024,
):
AUTO = tf.data.AUTOTUNE # AUTOTUNE 选项
slices = (
(texts,)
if labels is None
else (texts, keras.utils.to_categorical(labels, num_classes=4))
) # 创建切片
ds = tf.data.Dataset.from_tensor_slices(slices) # 从切片创建数据集
ds = ds.cache() if cache else ds # 如果启用,缓存数据集
if augment: # 如果启用,应用增强
ds = ds.map(augment_fn, num_parallel_calls=AUTO)
ds = ds.map(preprocess_fn, num_parallel_calls=AUTO) # 映射预处理函数
ds = ds.repeat() if repeat else ds # 如果启用,重复数据集
opt = tf.data.Options() # 创建数据集选项
if shuffle:
ds = ds.shuffle(shuffle, seed=CFG.seed) # 如果启用,打乱数据集
opt.experimental_deterministic = False
ds = ds.with_options(opt) # 设置数据集选项
ds = ds.batch(batch_size, drop_remainder=True) # 批量处理数据集
ds = ds.prefetch(AUTO) # 预取下一个批次
return ds # 返回构建的数据集
相同模型的五个实例。
# 构建训练数据加载器
train_texts = train_df.options.tolist() # 提取训练文本
train_labels = train_df.label.tolist() # 提取训练标签
train_ds = build_dataset(
train_texts,
train_labels,
batch_size=CFG.batch_size,
cache=True,
shuffle=True,
repeat=True,
augment=CFG.augment,
)
# 构建验证数据加载器
valid_texts = valid_df.options.tolist() # 提取验证文本
valid_labels = valid_df.label.tolist() # 提取验证标签
valid_ds = build_dataset(
valid_texts,
valid_labels,
batch_size=CFG.batch_size,
cache=True,
shuffle=False,
repeat=False,
augment=False,
)
学习率调度
实现学习率调度器对于迁移学习至关重要。学习率从 lr_start 开始,并通过 余弦 曲线逐渐降低到 lr_min。
重要性: 一个结构良好的学习率调度对于高效的模型训练至关重要,确保最佳收敛,并避免过冲或停滞等问题。
import math
def get_lr_callback(batch_size=8, mode="cos", epochs=10, plot=False):
lr_start, lr_max, lr_min = 1.0e-6, 0.6e-6 * batch_size, 1e-6
lr_ramp_ep, lr_sus_ep = 2, 0
def lrfn(epoch): # 学习率更新函数
if epoch < lr_ramp_ep:
lr = (lr_max - lr_start) / lr_ramp_ep * epoch + lr_start
elif epoch < lr_ramp_ep + lr_sus_ep:
lr = lr_max
else:
decay_total_epochs, decay_epoch_index = (
epochs - lr_ramp_ep - lr_sus_ep + 3,
epoch - lr_ramp_ep - lr_sus_ep,
)
phase = math.pi * decay_epoch_index / decay_total_epochs
lr = (lr_max - lr_min) * 0.5 * (1 + math.cos(phase)) + lr_min
return lr
if plot: # 如果 plot 为 True,则绘制学习率曲线
plt.figure(figsize=(10, 5))
plt.plot(
np.arange(epochs),
[lrfn(epoch) for epoch in np.arange(epochs)],
marker="o",
)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("学习率调度器")
plt.show()
return keras.callbacks.LearningRateScheduler(
lrfn, verbose=False
) # 创建学习率回调
_ = get_lr_callback(CFG.batch_size, plot=True)
![]()
回调函数
下面的函数将收集所有的训练回调,例如 lr_scheduler 和 model_checkpoint。
def get_callbacks():
callbacks = []
lr_cb = get_lr_callback(CFG.batch_size) # 获取学习率回调
ckpt_cb = keras.callbacks.ModelCheckpoint(
f"best.keras",
monitor="val_accuracy",
save_best_only=True,
save_weights_only=False,
mode="max",
) # 获取模型检查点回调
callbacks.extend([lr_cb, ckpt_cb]) # 添加学习率和检查点回调
return callbacks # 返回回调列表
callbacks = get_callbacks()
多项选择模型
预训练模型
KerasNLP 库提供了流行的 NLP 模型架构的全面、现成的实现。它提供了多种预训练模型,包括 Bert、Roberta、DebertaV3 等。在本笔记本中,我们将展示 DistillBert 的用法。不过,欢迎随时浏览 KerasNLP 文档 中的所有可用模型。同时,要深入了解 KerasNLP,请参考信息丰富的 入门指南。
我们的方法是使用 keras_nlp.models.XXClassifier 来处理每个问题和选项对(例如 (Q+A), (Q+B) 等),生成 logits。这些 logits 然后结合并通过 softmax 函数产生最终输出。
多项选择任务的分类器
在处理多项选择问题时,我们不将问题和所有选项一起提供给模型 (Q + A + B + C ...),而是一次提供一个选项和问题。例如,(Q + A)、(Q + B),依此类推。一旦我们获得了所有选项的预测分数(logits),我们通过 Softmax 函数将它们结合以获得最终结果。如果我们将所有选项一次性提供给模型,文本的长度将增加,使得模型更难处理。下图说明了这个想法:
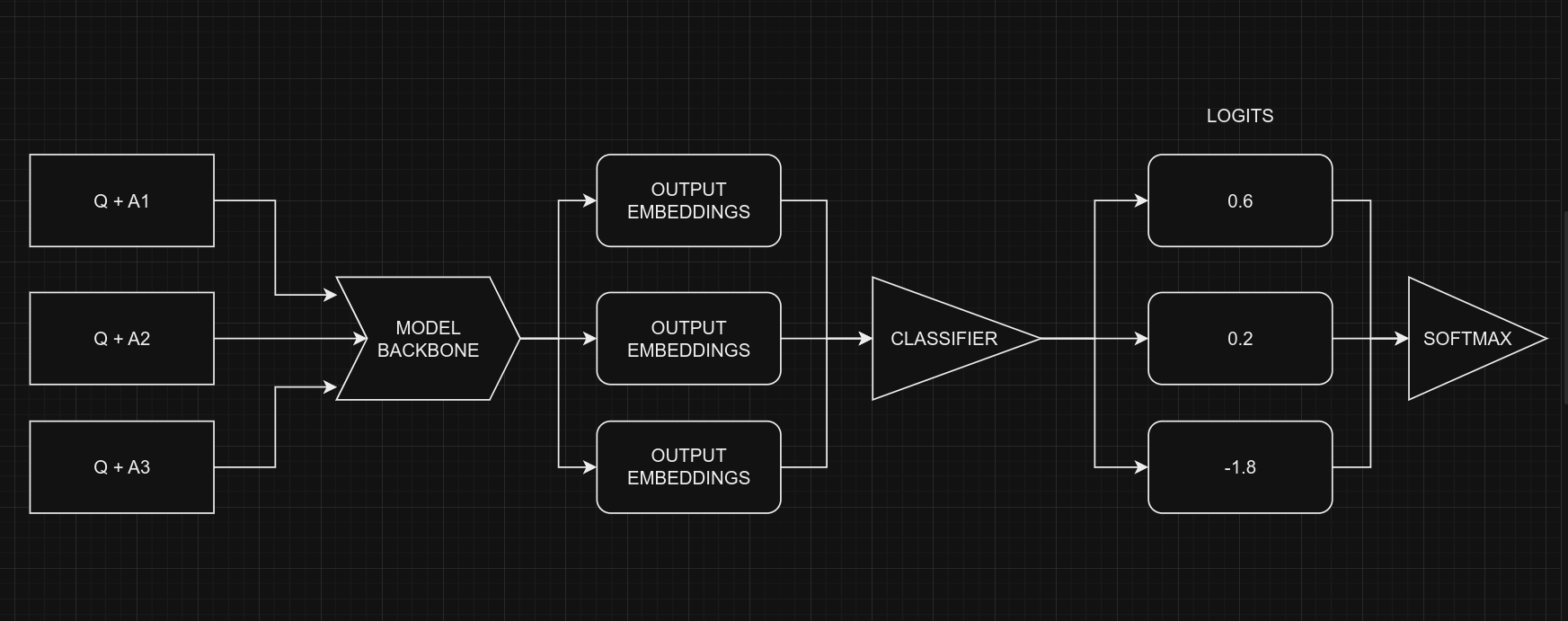
从编码的角度来看,请记住我们对所有五个选项使用相同的模型,具有共享权重。尽管图形暗示五个独立的模型,但实际上它们是一个模型,具有共享权重。另一个需要考虑的点是分类器和多项选择的输入形状。
- 多项选择的输入形状:$(batch_size, num_choices, seq_length)$
- 分类器的输入形状:$(batch_size, seq_length)$
显然,我们不能直接将多项选择任务的数据提供给模型,因为输入形状不匹配。为了解决这个问题,我们将使用 切片。这意味着我们将每个选项的特征分开,例如 $feature_{(Q + A)}$ 和 $feature_{(Q + B)}$,并将它们逐个提供给 NLP 分类器。在获得所有选项的预测分数 $logits_{(Q + A)}$ 和 $logits_{(Q + B)}$ 后,我们将使用 Softmax 函数,例如 $\operatorname{Softmax}([logits_{(Q + A)}, logits_{(Q + B)}])$,将它们结合。这最后一步帮助我们做出最终的决定或选择。
请注意,在分类器中,我们将
num_classes=1而不是5。这是因为分类器对每个选项产生一个输出。当处理五个选项时,这些单个输出被组合在一起,然后通过 softmax 函数处理,以生成最终结果,其维度为5。
# 从五个选项中选择一个
class SelectOption(keras.layers.Layer):
def __init__(self, index, **kwargs):
super().__init__(**kwargs)
self.index = index
def call(self, inputs):
# 从输入张量中选择特定切片
return inputs[:, self.index, :]
def get_config(self):
# 用于序列化模型
base_config = super().get_config()
config = {
"index": self.index,
}
return {**base_config, **config}
def build_model():
# 定义输入层
inputs = {
"token_ids": keras.Input(shape=(4, None), dtype="int32", name="token_ids"),
"padding_mask": keras.Input(
shape=(4, None), dtype="int32", name="padding_mask"
),
}
# 创建一个DebertaV3分类器模型
classifier = keras_nlp.models.DebertaV3Classifier.from_preset(
CFG.preset,
preprocessor=None,
num_classes=1, # 每个选项一个输出,总共五个选项的输出
)
logits = []
# 遍历每个选项 (Q+A), (Q+B) 等并计算相关的logits
for option_idx in range(4):
option = {
k: SelectOption(option_idx, name=f"{k}_{option_idx}")(v)
for k, v in inputs.items()
}
logit = classifier(option)
logits.append(logit)
# 计算最终输出
logits = keras.layers.Concatenate(axis=-1)(logits)
outputs = keras.layers.Softmax(axis=-1)(logits)
model = keras.Model(inputs, outputs)
# 使用优化器、损失和指标编译模型
model.compile(
optimizer=keras.optimizers.AdamW(5e-6),
loss=keras.losses.CategoricalCrossentropy(label_smoothing=0.02),
metrics=[
keras.metrics.CategoricalAccuracy(name="accuracy"),
],
jit_compile=True,
)
return model
# 构建模型
model = build_model()
让我们查看模型摘要,以更好地理解模型。
model.summary()
模型: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, 4, None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids │ (None, 4, None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ padding_mask_0 │ (无, 无) │ 0 │ padding_mask[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids_0 │ (无, 无) │ 0 │ token_ids[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ padding_mask_1 │ (无, 无) │ 0 │ padding_mask[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids_1 │ (无, 无) │ 0 │ token_ids[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ padding_mask_2 │ (无, 无) │ 0 │ padding_mask[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids_2 │ (无, 无) │ 0 │ token_ids[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ padding_mask_3 │ (无, 无) │ 0 │ padding_mask[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids_3 │ (无, 无) │ 0 │ token_ids[0][0] │ │ (选择选项) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ deberta_v3_classif… │ (无, 1) │ 70,830… │ padding_mask_0[0][0… │ │ (DebertaV3Classifi… │ │ │ token_ids_0[0][0], │ │ │ │ │ padding_mask_1[0][0… │ │ │ │ │ token_ids_1[0][0], │ │ │ │ │ padding_mask_2[0][0… │ │ │ │ │ token_ids_2[0][0], │ │ │ │ │ padding_mask_3[0][0… │ │ │ │ │ token_ids_3[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ concatenate │ (无, 4) │ 0 │ deberta_v3_classifi… │ │ (连接) │ │ │ deberta_v3_classifi… │ │ │ │ │ deberta_v3_classifi… │ │ │ │ │ deberta_v3_classifi… │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ softmax (Softmax) │ (无, 4) │ 0 │ concatenate[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
总参数: 70,830,337 (270.20 MB)
可训练参数: 70,830,337 (270.20 MB)
非可训练参数: 0 (0.00 B)
最后,让我们检查一下模型结构,看看一切是否就位。
keras.utils.plot_model(model, show_shapes=True)
![]()
训练
# 开始训练模型
history = model.fit(
train_ds,
epochs=CFG.epochs,
validation_data=valid_ds,
callbacks=callbacks,
steps_per_epoch=int(len(train_df) / CFG.batch_size),
verbose=1,
)
Epoch 1/5
183/183 ━━━━━━━━━━━━━━━━━━━━ 5087s 25s/step - accuracy: 0.2563 - loss: 1.3884 - val_accuracy: 0.5150 - val_loss: 1.3742 - learning_rate: 1.0000e-06
Epoch 2/5
183/183 ━━━━━━━━━━━━━━━━━━━━ 4529s 25s/step - accuracy: 0.3825 - loss: 1.3364 - val_accuracy: 0.7125 - val_loss: 0.9071 - learning_rate: 2.9000e-06
Epoch 3/5
183/183 ━━━━━━━━━━━━━━━━━━━━ 4524s 25s/step - accuracy: 0.6144 - loss: 1.0118 - val_accuracy: 0.7425 - val_loss: 0.8017 - learning_rate: 4.8000e-06
Epoch 4/5
183/183 ━━━━━━━━━━━━━━━━━━━━ 4522s 25s/step - accuracy: 0.6744 - loss: 0.8460 - val_accuracy: 0.7625 - val_loss: 0.7323 - learning_rate: 4.7230e-06
Epoch 5/5
183/183 ━━━━━━━━━━━━━━━━━━━━ 4517s 25s/step - accuracy: 0.7200 - loss: 0.7458 - val_accuracy: 0.7750 - val_loss: 0.7022 - learning_rate: 4.4984e-06
推理
# 使用训练好的模型在最后的验证数据上进行预测
predictions = model.predict(
valid_ds,
batch_size=CFG.batch_size, # 最大批量大小 = 验证集大小
verbose=1,
)
# 格式化预测结果和真实答案
pred_answers = np.arange(4)[np.argsort(-predictions)][:, 0]
true_answers = valid_df.label.values
# 检查 5 个预测结果
print("# 预测结果\n")
for i in range(0, 50, 10):
row = valid_df.iloc[i]
question = row.startphrase
pred_answer = f"ending{pred_answers[i]}"
true_answer = f"ending{true_answers[i]}"
print(f"❓ 句子 {i+1}:\n{question}\n")
print(f"✅ 正确结尾: {true_answer}\n >> {row[true_answer]}\n")
print(f"🤖 预测结尾: {pred_answer}\n >> {row[pred_answer]}\n")
print("-" * 90, "\n")
50/50 ━━━━━━━━━━━━━━━━━━━━ 274s 5s/step
# 预测结果
❓ 句子 1:
这个男人向青少年展示如何划桨。青少年
✅ 正确结尾: ending3
>> 按照这个男人的指示并划桨。
🤖 预测结尾: ending3
>> 按照这个男人的指示并划桨。
------------------------------------------------------------------------------------------
❓ 句子 11:
湖泊映出了山脉和天空。有人
✅ 正确结尾: ending2
>> 沿着沙漠公路奔跑。
🤖 预测结尾: ending1
>> 留在门口。
------------------------------------------------------------------------------------------
❓ 句子 21:
屏幕上,她微笑着有人举起一个礼物。他严肃地看着屏幕,看到他的母亲
✅ 正确结尾: ending1
>> 把他抱起,在花园里和他玩耍。
🤖 预测结尾: ending0
>> 走出她的公寓,怒视着她的笔记本电脑。
------------------------------------------------------------------------------------------
❓ 句子 31:
一个穿着黑色衬衫的女人坐在长椅上。一个男人
✅ 正确结尾: ending2
>> 坐在桌子后面。
🤖 预测结尾: ending0
>> 正在舞台上跳舞。
------------------------------------------------------------------------------------------
❓ 句子 41:
人们穿着红色衬衫站在沙子上。他们
✅ 正确结尾: ending3
>> 在沙子上踢足球。
🤖 预测结尾: ending3
>> 在沙子上踢足球。
------------------------------------------------------------------------------------------
参考
- 使用 HF 的多项选择
- Keras NLP
- [BirdCLEF23: 预训练是您所需的一切]
[训练]](https://www.kaggle.com/code/awsaf49/birdclef23-pretraining-is-all-you-need-train)
[训练]](https://www.kaggle.com/code/awsaf49/birdclef23-pretraining-is-all-you-need-train) - 三重分层KFold与 TFRecords