参数高效的GPT-2微调与LoRA
作者: Abheesht Sharma, Matthew Watson
创建日期: 2023/05/27
最后修改日期: 2023/05/27
描述: 使用KerasNLP微调带有LoRA的GPT-2 LLM。

介绍
大型语言模型 (LLM) 已经证明在各种NLP任务中有效。LLM首先在大规模文本语料库上进行自监督的预训练。预训练帮助LLM学习通用知识,例如单词之间的统计关系。然后,LLM可以在感兴趣的下游任务(例如情感分析)上进行微调。
然而,LLM的大小非常庞大,在微调时我们并不需要训练模型中的所有参数,尤其是因为微调模型的数据集相对较小。换句话说,LLM对于微调来说参数过多。此时,低秩适应 (LoRA) 就派上用场了;它显著减少了可训练参数的数量。这导致训练时间和GPU内存使用量减少,同时保持输出质量。
在此示例中,我们将用技术术语解释LoRA,展示技术解释如何转化为代码,黑客KerasNLP的GPT-2模型并使用LoRA在下一个标记预测任务上进行微调。我们将从生成文本的质量、训练时间和GPU内存使用方面比较LoRA GPT-2与完全微调的GPT-2。
注意:此示例完全在TensorFlow后端上运行,目的是为了便于绘制内存使用情况的tf.config.experimental.get_memory_info API。除了内存使用回调外,此示例将在jax和torch后端上运行。
设置
在开始实现管道之前,先安装并导入所有需要的库。我们将使用KerasNLP库。
其次,让我们启用混合精度训练。这将帮助我们减少训练时间。
!pip install -q --upgrade keras-nlp
!pip install -q --upgrade keras # 升级到Keras 3.
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras_nlp
import keras
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
import time
keras.mixed_precision.set_global_policy("mixed_float16")
让我们还定义我们的超参数。
# 一般超参数
BATCH_SIZE = 32
NUM_BATCHES = 500
EPOCHS = 1 # 可以设置为更高的值以获得更好的结果
MAX_SEQUENCE_LENGTH = 128
MAX_GENERATION_LENGTH = 200
GPT2_PRESET = "gpt2_base_en"
# LoRA特定的超参数
RANK = 4
ALPHA = 32.0
数据集
让我们加载一个Reddit数据集。我们将对该数据集的一个子集进行GPT-2模型和LoRA GPT-2模型的微调。目的是生成与Reddit帖子风格相似的文本。
reddit_ds = tfds.load("reddit_tifu", split="train", as_supervised=True)
该数据集有两个字段:document和title。
for document, title in reddit_ds:
print(document.numpy())
print(title.numpy())
break
我们现在将对数据集进行批处理,只保留 document 字段,因为我们正在对模型进行下一个单词预测任务的微调。为了这个示例,取数据集的一个子集。
train_ds = (
reddit_ds.map(lambda document, _: document)
.batch(BATCH_SIZE)
.cache()
.prefetch(tf.data.AUTOTUNE)
)
train_ds = train_ds.take(NUM_BATCHES)
辅助函数
在开始微调模型之前,让我们定义几个辅助函数和类。
用于跟踪GPU内存使用情况的回调
我们将定义一个自定义回调函数来跟踪GPU内存使用情况。该回调函数使用TensorFlow的 tf.config.experimental.get_memory_info API。
在这里,我们假设我们使用的是单个GPU,GPU:0。
class GPUMemoryCallback(keras.callbacks.Callback):
def __init__(
self,
target_batches,
print_stats=False,
**kwargs,
):
super().__init__(**kwargs)
self.target_batches = target_batches
self.print_stats = print_stats
self.memory_usage = []
self.labels = []
def _compute_memory_usage(self):
memory_stats = tf.config.experimental.get_memory_info("GPU:0")
# 转换字节为GB并存储在列表中。
peak_usage = round(memory_stats["peak"] / (2**30), 3)
self.memory_usage.append(peak_usage)
def on_epoch_begin(self, epoch, logs=None):
self._compute_memory_usage()
self.labels.append(f"epoch {epoch} start")
def on_train_batch_begin(self, batch, logs=None):
if batch in self.target_batches:
self._compute_memory_usage()
self.labels.append(f"batch {batch}")
def on_epoch_end(self, epoch, logs=None):
self._compute_memory_usage()
self.labels.append(f"epoch {epoch} end")
文本生成函数
这是一个生成文本的辅助函数。
def generate_text(model, input_text, max_length=200):
start = time.time()
output = model.generate(input_text, max_length=max_length)
print("\nOutput:")
print(output)
end = time.time()
print(f"总耗时: {end - start:.2f}s")
定义优化器和损失函数
我们将使用AdamW优化器和交叉熵损失来训练这两个模型。
def get_optimizer_and_loss():
optimizer = keras.optimizers.AdamW(
learning_rate=5e-5,
weight_decay=0.01,
epsilon=1e-6,
global_clipnorm=1.0, # 梯度裁剪。
)
# 将layernorm和偏差项排除在权重衰减之外。
optimizer.exclude_from_weight_decay(var_names=["bias"])
optimizer.exclude_from_weight_decay(var_names=["gamma"])
optimizer.exclude_from_weight_decay(var_names=["beta"])
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
return optimizer, loss
微调GPT-2
让我们首先加载模型和预处理器。我们使用128的序列长度,而不是默认的1024。这将限制我们预测长序列的能力,但会让我们能够在Colab上快速运行这个示例。
preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=MAX_SEQUENCE_LENGTH,
)
gpt2_lm = keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en", preprocessor=preprocessor
)
gpt2_lm.summary()
预处理器: "gpt2_causal_lm_preprocessor"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 分词器 (类型) ┃ 词汇数 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ gpt2_tokenizer (GPT2Tokenizer) │ 50,257 │ └────────────────────────────────────────────────────┴─────────────────────────────────────────────────────┘
模型: "gpt2_causal_lm"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask (输入层) │ (None, None) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_ids (输入层) │ (None, None) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ gpt2_backbone (GPT2主干) │ (None, None, 768) │ 124,439,808 │ padding_mask[0][0], │ │ │ │ │ token_ids[0][0] │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_embedding │ (None, None, 50257) │ 38,597,376 │ gpt2_backbone[0][0] │ │ (可逆嵌入) │ │ │ │ └───────────────────────────────┴───────────────────────────┴─────────────┴────────────────────────────────┘
总参数: 124,439,808 (474.70 MB)
可训练参数: 124,439,808 (474.70 MB)
非可训练参数: 0 (0.00 B)
初始化 GPU 内存追踪回调对象,并编译模型。我们 使用 Adam 优化器和线性衰减的学习率。
gpu_memory_callback = GPUMemoryCallback(
target_batches=[5, 10, 25, 50, 100, 150, 200, 300, 400, 500],
print_stats=True,
)
optimizer, loss = get_optimizer_and_loss()
gpt2_lm.compile(
optimizer=optimizer,
loss=loss,
weighted_metrics=["accuracy"],
)
我们准备好训练模型了!
gpt2_lm.fit(train_ds, epochs=EPOCHS, callbacks=[gpu_memory_callback])
gpt2_lm_memory_usage = gpu_memory_callback.memory_usage
警告:在调用 absl::InitializeLog() 之前的所有日志消息都写入 STDERR
I0000 00:00:1701128462.076856 38706 device_compiler.h:186] 使用 XLA 编译的集群!此行在进程的生命周期内最多记录一次。
W0000 00:00:1701128462.146837 38706 graph_launch.cc:671] 由于 memset 节点破坏了图更新,回退到逐操作模式
500/500 ━━━━━━━━━━━━━━━━━━━━ 114s 128ms/步 - 准确率: 0.3183 - 损失: 3.3682
作为最后一步,让我们生成一些文本。我们将利用XLA的力量。
第一次调用generate()会很慢,因为要进行XLA编译,但后续调用将非常快速。 :)
generate_text(gpt2_lm, "我喜欢篮球", max_length=MAX_GENERATION_LENGTH)
generate_text(gpt2_lm, "那家意大利餐厅是", max_length=MAX_GENERATION_LENGTH)
输出:
我喜欢篮球,但这件事实际上发生在几个月前。
我当时正前往城里的一个派对时,注意到一群家伙在打篮球。我的一个朋友,一个叫“珍妮”的家伙正在打球。珍妮的妈妈,一个非常好的人,正坐在她的沙发上。
珍妮和珍妮围坐成一圈,我开始玩一些我最喜欢的篮球游戏。我走到圈子的尽头,珍妮开始跑。我不知道珍妮在做什么。她跑了,但它
消耗的总时间:6.66秒
输出:
那家意大利餐厅有点神秘,因为这个地方关门了。
所以我在我朋友家,我去拿点食物,于是我拿了平常的比萨和一些鸡肉,但它实际上并不是比萨,所以我只是拿了我朋友的比萨。
我吃了很多鸡肉,但我很饿,于是我决定拿几块已经在那里的其他比萨。
我和一些朋友一起吃比萨,然后我吃比萨后,有人敲门。
我面前的那个家伙是
消耗的总时间:0.22秒
LoRA GPT-2
在本节中,我们讨论LoRA的技术细节,构建LoRA GPT-2模型,微调它并生成文本。
什么是LoRA?
LoRA是用于大语言模型(LLMs)的高效微调技术。它冻结了LLM的权重,并注入可训练的秩分解矩阵。让我们更清楚地理解这一点。
假设我们有一个n x n的预训练密集层(或权重矩阵),W0。我们初始化两个密集层,A和B,形状分别为n x rank和rank x n。rank远小于n。在论文中,1到4之间的值被证明效果很好。
LoRA方程
原始方程是output = W0x + b0,其中x是输入,W0和b0是原始密集层的权重矩阵和偏置项(已冻结)。
LoRA方程是:output = W0x + b0 + BAx,其中A和B是秩分解矩阵。
LoRA的基础在于预训练语言模型的权重更新具有低“内在秩”,因为预训练语言模型是过度参数化的。通过将W0的更新限制为低秩分解矩阵,能够重现完全微调的预测性能。

可训练参数数量
让我们做一些快速的数学。假设n是768,而rank是4。W0有768 x 768 = 589,824个参数,而LoRA层A和B加在一起有768 x 4 + 4 x 768 = 6,144个参数。因此,对于密集层,我们从589,824个可训练参数减少到6,144个可训练参数!
为什么LoRA减少内存占用?
即使参数总数增加(因为我们添加了LoRA层),内存占用减少,因为可训练参数的数量减少。让我们深入探讨这一点。
模型的内存使用可以分为四个部分:
- 模型内存:这是存储模型权重所需的内存。对于LoRA而言,这将略高于GPT-2。
- 前向传播内存:这主要取决于批量大小、序列长度等。为了公平比较,我们保持两个模型的这一点不变。
- 反向传播内存:这是存储梯度所需的内存。请注意,梯度仅为可训练参数计算。
- 优化器内存:这是存储优化器状态所需的内存。例如,Adam优化器为可训练参数存储“第一动量向量”和“第二动量向量”。
由于LoRA在可训练参数数量上有巨大下降,因此LoRA的优化器内存和存储梯度所需的内存远少于GPT-2。这是大多数内存节省发生的地方。
为什么LoRA如此受欢迎?
- 减少GPU内存使用;
- 更快的训练;和
- 无额外推理延迟。
创建LoRA层
根据上述技术描述,让我们创建一个LoRA层。在变换器模型中,LoRA层被创建并注入到查询和值投影矩阵中。在keras.layers.MultiHeadAttention中,查询/值投影层是keras.layers.EinsumDense层。
import math
class LoraLayer(keras.layers.Layer): def init( self, original_layer, rank=8, alpha=32, trainable=False, **kwargs, ): # 我们希望保持这个层的名称与原始 # 密集层相同。 original_layer_config = original_layer.get_config() name = original_layer_config["name"]
kwargs.pop("name", None)
super().__init__(name=name, trainable=trainable, **kwargs)
self.rank = rank
self.alpha = alpha
self._scale = alpha / rank
self._num_heads = original_layer_config["output_shape"][-2]
self._hidden_dim = self._num_heads * original_layer_config["output_shape"][-1]
# 层。
# 原始密集层。
self.original_layer = original_layer
# 无论我们是在训练模型还是在推理模式下,
# 这个层都应该被冻结。
self.original_layer.trainable = False
# LoRA 密集层。
self.A = keras.layers.Dense(
units=rank,
use_bias=False,
# 注意:原始论文提到使用
# 正态分布进行初始化。然而,官方的 LoRA 实现
# 使用“凯明/何初始化”。
kernel_initializer=keras.initializers.VarianceScaling(
scale=math.sqrt(5), mode="fan_in", distribution="uniform"
),
trainable=trainable,
name=f"lora_A",
)
# B 与原始层具有相同的 `equation` 和 `output_shape`。
# `equation = abc,cde->abde`,其中 `a`:批大小,`b`:序列
# 长度,`c`:`hidden_dim`,`d`:`num_heads`,
# `e`:`hidden_dim//num_heads`。唯一的区别在于在层 `B` 中,
# `c` 代表 `rank`。
self.B = keras.layers.EinsumDense(
equation=original_layer_config["equation"],
output_shape=original_layer_config["output_shape"],
kernel_initializer="zeros",
trainable=trainable,
name=f"lora_B",
)
def call(self, inputs):
original_output = self.original_layer(inputs)
if self.trainable:
# 如果我们正在微调模型,我们将把 LoRA 层的输出
# 添加到原始层的输出中。
lora_output = self.B(self.A(inputs)) * self._scale
return original_output + lora_output
# 如果我们处于推理模式,我们将“合并” LoRA 层的权重到
# 原始层的权重中 - 更多内容将在文本生成
# 部分中讨论!
return original_output
### 注入 LoRA 层到模型中
我们现在将黑客攻击原始的 GPT-2 模型,并将 LoRA 层注入其中。让我们先做几件事:
- 删除之前的模型;
- 使用 [`tf.config.experimental.reset_memory_stats`](https://www.tensorflow.org/api_docs/python/tf/config/experimental/reset_memory_stats) 重置“峰值” GPU 内存使用;
- 加载一个新的 GPT-2 模型。
```python
del gpt2_lm
del optimizer
del loss
# 这将“重置”内存的“峰值”使用为“当前”内存使用。
tf.config.experimental.reset_memory_stats("GPU:0")
# 加载原始模型。
preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=128,
)
lora_model = keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=preprocessor,
)
我们现在将用新的 LoRA 层覆盖原始的查询/值投影矩阵。
for layer_idx in range(lora_model.backbone.num_layers):
# 更改查询密集层。
decoder_layer = lora_model.backbone.get_layer(f"transformer_layer_{layer_idx}")
self_attention_layer = decoder_layer._self_attention_layer
# 允许对 Keras 层状态进行更改。
self_attention_layer._tracker.locked = False
# 更改查询密集层。
self_attention_layer._query_dense = LoraLayer(
self_attention_layer._query_dense,
rank=RANK,
alpha=ALPHA,
trainable=True,
)
# 更改值密集层。
self_attention_layer._value_dense = LoraLayer(
self_attention_layer._value_dense,
rank=RANK,
alpha=ALPHA,
trainable=True,
)
现在让我们进行前向传播,以确保我们仍然有一个有效的计算链。
lora_model(preprocessor(["LoRA is very useful for quick LLM finetuning"])[0])
pass
冻结整个 LLM,只有 LoRA 层应该是可训练的。
for layer in lora_model._flatten_layers():
lst_of_sublayers = list(layer._flatten_layers())
if len(lst_of_sublayers) == 1: # "leaves of the model"
if layer.name in ["lora_A", "lora_B"]:
layer.trainable = True
else:
layer.trainable = False
打印模型的摘要,并检查不可训练参数和
总参数的数量是否正确。
在前面的部分,我们计算了与LoRA层相关的参数数量为6,144。模型中的可训练参数总数应为 num_layers * (query, value) * 6,144 = 12 * 2 * 6,144 = 147,456。不可训练参数的数量应与原始GPT-2模型中的参数总数相同,即 124,439,808。
lora_model.summary() # 输出模型摘要
预处理器: "gpt2_causal_lm_preprocessor_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 词元器(类型) ┃ 词汇数 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ gpt2_tokenizer_1 (GPT2Tokenizer) │ 50,257 │ └────────────────────────────────────────────────────┴─────────────────────────────────────────────────────┘
模型: "gpt2_causal_lm_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层(类型) ┃ 输出形状 ┃ 参数数量 ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask (输入层) │ (无, 无) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_ids (输入层) │ (无, 无) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ gpt2_backbone_1 │ (无, 无, 768) │ 124,587,264 │ padding_mask[0][0], │ │ (GPT2主干) │ │ │ token_ids[0][0] │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_embedding │ (无, 无, 50257) │ 38,597,376 │ gpt2_backbone_1[0][0] │ │ (可逆嵌入) │ │ │ │ └───────────────────────────────┴───────────────────────────┴─────────────┴────────────────────────────────┘
总参数: 124,587,264 (475.26 MB)
可训练参数: 147,456 (576.00 KB)
不可训练参数: 124,439,808 (474.70 MB)
微调 LoRA GPT-2
现在我们已经破解并验证了 LoRA GPT-2 模型,让我们来训练它!
gpu_memory_callback = GPUMemoryCallback(
target_batches=[5, 10, 25, 50, 100, 150, 200, 300, 400, 500],
print_stats=True,
)
optimizer, loss = get_optimizer_and_loss()
lora_model.compile(
optimizer=optimizer,
loss=loss,
weighted_metrics=["accuracy"],
)
lora_model.fit(
train_ds,
epochs=EPOCHS,
callbacks=[gpu_memory_callback],
)
lora_model_memory_usage = gpu_memory_callback.memory_usage
2/500 ━━━━━━━━━━━━━━━━━━━━ 41s 84ms/step - accuracy: 0.2828 - loss: 3.7188
W0000 00:00:1701128576.353742 38699 graph_launch.cc:671] 因为 memset 节点破坏了图更新,回退到逐操作模式
500/500 ━━━━━━━━━━━━━━━━━━━━ 80s 81ms/step - accuracy: 0.2930 - loss: 3.6158
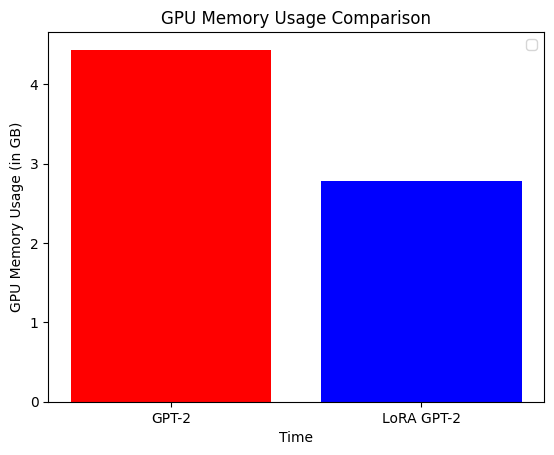
我们已经完成了模型的微调!在生成文本之前,让我们比较这两个模型的训练时间和内存使用情况。GPT-2 在 16 GB Tesla T4(Colab)上的训练时间为 7 分钟,而 LoRA 的训练时间为 5 分钟,减少了 30%。LoRA GPT-2 的内存使用大约比 GPT-2 减少了 35%。
plt.bar(
["GPT-2", "LoRA GPT-2"],
[max(gpt2_lm_memory_usage), max(lora_model_memory_usage)],
color=["red", "blue"],
)
plt.xlabel("时间")
plt.ylabel("GPU 内存使用 (GB)")
plt.title("GPU 内存使用比较")
plt.legend()
plt.show()
WARNING:matplotlib.legend:没有找到带标签的艺术家放入图例。 请注意,以下划线开头的标签的艺术家在调用 legend() 时会被忽略。
合并权重并生成文本!
LoRA 相较于其他适配器方法的最大优势之一是它不会带来额外的推理延迟。让我们理解一下原因。
回忆我们的 LoRA 方程:output = W0x + b0 + BAx。我们可以将其重写为:
output = = Wx + b0 = (W0 + BA)x + b0,其中 W = W0 + BA。这意味着如果我们合并原始模型和适配器的权重,我们将基本上做与原始模型相同的计算!
for layer_idx in range(lora_model.backbone.num_layers):
self_attention_layer = lora_model.backbone.get_layer(
f"transformer_layer_{layer_idx}"
)._self_attention_layer
# 合并查询密集层。
query_lora_layer = self_attention_layer._query_dense
A_weights = query_lora_layer.A.kernel # (768, 1) (a, b)
B_weights = query_lora_layer.B.kernel # (1, 12, 64) (b, c, d)
increment_weights = tf.einsum("ab,bcd->acd", A_weights, B_weights) * (ALPHA / RANK)
query_lora_layer.original_layer.kernel.assign_add(increment_weights)
# 合并值密集层。
value_lora_layer = self_attention_layer._value_dense
A_weights = value_lora_layer.A.kernel # (768, 1) (a, b)
B_weights = value_lora_layer.B.kernel # (1, 12, 64) (b, c, d)
increment_weights = tf.einsum("ab,bcd->acd", A_weights, B_weights) * (ALPHA / RANK)
value_lora_layer.original_layer.kernel.assign_add(increment_weights)
# 用更新的权重放回原层
self_attention_layer._query_dense = query_lora_layer.original_layer
self_attention_layer._value_dense = value_lora_layer.original_layer
我们现在已经准备好使用我们的 LoRA 模型生成文本 :)
# 在生成时不需要冻结权重,因为没有权重被更新。
generate_text(lora_model, "我喜欢篮球", max_length=MAX_GENERATION_LENGTH)
generate_text(
lora_model, "那家意大利餐厅是", max_length=MAX_GENERATION_LENGTH
)
输出:
我喜欢篮球。 我玩这个游戏已经差不多一个星期了,我感到很累。 今天,我正和我的朋友一起打,他是一位非常好的球员。 我比平均球员年长一点,但我又有点年轻。
总耗时:6.81秒
输出:
那家意大利餐厅位于市中心,坐落在一条最近为夏天翻新的街道上。
我和一群朋友在一起,度过了愉快的时光。
总耗时: 0.32秒
大家都完成了!