使用前向-前向算法进行图像分类
作者: Suvaditya Mukherjee
创建日期: 2023/01/08
最后修改: 2023/01/08
描述: 使用前向-前向算法训练一个稠密层模型。

介绍
下面的示例探索了如何使用前向-前向算法进行训练,而不是传统的反向传播方法,正如Hinton在 前向-前向算法:一些初步调查 (2022)中提出的。
这个概念受到玻尔兹曼机背后的理解启发。反向传播 涉及通过成本函数计算实际输出和预测输出之间的差异,以调整网络权重。另一方面,FF算法建议 一种神经元的类比,这些神经元根据查看某种已识别的图像及其正确对应标签的组合而“兴奋”。
此方法从皮层中的生物学习过程中获得了一定的灵感。这种方法带来的一个显著优势是,不再需要通过网络进行反向传播,权重更新局限于层本身。
由于这仍然是一种实验方法,它并不能产生先进的结果。 但通过适当的调优,它应该接近相同的结果。 通过这个示例,我们将检查一个过程,该过程允许我们在层内部实现前向-前向算法,而不是传统依赖于全局损失函数和优化器的方法。
本教程的结构如下:
- 执行必要的导入
- 加载MNIST数据集
- 可视化MNIST数据集中的随机样本
- 定义一个
FFDense层,以覆盖call并实现一个自定义的forwardforward方法来执行权重更新。 - 定义一个
FFNetwork层,以覆盖train_step、predict并实现两个自定义函数用于每个样本的预测和叠加标签 - 将MNIST从
NumPy数组转换为tf.data.Dataset - 拟合网络
- 可视化结果
- 对测试样本进行推断
由于这个示例需要定制某些核心功能与keras.layers.Layer和keras.models.Model,请参考以下资源以获取如何执行此操作的入门:
设置导入
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
import random
from tensorflow.compiler.tf2xla.python import xla
加载数据集并可视化数据
我们使用keras.datasets.mnist.load_data()工具直接以NumPy数组的形式拉取MNIST数据集。
然后,我们将其安排为训练集和测试集的形式。
在加载数据集后,我们从训练集中选择4个随机样本,并使用matplotlib.pyplot对它们进行可视化。
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print("4个随机训练样本及其标签")
idx1, idx2, idx3, idx4 = random.sample(range(0, x_train.shape[0]), 4)
img1 = (x_train[idx1], y_train[idx1])
img2 = (x_train[idx2], y_train[idx2])
img3 = (x_train[idx3], y_train[idx3])
img4 = (x_train[idx4], y_train[idx4])
imgs = [img1, img2, img3, img4]
plt.figure(figsize=(10, 10))
for idx, item in enumerate(imgs):
image, label = item[0], item[1]
plt.subplot(2, 2, idx + 1)
plt.imshow(image, cmap="gray")
plt.title(f"标签 : {label}")
plt.show()
正在从 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 下载数据
11490434/11490434 [==============================] - 0s 0us/step
4个随机训练样本及其标签
定义FFDense自定义层
在这个自定义层中,我们有一个基础的keras.layers.Dense对象,作为内部的基础Dense层。由于权重更新将在层内部发生,我们添加了一个从用户接受的keras.optimizers.Optimizer对象。这里,我们
use Adam作为我们的优化器,学习率设置为0.03,相对较高。
根据算法的具体要求,我们必须设置一个threshold参数,这将在每次预测中用于做出正负决定。该参数的默认值设置为2.0。
由于轮次是局部化到层本身的,我们还设置了一个num_epochs参数(默认为50)。
我们重写call方法,以便对完整的输入空间进行归一化,然后将其经过基础的Dense层,这与在正常的Dense层调用中发生的情况相同。
我们实现了前向-前向算法,它接受2种输入张量,分别代表正样本和负样本。我们在这里编写了一个自定义训练循环,使用tf.GradientTape(),在其中我们通过计算预测与阈值的距离来理解错误,并取其均值以获得mean_loss指标。
借助tf.GradientTape(),我们计算可训练的基础Dense层的梯度更新,并使用该层的局部优化器应用它们。
最后,我们返回call结果作为正样本和负样本的Dense结果,同时返回最后的mean_loss指标和在某个所有轮次的运行中的所有损失值。
class FFDense(keras.layers.Layer):
"""
一个自定义的启用ForwardForward的Dense层。它内部实现了
Forward-Forward网络供使用。
此层必须与`FFNetwork`模型结合使用。
"""
def __init__(
self,
units,
optimizer,
loss_metric,
num_epochs=50,
use_bias=True,
kernel_initializer="glorot_uniform",
bias_initializer="zeros",
kernel_regularizer=None,
bias_regularizer=None,
**kwargs,
):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=units,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
)
self.relu = keras.layers.ReLU()
self.optimizer = optimizer
self.loss_metric = loss_metric
self.threshold = 1.5
self.num_epochs = num_epochs
# 我们在将输入传递通过Dense层之前执行归一化步骤。
def call(self, x):
x_norm = tf.norm(x, ord=2, axis=1, keepdims=True)
x_norm = x_norm + 1e-4
x_dir = x / x_norm
res = self.dense(x_dir)
return self.relu(res)
# 前向-前向算法如下。我们首先执行Dense层
# 操作,然后分别为所有正样本和负样本获取均方值。
# 自定义损失函数找到均方
# 结果与我们设置的阈值之间的距离(超参数),这将定义
# 预测是正向还是负向。一旦计算了损失,我们在整个批次中求出均值,然后进行
# 梯度计算和优化步骤。这在技术上并不
# 符合反向传播,因为没有梯度
# 被传递到任何先前的层,完全是局部的。
def forward_forward(self, x_pos, x_neg):
for i in range(self.num_epochs):
with tf.GradientTape() as tape:
g_pos = tf.math.reduce_mean(tf.math.pow(self.call(x_pos), 2), 1)
g_neg = tf.math.reduce_mean(tf.math.pow(self.call(x_neg), 2), 1)
loss = tf.math.log(
1
+ tf.math.exp(
tf.concat([-g_pos + self.threshold, g_neg - self.threshold], 0)
)
)
mean_loss = tf.cast(tf.math.reduce_mean(loss), tf.float32)
self.loss_metric.update_state([mean_loss])
gradients = tape.gradient(mean_loss, self.dense.trainable_weights)
self.optimizer.apply_gradients(zip(gradients, self.dense.trainable_weights))
return (
tf.stop_gradient(self.call(x_pos)),
tf.stop_gradient(self.call(x_neg)),
self.loss_metric.result(),
)
定义FFNetwork自定义模型
在定义了自定义层之后,我们还需要重写train_step方法,并定义一个与我们的FFDense层配合工作的自定义keras.models.Model。
对于该算法,我们必须将标签“嵌入”到原始图像中。为此,我们利用MNIST图像的结构,其中左上角的10个像素始终为零。我们将其作为标签空间,以便在图像中可视化地对标签进行独热编码。此操作由overlay_y_on_x函数执行。
我们将预测函数分解为一个每个样本的预测函数,然后通过重写的 predict() 函数在整个测试集上调用该函数。此处的预测是通过测量每个图像在每层的神经元的 excitation 来执行的。然后将所有层的值相加,以计算网络的“好分数”。具有最高“好分数”的标签将被选为样本预测。
重写的 train_step 函数作为主要控制循环,用于按照每层的轮次数运行每层的训练。
class FFNetwork(keras.Model):
"""
一个支持创建 `FFDense` 网络的 [`keras.Model`](/api/models/model#model-class)。该模型可以用于任何类型的分类任务。它有一个内部实现,包含一些与 MNIST 数据集特定的细节,可以根据使用案例进行更改。
"""
# 由于每个层在本地运行梯度计算和优化,每个层都有自己的优化器,我们将其传递。作为标准选择,我们传递具有默认学习率 0.03 的 `Adam` 优化器,因为经过实验发现这是最佳速率。
# 使用 `loss_var` 和 `loss_count` 变量跟踪损失。
# 使用遗留优化器作为层优化器以修复问题
# https://github.com/keras-team/keras-io/issues/1241
def __init__(
self,
dims,
layer_optimizer=keras.optimizers.legacy.Adam(learning_rate=0.03),
**kwargs,
):
super().__init__(**kwargs)
self.layer_optimizer = layer_optimizer
self.loss_var = tf.Variable(0.0, trainable=False, dtype=tf.float32)
self.loss_count = tf.Variable(0.0, trainable=False, dtype=tf.float32)
self.layer_list = [keras.Input(shape=(dims[0],))]
for d in range(len(dims) - 1):
self.layer_list += [
FFDense(
dims[d + 1],
optimizer=self.layer_optimizer,
loss_metric=keras.metrics.Mean(),
)
]
# 该函数对图像进行动态更改,标签被放置在原始图像的顶部(对于此示例,由于 MNIST 有 10 个唯一标签,我们获取左上角的前 10 个像素)。该函数返回原始数据张量,前 10 个像素是标签的基于像素的独热表示。
@tf.function(reduce_retracing=True)
def overlay_y_on_x(self, data):
X_sample, y_sample = data
max_sample = tf.reduce_max(X_sample, axis=0, keepdims=True)
max_sample = tf.cast(max_sample, dtype=tf.float64)
X_zeros = tf.zeros([10], dtype=tf.float64)
X_update = xla.dynamic_update_slice(X_zeros, max_sample, [y_sample])
X_sample = xla.dynamic_update_slice(X_sample, X_update, [0])
return X_sample, y_sample
# 自定义 `predict_one_sample` 通过将图像传递通过网络来执行预测,测量每层产生的结果(即输出值相对于每个标签的设定阈值有多高/多低),然后简单地找到具有最高值的标签。
# 在这种情况下,图像会针对所有标签进行“良好性”测试。
@tf.function(reduce_retracing=True)
def predict_one_sample(self, x):
goodness_per_label = []
x = tf.reshape(x, [tf.shape(x)[0] * tf.shape(x)[1]])
for label in range(10):
h, label = self.overlay_y_on_x(data=(x, label))
h = tf.reshape(h, [-1, tf.shape(h)[0]])
goodness = []
for layer_idx in range(1, len(self.layer_list)):
layer = self.layer_list[layer_idx]
h = layer(h)
goodness += [tf.math.reduce_mean(tf.math.pow(h, 2), 1)]
goodness_per_label += [
tf.expand_dims(tf.reduce_sum(goodness, keepdims=True), 1)
]
goodness_per_label = tf.concat(goodness_per_label, 1)
return tf.cast(tf.argmax(goodness_per_label, 1), tf.float64)
def predict(self, data):
x = data
preds = list()
preds = tf.map_fn(fn=self.predict_one_sample, elems=x)
return np.asarray(preds, dtype=int)
# 这个自定义的 `train_step` 函数重写了内部的 `train_step` 实现。我们获取所有输入图像张量,将它们展平,然后随后在图像上生成正样本和负样本。
# 正样本是一个具有正确标签编码的图像,并使用 `overlay_y_on_x` 函数生成。负样本是一个包含错误标签的图像。
# 准备好样本后,我们将其传递通过每个 `FFLayer` 并对其执行前向-前向计算。返回的损失是所有层的最终损失值。
@tf.function(jit_compile=True)
def train_step(self, data):
x, y = data
# 展平操作
x = tf.reshape(x, [-1, tf.shape(x)[1] * tf.shape(x)[2]])
x_pos, y = tf.map_fn(fn=self.overlay_y_on_x, elems=(x, y))
random_y = tf.random.shuffle(y)
x_neg, y = tf.map_fn(fn=self.overlay_y_on_x, elems=(x, random_y))
h_pos, h_neg = x_pos, x_neg
for idx, layer in enumerate(self.layers):
if isinstance(layer, FFDense):
print(f"正在训练第 {idx+1} 层 : ")
h_pos, h_neg, loss = layer.forward_forward(h_pos, h_neg)
self.loss_var.assign_add(loss)
self.loss_count.assign_add(1.0)
else:
print(f"现在传递第 {idx+1} 层 : ")
x = layer(x)
mean_res = tf.math.divide(self.loss_var, self.loss_count)
return {"FinalLoss": mean_res}
将MNIST NumPy 数组转换为 tf.data.Dataset
我们现在对 NumPy 数组进行一些初步处理,然后将它们转换为
tf.data.Dataset 格式,以便实现优化加载。
x_train = x_train.astype(float) / 255
x_test = x_test.astype(float) / 255
y_train = y_train.astype(int)
y_test = y_test.astype(int)
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.batch(60000)
test_dataset = test_dataset.batch(10000)
拟合网络并可视化结果
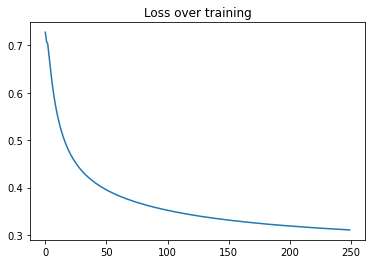
在完成所有先前的设置后,我们现在将运行 model.fit(),并运行250
个模型周期,这将对每一层进行50*250次周期。我们可以看到每一层训练时的损失曲线图。
model = FFNetwork(dims=[784, 500, 500])
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.03),
loss="mse",
jit_compile=True,
metrics=[keras.metrics.Mean()],
)
epochs = 250
history = model.fit(train_dataset, epochs=epochs)
Epoch 1/250
Training layer 1 now :
Training layer 2 now :
Training layer 1 now :
Training layer 2 now :
1/1 [==============================] - 72s 72s/step - FinalLoss: 0.7279
Epoch 2/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.7082
Epoch 3/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.7031
Epoch 4/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.6806
Epoch 5/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.6564
Epoch 6/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.6333
Epoch 7/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.6126
Epoch 8/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5946
Epoch 9/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5786
Epoch 10/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5644
Epoch 11/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5518
Epoch 12/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5405
Epoch 13/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5301
Epoch 14/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5207
Epoch 15/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.5122
Epoch 16/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.5044
Epoch 17/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4972
Epoch 18/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4906
Epoch 19/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4845
Epoch 20/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4787
Epoch 21/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4734
Epoch 22/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4685
Epoch 23/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4639
Epoch 24/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4596
Epoch 25/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4555
Epoch 26/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4516
Epoch 27/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4479
Epoch 28/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4445
Epoch 29/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4411
Epoch 30/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4380
Epoch 31/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4350
Epoch 32/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4322
Epoch 33/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4295
Epoch 34/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4269
Epoch 35/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4245
Epoch 36/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4222
Epoch 37/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4199
Epoch 38/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4178
Epoch 39/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4157
Epoch 40/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4136
Epoch 41/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4117
Epoch 42/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4098
Epoch 43/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4079
Epoch 44/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4062
Epoch 45/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4045
Epoch 46/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4028
Epoch 47/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.4012
Epoch 48/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3996
Epoch 49/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3982
Epoch 50/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3967
Epoch 51/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3952
Epoch 52/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3938
Epoch 53/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3925
Epoch 54/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3912
Epoch 55/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3899
Epoch 56/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3886
Epoch 57/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3874
Epoch 58/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3862
Epoch 59/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3851
Epoch 60/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3840
Epoch 61/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3829
Epoch 62/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3818
Epoch 63/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3807
Epoch 64/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3797
Epoch 65/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3787
Epoch 66/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3777
Epoch 67/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3767
Epoch 68/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3758
Epoch 69/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3748
Epoch 70/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3739
Epoch 71/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3730
Epoch 72/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3721
Epoch 73/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3712
Epoch 74/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3704
Epoch 75/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3695
Epoch 76/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3688
Epoch 77/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3680
Epoch 78/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3671
Epoch 79/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3664
Epoch 80/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3656
Epoch 81/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3648
Epoch 82/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3641
Epoch 83/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3634
Epoch 84/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3627
Epoch 85/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3620
Epoch 86/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3613
Epoch 87/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3606
Epoch 88/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3599
Epoch 89/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3593
Epoch 90/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3586
Epoch 91/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3580
Epoch 92/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3574
Epoch 93/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3568
Epoch 94/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3561
Epoch 95/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3555
Epoch 96/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3549
Epoch 97/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3544
Epoch 98/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3538
Epoch 99/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3532
Epoch 100/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3526
Epoch 101/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3521
Epoch 102/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3515
Epoch 103/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3510
Epoch 104/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3505
Epoch 105/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3499
Epoch 106/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3494
Epoch 107/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3489
Epoch 108/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3484
Epoch 109/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3478
Epoch 110/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3474
Epoch 111/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3468
Epoch 112/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3464
Epoch 113/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3459
Epoch 114/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3454
Epoch 115/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3450
Epoch 116/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3445
Epoch 117/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3440
Epoch 118/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3436
Epoch 119/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3432
Epoch 120/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3427
Epoch 121/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3423
Epoch 122/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3419
Epoch 123/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3414
Epoch 124/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3410
Epoch 125/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3406
Epoch 126/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3402
Epoch 127/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3398
Epoch 128/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3394
Epoch 129/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3390
Epoch 130/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3386
Epoch 131/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3382
Epoch 132/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3378
Epoch 133/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3375
Epoch 134/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3371
Epoch 135/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3368
Epoch 136/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3364
Epoch 137/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3360
Epoch 138/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3357
Epoch 139/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3353
Epoch 140/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3350
Epoch 141/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3346
Epoch 142/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3343
Epoch 143/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3339
Epoch 144/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3336
Epoch 145/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3333
Epoch 146/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3329
Epoch 147/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3326
Epoch 148/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3323
Epoch 149/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3320
Epoch 150/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3317
Epoch 151/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3313
Epoch 152/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3310
Epoch 153/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3307
Epoch 154/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3304
Epoch 155/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3302
Epoch 156/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3299
Epoch 157/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3296
Epoch 158/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3293
Epoch 159/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3290
Epoch 160/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3287
Epoch 161/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3284
Epoch 162/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3281
Epoch 163/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3279
Epoch 164/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3276
Epoch 165/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3273
Epoch 166/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3270
Epoch 167/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3268
Epoch 168/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3265
Epoch 169/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3262
Epoch 170/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3260
Epoch 171/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3257
Epoch 172/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3255
Epoch 173/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3252
Epoch 174/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3250
Epoch 175/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3247
Epoch 176/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3244
Epoch 177/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3242
Epoch 178/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3240
Epoch 179/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3237
Epoch 180/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3235
Epoch 181/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3232
Epoch 182/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3230
Epoch 183/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3228
Epoch 184/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3225
Epoch 185/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3223
Epoch 186/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3221
Epoch 187/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3219
Epoch 188/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3216
Epoch 189/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3214
Epoch 190/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3212
Epoch 191/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3210
Epoch 192/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3208
Epoch 193/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3205
Epoch 194/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3203
Epoch 195/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3201
Epoch 196/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3199
Epoch 197/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3197
Epoch 198/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3195
Epoch 199/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3193
Epoch 200/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3191
Epoch 201/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3189
Epoch 202/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3187
Epoch 203/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3185
Epoch 204/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3183
Epoch 205/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3181
Epoch 206/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3179
Epoch 207/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3177
Epoch 208/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3175
Epoch 209/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3174
Epoch 210/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3172
Epoch 211/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3170
Epoch 212/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3168
Epoch 213/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3166
Epoch 214/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3165
Epoch 215/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3163
Epoch 216/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3161
Epoch 217/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3159
Epoch 218/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3157
Epoch 219/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3155
Epoch 220/250
1/1 [==============================] - 5s 5s/step - FinalLoss: 0.3154
Epoch 221/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3152
Epoch 222/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3150
Epoch 223/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3148
Epoch 224/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3147
Epoch 225/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3145
Epoch 226/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3143
Epoch 227/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3142
Epoch 228/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3140
Epoch 229/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3139
Epoch 230/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3137
Epoch 231/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3135
Epoch 232/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3134
Epoch 233/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3132
Epoch 234/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3131
Epoch 235/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3129
Epoch 236/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3127
Epoch 237/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3126
Epoch 238/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3124
Epoch 239/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3123
Epoch 240/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3121
Epoch 241/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3120
Epoch 242/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3118
Epoch 243/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3117
Epoch 244/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3116
Epoch 245/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3114
Epoch 246/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3113
Epoch 247/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3111
Epoch 248/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3110
Epoch 249/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3108
Epoch 250/250
1/1 [==============================] - 6s 6s/step - FinalLoss: 0.3107
进行推断和测试
在大程度上训练了模型后,我们现在看看它在测试集上的表现。我们计算准确率得分以更深入地了解结果。
preds = model.predict(tf.convert_to_tensor(x_test))
preds = preds.reshape((preds.shape[0], preds.shape[1]))
results = accuracy_score(preds, y_test)
print(f"测试准确率得分 : {results*100}%")
plt.plot(range(len(history.history["FinalLoss"])), history.history["FinalLoss"])
plt.title("训练过程中的损失")
plt.show()
测试准确率得分 : 97.64%
结论
本示例展示了如何使用 TensorFlow 和 Keras 包实现 Forward-Forward 算法。尽管 Hinton 教授在其论文中提出的研究结果目前仍局限于 MNIST 和 Fashion-MNIST 等较小模型和数据集,但对更大模型(如 LLM)的后续结果预计会在未来的论文中出现。
通过论文,Hinton 教授报告了一个包含 2000 个单元、4 个隐藏层的全连接网络的测试准确率误差为 1.36%,该网络运行了 60 轮(同时提到反向传播只需 20 轮即可达到类似性能)。另一种通过加倍学习率并训练 40 轮的算法的误差率略微变为 1.46%。
当前示例未能产生最先进的结果。但通过合理调整学习率、模型架构(Dense 层中的单元数量、内核激活、初始化、正则化等),结果可以得到改善,以符合论文的声明。