使用 TensorFlow Similarity 进行图像相似性搜索的度量学习
作者: Owen Vallis
创建日期: 2021/09/30
最后修改日期: 2022/02/29
描述: 在 CIFAR-10 图像上使用相似性度量学习的示例。

概述
该示例基于 "图像相似性搜索的度量学习" 示例。 我们的目标是使用相同的数据集,但使用 TensorFlow Similarity 实现模型。
度量学习旨在训练模型,将输入嵌入到高维空间中,使“相似”的输入彼此更靠近,而“不同”的输入则被推得更远。一旦模型训练完成,这些模型可以为下游系统生成嵌入,在这些系统中,此类相似性是有用的,例如作为搜索的排名信号或作为另一个监督问题的预训练嵌入模型形式。
有关度量学习的更详细概述,请参阅:
设置
本教程将使用 TensorFlow Similarity 库 来学习和评估相似性嵌入。 TensorFlow Similarity 提供了以下组件:
- 简化和加快对比模型的训练。
- 确保批次包含示例对。
- 评估嵌入质量。
TensorFlow Similarity 可以通过 pip 简单安装,如下所示:
pip -q install tensorflow_similarity
import random
from matplotlib import pyplot as plt
from mpl_toolkits import axes_grid1
import numpy as np
import tensorflow as tf
from tensorflow import keras
import tensorflow_similarity as tfsim
tfsim.utils.tf_cap_memory()
print("TensorFlow:", tf.__version__)
print("TensorFlow Similarity:", tfsim.__version__)
TensorFlow: 2.7.0
TensorFlow Similarity: 0.15.5
数据集采样器
我们将使用 CIFAR-10 数据集进行本教程。
为了让相似性模型高效地学习, 每个批次必须至少包含 2 个每个类别的示例。
为了简化这一点,tf_similarity 提供 Sampler 对象,使您能够设置每个批次的类别数量和每个类别的最小示例数量。
训练和验证数据集将使用 TFDatasetMultiShotMemorySampler 对象创建。这创建了一个从 TensorFlow Datasets 加载数据集并生成包含目标类别数量和每个类别的目标示例数量的批次的采样器。此外,我们还可以限制采样器仅生成定义在 class_list 中的类的子集,从而使我们可以在某些类的子集上进行训练,然后测试嵌入如何推广到未见的类。这在处理少量学习问题时可能非常有用。
以下单元创建一个 train_ds 采样:
- 从 TFDS 加载 CIFAR-10 数据集,然后获取
examples_per_class_per_batch。 - 确保采样器将类限制为定义在
class_list中的类。 - 确保每个批次包含 10 个不同的类别,每个类别有 8 个示例。
我们也以相同的方式创建验证数据集,但我们将每个类别的总示例数限制为 100,每个批次每个类别的示例数设置为默认值 2。
# 这决定了训练期间使用的类别数量。
# 在这里我们使用所有类别。
num_known_classes = 10
class_list = random.sample(population=range(10), k=num_known_classes)
classes_per_batch = 10
# 每个批次传递每个类别的多个示例确保每个示例都有
# 多个正对。进行三元组挖掘或
# 使用诸如`MultiSimilarityLoss`或`CircleLoss`这类损失时,这可能是有用的,因为这些可以
# 采用所有正对的加权混合。一般来说,每个
# 类别的更多示例将为正对提供更多信息,而每个批次的更多类别
# 将在负对中提供更多不同的信息。然而,
# 损失计算批次中示例之间的成对距离,因此
# 批次大小的上限受限于内存。
examples_per_class_per_batch = 8
print(
"批次大小为: "
f"{min(classes_per_batch, num_known_classes) * examples_per_class_per_batch}"
)
print(" 创建训练数据 ".center(34, "#"))
train_ds = tfsim.samplers.TFDatasetMultiShotMemorySampler(
"cifar10",
classes_per_batch=min(classes_per_batch, num_known_classes),
splits="train",
steps_per_epoch=4000,
examples_per_class_per_batch=examples_per_class_per_batch,
class_list=class_list,
)
print("\n" + " 创建验证数据 ".center(34, "#"))
val_ds = tfsim.samplers.TFDatasetMultiShotMemorySampler(
"cifar10",
classes_per_batch=classes_per_batch,
splits="test",
total_examples_per_class=100,
)
批量大小为:80
###### 创建训练数据 ######
正在转换训练数据: 0%| | 0/50000 [00:00<?, ?it/s]
初始批量大小为80(10个类 * 每个类8个示例),没有增强器
筛选示例: 0%| | 0/50000 [00:00<?, ?it/s]
选择类别: 0%| | 0/10 [00:00<?, ?it/s]
收集示例: 0%| | 0/50000 [00:00<?, ?it/s]
索引类别: 0%| | 0/50000 [00:00<?, ?it/s]
##### 创建验证数据 #####
正在转换测试数据: 0%| | 0/10000 [00:00<?, ?it/s]
初始批量大小为20(10个类 * 每个类2个示例),没有增强器
筛选示例: 0%| | 0/10000 [00:00<?, ?it/s]
选择类别: 0%| | 0/10 [00:00<?, ?it/s]
收集示例: 0%| | 0/1000 [00:00<?, ?it/s]
索引类别: 0%| | 0/1000 [00:00<?, ?it/s]
可视化数据集
采样器将打乱数据集,因此我们可以通过 绘制前25张图像来了解数据集。
采样器提供了一个 get_slice(begin, size) 方法,使我们能够轻松选择一块样本。
另外,我们可以使用 generate_batch() 方法来生成一批样本。这样我们可以检查一批是否包含预期数量的类别和每个类别的示例。
num_cols = num_rows = 5
# 获取前25个示例。
x_slice, y_slice = train_ds.get_slice(begin=0, size=num_cols * num_rows)
fig = plt.figure(figsize=(6.0, 6.0))
grid = axes_grid1.ImageGrid(fig, 111, nrows_ncols=(num_cols, num_rows), axes_pad=0.1)
for ax, im, label in zip(grid, x_slice, y_slice):
ax.imshow(im)
ax.axis("off")

嵌入模型
接下来,我们使用Keras功能API定义一个 SimilarityModel。该模型
是一个标准的卷积网络,增加了一个 MetricEmbedding 层以应用L2归一化。度量嵌入层在使用
Cosine 距离时很有用,因为我们只关心向量之间的角度。
此外,SimilarityModel 提供了一些辅助方法来:
- 索引嵌入示例
- 执行示例查找
- 评估分类
- 评估嵌入空间的质量
有关更多详细信息,请参阅 TensorFlow Similarity 文档。
embedding_size = 256
inputs = keras.layers.Input((32, 32, 3))
x = keras.layers.Rescaling(scale=1.0 / 255)(inputs)
x = keras.layers.Conv2D(64, 3, activation="relu")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(128, 3, activation="relu")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.MaxPool2D((4, 4))(x)
x = keras.layers.Conv2D(256, 3, activation="relu")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(256, 3, activation="relu")(x)
x = keras.layers.GlobalMaxPool2D()(x)
outputs = tfsim.layers.MetricEmbedding(embedding_size)(x)
# 构建模型
model = tfsim.models.SimilarityModel(inputs, outputs)
model.summary()
模型: "similarity_model"
_________________________________________________________________
层 (类型) 输出形状 参数 #
=================================================================
输入层 (InputLayer) [(None, 32, 32, 3)] 0
归一化 (Rescaling) (None, 32, 32, 3) 0
卷积层 (Conv2D) (None, 30, 30, 64) 1792
批量归一化 (BatchNormaliza (None, 30, 30, 64) 256
tion)
卷积层_1 (Conv2D) (None, 28, 28, 128) 73856
批量归一化_1 (BatchNormal (None, 28, 28, 128) 512
ization)
最大池化层 (MaxPooling2D) (None, 7, 7, 128) 0
卷积层_2 (Conv2D) (None, 5, 5, 256) 295168
批量归一化_2 (BatchNormal (None, 5, 5, 256) 1024
ization)
卷积层_3 (Conv2D) (None, 3, 3, 256) 590080
全局最大池化层 (GlobalMaxP (None, 256) 0
ooling2D)
度量嵌入 (MetricEmbedding) (None, 256) 65792
=================================================================
总参数: 1,028,480
可训练参数: 1,027,584
不可训练参数: 896
_________________________________________________________________
相似度损失
相似度损失期望每个批次包含至少2个类别的示例,从中计算成对正负距离的损失。在这里我们使用 MultiSimilarityLoss()
(论文),这是
TensorFlow Similarity中的几个损失之一。该损失
尝试在批次中使用所有信息丰富的对,考虑自相似性、正相似性和负相似性。
epochs = 3
learning_rate = 0.002
val_steps = 50
# 初始化相似度损失
loss = tfsim.losses.MultiSimilarityLoss()
# 编译和训练
model.compile(
optimizer=keras.optimizers.Adam(learning_rate), loss=loss, steps_per_execution=10,
)
history = model.fit(
train_ds, epochs=epochs, validation_data=val_ds, validation_steps=val_steps
)
距离度量自动设置为余弦,用距离参数覆盖。
第 1/3 轮
4000/4000 [==============================] - ETA: 0s - loss: 2.2179预热完成
4000/4000 [==============================] - 38s 9ms/step - loss: 2.2179 - val_loss: 0.8894
预热完成
第 2/3 轮
4000/4000 [==============================] - 34s 9ms/step - loss: 1.9047 - val_loss: 0.8767
第 3/3 轮
4000/4000 [==============================] - 35s 9ms/step - loss: 1.6336 - val_loss: 0.8469
索引
现在我们已经训练了模型,可以创建示例的索引。在这里我们通过传递 x 和 y 来批量索引前 200 个验证示例,同时将图像存储在数据参数中。x_index 的值被嵌入并添加到索引中以使其可搜索。y_index 和数据参数是可选的,但允许用户将元数据与嵌入的示例关联。
x_index, y_index = val_ds.get_slice(begin=0, size=200)
model.reset_index()
model.index(x_index, y_index, data=x_index)
[索引 200 个点]
|-计算嵌入
|-在键值存储中存储数据点
|-将嵌入添加到索引中。
|-构建索引。
0% 10 20 30 40 50 60 70 80 90 100%
|----|----|----|----|----|----|----|----|----|----|
***************************************************
标定
建立索引后,我们可以使用匹配策略和标定指标来标定距离阈值。
在这里,我们正在寻找最佳的 F1 得分,同时将 K=1 作为我们的分类器。所有在或低于标定阈值距离的匹配将被标记为查询示例和匹配结果相关联标签之间的正匹配,而所有高于阈值距离的匹配将被标记为负匹配。
此外,我们还传入额外的指标进行计算。输出中的所有值均在标定阈值下计算。
最后,model.calibrate() 返回一个 CalibrationResults 对象,其中包含:
"cutpoints":一个 Python 字典,将切点名称映射到包含与特定距离阈值相关的ClassificationMetric值的字典,例如,"optimal" : {"acc": 0.90, "f1": 0.92}。"thresholds":一个 Python 字典,将ClassificationMetric名称映射到包含在每个距离阈值下计算的指标值的列表,例如,{"f1": [0.99, 0.80], "distance": [0.0, 1.0]}。
x_train, y_train = train_ds.get_slice(begin=0, size=1000)
calibration = model.calibrate(
x_train,
y_train,
calibration_metric="f1",
matcher="match_nearest",
extra_metrics=["precision", "recall", "binary_accuracy"],
verbose=1,
)
执行 NN 搜索
构建 NN 列表: 0%| | 0/1000 [00:00<?, ?it/s]
评估: 0%| | 0/4 [00:00<?, ?it/s]
计算阈值: 0%| | 0/989 [00:00<?, ?it/s]
name value distance precision recall binary_accuracy f1
------- ------- ---------- ----------- -------- ----------------- --------
optimal 0.93 0.048435 0.869 1 0.869 0.929909
可视化
仅从指标中获取模型质量可能是困难的。一个补充的方法是手动检查一组查询结果,以了解匹配的质量。
在这里,我们取 10 个验证示例,并绘制它们及其 5 个最近邻和到查询示例的距离。查看结果,我们看到尽管它们并不完美,但仍然代表了有意义的相似图像,并且模型能够找到相似的图像,无论其姿势或图像光照如何。
我们还可以看到,模型对某些图像非常有信心,导致 在查询和邻居之间的距离非常小的时候,错误较少。相反,随着距离的增大,我们看到类标签的错误增多。这也是校准对匹配应用至关重要的原因之一。
num_neighbors = 5
labels = [
"飞机",
"汽车",
"鸟",
"猫",
"鹿",
"狗",
"青蛙",
"马",
"船",
"卡车",
"未知",
]
class_mapping = {c_id: c_lbl for c_id, c_lbl in zip(range(11), labels)}
x_display, y_display = val_ds.get_slice(begin=200, size=10)
# 在索引中查找最近的邻居
nns = model.lookup(x_display, k=num_neighbors)
# 显示
for idx in np.argsort(y_display):
tfsim.visualization.viz_neigbors_imgs(
x_display[idx],
y_display[idx],
nns[idx],
class_mapping=class_mapping,
fig_size=(16, 2),
)
执行NN搜索
构建NN列表: 0%| | 0/10 [00:00<?, ?it/s]










指标
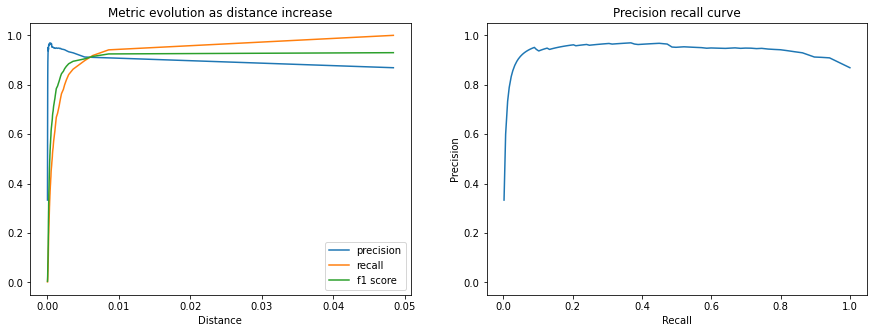
我们还可以绘制CalibrationResults中包含的额外指标,以了解随着距离阈值增加,匹配性能的变化。
以下图表显示了精确度、召回率和F1分数。我们可以看到,随着距离的增加匹配精度下降,但我们接受为正匹配的查询百分比(召回率)增长得更快,直到校准的距离阈值。
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
x = calibration.thresholds["distance"]
ax1.plot(x, calibration.thresholds["precision"], label="精确度")
ax1.plot(x, calibration.thresholds["recall"], label="召回率")
ax1.plot(x, calibration.thresholds["f1"], label="F1分数")
ax1.legend()
ax1.set_title("距离增加时指标的演变")
ax1.set_xlabel("距离")
ax1.set_ylim((-0.05, 1.05))
ax2.plot(calibration.thresholds["recall"], calibration.thresholds["precision"])
ax2.set_title("精确度-召回率曲线")
ax2.set_xlabel("召回率")
ax2.set_ylabel("精确度")
ax2.set_ylim((-0.05, 1.05))
plt.show()
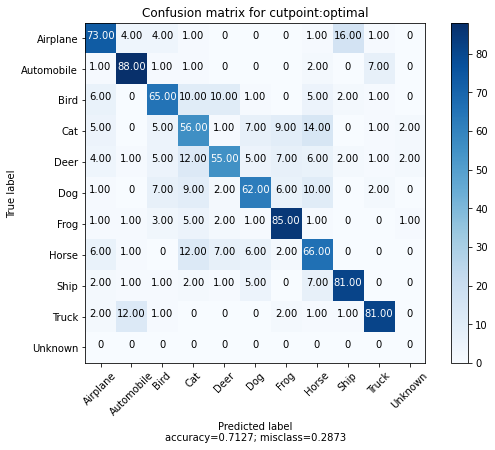
我们还可以为每个类别选取100个示例,并绘制每个示例及其最近匹配的混淆矩阵。我们还添加了一个“额外的”第10类别,以表示超过校准距离阈值的匹配。
我们可以看到,大多数错误发生在动物类之间,飞机和鸟之间存在有趣的混淆。此外,我们看到每个类别的100个示例中,只有少数返回了校准距离阈值之外的匹配。
cutpoint = "optimal"
# 这为每个类别提供100个示例。
# 我们在创建val_ds采样器时定义了这个。
x_confusion, y_confusion = val_ds.get_slice(0, -1)
matches = model.match(x_confusion, cutpoint=cutpoint, no_match_label=10)
cm = tfsim.visualization.confusion_matrix(
matches,
y_confusion,
labels=labels,
title="切点:%s的混淆矩阵" % cutpoint,
normalize=False,
)
无匹配
我们可以绘制在校准阈值之外的示例,以查看哪些图像没有与任何索引示例匹配。
这可能提供对其他需要索引的示例或在类别内显示异常示例的见解。
idx_no_match = np.where(np.array(matches) == 10)
no_match_queries = x_confusion[idx_no_match]
if len(no_match_queries):
plt.imshow(no_match_queries[0])
else:
print("所有查询在距离阈值以下都有匹配。")

可视化聚类
快速了解模型表现质量和理解其不足之处的最好方法之一是将嵌入投影到2D空间。
这使我们能够检查图像的聚类,并理解哪些类别是交织在一起的。
# val_ds 中每个类别被限制为 100 个示例。
num_examples_to_clusters = 1000
thumb_size = 96
plot_size = 800
vx, vy = val_ds.get_slice(0, num_examples_to_clusters)
# 取消注释以运行交互式投影仪。
# tfsim.visualization.projector(
# model.predict(vx),
# labels=vy,
# images=vx,
# class_mapping=class_mapping,
# image_size=thumb_size,
# plot_size=plot_size,
# )