Few-Shot 学习与 Reptile
作者: ADMoreau
创建日期: 2020/05/21
最后修改: 2023/07/20
描述: 使用 Reptile 在 Omniglot 数据集上进行少样本分类。

介绍
Reptile 算法是由 OpenAI 开发的, 用于执行与模型无关的元学习。具体来说,该算法旨在 通过最小的训练快速学习执行新任务(少样本学习)。 该算法通过使用在以前未见过的数据的小批量上训练的权重与 在固定数量的元迭代前的模型权重之间的差异,执行随机梯度下降。
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import random
import tensorflow as tf
import tensorflow_datasets as tfds
定义超参数
learning_rate = 0.003
meta_step_size = 0.25
inner_batch_size = 25
eval_batch_size = 25
meta_iters = 2000
eval_iters = 5
inner_iters = 4
eval_interval = 1
train_shots = 20
shots = 5
classes = 5
准备数据
Omniglot 数据集 是一个包含 1,623
个字符的集合,来自 50 种不同的字母表,每个字符有 20 个示例。
每个字符的 20 个样本是通过亚马逊的 Mechanical Turk 在线抽取的。
对于少样本学习任务,k 个样本(或“shot”)是从 n 个随机选择的
类别中随机抽取的。这些 n 个数值用于创建一组新的临时标签,用于
测试模型在给定少量示例情况下学习新任务的能力。换句话说,如果你
在 5 个类别上进行训练,你的新类别标签将是 0、1、2、3 或 4。
Omniglot 是非常适合这个任务的数据集,因为有许多不同的类别可供抽取,
每个类别有合理数量的样本。
class Dataset:
# 这个类将便于从Omniglot数据集中创建一个少样本数据集
# 可以快速抽样,同时也允许同时创建新标签。
def __init__(self, training):
# 下载包含omniglot数据的tfrecord文件并转换为
# 数据集。
split = "train" if training else "test"
ds = tfds.load("omniglot", split=split, as_supervised=True, shuffle_files=False)
# 遍历数据集以获取每个单独的图像及其类别,
# 并将数据放入字典中。
self.data = {}
def extraction(image, label):
# 此函数将缩小Omniglot图像到所需大小,
# 缩放像素值并将RGB图像转换为灰度图像
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.rgb_to_grayscale(image)
image = tf.image.resize(image, [28, 28])
return image, label
for image, label in ds.map(extraction):
image = image.numpy()
label = str(label.numpy())
if label not in self.data:
self.data[label] = []
self.data[label].append(image)
self.labels = list(self.data.keys())
def get_mini_dataset(
self, batch_size, repetitions, shots, num_classes, split=False
):
temp_labels = np.zeros(shape=(num_classes * shots))
temp_images = np.zeros(shape=(num_classes * shots, 28, 28, 1))
if split:
test_labels = np.zeros(shape=(num_classes))
test_images = np.zeros(shape=(num_classes, 28, 28, 1))
# 从整个标签集中获取一随机子集的标签。
label_subset = random.choices(self.labels, k=num_classes)
for class_idx, class_obj in enumerate(label_subset):
# 使用枚举索引值作为少样本学习中
# 小批量的临时标签。
temp_labels[class_idx * shots : (class_idx + 1) * shots] = class_idx
# 如果创建用于测试的拆分数据集,从每个标签选择一个额外样本
# 以创建测试数据集。
if split:
test_labels[class_idx] = class_idx
images_to_split = random.choices(
self.data[label_subset[class_idx]], k=shots + 1
)
test_images[class_idx] = images_to_split[-1]
temp_images[
class_idx * shots : (class_idx + 1) * shots
] = images_to_split[:-1]
else:
# 对于随机选择的label_subset中的每个索引,抽样
# 必要数量的图像。
temp_images[
class_idx * shots : (class_idx + 1) * shots
] = random.choices(self.data[label_subset[class_idx]], k=shots)
dataset = tf.data.Dataset.from_tensor_slices(
(temp_images.astype(np.float32), temp_labels.astype(np.int32))
)
dataset = dataset.shuffle(100).batch(batch_size).repeat(repetitions)
if split:
return dataset, test_images, test_labels
return dataset
import urllib3
urllib3.disable_warnings() # 禁用在下载过程中可能发生的SSL警告。
train_dataset = Dataset(training=True)
test_dataset = Dataset(training=False)
下载和准备数据集 17.95 MiB (下载: 17.95 MiB, 生成: 未知大小, 总计: 17.95 MiB) 到 /home/fchollet/tensorflow_datasets/omniglot/3.0.0...
Dl 完成...: 0 url [00:00, ? url/s]
Dl 大小...: 0 MiB [00:00, ? MiB/s]
提取完成...: 0 文件 [00:00, ? file/s]
生成拆分...: 0%| | 0/4 [00:00<?, ? splits/s]
生成训练示例...: 0%| | 0/19280 [00:00<?, ? examples/s]
洗牌 /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-train.tfrecord*...: 0%…
生成测试示例...: 0%| | 0/13180 [00:00<?, ? examples/s]
洗牌 /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-test.tfrecord*...: 0%|…
生成小示例1...: 0%| | 0/2720 [00:00<?, ? examples/s]
洗牌 /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-small1.tfrecord*...: 0…
生成小示例2...: 0%| | 0/3120 [00:00<?, ? examples/s]
洗牌 /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-small2.tfrecord*...: 0…
数据集 omniglot 已下载并准备好在 /home/fchollet/tensorflow_datasets/omniglot/3.0.0。后续调用将重用此数据。
可视化数据集中的一些示例
_, axarr = plt.subplots(nrows=5, ncols=5, figsize=(20, 20))
sample_keys = list(train_dataset.data.keys())
for a in range(5):
for b in range(5):
temp_image = train_dataset.data[sample_keys[a]][b]
temp_image = np.stack((temp_image[:, :, 0],) * 3, axis=2)
temp_image *= 255
temp_image = np.clip(temp_image, 0, 255).astype("uint8")
if b == 2:
axarr[a, b].set_title("类别 : " + sample_keys[a])
axarr[a, b].imshow(temp_image, cmap="gray")
axarr[a, b].xaxis.set_visible(False)
axarr[a, b].yaxis.set_visible(False)
plt.show()

构建模型
def conv_bn(x):
x = layers.Conv2D(filters=64, kernel_size=3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
return layers.ReLU()(x)
inputs = layers.Input(shape=(28, 28, 1))
x = conv_bn(inputs)
x = conv_bn(x)
x = conv_bn(x)
x = conv_bn(x)
x = layers.Flatten()(x)
outputs = layers.Dense(classes, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile()
optimizer = keras.optimizers.SGD(learning_rate=learning_rate)
训练模型
training = []
testing = []
for meta_iter in range(meta_iters):
frac_done = meta_iter / meta_iters
cur_meta_step_size = (1 - frac_done) * meta_step_size
# 暂时保存模型的权重。
old_vars = model.get_weights()
# 从完整数据集中获取一个样本。
mini_dataset = train_dataset.get_mini_dataset(
inner_batch_size, inner_iters, train_shots, classes
)
for images, labels in mini_dataset:
with tf.GradientTape() as tape:
preds = model(images)
loss = keras.losses.sparse_categorical_crossentropy(labels, preds)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
new_vars = model.get_weights()
# 对元步骤执行SGD。
for var in range(len(new_vars)):
new_vars[var] = old_vars[var] + (
(new_vars[var] - old_vars[var]) * cur_meta_step_size
)
# 在元学习步骤后,将新训练的权重重新加载到模型中。
model.set_weights(new_vars)
# 评估循环
if meta_iter % eval_interval == 0:
accuracies = []
for dataset in (train_dataset, test_dataset):
# 从完整数据集中抽取一个小数据集。
train_set, test_images, test_labels = dataset.get_mini_dataset(
eval_batch_size, eval_iters, shots, classes, split=True
)
old_vars = model.get_weights()
# 在样本上训练并获取结果准确率。
for images, labels in train_set:
with tf.GradientTape() as tape:
preds = model(images)
loss = keras.losses.sparse_categorical_crossentropy(labels, preds)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
test_preds = model.predict(test_images)
test_preds = tf.argmax(test_preds).numpy()
num_correct = (test_preds == test_labels).sum()
# 获取评估准确率后重置权重。
model.set_weights(old_vars)
accuracies.append(num_correct / classes)
training.append(accuracies[0])
testing.append(accuracies[1])
if meta_iter % 100 == 0:
print(
"batch %d: train=%f test=%f" % (meta_iter, accuracies[0], accuracies[1])
)
batch 0: train=0.600000 test=0.200000
batch 100: train=0.800000 test=0.200000
batch 200: train=1.000000 test=1.000000
batch 300: train=1.000000 test=0.800000
batch 400: train=1.000000 test=0.600000
batch 500: train=1.000000 test=1.000000
batch 600: train=1.000000 test=0.600000
batch 700: train=1.000000 test=1.000000
batch 800: train=1.000000 test=0.800000
batch 900: train=0.800000 test=0.600000
batch 1000: train=1.000000 test=0.600000
batch 1100: train=1.000000 test=1.000000
batch 1200: train=1.000000 test=1.000000
batch 1300: train=0.600000 test=1.000000
batch 1400: train=1.000000 test=0.600000
batch 1500: train=1.000000 test=1.000000
batch 1600: train=0.800000 test=1.000000
batch 1700: train=0.800000 test=1.000000
batch 1800: train=0.800000 test=1.000000
batch 1900: train=1.000000 test=1.000000
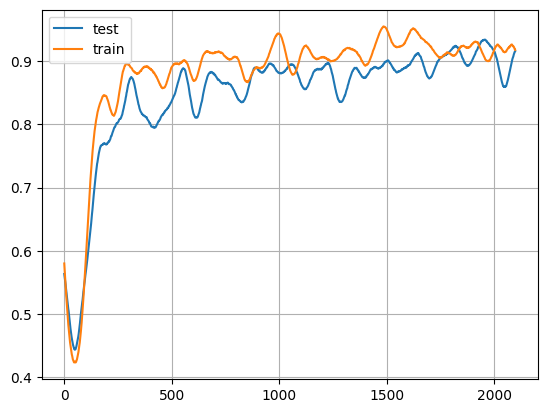
可视化结果
# 首先,对训练和测试数组进行一些预处理,以便于展示。
window_length = 100
train_s = np.r_[
training[window_length - 1 : 0 : -1],
training,
training[-1:-window_length:-1],
]
test_s = np.r_[
testing[window_length - 1 : 0 : -1], testing, testing[-1:-window_length:-1]
]
w = np.hamming(window_length)
train_y = np.convolve(w / w.sum(), train_s, mode="valid")
test_y = np.convolve(w / w.sum(), test_s, mode="valid")
# 显示训练准确性。
x = np.arange(0, len(test_y), 1)
plt.plot(x, test_y, x, train_y)
plt.legend(["test", "train"])
plt.grid()
train_set, test_images, test_labels = dataset.get_mini_dataset(
eval_batch_size, eval_iters, shots, classes, split=True
)
for images, labels in train_set:
with tf.GradientTape() as tape:
preds = model(images)
loss = keras.losses.sparse_categorical_crossentropy(labels, preds)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
test_preds = model.predict(test_images)
test_preds = tf.argmax(test_preds).numpy()
_, axarr = plt.subplots(nrows=1, ncols=5, figsize=(20, 20))
sample_keys = list(train_dataset.data.keys())
for i, ax in zip(range(5), axarr):
temp_image = np.stack((test_images[i, :, :, 0],) * 3, axis=2)
temp_image *= 255
temp_image = np.clip(temp_image, 0, 255).astype("uint8")
ax.set_title(
"标签 : {}, 预测 : {}".format(int(test_labels[i]), test_preds[i])
)
ax.imshow(temp_image, cmap="gray")
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
plt.show()