语义图像聚类
作者: Khalid Salama
创建日期: 2021/02/28
最后修改日期: 2021/02/28
描述: 通过采用最近邻居(SCAN)算法进行语义聚类。

介绍
该示例演示了如何对CIFAR-10数据集应用通过采用最近邻居进行语义聚类(SCAN)算法 (Van Gansbeke et al., 2020)。该算法由两个阶段组成:
- 对图像进行自监督视觉表示学习,其中我们使用simCLR技术。
- 对学习到的视觉表示向量进行聚类,以最大化相邻向量的聚类分配之间的一致性。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
from collections import defaultdict
import numpy as np
import tensorflow as tf
import keras
from keras import layers
import matplotlib.pyplot as plt
from tqdm import tqdm
准备数据
num_classes = 10
input_shape = (32, 32, 3)
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_data = np.concatenate([x_train, x_test])
y_data = np.concatenate([y_train, y_test])
print("x_data shape:", x_data.shape, "- y_data shape:", y_data.shape)
classes = [
"飞机",
"汽车",
"鸟",
"猫",
"鹿",
"狗",
"青蛙",
"马",
"船",
"卡车",
]
x_data shape: (60000, 32, 32, 3) - y_data shape: (60000, 1)
定义超参数
target_size = 32 # 调整输入图像大小。
representation_dim = 512 # 特征向量的维度。
projection_units = 128 # 表示学习者的投影头。
num_clusters = 20 # 聚类数量。
k_neighbours = 5 # 在聚类学习过程中考虑的邻居数量。
tune_encoder_during_clustering = False # 在聚类学习中冻结编码器。
实现数据预处理
数据预处理步骤将输入图像的大小调整为所需的target_size并应用特征归一化。请注意,当使用keras.applications.ResNet50V2作为视觉编码器时,将图像调整为255 x 255的输入将导致更准确的结果,但需要更长的训练时间。
data_preprocessing = keras.Sequential(
[
layers.Resizing(target_size, target_size),
layers.Normalization(),
]
)
# 计算数据的均值和方差用于归一化。
data_preprocessing.layers[-1].adapt(x_data)
数据增强
与simCLR不同,后者随机选择一个数据增强函数应用于输入图像,我们随机将一组数据增强函数应用于输入图像。 (您可以通过遵循data augmentation tutorial来尝试其他图像增强技术。)
data_augmentation = keras.Sequential(
[
layers.RandomTranslation(
height_factor=(-0.2, 0.2), width_factor=(-0.2, 0.2), fill_mode="nearest"
),
layers.RandomFlip(mode="horizontal"),
layers.RandomRotation(factor=0.15, fill_mode="nearest"),
layers.RandomZoom(
height_factor=(-0.3, 0.1), width_factor=(-0.3, 0.1), fill_mode="nearest"
),
]
)
显示随机图像
image_idx = np.random.choice(range(x_data.shape[0]))
image = x_data[image_idx]
image_class = classes[y_data[image_idx][0]]
plt.figure(figsize=(3, 3))
plt.imshow(x_data[image_idx].astype("uint8"))
plt.title(image_class)
_ = plt.axis("off")

显示图像的增强版本样本
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_images = data_augmentation(np.array([image]))
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

自监督表示学习
实现视觉编码器
def create_encoder(representation_dim):
encoder = keras.Sequential(
[
keras.applications.ResNet50V2(
include_top=False, weights=None, pooling="avg"
),
layers.Dense(representation_dim), # 密集层
]
)
return encoder
实现无监督对比损失
class RepresentationLearner(keras.Model):
def __init__(
self,
encoder,
projection_units,
num_augmentations,
temperature=1.0,
dropout_rate=0.1,
l2_normalize=False,
**kwargs
):
super().__init__(**kwargs)
self.encoder = encoder
# 创建投影头。
self.projector = keras.Sequential(
[
layers.Dropout(dropout_rate),
layers.Dense(units=projection_units, use_bias=False),
layers.BatchNormalization(),
layers.ReLU(),
]
)
self.num_augmentations = num_augmentations
self.temperature = temperature
self.l2_normalize = l2_normalize
self.loss_tracker = keras.metrics.Mean(name="loss")
@property
def metrics(self):
return [self.loss_tracker]
def compute_contrastive_loss(self, feature_vectors, batch_size):
num_augmentations = keras.ops.shape(feature_vectors)[0] // batch_size
if self.l2_normalize:
feature_vectors = keras.utils.normalize(feature_vectors)
# logits 的形状是 [num_augmentations * batch_size, num_augmentations * batch_size]。
logits = (
tf.linalg.matmul(feature_vectors, feature_vectors, transpose_b=True)
/ self.temperature
)
# 应用 log-max 技巧以提高数值稳定性。
logits_max = keras.ops.max(logits, axis=1)
logits = logits - logits_max
# targets 的形状是 [num_augmentations * batch_size, num_augmentations * batch_size]。
# targets 是一个由 num_augmentations 个子矩阵组成的矩阵,形状为 [batch_size * batch_size]。
# 每个 [batch_size * batch_size] 的子矩阵是一个单位矩阵(对角线元素为 1)。
targets = keras.ops.tile(
tf.eye(batch_size), [num_augmentations, num_augmentations]
)
# 计算交叉熵损失
return keras.losses.categorical_crossentropy(
y_true=targets, y_pred=logits, from_logits=True
)
def call(self, inputs):
# 预处理输入图像。
preprocessed = data_preprocessing(inputs)
# 创建图像的增强版本。
augmented = []
for _ in range(self.num_augmentations):
augmented.append(data_augmentation(preprocessed))
augmented = layers.Concatenate(axis=0)(augmented)
# 生成图像的嵌入表示。
features = self.encoder(augmented)
# 应用投影头。
return self.projector(features)
def train_step(self, inputs):
batch_size = keras.ops.shape(inputs)[0]
# 运行前向传播并计算对比损失
with tf.GradientTape() as tape:
feature_vectors = self(inputs, training=True)
loss = self.compute_contrastive_loss(feature_vectors, batch_size)
# 计算梯度
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# 更新权重
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# 更新损失跟踪指标
self.loss_tracker.update_state(loss)
# 返回一个将指标名称映射到当前值的字典
return {m.name: m.result() for m in self.metrics}
def test_step(self, inputs):
batch_size = keras.ops.shape(inputs)[0]
feature_vectors = self(inputs, training=False)
loss = self.compute_contrastive_loss(feature_vectors, batch_size)
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
训练模型
# 创建视觉编码器。
encoder = create_encoder(representation_dim)
# 创建表示学习器。
representation_learner = RepresentationLearner(
encoder, projection_units, num_augmentations=2, temperature=0.1
)
# 创建余弦衰减学习率调度器。
lr_scheduler = keras.optimizers.schedules.CosineDecay(
initial_learning_rate=0.001, decay_steps=500, alpha=0.1
)
# 编译模型。
representation_learner.compile(
optimizer=keras.optimizers.AdamW(learning_rate=lr_scheduler, weight_decay=0.0001),
jit_compile=False,
)
# 拟合模型。
history = representation_learner.fit(
x=x_data,
batch_size=512,
epochs=50, # 为了获得更好的结果,请将训练轮数增加到 500。
)
第 1 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 78s 187ms/步 - 损失: 557.1537
第 2 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 473.7576
第 3 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 204.2021
第 4 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 199.6705
第 5 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 199.4409
第 6 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 201.0644
第 7 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 199.7465
第 8 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 209.4148
第 9 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 200.9096
第 10 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 203.5660
第 11 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 197.5067
第 12 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 185.4315
第 13 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 196.7072
第 14 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 205.7930
第 15 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 196.2166
第 16 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 172.0755
第 17 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 153.7445
第 18 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 177.7372
第 19 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 161ms/步 - 损失: 149.0251
第 20 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 128.1759
第 21 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 122.5469
第 22 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 139.9140
第 23 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 135.2490
第 24 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 117.5860
第 25 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 117.3953
第 26 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 121.0800
第 27 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 108.4165
第 28 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 97.3604
第 29 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 88.7970
第 30 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 79.8381
第 31 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 69.1802
第 32 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 21s 159ms/步 - 损失: 66.0070
第 33 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 62.4077
第 34 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 55.4975
第 35 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 160ms/步 - 损失: 51.2528
第 36 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 45.4217
第 37 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 39.3580
第 38 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 36.4156
第 39 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 33.9250
第 40 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 30.2516
第 41 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 159ms/步 - 损失: 25.0412
第 42 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 25.4968
第 43 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 22.3305
第 44 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 20.6767
第 45 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 157ms/步 - 损失: 20.2187
第 46 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 18s 156ms/步 - 损失: 18.0097
第 47 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 18s 156ms/步 - 损失: 17.4783
第 48 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 19s 158ms/步 - 损失: 16.6550
第 49 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 18s 156ms/步 - 损失: 16.0668
第 50 轮/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 18s 156ms/步 - 损失: 15.2431
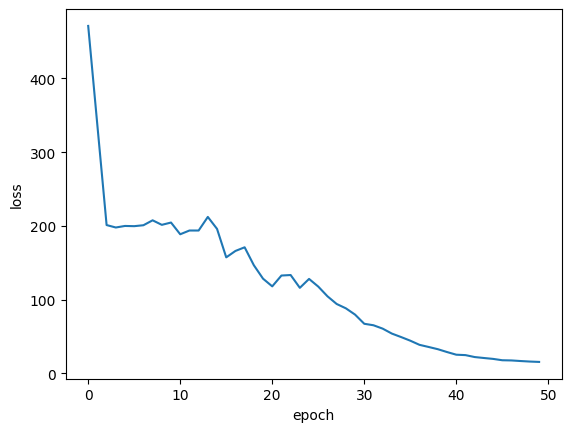
绘制训练损失
plt.plot(history.history["loss"])
plt.ylabel("损失")
plt.xlabel("轮次")
plt.show()
计算最近邻
为图像生成嵌入
batch_size = 500
# 获取图像的特征向量表示。
feature_vectors = encoder.predict(x_data, batch_size=batch_size, verbose=1)
# 归一化特征向量。
feature_vectors = keras.utils.normalize(feature_vectors)
19/120 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1699918624.555770 94228 device_compiler.h:187] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
120/120 ━━━━━━━━━━━━━━━━━━━━ 8s 9ms/step
为每个嵌入查找 k 个最近邻
neighbours = []
num_batches = feature_vectors.shape[0] // batch_size
for batch_idx in tqdm(range(num_batches)):
start_idx = batch_idx * batch_size
end_idx = start_idx + batch_size
current_batch = feature_vectors[start_idx:end_idx]
# 计算点积相似性。
similarities = tf.linalg.matmul(current_batch, feature_vectors, transpose_b=True)
# 获取最相似向量的索引。
_, indices = keras.ops.top_k(similarities, k=k_neighbours + 1, sorted=True)
# 将索引添加到邻居中。
neighbours.append(indices[..., 1:])
neighbours = np.reshape(np.array(neighbours), (-1, k_neighbours))
100%|████████████████████████████████████████████████████████████████████████| 120/120 [00:17<00:00, 6.99it/s]
让我们在每一行显示一些邻居
nrows = 4
ncols = k_neighbours + 1
plt.figure(figsize=(12, 12))
position = 1
for _ in range(nrows):
anchor_idx = np.random.choice(range(x_data.shape[0]))
neighbour_indicies = neighbours[anchor_idx]
indices = [anchor_idx] + neighbour_indicies.tolist()
for j in range(ncols):
plt.subplot(nrows, ncols, position)
plt.imshow(x_data[indices[j]].astype("uint8"))
plt.title(classes[y_data[indices[j]][0]])
plt.axis("off")
position += 1

你会注意到每一行上的图像在视觉上相似,并且属于相似的类别。
使用最近邻进行语义聚类
实现聚类一致性损失
该损失尝试确保邻居具有相同的聚类分配。
class ClustersConsistencyLoss(keras.losses.Loss):
def __init__(self):
super().__init__()
def __call__(self, target, similarity, sample_weight=None):
# 将目标设置为1。
target = keras.ops.ones_like(similarity)
# 计算交叉熵损失。
loss = keras.losses.binary_crossentropy(
y_true=target, y_pred=similarity, from_logits=True
)
return keras.ops.mean(loss)
实现聚类熵损失
该损失试图确保聚类分布大致均匀,以避免 将大多数实例分配给一个聚类。
class ClustersEntropyLoss(keras.losses.Loss):
def __init__(self, entropy_loss_weight=1.0):
super().__init__()
self.entropy_loss_weight = entropy_loss_weight
def __call__(self, target, cluster_probabilities, sample_weight=None):
# 理想熵 = log(聚类数量)。
num_clusters = keras.ops.cast(
keras.ops.shape(cluster_probabilities)[-1], "float32"
)
target = keras.ops.log(num_clusters)
# 计算总体聚类分布。
cluster_probabilities = keras.ops.mean(cluster_probabilities, axis=0)
# 将零概率(如果有的话)替换为一个很小的值。
cluster_probabilities = keras.ops.clip(cluster_probabilities, 1e-8, 1.0)
# 计算聚类的熵。
entropy = -keras.ops.sum(
cluster_probabilities * keras.ops.log(cluster_probabilities)
)
# 计算目标和实际之间的差异。
loss = target - entropy
return loss
实现聚类模型
该模型将原始图像作为输入,使用训练好的编码器生成其特征向量,并生成给定特征向量的聚类概率分布作为聚类分配。
def create_clustering_model(encoder, num_clusters, name=None):
inputs = keras.Input(shape=input_shape)
# 预处理输入图像。
preprocessed = data_preprocessing(inputs)
# 对图像应用数据增强。
augmented = data_augmentation(preprocessed)
# 生成图像的嵌入表示。
features = encoder(augmented)
# 将图像分配给集群。
outputs = layers.Dense(units=num_clusters, activation="softmax")(features)
# 创建模型。
model = keras.Model(inputs=inputs, outputs=outputs, name=name)
return model
实现聚类学习器
该模型接收输入的 anchor 图像及其 neighbours,利用 clustering_model 产生它们的聚类分配,并生成两个输出:
1. similarity:anchor 图像与其 neighbours 的聚类分配之间的相似性。该输出输入到 ClustersConsistencyLoss 中。
2. anchor_clustering:anchor 图像的聚类分配。该输出输入到 ClustersEntropyLoss 中。
def create_clustering_learner(clustering_model):
anchor = keras.Input(shape=input_shape, name="anchors")
neighbours = keras.Input(
shape=tuple([k_neighbours]) + input_shape, name="neighbours"
)
# 更改 neighbours 的形状为 [batch_size * k_neighbours, width, height, channels]
neighbours_reshaped = keras.ops.reshape(neighbours, tuple([-1]) + input_shape)
# anchor_clustering 形状: [batch_size, num_clusters]
anchor_clustering = clustering_model(anchor)
# neighbours_clustering 形状: [batch_size * k_neighbours, num_clusters]
neighbours_clustering = clustering_model(neighbours_reshaped)
# 将 neighbours_clustering 形状转换为 [batch_size, k_neighbours, num_clusters]
neighbours_clustering = keras.ops.reshape(
neighbours_clustering,
(-1, k_neighbours, keras.ops.shape(neighbours_clustering)[-1]),
)
# similarity 形状: [batch_size, 1, k_neighbours]
similarity = keras.ops.einsum(
"bij,bkj->bik",
keras.ops.expand_dims(anchor_clustering, axis=1),
neighbours_clustering,
)
# similarity 形状: [batch_size, k_neighbours]
similarity = layers.Lambda(
lambda x: keras.ops.squeeze(x, axis=1), name="similarity"
)(similarity)
# 创建模型。
model = keras.Model(
inputs=[anchor, neighbours],
outputs=[similarity, anchor_clustering],
name="clustering_learner",
)
return model
训练模型
# 如果 tune_encoder_during_clustering 设置为 False,
# 则冻结编码器权重。
for layer in encoder.layers:
layer.trainable = tune_encoder_during_clustering
# 创建聚类模型和学习器。
clustering_model = create_clustering_model(encoder, num_clusters, name="clustering")
clustering_learner = create_clustering_learner(clustering_model)
# 实例化模型损失。
losses = [ClustersConsistencyLoss(), ClustersEntropyLoss(entropy_loss_weight=5)]
# 创建模型输入和标签。
inputs = {"anchors": x_data, "neighbours": tf.gather(x_data, neighbours)}
labels = np.ones(shape=(x_data.shape[0]))
# 编译模型。
clustering_learner.compile(
optimizer=keras.optimizers.AdamW(learning_rate=0.0005, weight_decay=0.0001),
loss=losses,
jit_compile=False,
)
# 开始训练模型。
clustering_learner.fit(x=inputs, y=labels, batch_size=512, epochs=50)
Epoch 1/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 31s 109ms/step - 损失: 0.3133
Epoch 2/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 85ms/step - 损失: 0.3133
Epoch 3/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 84ms/step - 损失: 0.3133
Epoch 4/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 5/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 6/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 7/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 8/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 85ms/step - 损失: 0.3133
Epoch 9/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 84ms/step - 损失: 0.3133
Epoch 10/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 11/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 12/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 13/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 14/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 84ms/step - 损失: 0.3133
Epoch 15/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 16/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 17/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 18/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 19/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 20/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 84ms/step - 损失: 0.3133
Epoch 21/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 22/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 23/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 24/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 25/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 26/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 27/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 28/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 29/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 30/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 31/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 32/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 33/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 83ms/step - 损失: 0.3133
Epoch 34/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 35/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 36/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 37/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 38/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 39/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 84ms/step - 损失: 0.3133
Epoch 40/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 41/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 42/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 43/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 44/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 45/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 84ms/step - 损失: 0.3133
Epoch 46/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 47/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 48/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 81ms/step - 损失: 0.3133
Epoch 49/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
Epoch 50/50
118/118 ━━━━━━━━━━━━━━━━━━━━ 10s 82ms/step - 损失: 0.3133
<keras.src.callbacks.history.History at 0x7f629171c5b0>
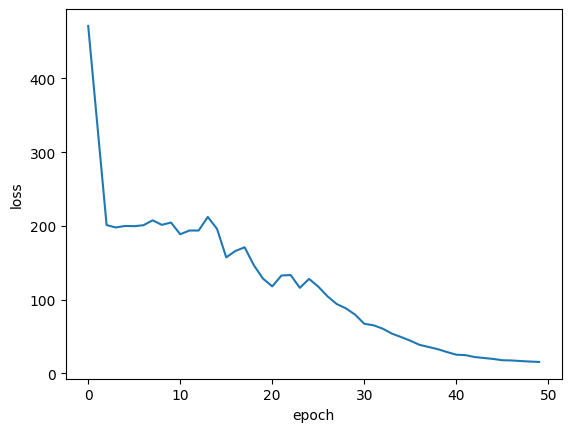
plt.plot(history.history["loss"])
plt.ylabel("损失")
plt.xlabel("轮次")
plt.show()
聚类分析
将图像分配给簇
# 获取输入图像的簇概率分布。
clustering_probs = clustering_model.predict(x_data, batch_size=batch_size, verbose=1)
# 获取概率最高的簇。
cluster_assignments = keras.ops.argmax(clustering_probs, axis=-1).numpy()
# 存储聚类置信度。
# 具有最高聚类置信度的图像被视为簇的“原型”。
cluster_confidence = keras.ops.max(clustering_probs, axis=-1).numpy()
120/120 ━━━━━━━━━━━━━━━━━━━━ 5s 13ms/step
让我们计算簇的大小
clusters = defaultdict(list)
for idx, c in enumerate(cluster_assignments):
clusters[c].append((idx, cluster_confidence[idx]))
non_empty_clusters = defaultdict(list)
for c in clusters.keys():
if clusters[c]:
non_empty_clusters[c] = clusters[c]
for c in range(num_clusters):
print("簇", c, ":", len(clusters[c]))
簇 0 : 0
簇 1 : 0
簇 2 : 0
簇 3 : 0
簇 4 : 0
簇 5 : 0
簇 6 : 0
簇 7 : 0
簇 8 : 0
簇 9 : 0
簇 10 : 0
簇 11 : 0
簇 12 : 0
簇 13 : 0
簇 14 : 0
簇 15 : 0
簇 16 : 0
簇 17 : 0
簇 18 : 60000
簇 19 : 0
可视化簇图像
显示每个簇的原型——具有最高聚类置信度的实例:
num_images = 8
plt.figure(figsize=(15, 15))
position = 1
for c in non_empty_clusters.keys():
cluster_instances = sorted(
non_empty_clusters[c], key=lambda kv: kv[1], reverse=True
)
for j in range(num_images):
image_idx = cluster_instances[j][0]
plt.subplot(len(non_empty_clusters), num_images, position)
plt.imshow(x_data[image_idx].astype("uint8"))
plt.title(classes[y_data[image_idx][0]])
plt.axis("off")
position += 1

计算聚类准确性
首先,我们根据每个簇图像的多数标签为每个簇分配标签。 然后,我们通过将具有多数标签的图像数量除以簇的大小来计算每个簇的准确性。
cluster_label_counts = dict()
for c in range(num_clusters):
cluster_label_counts[c] = [0] * num_classes
instances = clusters[c]
for i, _ in instances:
cluster_label_counts[c][y_data[i][0]] += 1
cluster_label_idx = np.argmax(cluster_label_counts[c])
correct_count = np.max(cluster_label_counts[c])
cluster_size = len(clusters[c])
accuracy = (
np.round((correct_count / cluster_size) * 100, 2) if cluster_size > 0 else 0
)
cluster_label = classes[cluster_label_idx]
print("簇", c, "标签为:", cluster_label, " - 准确率:", accuracy, "%")
簇 0 标签为: 飞机 - 准确率: 0 %
簇 1 标签为: 飞机 - 准确率: 0 %
簇 2 标签为: 飞机 - 准确率: 0 %
簇 3 标签为: 飞机 - 准确率: 0 %
簇 4 标签为: 飞机 - 准确率: 0 %
簇 5 标签为: 飞机 - 准确率: 0 %
簇 6 标签为: 飞机 - 准确率: 0 %
簇 7 标签为: 飞机 - 准确率: 0 %
簇 8 标签为: 飞机 - 准确率: 0 %
簇 9 标签为: 飞机 - 准确率: 0 %
簇 10 标签为: 飞机 - 准确率: 0 %
簇 11 标签为: 飞机 - 准确率: 0 %
簇 12 标签为: 飞机 - 准确率: 0 %
簇 13 标签为: 飞机 - 准确率: 0 %
簇 14 标签为: 飞机 - 准确率: 0 %
簇 15 标签为: 飞机 - 准确率: 0 %
簇 16 标签为: 飞机 - 准确率: 0 %
簇 17 标签为: 飞机 - 准确率: 0 %
簇 18 标签为: 飞机 - 准确率: 10.0 %
簇 19 标签为: 飞机 - 准确率: 0 %
结论
为了提高准确率结果,您可以:1) 增加表示学习和聚类阶段的轮次;2) 允许在聚类阶段调整编码器权重;3) 通过自我标记进行最终微调,如原始SCAN论文所述。 请注意,期望无监督图像聚类技术的准确性不会超过监督图像分类技术的准确性,而是表明它们可以学习图像的语义并将其分组到与其原始类别相似的簇中。