半监督图像分类使用对比预训练的SimCLR
作者: András Béres
创建日期: 2021/04/24
最后修改日期: 2024/03/04
描述: 使用SimCLR进行半监督图像分类的对比预训练,数据集为STL-10。

介绍
半监督学习
半监督学习是一种处理部分标记数据集的机器学习范式。在实际应用深度学习时,通常需要收集大量数据集才能使其表现良好。然而,标记的成本与数据集规模呈线性增长(标记每个示例需要恒定时间),而模型性能的增长仅呈sublinear。这意味着,标记越来越多的样本的成本效益越来越低,而收集未标记的数据通常是便宜的,因为它通常可以大规模地轻松获得。
半监督学习通过仅要求一个部分标记的数据集来解决这个问题,同时通过利用未标记的示例进行学习,来提高标记效率。
在这个示例中,我们将使用完全没有标记的STL-10半监督数据集预训练一个编码器,然后仅使用其标记子集进行微调。
对比学习
在最高层次上,对比学习的主要思想是以自监督的方式学习对图像增强不变的表示。这个目标的一大问题是,它有一个平凡的退化解:表示恒定,并且根本不依赖输入图像的情况。
对比学习通过以下方式修改目标以避免这种陷阱:它将增强版本/视图的表示拉近(收缩正样本),同时在表示空间中将不同的图像推开(对比负样本)。
一种这样的对比方法是SimCLR,它基本上确定了优化这个目标所需的核心组件,并能够通过扩展这种简单的方法来实现高性能。
另一种方法是SimSiam(Keras示例),其与SimCLR的主要区别在于前者在其损失中不使用任何负样本。因此,它没有明确地阻止平凡解,而是通过架构设计隐式地避免此问题(在最终层中使用预测网络和批量归一化(BatchNorm)的不对称编码路径)。
关于SimCLR的进一步阅读,请查阅官方Google AI博客文章,有关视觉和语言自监督学习的概述,请查阅这篇博客文章。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
# 确保我们能够处理大数据集
import resource
low, high = resource.getrlimit(resource.RLIMIT_NOFILE)
resource.setrlimit(resource.RLIMIT_NOFILE, (high, high))
import math
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
import keras
from keras import ops
from keras import layers
超参数设置
# 数据集超参数
unlabeled_dataset_size = 100000
labeled_dataset_size = 5000
image_channels = 3
# 算法超参数
num_epochs = 20
batch_size = 525 # 每个epoch对应200个步骤
width = 128
temperature = 0.1
# 对比学习使用更强的增强,监督训练使用较弱的增强
contrastive_augmentation = {"min_area": 0.25, "brightness": 0.6, "jitter": 0.2}
classification_augmentation = {
"min_area": 0.75,
"brightness": 0.3,
"jitter": 0.1,
}
数据集
在训练期间,我们将同时加载大量未标记图像和一小批标记图像。
def prepare_dataset():
# 同步加载带标签和不带标签的样本
# 批大小相应选择
steps_per_epoch = (unlabeled_dataset_size + labeled_dataset_size) // batch_size
unlabeled_batch_size = unlabeled_dataset_size // steps_per_epoch
labeled_batch_size = labeled_dataset_size // steps_per_epoch
print(
f"batch size is {unlabeled_batch_size} (unlabeled) + {labeled_batch_size} (labeled)"
)
# 关闭随机打乱以降低资源使用
unlabeled_train_dataset = (
tfds.load("stl10", split="unlabelled", as_supervised=True, shuffle_files=False)
.shuffle(buffer_size=10 * unlabeled_batch_size)
.batch(unlabeled_batch_size)
)
labeled_train_dataset = (
tfds.load("stl10", split="train", as_supervised=True, shuffle_files=False)
.shuffle(buffer_size=10 * labeled_batch_size)
.batch(labeled_batch_size)
)
test_dataset = (
tfds.load("stl10", split="test", as_supervised=True)
.batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# 将带标签和不带标签的数据集压缩在一起
train_dataset = tf.data.Dataset.zip(
(unlabeled_train_dataset, labeled_train_dataset)
).prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, labeled_train_dataset, test_dataset
# 加载STL10数据集
train_dataset, labeled_train_dataset, test_dataset = prepare_dataset()
批处理大小为 500(未标记) + 25(已标记)
图像增强
对比学习中最重要的两个图像增强是:
- 裁剪:迫使模型对同一图像的不同部分进行相似编码,我们通过 随机平移 和 随机缩放 层来实现
- 颜色抖动:通过扭曲颜色直方图防止对任务的平凡颜色直方图基础解决方案。实现这一点的原则性方法是在颜色空间中进行仿射变换。
在这个示例中,我们还使用随机水平翻转。对比学习应用了更强的增强,而监督分类则应用了较弱的增强,以避免在少量标记示例上的过拟合。
我们将随机颜色抖动实现为自定义预处理层。使用预处理层进行数据增强有以下两个优点:
- 数据增强将在 GPU 上以批处理方式运行,因此在 CPU 资源受限的环境(如 Colab Notebooks 或个人计算机)中,训练不会被数据管道瓶颈所阻止
- 部署更容易,因为数据预处理管道封装在模型中,而不必在部署时重新实现
# 扭曲图像的颜色分布
class RandomColorAffine(layers.Layer):
def __init__(self, brightness=0, jitter=0, **kwargs):
super().__init__(**kwargs)
self.seed_generator = keras.random.SeedGenerator(1337)
self.brightness = brightness
self.jitter = jitter
def get_config(self):
config = super().get_config()
config.update({"brightness": self.brightness, "jitter": self.jitter})
return config
def call(self, images, training=True):
if training:
batch_size = ops.shape(images)[0]
# 所有颜色相同
brightness_scales = 1 + keras.random.uniform(
(batch_size, 1, 1, 1),
minval=-self.brightness,
maxval=self.brightness,
seed=self.seed_generator,
)
# 所有颜色不同
jitter_matrices = keras.random.uniform(
(batch_size, 1, 3, 3),
minval=-self.jitter,
maxval=self.jitter,
seed=self.seed_generator,
)
color_transforms = (
ops.tile(ops.expand_dims(ops.eye(3), axis=0), (batch_size, 1, 1, 1))
* brightness_scales
+ jitter_matrices
)
images = ops.clip(ops.matmul(images, color_transforms), 0, 1)
return images
# 图像增强模块
def get_augmenter(min_area, brightness, jitter):
zoom_factor = 1.0 - math.sqrt(min_area)
return keras.Sequential(
[
layers.Rescaling(1 / 255),
layers.RandomFlip("horizontal"),
layers.RandomTranslation(zoom_factor / 2, zoom_factor / 2),
layers.RandomZoom((-zoom_factor, 0.0), (-zoom_factor, 0.0)),
RandomColorAffine(brightness, jitter),
]
)
def visualize_augmentations(num_images):
# 从数据集中抽样一批
images = next(iter(train_dataset))[0][0][:num_images]
# 应用增强
augmented_images = zip(
images,
get_augmenter(**classification_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
)
row_titles = [
"原始:",
"轻度增强:",
"强度增强:",
"强度增强:",
]
plt.figure(figsize=(num_images * 2.2, 4 * 2.2), dpi=100)
for column, image_row in enumerate(augmented_images):
for row, image in enumerate(image_row):
plt.subplot(4, num_images, row * num_images + column + 1)
plt.imshow(image)
if column == 0:
plt.title(row_titles[row], loc="left")
plt.axis("off")
plt.tight_layout()
visualize_augmentations(num_images=8)

编码器架构
# 定义编码器架构
def get_encoder():
return keras.Sequential(
[
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Flatten(),
layers.Dense(width, activation="relu"),
],
name="encoder",
)
监督基线模型
一个基线监督模型使用随机初始化进行训练。
# 基线监督训练,使用随机初始化
baseline_model = keras.Sequential(
[
get_augmenter(**classification_augmentation),
get_encoder(),
layers.Dense(10),
],
name="baseline_model",
)
baseline_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
baseline_history = baseline_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"最大验证准确率: {:.2f}%".format(
max(baseline_history.history["val_acc"]) * 100
)
)
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 9s 25ms/step - acc: 0.2031 - loss: 2.1576 - val_acc: 0.3234 - val_loss: 1.7719
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.3476 - loss: 1.7792 - val_acc: 0.4042 - val_loss: 1.5626
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4060 - loss: 1.6054 - val_acc: 0.4319 - val_loss: 1.4832
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.4347 - loss: 1.5052 - val_acc: 0.4570 - val_loss: 1.4428
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.4600 - loss: 1.4546 - val_acc: 0.4765 - val_loss: 1.3977
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4754 - loss: 1.4015 - val_acc: 0.4740 - val_loss: 1.4082
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4901 - loss: 1.3589 - val_acc: 0.4761 - val_loss: 1.4061
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5110 - loss: 1.2793 - val_acc: 0.5247 - val_loss: 1.3026
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5298 - loss: 1.2765 - val_acc: 0.5138 - val_loss: 1.3286
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5514 - loss: 1.2078 - val_acc: 0.5543 - val_loss: 1.2227
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5520 - loss: 1.1851 - val_acc: 0.5446 - val_loss: 1.2709
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5851 - loss: 1.1368 - val_acc: 0.5725 - val_loss: 1.1944
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.5738 - loss: 1.1411 - val_acc: 0.5685 - val_loss: 1.1974
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 21ms/step - acc: 0.6078 - loss: 1.0308 - val_acc: 0.5899 - val_loss: 1.1769
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.6284 - loss: 1.0386 - val_acc: 0.5863 - val_loss: 1.1742
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.6450 - loss: 0.9773 - val_acc: 0.5849 - val_loss: 1.1993
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6547 - loss: 0.9555 - val_acc: 0.5683 - val_loss: 1.2424
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6593 - loss: 0.9084 - val_acc: 0.5990 - val_loss: 1.1458
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6672 - loss: 0.9267 - val_acc: 0.5685 - val_loss: 1.2758
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6824 - loss: 0.8863 - val_acc: 0.5969 - val_loss: 1.2035
最大验证准确率: 59.90%
自监督模型用于对比预训练
我们在无标签图像上预训练编码器,使用对比损失。 在编码器的顶部附加了一个非线性投影头,以提高编码器表示的质量。
我们使用InfoNCE/NT-Xent/N-pairs损失,可以这样解释:
- 我们将批次中的每个图像视为拥有自己的类别。
- 然后,对于每个“类别”,我们有两个示例(增强视图的对)。
- 每个视图的表示与每个可能对的表示(对于两个增强版本)进行比较。
- 我们使用比较表示的温度缩放余弦相似性作为logits。
- 最后,我们使用分类交叉熵作为“分类”损失。
以下两个指标用于监控预训练性能:
- 对比准确度 (SimCLR 表5): 自监督指标,表示图像的表示与其不同增强版本的表示相比,更类似于当前批次中的任何其他图像的比例。即使在没有标签示例的情况下,自监督指标也可以用于超参数调优。
- 线性探测准确度: 线性探测是用来评估自监督分类器的常用指标。它是通过在编码器特征上训练的逻辑回归分类器的准确度来计算的。在我们的例子中,这是通过在冻结的编码器上训练一个单一的密集层来完成的。注意,与传统方法不同,在预训练阶段后进行分类器训练,在这个示例中我们 在预训练期间对其进行训练。这可能会略微降低其准确性,但通过这种方式我们可以在训练过程中监控其值,这有助于实验和调试。
另一个广泛使用的监督指标是KNN准确率,即在编码器特征上训练的KNN分类器的准确率,本文中并未实现这一点。
# 定义对比模型,使用模型子类化
class ContrastiveModel(keras.Model):
def __init__(self):
super().__init__()
self.temperature = temperature
self.contrastive_augmenter = get_augmenter(**contrastive_augmentation)
self.classification_augmenter = get_augmenter(**classification_augmentation)
self.encoder = get_encoder()
# 非线性多层感知机作为投影头
self.projection_head = keras.Sequential(
[
keras.Input(shape=(width,)),
layers.Dense(width, activation="relu"),
layers.Dense(width),
],
name="projection_head",
)
# 单层密集层用于线性探测
self.linear_probe = keras.Sequential(
[layers.Input(shape=(width,)), layers.Dense(10)],
name="linear_probe",
)
self.encoder.summary()
self.projection_head.summary()
self.linear_probe.summary()
def compile(self, contrastive_optimizer, probe_optimizer, **kwargs):
super().compile(**kwargs)
self.contrastive_optimizer = contrastive_optimizer
self.probe_optimizer = probe_optimizer
# self.contrastive_loss 将定义为一个方法
self.probe_loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.contrastive_loss_tracker = keras.metrics.Mean(name="c_loss")
self.contrastive_accuracy = keras.metrics.SparseCategoricalAccuracy(
name="c_acc"
)
self.probe_loss_tracker = keras.metrics.Mean(name="p_loss")
self.probe_accuracy = keras.metrics.SparseCategoricalAccuracy(name="p_acc")
@property
def metrics(self):
return [
self.contrastive_loss_tracker,
self.contrastive_accuracy,
self.probe_loss_tracker,
self.probe_accuracy,
]
def contrastive_loss(self, projections_1, projections_2):
# InfoNCE损失(信息噪声对比估计)
# NT-Xent损失(归一化温度缩放交叉熵)
# 余弦相似度:l2规范化特征向量的点积
projections_1 = ops.normalize(projections_1, axis=1)
projections_2 = ops.normalize(projections_2, axis=1)
similarities = (
ops.matmul(projections_1, ops.transpose(projections_2)) / self.temperature
)
# 同一图像的两个增强视图之间的表示相似度应高于与其他视图的相似度
batch_size = ops.shape(projections_1)[0]
contrastive_labels = ops.arange(batch_size)
self.contrastive_accuracy.update_state(contrastive_labels, similarities)
self.contrastive_accuracy.update_state(
contrastive_labels, ops.transpose(similarities)
)
# 温度缩放的相似度作为交叉熵的logits
# 此处使用了损失的对称版本
loss_1_2 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, similarities, from_logits=True
)
loss_2_1 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, ops.transpose(similarities), from_logits=True
)
return (loss_1_2 + loss_2_1) / 2
def train_step(self, data):
(unlabeled_images, _), (labeled_images, labels) = data
# 使用未标记和标记的图像,但没有标签
images = ops.concatenate((unlabeled_images, labeled_images), axis=0)
# 每个图像被以不同的方式增强两次
augmented_images_1 = self.contrastive_augmenter(images, training=True)
augmented_images_2 = self.contrastive_augmenter(images, training=True)
with tf.GradientTape() as tape:
features_1 = self.encoder(augmented_images_1, training=True)
features_2 = self.encoder(augmented_images_2, training=True)
# 表示通过投影mlp
projections_1 = self.projection_head(features_1, training=True)
projections_2 = self.projection_head(features_2, training=True)
contrastive_loss = self.contrastive_loss(projections_1, projections_2)
gradients = tape.gradient(
contrastive_loss,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
self.contrastive_optimizer.apply_gradients(
zip(
gradients,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
)
self.contrastive_loss_tracker.update_state(contrastive_loss)
# 仅在评估时使用标签进行动态逻辑回归
preprocessed_images = self.classification_augmenter(
labeled_images, training=True
)
with tf.GradientTape() as tape:
# 在此处以推理模式使用编码器,以避免正则化
# 并更新批量归一化参数(如果使用)
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=True)
probe_loss = self.probe_loss(labels, class_logits)
gradients = tape.gradient(probe_loss, self.linear_probe.trainable_weights)
self.probe_optimizer.apply_gradients(
zip(gradients, self.linear_probe.trainable_weights)
)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
return {m.name: m.result() for m in self.metrics}
def test_step(self, data):
labeled_images, labels = data
# 测试组件时使用 training=False 标志
preprocessed_images = self.classification_augmenter(
labeled_images, training=False
)
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=False)
probe_loss = self.probe_loss(labels, class_logits)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
# 仅在测试时记录探测指标
return {m.name: m.result() for m in self.metrics[2:]}
# 对比预训练
pretraining_model = ContrastiveModel()
pretraining_model.compile(
contrastive_optimizer=keras.optimizers.Adam(),
probe_optimizer=keras.optimizers.Adam(),
)
pretraining_history = pretraining_model.fit(
train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"最大验证准确率: {:.2f}%".format(
max(pretraining_history.history["val_p_acc"]) * 100
)
)
模型: "encoder"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ conv2d_4 (卷积层) │ ? │ 0 │ │ │ │ (未构建) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ conv2d_5 (卷积层) │ ? │ 0 │ │ │ │ (未构建) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ conv2d_6 (卷积层) │ ? │ 0 │ │ │ │ (未构建) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ conv2d_7 (卷积层) │ ? │ 0 │ │ │ │ (未构建) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ flatten_1 (展平层) │ ? │ 0 │ │ │ │ (未构建) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dense_2 (全连接层) │ ? │ 0 │ │ │ │ (未构建) │ └─────────────────────────────────┴───────────────────────────┴────────────┘
总参数: 0 (0.00 B)
可训练参数: 0 (0.00 B)
非可训练参数: 0 (0.00 B)
模型: "projection_head"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ dense_3 (全连接层) │ (无, 128) │ 16,512 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dense_4 (Dense) │ (None, 128) │ 16,512 │ └─────────────────────────────────┴───────────────────────────┴────────────┘
总参数: 33,024 (129.00 KB)
可训练参数: 33,024 (129.00 KB)
不可训练参数: 0 (0.00 B)
模型: "linear_probe"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ dense_5 (Dense) │ (None, 10) │ 1,290 │ └─────────────────────────────────┴───────────────────────────┴────────────┘
总参数: 1,290 (5.04 KB)
可训练参数: 1,290 (5.04 KB)
不可训练参数: 0 (0.00 B)
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 34s 134ms/step - c_acc: 0.0880 - c_loss: 5.2606 - p_acc: 0.1326 - p_loss: 2.2726 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.2579 - val_p_loss: 2.0671
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.2808 - c_loss: 3.6233 - p_acc: 0.2956 - p_loss: 2.0228 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3440 - val_p_loss: 1.9242
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 136ms/step - c_acc: 0.4097 - c_loss: 2.9369 - p_acc: 0.3671 - p_loss: 1.8674 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3876 - val_p_loss: 1.7757
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 30s 142ms/step - c_acc: 0.4893 - c_loss: 2.5707 - p_acc: 0.3957 - p_loss: 1.7490 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3960 - val_p_loss: 1.7002
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 136ms/step - c_acc: 0.5458 - c_loss: 2.3342 - p_acc: 0.4274 - p_loss: 1.6608 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4374 - val_p_loss: 1.6145
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.5949 - c_loss: 2.1179 - p_acc: 0.4410 - p_loss: 1.5812 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4444 - val_p_loss: 1.5439
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.6273 - c_loss: 1.9861 - p_acc: 0.4633 - p_loss: 1.5076 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4695 - val_p_loss: 1.5056
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.6566 - c_loss: 1.8668 - p_acc: 0.4817 - p_loss: 1.4601 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4790 - val_p_loss: 1.4566
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.6726 - c_loss: 1.7938 - p_acc: 0.4885 - p_loss: 1.4136 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4933 - val_p_loss: 1.4163
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.6931 - c_loss: 1.7210 - p_acc: 0.4954 - p_loss: 1.3663 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5140 - val_p_loss: 1.3677
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 137ms/step - c_acc: 0.7055 - c_loss: 1.6619 - p_acc: 0.5210 - p_loss: 1.3376 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5155 - val_p_loss: 1.3573
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 30s 145ms/step - c_acc: 0.7215 - c_loss: 1.6112 - p_acc: 0.5264 - p_loss: 1.2920 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5232 - val_p_loss: 1.3337
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 31s 146ms/step - c_acc: 0.7279 - c_loss: 1.5749 - p_acc: 0.5388 - p_loss: 1.2570 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5217 - val_p_loss: 1.3155
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7435 - c_loss: 1.5196 - p_acc: 0.5505 - p_loss: 1.2507 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5460 - val_p_loss: 1.2640
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 40s 135ms/step - c_acc: 0.7477 - c_loss: 1.4979 - p_acc: 0.5653 - p_loss: 1.2188 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5594 - val_p_loss: 1.2351
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.7598 - c_loss: 1.4463 - p_acc: 0.5590 - p_loss: 1.1917 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5551 - val_p_loss: 1.2411
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.7633 - c_loss: 1.4271 - p_acc: 0.5775 - p_loss: 1.1731 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5502 - val_p_loss: 1.2428
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7666 - c_loss: 1.4246 - p_acc: 0.5752 - p_loss: 1.1805 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5633 - val_p_loss: 1.2167
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.7708 - c_loss: 1.3928 - p_acc: 0.5814 - p_loss: 1.1677 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5665 - val_p_loss: 1.2191
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7806 - c_loss: 1.3733 - p_acc: 0.5836 - p_loss: 1.1442 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5640 - val_p_loss: 1.2172
最大验证准确率: 56.65%
微调预训练编码器
然后,我们在标记示例上微调编码器,通过在其顶部附加一个随机初始化的全连接分类层。
# 微调预训练编码器
finetuning_model = keras.Sequential(
[
get_augmenter(**classification_augmentation),
pretraining_model.encoder,
layers.Dense(10),
],
name="finetuning_model",
)
finetuning_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
finetuning_history = finetuning_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"最大验证准确率: {:.2f}%".format(
max(finetuning_history.history["val_acc"]) * 100
)
)
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 5s 18ms/step - acc: 0.2104 - loss: 2.0930 - val_acc: 0.4017 - val_loss: 1.5433
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4037 - loss: 1.5791 - val_acc: 0.4544 - val_loss: 1.4250
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4639 - loss: 1.4161 - val_acc: 0.5266 - val_loss: 1.2958
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5438 - loss: 1.2686 - val_acc: 0.5655 - val_loss: 1.1711
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5678 - loss: 1.1746 - val_acc: 0.5775 - val_loss: 1.1670
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6096 - loss: 1.1071 - val_acc: 0.6034 - val_loss: 1.1400
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6242 - loss: 1.0413 - val_acc: 0.6235 - val_loss: 1.0756
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6284 - loss: 1.0264 - val_acc: 0.6030 - val_loss: 1.1048
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6491 - loss: 0.9706 - val_acc: 0.5770 - val_loss: 1.2818
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6754 - loss: 0.9104 - val_acc: 0.6119 - val_loss: 1.1087
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 20ms/step - acc: 0.6620 - loss: 0.8855 - val_acc: 0.6323 - val_loss: 1.0526
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 19ms/step - acc: 0.7060 - loss: 0.8179 - val_acc: 0.6406 - val_loss: 1.0565
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 3s 17ms/step - acc: 0.7252 - loss: 0.7796 - val_acc: 0.6135 - val_loss: 1.1273
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7176 - loss: 0.7935 - val_acc: 0.6292 - val_loss: 1.1028
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7322 - loss: 0.7471 - val_acc: 0.6266 - val_loss: 1.1313
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7400 - loss: 0.7218 - val_acc: 0.6332 - val_loss: 1.1064
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7490 - loss: 0.6968 - val_acc: 0.6532 - val_loss: 1.0112
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7491 - loss: 0.6879 - val_acc: 0.6403 - val_loss: 1.1083
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7802 - loss: 0.6504 - val_acc: 0.6479 - val_loss: 1.0548
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 3s 17ms/step - acc: 0.7800 - loss: 0.6234 - val_acc: 0.6409 - val_loss: 1.0998
最大验证准确率: 65.32%
与基准的比较
# 基准和预训练 + 微调过程的分类准确率:
def plot_training_curves(pretraining_history, finetuning_history, baseline_history):
for metric_key, metric_name in zip(["acc", "loss"], ["accuracy", "loss"]):
plt.figure(figsize=(8, 5), dpi=100)
plt.plot(
baseline_history.history[f"val_{metric_key}"],
label="监督基准",
)
plt.plot(
pretraining_history.history[f"val_p_{metric_key}"],
label="自监督预训练",
)
plt.plot(
finetuning_history.history[f"val_{metric_key}"],
label="监督微调",
)
plt.legend()
plt.title(f"训练期间的分类 {metric_name}")
plt.xlabel("epoch")
plt.ylabel(f"验证 {metric_name}")
plot_training_curves(pretraining_history, finetuning_history, baseline_history)
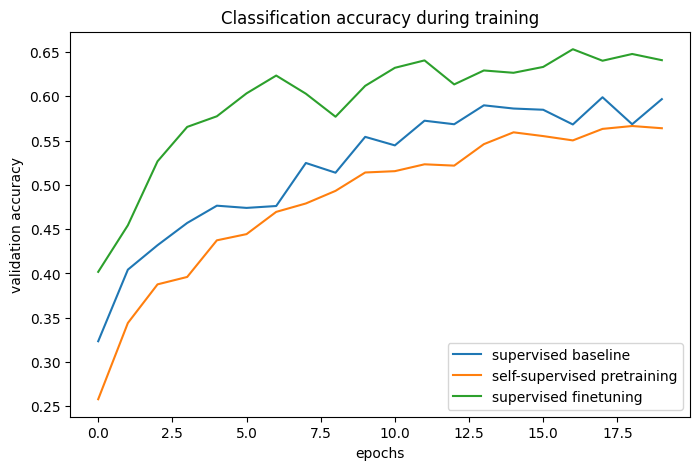
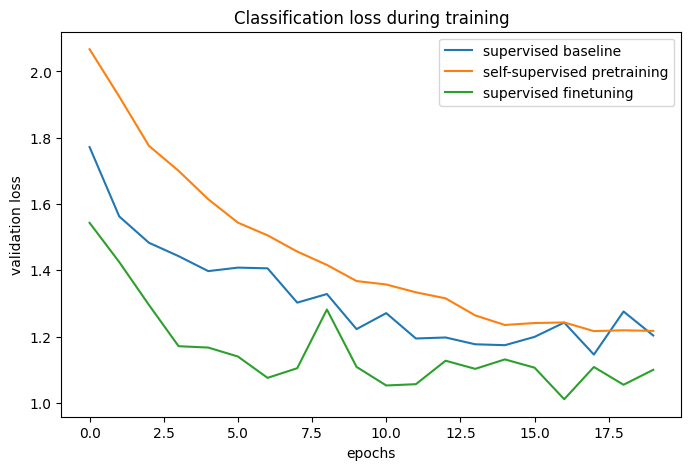
通过比较训练曲线,我们可以看到,当使用对比预训练时,能够达到更高的验证准确率,同时伴随更低的验证损失,这意味着预训练网络在仅看到少量标记示例时能够更好地泛化。
进一步改进
架构
实验在原始论文中表明,增加模型的宽度和深度可以以比监督学习更高的速度提高性能。此外,在文献中使用 ResNet-50 编码器是相当标准的。然而请记住,更强大的模型不仅会增加训练时间,还会需要更多内存,并限制您可以使用的最大批量大小。
有 报道 指出 使用 BatchNorm 层有时可能会降低性能,因为它在样本之间引入了内部批次依赖性,这就是我在这个例子中没有使用它们的原因。然而在我的实验中,使用 BatchNorm,特别是在投影头中,确实提高了性能。
超参数
在这个例子中使用的超参数已经为这个任务和架构手动调整。因此,在不更改它们的情况下,仅通过进一步的超参数调整可以预期获得微小的收益。
然而,对于不同的任务或模型架构,这些都需要调整,因此这里是我对最重要的超参数的笔记:
- 批量大小:由于目标可以被解释为对一批图像的分类(粗略来说),批量大小实际上是一个比通常更重要的超参数。越大越好。
- 温度:温度定义了在交叉熵损失中使用的 softmax 分布的“柔和度”,是一个重要的超参数。较低的值通常会导致更高的对比准确率。最近一个技巧(在 ALIGN 中)是学习温度的值(可以通过将其定义为 tf.Variable 并对其应用梯度)。尽管这提供了一个良好的基线值,在我的实验中,学习到的温度略低于最佳值,因为它是相对于对比损失优化的,而对比损失并不是表示质量的完美代理。
- 图像增强强度:在预训练期间,更强的增强增加了任务的难度,然而在某个点之后,过强的增强会降低性能。在微调期间,更强的增强减少了过拟合,而根据我的经验,过强的增强会降低预训练的性能提升。整个数据增强管道可以被视为算法的重要超参数,其他自定义图像增强层在 Keras 中的实现可以在 这个仓库 中找到。
- 学习率调度:这里使用了常量调度,但在文献中常用的是 余弦衰减调度,这可以进一步提高性能。
- 优化器:在这个例子中使用了 Adam,因为它在默认参数下提供了良好的性能。带动量的 SGD 需要更多的调整,但它可能会稍微提高性能。
相关工作
其他实例级(图像级)对比学习方法:
- MoCo (v2, v3):同样使用动量编码器,其权重是目标编码器的指数移动平均
- SwAV:使用聚类而不是成对比较
- BarlowTwins:使用基于交叉相关的目标而不是成对比较
MoCo 和 BarlowTwins 的 Keras 实现可以在 这个仓库 中找到,其中包含一个 Colab 笔记本。
还有一系列新的工作,优化类似的目标,但不使用任何负样本:
根据我的经验,这些方法更加脆弱(它们可能会崩溃到一个常数表示,我无法使用这种编码器架构使它们正常工作)。尽管它们通常更依赖于 模型 架构,但它们可以在较小批量大小时提高性能。
您可以使用托管在 Hugging Face Hub 上的训练模型,并尝试在 Hugging Face Spaces 上进行演示。