自监督对比学习与 SimSiam
作者: Sayak Paul
创建日期: 2021/03/19
最后修改: 2023/12/29
描述: 计算机视觉自监督学习方法的实现。

自监督学习 (SSL) 是表示学习领域中一个有趣的研究方向。SSL 系统试图从未标记的数据点集合中构造一个监督信号。一个例子是我们训练一个深度神经网络,根据给定的一组单词预测下一个单词。在文献中,这些任务被称为 前置任务 或 辅助任务。如果我们在一个巨大的数据集(例如 维基百科文本语料库)上训练这样的网络,它就能学习到非常有效的表示,这些表示在下游任务中转移效果很好。像 BERT、GPT-3、ELMo 等语言模型都受益于此。
与语言模型类似,我们可以使用类似的方式训练计算机视觉模型。为了使事情在计算机视觉中有效,我们需要将学习任务构造得使得底层模型(深度神经网络)能够理解视觉数据中存在的语义信息。一个这样的任务是让模型对同一图像的两个不同版本进行 对比。希望通过这种方式,模型能够学习到相似图像尽可能地聚集在一起,而不相似的图像则距离更远。
在本示例中,我们将实现一个名为 SimSiam 的系统,该系统在探索简单的孪生表示学习中提出。其实现如下:
- 我们使用随机数据增强管道创建同一数据集的两个不同版本。注意,在创建这些版本时,随机初始化种子需要相同。
- 我们使用一个没有任何分类头的 ResNet(主干),并在其上添加一个浅层全连接网络(投影头)。总体来说,这被称为 编码器。
- 我们将编码器的输出传递通过一个 预测器,该预测器同样是一个具有 自编码器 结构的浅层全连接网络。
- 然后我们训练编码器,以最大化我们数据集两个不同版本之间的余弦相似度。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
import keras_cv
from keras import ops
import matplotlib.pyplot as plt
import numpy as np
定义超参数
AUTO = tf.data.AUTOTUNE
BATCH_SIZE = 128
EPOCHS = 5
CROP_TO = 32
SEED = 26
PROJECT_DIM = 2048
LATENT_DIM = 512
WEIGHT_DECAY = 0.0005
加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
print(f"总训练示例: {len(x_train)}")
print(f"总测试示例: {len(x_test)}")
总训练示例: 50000
总测试示例: 10000
定义我们的数据增强管道
正如在SimCLR中研究的那样,正确的数据增强管道对 SSL 系统在计算机视觉中有效工作至关重要。两种特别重要的增强变换是:1.) 随机大小裁剪和 2.) 颜色失真。大多数其他计算机视觉的 SSL 系统(如 BYOL、MoCoV2、SwAV 等)在其训练管道中都包含这些。
strength = [0.4, 0.4, 0.4, 0.1]
random_flip = layers.RandomFlip(mode="horizontal_and_vertical")
random_crop = layers.RandomCrop(CROP_TO, CROP_TO)
random_brightness = layers.RandomBrightness(0.8 * strength[0])
random_contrast = layers.RandomContrast((1 - 0.8 * strength[1], 1 + 0.8 * strength[1]))
random_saturation = keras_cv.layers.RandomSaturation(
(0.5 - 0.8 * strength[2], 0.5 + 0.8 * strength[2])
)
random_hue = keras_cv.layers.RandomHue(0.2 * strength[3], [0,255])
grayscale = keras_cv.layers.Grayscale()
def flip_random_crop(image):
# 使用随机裁剪时,我们还会应用水平翻转。
image = random_flip(image)
image = random_crop(image)
return image
def color_jitter(x, strength=[0.4, 0.4, 0.3, 0.1]):
x = random_brightness(x)
x = random_contrast(x)
x = random_saturation(x)
x = random_hue(x)
# 仿射变换可能会干扰 RGB 图像的自然范围,因此这是必要的。
x = ops.clip(x, 0, 255)
return x
def color_drop(x):
x = grayscale(x)
x = ops.tile(x, [1, 1, 3])
return x
def random_apply(func, x, p):
if keras.random.uniform([], minval=0, maxval=1) < p:
return func(x)
else:
return x
def custom_augment(image):
# 正如 SimCLR 论文中所讨论的,系列增强
# 变换(随机裁剪除外)需要随机应用
# 以施加平移不变性。
image = flip_random_crop(image)
image = random_apply(color_jitter, image, p=0.8)
image = random_apply(color_drop, image, p=0.2)
return image
It should be noted that an augmentation pipeline is generally dependent on various properties of the dataset we are dealing with. For example, if images in the dataset are heavily object-centric then taking random crops with a very high probability may hurt the training performance.
Let's now apply our augmentation pipeline to our dataset and visualize a few outputs.
将数据转换为 TensorFlow Dataset 对象
在这里,我们创建两个不同版本的数据集没有任何真实标签。
ssl_ds_one = tf.data.Dataset.from_tensor_slices(x_train)
ssl_ds_one = (
ssl_ds_one.shuffle(1024, seed=SEED)
.map(custom_augment, num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
ssl_ds_two = tf.data.Dataset.from_tensor_slices(x_train)
ssl_ds_two = (
ssl_ds_two.shuffle(1024, seed=SEED)
.map(custom_augment, num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
# 然后我们将这两个数据集压缩在一起。
ssl_ds = tf.data.Dataset.zip((ssl_ds_one, ssl_ds_two))
# 可视化一些增强后的图像。
sample_images_one = next(iter(ssl_ds_one))
plt.figure(figsize=(10, 10))
for n in range(25):
ax = plt.subplot(5, 5, n + 1)
plt.imshow(sample_images_one[n].numpy().astype("int"))
plt.axis("off")
plt.show()
# 确保数据集的不同版本实际上包含
# 相同的图像。
sample_images_two = next(iter(ssl_ds_two))
plt.figure(figsize=(10, 10))
for n in range(25):
ax = plt.subplot(5, 5, n + 1)
plt.imshow(sample_images_two[n].numpy().astype("int"))
plt.axis("off")
plt.show()

注意到 samples_images_one 和 sample_images_two 中的图像本质上是相同的,但增强方式不同。
定义编码器和预测器
我们使用一个专门针对 CIFAR10 数据集配置的 ResNet20 实现。代码来自于 keras-idiomatic-programmer 仓库。这些架构的超参数参考了 原始论文 的第 3 节和附录 A。
!wget -q https://git.io/JYx2x -O resnet_cifar10_v2.py
import resnet_cifar10_v2
N = 2
DEPTH = N * 9 + 2
NUM_BLOCKS = ((DEPTH - 2) // 9) - 1
def get_encoder():
# 输入和主干网络。
inputs = layers.Input((CROP_TO, CROP_TO, 3))
x = layers.Rescaling(scale=1.0 / 127.5, offset=-1)(
inputs
)
x = resnet_cifar10_v2.stem(x)
x = resnet_cifar10_v2.learner(x, NUM_BLOCKS)
x = layers.GlobalAveragePooling2D(name="backbone_pool")(x)
# 投影头。
x = layers.Dense(
PROJECT_DIM, use_bias=False, kernel_regularizer=regularizers.l2(WEIGHT_DECAY)
)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Dense(
PROJECT_DIM, use_bias=False, kernel_regularizer=regularizers.l2(WEIGHT_DECAY)
)(x)
outputs = layers.BatchNormalization()(x)
return keras.Model(inputs, outputs, name="encoder")
def get_predictor():
model = keras.Sequential(
[
# 注意像 AutoEncoder 的结构。
layers.Input((PROJECT_DIM,)),
layers.Dense(
LATENT_DIM,
use_bias=False,
kernel_regularizer=regularizers.l2(WEIGHT_DECAY),
),
layers.ReLU(),
layers.BatchNormalization(),
layers.Dense(PROJECT_DIM),
],
name="predictor",
)
return model
定义(预)训练循环
使用这种方法训练网络的主要原因之一是利用学习到的表示来处理下游任务,如分类。这就是为什么这个特定的训练阶段也被称为 预训练。
我们首先定义损失函数。
def compute_loss(p, z):
# SimSiam 的作者强调了
# `stop_gradient` 操作符的影响,因为它
# 在整体优化中起着重要作用。
z = ops.stop_gradient(z)
p = keras.utils.normalize(p, axis=1, order=2)
z = keras.utils.normalize(z, axis=1, order=2)
# 负余弦相似度(最小化此值等同于最大化相似度)。
return -ops.mean(ops.sum((p * z), axis=1))
然后我们通过覆盖 keras.Model 类的 train_step() 函数来定义我们的训练循环。
class SimSiam(keras.Model):
def __init__(self, encoder, predictor):
super().__init__()
self.encoder = encoder
self.predictor = predictor
self.loss_tracker = keras.metrics.Mean(name="loss")
@property
def metrics(self):
return [self.loss_tracker]
def train_step(self, data):
# 解包数据。
ds_one, ds_two = data
# 通过编码器和预测器进行前向传播。
with tf.GradientTape() as tape:
z1, z2 = self.encoder(ds_one), self.encoder(ds_two)
p1, p2 = self.predictor(z1), self.predictor(z2)
# 注意这里我们强制网络匹配
# 两个不同增强批次的数据的表示。
loss = compute_loss(p1, z2) / 2 + compute_loss(p2, z1) / 2
# 计算梯度并更新参数。
learnable_params = (
self.encoder.trainable_variables + self.predictor.trainable_variables
)
gradients = tape.gradient(loss, learnable_params)
self.optimizer.apply_gradients(zip(gradients, learnable_params))
# 监控损失。
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
预训练我们的网络
在这个示例中,我们将模型训练5个周期。实际上,这应该至少是100个周期。
# 创建一个余弦衰减学习率调度器。
num_training_samples = len(x_train)
steps = EPOCHS * (num_training_samples // BATCH_SIZE)
lr_decayed_fn = keras.optimizers.schedules.CosineDecay(
initial_learning_rate=0.03, decay_steps=steps
)
# 创建一个早停回调。
early_stopping = keras.callbacks.EarlyStopping(
monitor="loss", patience=5, restore_best_weights=True
)
# 编译模型并开始训练。
simsiam = SimSiam(get_encoder(), get_predictor())
simsiam.compile(optimizer=keras.optimizers.SGD(lr_decayed_fn, momentum=0.6))
history = simsiam.fit(ssl_ds, epochs=EPOCHS, callbacks=[early_stopping])
# 可视化模型的训练进展。
plt.plot(history.history["loss"])
plt.grid()
plt.title("负余弦相似度")
plt.show()
Epoch 1/5
391/391 [==============================] - 33s 42ms/step - loss: -0.8973
Epoch 2/5
391/391 [==============================] - 16s 40ms/step - loss: -0.9129
Epoch 3/5
391/391 [==============================] - 16s 40ms/step - loss: -0.9165
Epoch 4/5
391/391 [==============================] - 16s 40ms/step - loss: -0.9176
Epoch 5/5
391/391 [==============================] - 16s 40ms/step - loss: -0.9182
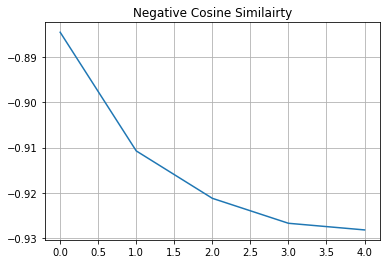
如果您的解决方案在不同的数据集和不同的骨干架构上迅速接近-1(我们损失的最小值),这很可能是因为表示收缩。这是一种现象,其中编码器对所有图像产生相似的输出。在这种情况下,需要额外的超参数调优,特别是在以下几个方面:
- 色彩失真的强度及其概率。
- 学习率及其调度。
- 骨干网络及其投影头的架构。
评估我们的SSL方法
在计算机视觉(或任何其他预训练方法)中,评估SSL方法最常用的方法是对训练好的骨干模型(在本例中为ResNet20)的冻结特征学习一个线性分类器,并在未见图像上评估该分类器。其他方法包括对源数据集或带有5%或10%标签的目标数据集进行微调。实际上,我们可以将骨干模型用于任何下游任务,例如语义分割、目标检测等,骨干模型通常通过纯监督学习进行预训练。
# 我们首先创建标记的 `Dataset` 对象。
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
# 然后我们对这个数据集进行打乱、分批和预取以提高性能。我们
# 还对训练集应用随机缩放裁剪作为数据增强。
train_ds = (
train_ds.shuffle(1024)
.map(lambda x, y: (flip_random_crop(x), y), num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
test_ds = test_ds.batch(BATCH_SIZE).prefetch(AUTO)
# 提取骨干网络ResNet20。
backbone = keras.Model(
simsiam.encoder.input, simsiam.encoder.get_layer("backbone_pool").output
)
# 然后我们创建线性分类器并训练它。
backbone.trainable = False
inputs = layers.Input((CROP_TO, CROP_TO, 3))
x = backbone(inputs, training=False)
outputs = layers.Dense(10, activation="softmax")(x)
linear_model = keras.Model(inputs, outputs, name="linear_model")
# 编译模型并开始训练。
linear_model.compile(
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
optimizer=keras.optimizers.SGD(lr_decayed_fn, momentum=0.9),
)
history = linear_model.fit(
train_ds, validation_data=test_ds, epochs=EPOCHS, callbacks=[early_stopping]
)
_, test_acc = linear_model.evaluate(test_ds)
print("测试准确率: {:.2f}%".format(test_acc * 100))
Epoch 1/5
391/391 [==============================] - 7s 11ms/step - loss: 3.8072 - accuracy: 0.1527 - val_loss: 3.7449 - val_accuracy: 0.2046
Epoch 2/5
391/391 [==============================] - 3s 8ms/step - loss: 3.7356 - accuracy: 0.2107 - val_loss: 3.7055 - val_accuracy: 0.2308
Epoch 3/5
391/391 [==============================] - 3s 8ms/step - loss: 3.7036 - accuracy: 0.2228 - val_loss: 3.6874 - val_accuracy: 0.2329
Epoch 4/5
391/391 [==============================] - 3s 8ms/step - loss: 3.6893 - accuracy: 0.2276 - val_loss: 3.6808 - val_accuracy: 0.2334
Epoch 5/5
391/391 [==============================] - 3s 9ms/step - loss: 3.6845 - accuracy: 0.2305 - val_loss: 3.6798 - val_accuracy: 0.2339
79/79 [==============================] - 1s 7ms/step - loss: 3.6798 - accuracy: 0.2339
测试准确率: 23.39%