可视化卷积神经网络学习的内容
作者: fchollet
创建日期: 2020/05/29
最后修改日期: 2020/05/29
描述: 显示卷积神经网络滤波器响应的视觉模式。

简介
在这个例子中,我们研究图像分类模型学习到的视觉模式。
我们将使用在 ImageNet 数据集上训练的 ResNet50V2 模型。
我们的过程很简单:我们将创建输入图像,以最大化特定滤波器在目标层(位于模型中间的某个位置:层 conv3_block4_out)的激活。这些图像代表了滤波器响应的模式的可视化。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
import numpy as np
import tensorflow as tf
# 输入图像的维度
img_width = 180
img_height = 180
# 我们的目标层:我们将可视化该层的滤波器。
# 如果您想更改此内容,请查看 `model.summary()` 以获取层名称列表。
layer_name = "conv3_block4_out"
构建特征提取模型
# 构建一个加载了预训练 ImageNet 权重的 ResNet50V2 模型
model = keras.applications.ResNet50V2(weights="imagenet", include_top=False)
# 设置一个返回我们目标层激活值的模型
layer = model.get_layer(name=layer_name)
feature_extractor = keras.Model(inputs=model.inputs, outputs=layer.output)
设置梯度上升过程
我们要最大化的“损失”只是我们目标层中特定滤波器激活的平均值。为了避免边界效果,我们排除了边界像素。
def compute_loss(input_image, filter_index):
activation = feature_extractor(input_image)
# 我们通过仅涉及非边界像素来避免边界伪影。
filter_activation = activation[:, 2:-2, 2:-2, filter_index]
return tf.reduce_mean(filter_activation)
我们的梯度上升函数简单地计算上述损失相对于输入图像的梯度,并更新图像,以便将其推向会更强烈激活目标滤波器的状态。
@tf.function
def gradient_ascent_step(img, filter_index, learning_rate):
with tf.GradientTape() as tape:
tape.watch(img)
loss = compute_loss(img, filter_index)
# 计算梯度。
grads = tape.gradient(loss, img)
# 规范化梯度。
grads = tf.math.l2_normalize(grads)
img += learning_rate * grads
return loss, img
设置端到端滤波器可视化循环
我们的过程如下:
- 从一幅接近“全灰”(即视觉中立)的随机图像开始
- 重复应用上面定义的梯度上升步骤函数
- 通过规范化、中心裁剪并限制在 [0, 255] 范围内,将结果输入图像转换回可显示的形式。
def initialize_image():
# 我们从一幅带有随机噪声的灰色图像开始
img = tf.random.uniform((1, img_width, img_height, 3))
# ResNet50V2 期望输入范围在 [-1, +1] 之间。
# 在这里我们将随机输入缩放到 [-0.125, +0.125]
return (img - 0.5) * 0.25
def visualize_filter(filter_index):
# 我们进行 20 次梯度上升
iterations = 30
learning_rate = 10.0
img = initialize_image()
for iteration in range(iterations):
loss, img = gradient_ascent_step(img, filter_index, learning_rate)
# 解码结果输入图像
img = deprocess_image(img[0].numpy())
return loss, img
def deprocess_image(img):
# 规范化数组:中心在 0,并确保方差为 0.15
img -= img.mean()
img /= img.std() + 1e-5
img *= 0.15
# 中心裁剪
img = img[25:-25, 25:-25, :]
# 限制在 [0, 1] 范围内
img += 0.5
img = np.clip(img, 0, 1)
# 转换为 RGB 数组
img *= 255
img = np.clip(img, 0, 255).astype("uint8")
return img
让我们尝试用目标层中的滤波器 0 来看看效果:
from IPython.display import Image, display
loss, img = visualize_filter(0)
keras.utils.save_img("0.png", img)
这就是最大化目标层中滤波器 0 响应的输入图像所呈现的样子:
display(Image("0.png"))

可视化目标层中的前 64 个滤波器
现在,让我们制作一个 8x8 的网格,展示目标层前 64 个过滤器,以了解模型所学习的不同视觉模式的范围。
# 计算最大化每个过滤器激活的图像输入
# 针对目标层的前 64 个过滤器
all_imgs = []
for filter_index in range(64):
print("处理过滤器 %d" % (filter_index,))
loss, img = visualize_filter(filter_index)
all_imgs.append(img)
# 构建一幅黑色图像,具有足够的空间
# 我们的 8 x 8 过滤器,大小为 128 x 128,之间有 5 像素的间隔
margin = 5
n = 8
cropped_width = img_width - 25 * 2
cropped_height = img_height - 25 * 2
width = n * cropped_width + (n - 1) * margin
height = n * cropped_height + (n - 1) * margin
stitched_filters = np.zeros((width, height, 3))
# 用我们保存的过滤器填充图像
for i in range(n):
for j in range(n):
img = all_imgs[i * n + j]
stitched_filters[
(cropped_width + margin) * i : (cropped_width + margin) * i + cropped_width,
(cropped_height + margin) * j : (cropped_height + margin) * j
+ cropped_height,
:,
] = img
keras.utils.save_img("stiched_filters.png", stitched_filters)
from IPython.display import Image, display
display(Image("stiched_filters.png"))
处理过滤器 0
处理过滤器 1
处理过滤器 2
处理过滤器 3
处理过滤器 4
处理过滤器 5
处理过滤器 6
处理过滤器 7
处理过滤器 8
处理过滤器 9
处理过滤器 10
处理过滤器 11
处理过滤器 12
处理过滤器 13
处理过滤器 14
处理过滤器 15
处理过滤器 16
处理过滤器 17
处理过滤器 18
处理过滤器 19
处理过滤器 20
处理过滤器 21
处理过滤器 22
处理过滤器 23
处理过滤器 24
处理过滤器 25
处理过滤器 26
处理过滤器 27
处理过滤器 28
处理过滤器 29
处理过滤器 30
处理过滤器 31
处理过滤器 32
处理过滤器 33
处理过滤器 34
处理过滤器 35
处理过滤器 36
处理过滤器 37
处理过滤器 38
处理过滤器 39
处理过滤器 40
处理过滤器 41
处理过滤器 42
处理过滤器 43
处理过滤器 44
处理过滤器 45
处理过滤器 46
处理过滤器 47
处理过滤器 48
处理过滤器 49
处理过滤器 50
处理过滤器 51
处理过滤器 52
处理过滤器 53
处理过滤器 54
处理过滤器 55
处理过滤器 56
处理过滤器 57
处理过滤器 58
处理过滤器 59
处理过滤器 60
处理过滤器 61
处理过滤器 62
处理过滤器 63
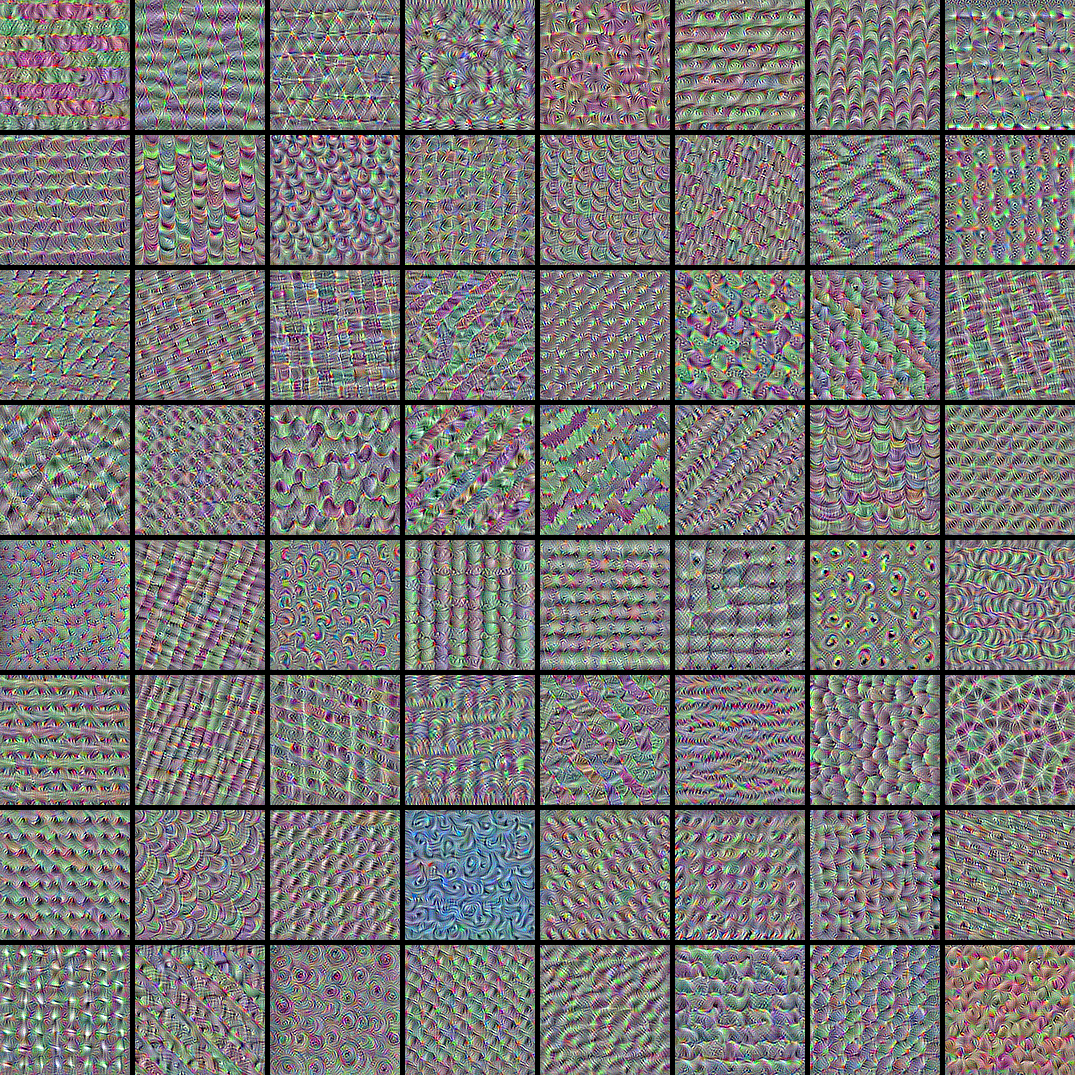
图像分类模型通过在“向量基”纹理过滤器上分解其输入来观察世界,例如这些。
另请参阅 这篇旧博文 以进行分析和解释。