入门KerasNLP
作者: Jonathan Bischof
创建日期: 2022/12/15
上次修改: 2023/07/01
描述: KerasNLP API 的介绍。

介绍
KerasNLP 是一个自然语言处理库,支持用户在整个开发周期中的需求。我们的工作流程由模块化组件构建,这些组件在开箱即用时具有最先进的预设权重和架构,并且在需要更多控制时易于自定义。
这个库是核心 Keras API 的扩展;所有高级模块都是 Layers 或 Models。如果你熟悉 Keras,恭喜你!你已经理解了 KerasNLP 的大部分内容。
KerasNLP 使用 Keras 3 与 TensorFlow、Pytorch 和 Jax 进行工作。在下面的指南中,我们将使用 jax 后端来训练我们的模型,并且使用 tf.data 来高效地运行我们的输入预处理。但是请随意混合使用!这个指南可以在 TensorFlow 或 PyTorch 后端下无缝运行,只需更新下面的 KERAS_BACKEND。
本指南通过情感分析示例以六个复杂度级别展示我们模块化的方法:
- 使用预训练分类器进行推断
- 对预训练骨干进行微调
- 使用用户控制的预处理进行微调
- 微调自定义模型
- 预训练骨干模型
- 从头构建和训练您自己的变换器
在我们的指南中,我们使用 Keras 教授,官方的 Keras 吉祥物,作为材料复杂性的视觉参考:
!pip install -q --upgrade keras-nlp
!pip install -q --upgrade keras # 升级到 Keras 3。
import os
os.environ["KERAS_BACKEND"] = "jax" # 或 "tensorflow" 或 "torch"
import keras_nlp
import keras
# 使用混合精度加速本指南中的所有训练。
keras.mixed_precision.set_global_policy("mixed_float16")
API 快速入门
我们最高级别的 API 是 keras_nlp.models。这些符号涵盖了将字符串转换为标记、将标记转换为密集特征,以及将密集特征转换为特定任务输出的完整用户旅程。对于每个 XX 架构(例如,Bert),我们提供以下模块:
- Tokenizer:
keras_nlp.models.XXTokenizer- 作用: 将字符串转换为标记 ID 序列。
- 重要性: 字符串的原始字节维度过高,无法作为有用特征,因此我们首先将它们映射到少量标记,例如将
"The quick brown fox"映射为["the", "qu", "##ick", "br", "##own", "fox"]。 - 继承自:
keras.layers.Layer。
- Preprocessor:
keras_nlp.models.XXPreprocessor- 作用: 将字符串转换为由骨干消费的预处理张量字典,首先进行标记化。
- 重要性: 每个模型使用特殊标记和额外张量来理解输入,例如分隔输入段和识别填充标记。将每个序列填充到相同长度可以提高计算效率。
- 具有:
XXTokenizer。 - 继承自:
keras.layers.Layer。
- Backbone:
keras_nlp.models.XXBackbone- 作用: 将预处理张量转换为密集特征。不处理字符串;请先调用预处理器。
- 重要性: 骨干将输入标记提炼为可用于下游任务的密集特征。它通常在语言建模任务上使用大量未标记数据进行预训练。将此信息转移到新任务是现代 NLP 的一项重大突破。
- 继承自:
keras.Model。
- Task: 例如,
keras_nlp.models.XXClassifier- 作用: 将字符串转换为特定任务的输出(例如,分类概率)。
- 重要性: 任务模型将字符串预处理和骨干模型与特定任务的
Layers结合起来,以解决例如句子分类、标记分类或文本生成等问题。附加的Layers必须在标记数据上进行微调。 - 具有:
XXBackbone和XXPreprocessor。 - 继承自:
keras.Model。
以下是 BertClassifier 的模块化层次结构(所有关系都是组合性):
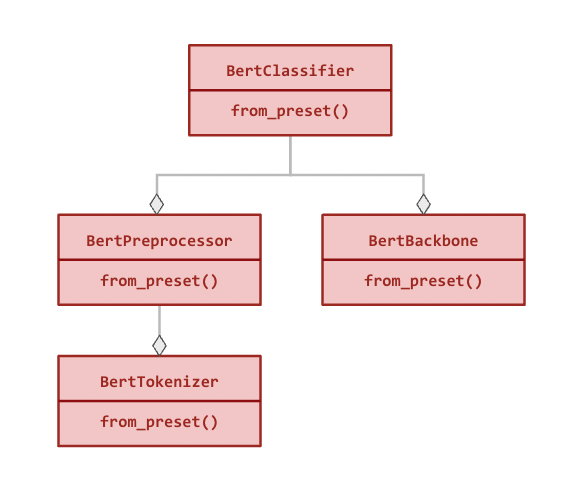
所有模块都可以独立使用,并且除了标准构造函数外,还具有 from_preset() 方法,该方法使用预设架构和权重实例化类(请参见下面的示例)。
数据
我们将使用 IMDB 电影评论的情感分析作为示例。在此任务中,我们使用文本预测评论是积极的(label = 1)还是消极的(label = 0)。
我们使用 keras.utils.text_dataset_from_directory 加载数据,该方法利用强大的 tf.data.Dataset 格式来处理示例。
!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xf aclImdb_v1.tar.gz
!# 删除无监督示例
!rm -r aclImdb/train/unsup
BATCH_SIZE = 16
imdb_train = keras.utils.text_dataset_from_directory(
"aclImdb/train",
batch_size=BATCH_SIZE,
)
imdb_test = keras.utils.text_dataset_from_directory(
"aclImdb/test",
batch_size=BATCH_SIZE,
)
# 检查第一条评论
# 格式为(评论文本张量,标签张量)
print(imdb_train.unbatch().take(1).get_single_element())
% 总计 % 接收 % 传输 平均速度 时间 时间 时间 当前
下载 上传 总计 已花费 剩余 速度
100 80.2M 100 80.2M 0 0 88.0M 0 --:--:-- --:--:-- --:--:-- 87.9M
找到属于 2 个类别的 25000 个文件。
找到属于 2 个类别的 25000 个文件。
(<tf.Tensor: shape=(), dtype=string, numpy=b'This is a very, very early Bugs Bunny cartoon. As a result, the character is still in a transition period--he is not drawn as elongated as he later was and his voice isn\'t quite right. In addition, the chemistry between Elmer and Bugs is a little unusual. Elmer is some poor sap who buys Bugs from a pet shop--there is no gun or desire on his part to blast the bunny to smithereens! However, despite this, this is still a very enjoyable film. The early Bugs was definitely more sassy and cruel than his later incarnations. In later films, he messed with Elmer, Yosimite Sam and others because they started it--they messed with the rabbit. But, in this film, he is much more like Daffy Duck of the late 30s and early 40s--a jerk who just loves irritating others!! A true "anarchist" instead of the hero of the later cartoons. While this isn\'t among the best Bug Bunny cartoons, it sure is fun to watch and it\'s interesting to see just how much he\'s changed over the years.'>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
使用预训练分类器进行推断

KerasNLP 中的最高级模块是 任务。任务是一个 keras.Model,由一个(通常是预训练的)主干模型和特定于任务的层组成。以下是使用 keras_nlp.models.BertClassifier 的示例。
注意:输出是每个类别的 logits(例如,[0, 0] 是 50% 的积极可能性)。输出是针对二元分类的 [负面,正面]。
classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
# 注意:期望批量输入,因此必须将字符串包装在可迭代对象中
classifier.predict(["I love modular workflows in keras-nlp!"])
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 689ms/step
array([[-1.539, 1.543]], dtype=float16)
所有 任务 都有一个 from_preset 方法,用于构造带有预设预处理、架构和权重的 keras.Model 实例。这意味着我们可以传递任何格式的原始字符串, keras.Model 接受,并获得与我们的任务相关的输出。
这个特定的 预设 是在 sst2 上微调的 "bert_tiny_uncased_en" 主干,另一个电影评论情感分析(这次来自 Rotten Tomatoes)。我们使用 tiny 架构进行演示,但建议使用更大的模型以获得最佳性能。有关 BertClassifier 可用的所有特定于任务的预设,请参见我们的 keras.io 模型页面。
让我们在 IMDB 数据集上评估我们的分类器。你会注意到我们在这里不需要调用 keras.Model.compile。所有像 BertClassifier 这样的 任务 模型都附带编译默认值,这意味着我们可以直接调用 keras.Model.evaluate。你可以随时像往常一样调用编译以覆盖这些默认值(例如,添加新指标)。
以下输出是 [损失,准确率],
classifier.evaluate(imdb_test)
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - loss: 0.4610 - sparse_categorical_accuracy: 0.7882
[0.4630218744277954, 0.783519983291626]
我们的结果是 78% 的准确率,而没有训练任何内容。这感觉还不错!
微调预训练的 BERT 主干

当有特定于我们任务的标记文本可用时,微调自定义分类器可以提高性能。如果我们想预测IMDB评论的情感,使用IMDB数据应该比使用烂番茄数据表现得更好!并且对于许多任务,可能没有相关的预训练模型可用(例如,分类客户评论)。
微调的工作流程与上述几乎相同,只是我们请求的是仅用于主干模型的预设,而不是整个分类器。当传入一个主干 预设时,任务 Model将随机初始化所有特定于任务的层,以准备训练。有关可用于BertClassifier的所有主干预设,请参见我们的keras.io 模型页面。
要训练分类器,可以像使用任何其他keras.Model一样使用keras.Model.fit。与我们的推断示例一样,我们可以依赖任务的编译默认值,跳过keras.Model.compile。由于包含了预处理,我们再次传递原始数据。
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased",
num_classes=2,
)
classifier.fit(
imdb_train,
validation_data=imdb_test,
epochs=1,
)
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 16s 9ms/step - loss: 0.5202 - sparse_categorical_accuracy: 0.7281 - val_loss: 0.3254 - val_sparse_categorical_accuracy: 0.8621
<keras.src.callbacks.history.History at 0x7f281ffc9f90>
在这里,我们看到验证准确率显著提升(0.78 -> 0.87),即使IMDB数据集比sst2小得多,经过一次训练的单个周期后。
使用用户控制的预处理进行微调

对于某些高级训练场景,用户可能希望直接控制预处理。对于大型数据集,可以提前对示例进行预处理并保存到磁盘,或通过使用tf.data.experimental.service的单独工作池进行预处理。在其他情况下,需要自定义预处理以处理输入。
将preprocessor=None传递给任务 Model的构造函数,以跳过自动预处理,或者传递一个自定义的BertPreprocessor。
将预处理与相同的预设分开
每种模型架构都有一个具有自己from_preset构造函数的平行预处理器 Layer。为该Layer使用相同的预设将返回与任务匹配的预处理器。
在此工作流程中,我们使用tf.data.Dataset.cache()对模型进行训练三轮,该方法计算一次预处理并在拟合开始之前缓存结果。
注意:只有在训练数据适合CPU内存时才调用cache()!
import tensorflow as tf
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=512,
)
# Apply the preprocessor to every sample of train and test data using `map()`.
# [`tf.data.AUTOTUNE`](https://www.tensorflow.org/api_docs/python/tf/data/AUTOTUNE) and `prefetch()` are options to tune performance, see
# https://www.tensorflow.org/guide/data_performance for details.
# Note: only call `cache()` if you training data fits in CPU memory!
imdb_train_cached = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_cached = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased", preprocessor=None, num_classes=2
)
classifier.fit(
imdb_train_cached,
validation_data=imdb_test_cached,
epochs=3,
)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 15s 8ms/step - loss: 0.5194 - sparse_categorical_accuracy: 0.7272 - val_loss: 0.3032 - val_sparse_categorical_accuracy: 0.8728
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2871 - sparse_categorical_accuracy: 0.8805 - val_loss: 0.2809 - val_sparse_categorical_accuracy: 0.8818
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2134 - sparse_categorical_accuracy: 0.9178 - val_loss: 0.3043 - val_sparse_categorical_accuracy: 0.8790
<keras.src.callbacks.history.History at 0x7f281ffc87f0>
经过三轮后,我们的验证准确率只提高到0.88。这既是我们数据集大小的结果,也是我们模型的结果。要超过90%的准确率,可以尝试更大的预设,例如"bert_base_en_uncased"。有关所有主干预设
可用于 BertClassifier,请访问我们的 keras.io 模型页面。
自定义预处理
在需要自定义预处理的情况下,我们提供直接访问 Tokenizer 类,该类将原始字符串映射为标记。它还具有 from_preset() 构造函数,以获取与预训练匹配的词汇。
注意: BertTokenizer 默认情况下不对序列进行填充,因此输出是稀疏的(每个序列的长度不同)。下面的 MultiSegmentPacker 处理将这些稀疏序列填充为稠密张量类型(例如 tf.Tensor 或 torch.Tensor)。
tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
# 编写自己的打包器或使用我们的 `Layers`
packer = keras_nlp.layers.MultiSegmentPacker(
start_value=tokenizer.cls_token_id,
end_value=tokenizer.sep_token_id,
# 注意:这不能长于预设的 `sequence_length`,并且
# 对自定义预处理程序没有检查!
sequence_length=64,
)
# 该函数接受文本样本 `x` 和对应的标签 `y` 作为输入,将文本转换为适合输入 BERT 模型的格式。
def preprocessor(x, y):
token_ids, segment_ids = packer(tokenizer(x))
x = {
"token_ids": token_ids,
"segment_ids": segment_ids,
"padding_mask": token_ids != 0,
}
return x, y
imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
# 预处理示例
print(imdb_train_preprocessed.unbatch().take(1).get_single_element())
({'token_ids': <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([ 101, 2023, 2003, 2941, 2028, 1997, 2026, 5440, 3152,
1010, 1045, 2052, 16755, 2008, 3071, 12197, 2009, 1012,
2045, 2003, 2070, 2307, 3772, 1999, 2009, 1998, 2009,
3065, 2008, 2025, 2035, 1000, 2204, 1000, 3152, 2024,
2137, 1012, 1012, 1012, 1012, 102, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0], dtype=int32)>, 'segment_ids': <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)>, 'padding_mask': <tf.Tensor: shape=(64,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False])>}, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
使用自定义模型进行微调
对于更高级的应用,可能无法获得适当的 任务 Model。在这种情况下,我们提供直接访问 主干 Model,它具有自己的 from_preset 构造函数,并可以与自定义 Layer 组合。详细示例可以在我们的 迁移学习指南 中找到。
主干 Model 不包括自动预处理,但可以与使用相同 preset 的匹配 preprocessor 配对,如前面的工作流程所示。
在这个工作流程中,我们尝试冻结我们的主干模型并添加两个可训练的 transformer 层,以适应新的输入。
注意:我们可以忽略有关 pooled_dense 层的梯度警告,因为我们使用的是 BERT 的序列输出。
preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
imdb_train_preprocessed = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_preprocessed = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
backbone.trainable = False
inputs = backbone.input
sequence = backbone(inputs)["sequence_output"]
for _ in range(2):
sequence = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=512,
dropout=0.1,
)(sequence)
# 使用 [CLS] 标记的输出进行分类
outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
model = keras.Model(inputs, outputs)
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.summary()
model.fit(
imdb_train_preprocessed,
validation_data=imdb_test_preprocessed,
epochs=3,
)
模型: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (无, 无) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ segment_ids │ (无, 无) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids │ (无, 无) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ bert_backbone_3 │ [(无, 128), │ 4,385,… │ padding_mask[0][0], │ │ (BertBackbone) │ (无, 无, │ │ segment_ids[0][0], │ │ │ 128)] │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encoder │ (无, 无, 128) │ 198,272 │ bert_backbone_3[0][… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encode… │ (无, 无, 128) │ 198,272 │ transformer_encoder… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ get_item_4 │ (无, 128) │ 0 │ transformer_encoder… │ │ (获取项目) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ dense (密集层) │ (无, 2) │ 258 │ get_item_4[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
总参数数: 4,782,722 (18.24 MB)
可训练参数: 396,802 (1.51 MB)
不可训练参数: 4,385,920 (16.73 MB)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 17s 10ms/step - loss: 0.6208 - sparse_categorical_accuracy: 0.6612 - val_loss: 0.6119 - val_sparse_categorical_accuracy: 0.6758
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.5324 - sparse_categorical_accuracy: 0.7347 - val_loss: 0.5484 - val_sparse_categorical_accuracy: 0.7320
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.4735 - sparse_categorical_accuracy: 0.7723 - val_loss: 0.4874 - val_sparse_categorical_accuracy: 0.7742
<keras.src.callbacks.history.History at 0x7f2790170220>
这个模型即使只有我们 BertClassifier 模型的 10% 可训练参数,仍然能够实现合理的准确性。每个训练步骤大约只需 1/3 的时间——即使考虑到缓存的预处理。
预训练基础模型

您是否有访问大型未标记数据集的权限?它们的大小是否与用于训练流行基础模型(如 BERT、RoBERTa 或 GPT2)相近(XX+ GiB)?如果是这样,您可能会从特定于领域的基础模型预训练中受益。
NLP 模型通常在语言建模任务上进行预训练,根据输入句子中的可见单词预测被掩盖的单词。例如,给定输入 “The fox [MASK] over the [MASK] dog”,模型可能会被要求预测 ["jumped", "lazy"]。然后,该模型的较低层被打包为一个 基础模型,以便与与新任务相关的层结合。
KerasNLP 库提供 SoTA 基础模型 和 分词器,可以从头开始训练,无需预设。
在此工作流程中,我们使用我们的 IMDB 评价文本预训练一个 BERT 基础模型。我们跳过“下一个句子预测”(NSP)损失,因为它给数据处理添加了显著复杂性,并且在像 RoBERTa 这样的后续模型中被舍弃。请参阅我们的 e2e Transformer 预训练 以获取逐步详细信息,了解如何复制原始论文。
数据预处理
# All BERT `en` models have the same vocabulary, so reuse preprocessor from
# "bert_tiny_en_uncased"
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=256,
)
packer = preprocessor.packer
tokenizer = preprocessor.tokenizer
# keras.Layer to replace some input tokens with the "[MASK]" token
masker = keras_nlp.layers.MaskedLMMaskGenerator(
vocabulary_size=tokenizer.vocabulary_size(),
mask_selection_rate=0.25,
mask_selection_length=64,
mask_token_id=tokenizer.token_to_id("[MASK]"),
unselectable_token_ids=[
tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
],
)
def preprocess(inputs, label):
inputs = preprocessor(inputs)
masked_inputs = masker(inputs["token_ids"])
# Split the masking layer outputs into a (features, labels, and weights)
# tuple that we can use with keras.Model.fit().
features = {
"token_ids": masked_inputs["token_ids"],
"segment_ids": inputs["segment_ids"],
"padding_mask": inputs["padding_mask"],
"mask_positions": masked_inputs["mask_positions"],
}
labels = masked_inputs["mask_ids"]
weights = masked_inputs["mask_weights"]
return features, labels, weights
pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
pretrain_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
# Tokens with ID 103 are "masked"
print(pretrain_ds.unbatch().take(1).get_single_element())
({'token_ids': <tf.Tensor: shape=(256,), dtype=int32, numpy=
array([ 101, 103, 2332, 103, 1006, 103, 103, 2332, 2370,
1007, 103, 2029, 103, 2402, 2155, 1010, 24159, 2000,
3541, 7081, 1010, 2424, 2041, 2055, 1996, 9004, 4528,
103, 103, 2037, 2188, 103, 1996, 2269, 1006, 8512,
3054, 103, 4246, 1007, 2059, 4858, 1555, 2055, 1996,
23025, 22911, 8940, 2598, 3458, 1996, 25483, 4528, 2008,
2038, 103, 1997, 15218, 1011, 103, 1997, 103, 2505,
3950, 2045, 3310, 2067, 2025, 3243, 2157, 1012, 103,
7987, 1013, 1028, 103, 7987, 1013, 1028, 2917, 103,
1000, 5469, 1000, 103, 103, 2041, 22902, 1010, 23979,
1010, 1998, 1999, 23606, 103, 1998, 4247, 2008, 2126,
2005, 1037, 2096, 1010, 2007, 1996, 103, 5409, 103,
2108, 3054, 3211, 4246, 1005, 1055, 22692, 2836, 1012,
2009, 103, 1037, 2210, 2488, 103, 103, 2203, 1010,
2007, 103, 103, 9599, 1012, 103, 2391, 1997, 2755,
1010, 1996, 2878, 3185, 2003, 2428, 103, 1010, 103,
103, 103, 1045, 2064, 1005, 1056, 3294, 19776, 2009,
1011, 2012, 2560, 2009, 2038, 2242, 2000, 103, 2009,
13432, 1012, 11519, 4637, 4616, 2011, 5965, 1043, 11761,
103, 103, 2004, 103, 7968, 3243, 4793, 11429, 1010,
1998, 8226, 2665, 18331, 1010, 1219, 1996, 4487, 22747,
8004, 12165, 4382, 5125, 103, 3597, 103, 2024, 2025,
2438, 2000, 103, 2417, 21564, 2143, 103, 103, 7987,
1013, 1028, 1026, 103, 1013, 1028, 2332, 2038, 103,
5156, 12081, 2004, 1996, 103, 1012, 1026, 14216, 103,
103, 1026, 7987, 1013, 1028, 184, 2011, 1037, 8297,
2036, 103, 2011, 2984, 103, 1006, 2003, 2009, 2151,
4687, 2008, 2016, 1005, 1055, 2018, 2053, 7731, 103,
103, 2144, 1029, 102], dtype=int32)>, 'segment_ids': <tf.Tensor: shape=(256,), dtype=int32, numpy=
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)>, 'padding_mask': <tf.Tensor: shape=(256,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True])>, 'mask_positions': <tf.Tensor: shape=(64,), dtype=int64, numpy=
array([ 1, 3, 5, 6, 10, 12, 13, 27, 28, 31, 37, 42, 51,
55, 59, 61, 65, 71, 75, 80, 83, 84, 85, 94, 105, 107,
108, 118, 122, 123, 127, 128, 131, 141, 143, 144, 145, 149, 160,
167, 170, 171, 172, 174, 176, 185, 193, 195, 200, 204, 205, 208,
210, 215, 220, 223, 224, 225, 230, 231, 235, 238, 251, 252])>}, <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([ 4459, 6789, 22892, 2011, 1999, 1037, 2402, 2485, 2000,
1012, 3211, 2041, 9004, 4204, 2069, 2607, 3310, 1026,
1026, 2779, 1000, 3861, 4627, 1010, 7619, 5783, 2108,
4152, 2646, 1996, 15958, 14888, 1999, 14888, 2029, 2003,
2339, 1056, 2191, 2011, 11761, 2638, 1010, 1996, 2214,
2004, 14674, 2860, 2428, 1012, 1026, 1028, 7987, 2010,
2704, 7987, 1013, 1028, 2628, 2011, 2856, 12838, 2143,
2147], dtype=int32)>, <tf.Tensor: shape=(64,), dtype=float16, numpy=
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], dtype=float16)>)
</div>
### 预训练模型
```python
# BERT 主干
backbone = keras_nlp.models.BertBackbone(
vocabulary_size=tokenizer.vocabulary_size(),
num_layers=2,
num_heads=2,
hidden_dim=128,
intermediate_dim=512,
)
# 语言建模头
mlm_head = keras_nlp.layers.MaskedLMHead(
token_embedding=backbone.token_embedding,
)
inputs = {
"token_ids": keras.Input(shape=(None,), dtype=tf.int32, name="token_ids"),
"segment_ids": keras.Input(shape=(None,), dtype=tf.int32, name="segment_ids"),
"padding_mask": keras.Input(shape=(None,), dtype=tf.int32, name="padding_mask"),
"mask_positions": keras.Input(shape=(None,), dtype=tf.int32, name="mask_positions"),
}
# 编码的标记序列
sequence = backbone(inputs)["sequence_output"]
# 为每个被掩蔽的输入标记预测一个输出单词。
# 我们使用输入标记嵌入将编码向量投影到
# 词汇对数上,这已被证明可以提高训练效率。
outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
# 定义并编译我们的预训练模型。
pretraining_model = keras.Model(inputs, outputs)
pretraining_model.summary()
pretraining_model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(learning_rate=5e-4),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
# 在 IMDB 数据集上进行预训练
pretraining_model.fit(
pretrain_ds,
validation_data=pretrain_val_ds,
epochs=3, # 增加到 6 以提高准确性
)
模型: "functional_3"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 层 (类型) ┃ 输出形状 ┃ 参数 # ┃ 连接到 ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ mask_positions │ (None, None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ padding_mask │ (None, None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ segment_ids │ (None, None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (输入层) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ bert_backbone_4 │ [(None, 128), │ 4,385,… │ mask_positions[0][0… │ │ (BertBackbone) │ (无, 无, │ │ padding_mask[0][0], │ │ │ 128)] │ │ segment_ids[0][0], │ │ │ │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ masked_lm_head │ (无, 无, │ 3,954,… │ bert_backbone_4[0][… │ │ (MaskedLMHead) │ 30522) │ │ mask_positions[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
总参数: 4,433,210 (16.91 MB)
可训练参数: 4,433,210 (16.91 MB)
非可训练参数: 0 (0.00 B)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - loss: 5.7032 - sparse_categorical_accuracy: 0.0566 - val_loss: 5.0685 - val_sparse_categorical_accuracy: 0.1044
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 5.0701 - sparse_categorical_accuracy: 0.1096 - val_loss: 4.9363 - val_sparse_categorical_accuracy: 0.1239
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 4.9607 - sparse_categorical_accuracy: 0.1240 - val_loss: 4.7913 - val_sparse_categorical_accuracy: 0.1417
<keras.src.callbacks.history.History at 0x7f2738299330>
vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
imdb_train.map(lambda x, y: x),
vocabulary_size=20_000,
lowercase=True,
strip_accents=True,
reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
)
tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
vocabulary=vocab,
lowercase=True,
strip_accents=True,
oov_token="[UNK]",
)
packer = keras_nlp.layers.StartEndPacker(
start_value=tokenizer.token_to_id("[START]"),
end_value=tokenizer.token_to_id("[END]"),
pad_value=tokenizer.token_to_id("[PAD]"),
sequence_length=512,
)
def preprocess(x, y):
token_ids = packer(tokenizer(x))
return token_ids, y
imdb_preproc_train_ds = imdb_train.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
imdb_preproc_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
(<tf.Tensor: shape=(512,), dtype=int32, numpy=
array([ 1, 102, 11, 61, 43, 771, 16, 340, 916,
1259, 155, 16, 135, 207, 18, 501, 10568, 344,
16, 51, 206, 612, 211, 232, 43, 1094, 17,
215, 155, 103, 238, 202, 18, 111, 16, 51,
143, 1583, 131, 100, 18, 32, 101, 19, 34,
32, 101, 19, 34, 102, 11, 61, 43, 155,
105, 5337, 99, 120, 6, 1289, 6, 129, 96,
526, 18, 111, 16, 193, 51, 197, 102, 16,
51, 252, 11, 62, 167, 104, 642, 98, 6,
8572, 6, 154, 51, 153, 1464, 119, 3005, 990,
2393, 18, 102, 11, 61, 233, 404, 103, 104,
110, 18, 18, 18, 233, 1259, 18, 18, 18,
154, 51, 659, 16273, 867, 192, 1632, 133, 990,
2393, 18, 32, 101, 19, 34, 32, 101, 19,
34, 96, 110, 2886, 761, 114, 4905, 293, 12337,
97, 2375, 18, 113, 143, 158, 179, 104, 4905,
610, 16, 12585, 97, 516, 725, 18, 113, 323,
96, 651, 146, 104, 207, 17649, 16, 96, 176,
16022, 136, 16, 1414, 136, 18, 113, 323, 96,
2184, 18, 97, 150, 651, 51, 242, 104, 100,
11722, 18, 113, 151, 543, 102, 171, 115, 1081,
103, 96, 222, 18, 18, 18, 18, 102, 659,
1081, 18, 18, 18, 102, 11, 61, 115, 299,
18, 113, 323, 96, 1579, 98, 203, 4438, 2033,
103, 96, 222, 18, 18, 18, 32, 101, 19,
34, 32, 101, 19, 34, 111, 16, 51, 455,
174, 99, 859, 43, 1687, 3330, 99, 104, 1021,
18, 18, 18, 51, 181, 11, 62, 214, 138,
96, 155, 100, 115, 916, 14, 1286, 14, 99,
296, 96, 642, 105, 224, 4598, 117, 1289, 156,
103, 904, 16, 111, 115, 103, 1628, 18, 113,
181, 11, 62, 119, 96, 1054, 155, 16, 111,
156, 14665, 18, 146, 110, 139, 742, 16, 96,
4905, 293, 12337, 97, 7042, 1104, 106, 557, 103,
366, 18, 128, 16, 150, 2446, 135, 96, 960,
98, 96, 4905, 18, 113, 323, 156, 43, 1174,
293, 188, 18, 18, 18, 43, 639, 293, 96,
455, 108, 207, 97, 1893, 99, 1081, 104, 4905,
18, 51, 194, 104, 440, 98, 12337, 99, 7042,
1104, 654, 122, 30, 6, 51, 276, 99, 663,
18, 18, 18, 97, 138, 113, 207, 163, 16,
113, 171, 172, 107, 51, 1027, 113, 6, 18,
32, 101, 19, 34, 32, 101, 19, 34, 104,
110, 171, 333, 10311, 141, 1311, 135, 140, 100,
207, 97, 140, 100, 99, 120, 1632, 18, 18,
18, 97, 210, 11, 61, 96, 6236, 293, 188,
18, 51, 181, 11, 62, 214, 138, 96, 421,
98, 104, 110, 100, 6, 207, 14129, 122, 18,
18, 18, 151, 1128, 97, 1632, 1675, 6, 133,
6, 207, 100, 404, 18, 18, 18, 150, 646,
179, 133, 210, 6, 18, 111, 103, 152, 744,
16, 104, 110, 100, 557, 43, 1120, 108, 96,
701, 382, 105, 102, 260, 113, 194, 18, 18,
18, 2, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
token_id_input = keras.Input(
shape=(None,),
dtype="int32",
name="token_ids",
)
outputs = keras_nlp.layers.TokenAndPositionEmbedding(
vocabulary_size=len(vocab),
sequence_length=packer.sequence_length,
embedding_dim=64,
)(token_id_input)
outputs = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=128,
dropout=0.1,
)(outputs)
# 使用 "[START]" 令牌进行分类
outputs = keras.layers.Dense(2)(outputs[:, 0, :])
model = keras.Model(
inputs=token_id_input,
outputs=outputs,
)
model.summary()
Model: "functional_5"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ 层 (类型) ┃ 输出形状 ┃ 参数数量 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ token_ids (输入层) │ (无, 无) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ token_and_position_embedding │ (无, 无, 64) │ 1,259,648 │
│ (TokenAndPositionEmbedding) │ │ │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ transformer_encoder_2 │ (无, 无, 64) │ 33,472 │
│ (TransformerEncoder) │ │ │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ get_item_6 (获取项目) │ (无, 64) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense_1 (全连接层) │ (无, 2) │ 130 │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 1,293,250 (4.93 MB)
Trainable params: 1,293,250 (4.93 MB)
Non-trainable params: 0 (0.00 B)### 直接在分类目标上训练变压器
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.fit(
imdb_preproc_train_ds,
validation_data=imdb_preproc_val_ds,
epochs=3,
)
第 1 轮/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 8s 4ms/步 - 损失: 0.7790 - 稀疏分类准确率: 0.5367 - 验证损失: 0.4420 - 验证稀疏分类准确率: 0.8120
第 2 轮/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/步 - 损失: 0.3654 - 稀疏分类准确率: 0.8443 - 验证损失: 0.3046 - 验证稀疏分类准确率: 0.8752
第 3 轮/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/步 - 损失: 0.2471 - 稀疏分类准确率: 0.9019 - 验证损失: 0.3060 - 验证稀疏分类准确率: 0.8748
<keras.src.callbacks.history.History at 0x7f26d032a4d0>