后端服务(服务器)
该服务器通过API提供ktransformers的快速异构推理能力,供外部使用。
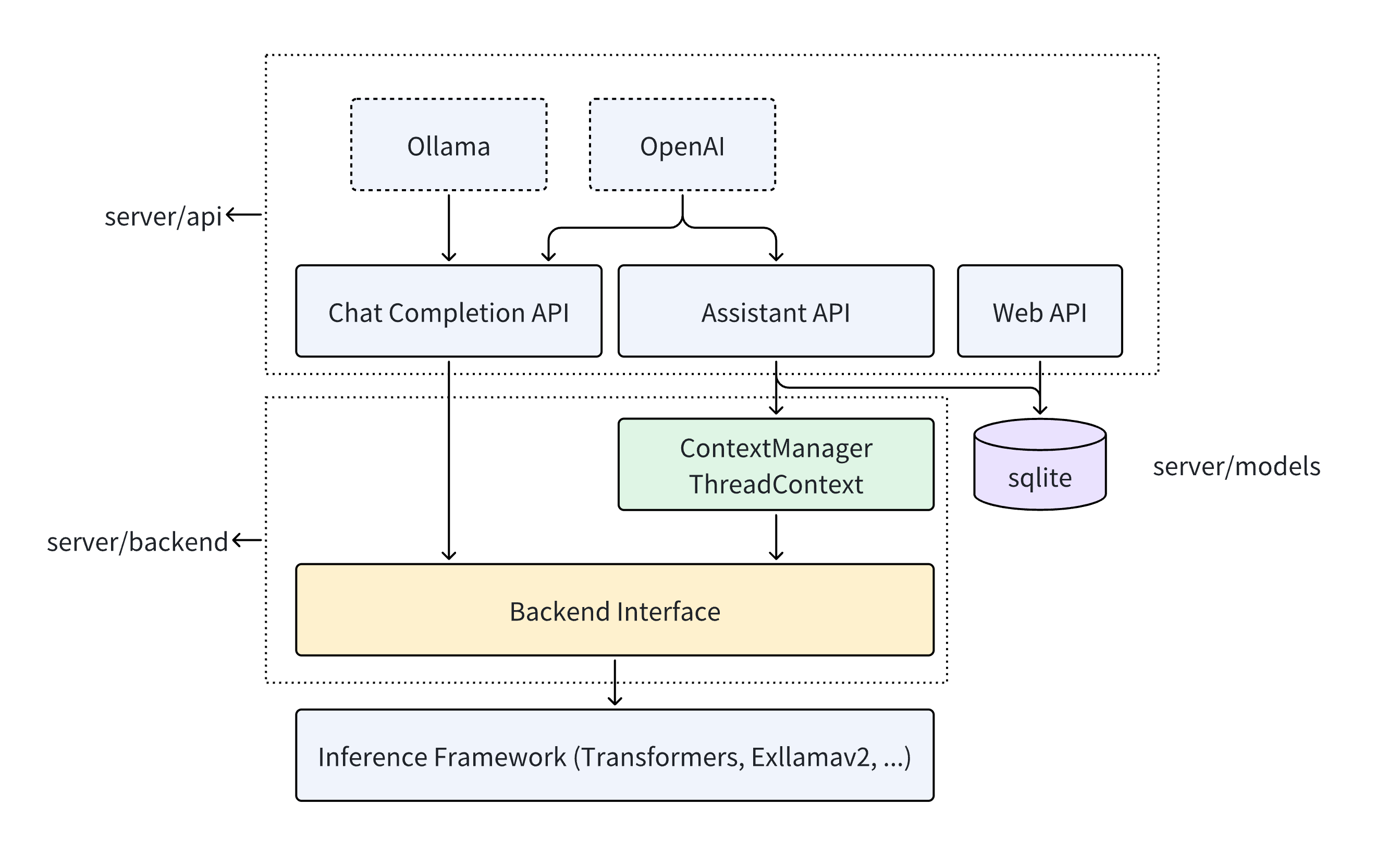
API
该服务器通过RESTful API对外提供模型推理服务,支持两种交互方式:ChatCompletion和Assistant。
- ChatCompletion接口要求用户一次性提供所有历史对话记录,之后模型才会响应。AI服务提供商(如OpenAI)和本地推理框架(如Ollama)都提供ChatCompletion接口。为确保与OpenAI和Ollama兼容,本服务器提供了与其一致的API接口。因此,当前使用OpenAI和Ollama的应用程序可以无缝切换到我们的服务器。例如:如何本地使用Tabby和ktransformers配合236B模型进行代码补全?。
- 该助手适用于需要复用一系列资源并调用模型的应用场景。例如在教育类应用中,开发者可以创建一个名为"二年级数学老师"的助手,设置初始提示语("你是一位经验丰富的二年级数学老师..."),并上传相关资料(二年级数学教材)。创建助手后,应用需要创建一个Thread来存储用户与模型之间的对话(Message)。调用模型时,应用会创建一个Run来获取助手的响应。与ChatCompletion相比,支持助手的服务端处理了对话上下文复用和多轮对话的问题,使得复杂场景下的模型调用更加便捷。OpenAI Assistant API引入了这种助手接口,服务端提供了一致的API。
这些API定义位于server/api中,它们的具体用法可以查看这里。
集成模型推理框架
服务器使用ktransformers进行模型调用和推理。它还支持其他推理框架,例如已经支持的transformers,并计划支持exllamav2。这些功能在server/backend中实现。
这些框架的模型推理功能被抽象成一个基类BackendInterfaceBase。该类包含一个函数:inference。它以历史对话信息messages作为输入,并返回模型的文本结果。inference函数采用异步生成器设计,允许服务器以流式方式返回模型响应。
class BackendInterfaceBase:
async def inference(self, messages, **kwargs)->AsyncIterator[str]:
...
该推理函数天然实现了ChatCompletion的功能,因为其输入和输出分别是历史对话和模型响应。因此,ChatCompletion API可以直接调用该推理函数来完成模型推理。
Assistant比ChatCompletion更复杂,需要服务器存储Assistant的相关状态并适当调用推理函数。服务器在数据库中维护一组Assistant逻辑,存储由应用程序创建的Assistants、Threads和Messages。在内存中,服务器为每个Thread维护一个ThreadContext,收集与每个Thread的Assistant相关的信息等。当用户发送新Message时,服务器调用ThreadContext的get_local_messages函数获取消息,然后调用推理函数获取推理结果。
class MyThreadContext(ThreadContext):
def get_local_messages(self):
...
由于不同模型推理框架具有不同的历史对话输入格式,ThreadContext和BackendInterface需要配对使用。除了自带的ktransformers外,Server还支持transformers。如需集成其他模型推理框架,请参考transformers.py中TransformersInterface和TransformersThreadContext的实现。