教程:异构和本地 MoE 推理
DeepSeek-(代码)-V2是一系列强大的专家混合(MoE)模型,具有总共2360亿个参数,每个token激活210亿个参数。该模型在各项基准测试中表现出了显著的推理能力,使其成为当前最佳(SOTA)开放模型之一,性能几乎与GPT-4相当。DeepSeek-R1使用与DeepSeek-V2类似的架构,但参数数量更大。
此外,与之前采用传统注意力机制如分组查询注意力(GQA)的模型不同,DeepSeek-V2 采用了一种新颖的多头潜在注意力(MLA)。这一创新显著减少了推理过程中所需的KV缓存大小,提高了效率。
然而,尽管它的效率很高,在个人计算机上运行如此大的模型似乎不太实际。DeepSeek-V2 的官方文档指出,标准推理操作需要八个 80GB 的 GPU,甚至缩减版的 Q4_k_m 版本也至少需要两个 80GB 的 GPU。这些要求超出了大多数个人研究人员和小团队的能力范围。
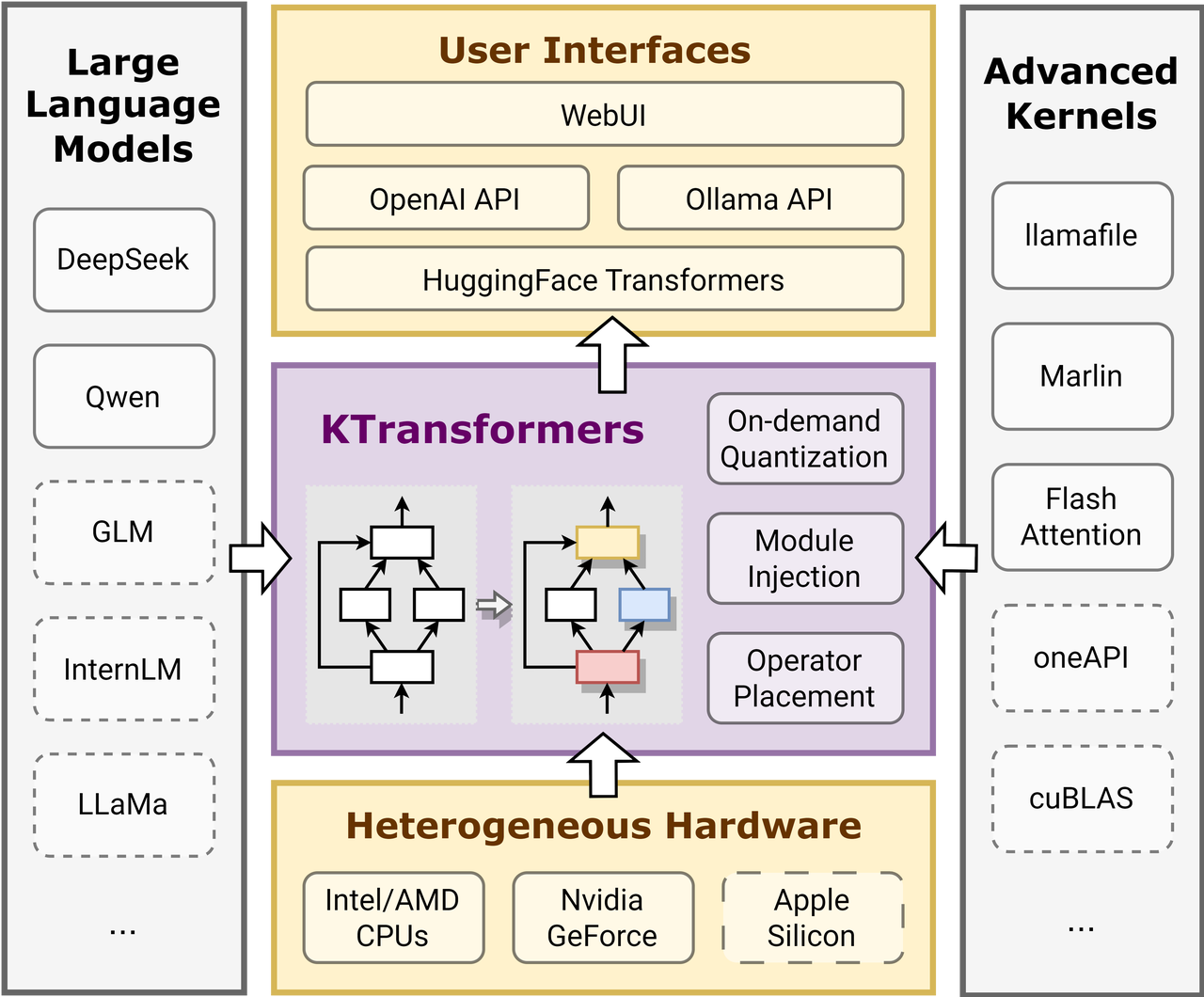
尽管如此,通过采用几种先进的优化技术,我们成功地在仅有21GB显存和136GB内存的桌面计算机上运行了这个庞大的模型。在本文中,我们概述了所使用的具体优化,并提供了如何使用KTransformers实现这些策略的详细教程。
应用的优化
优化的MLA操作符
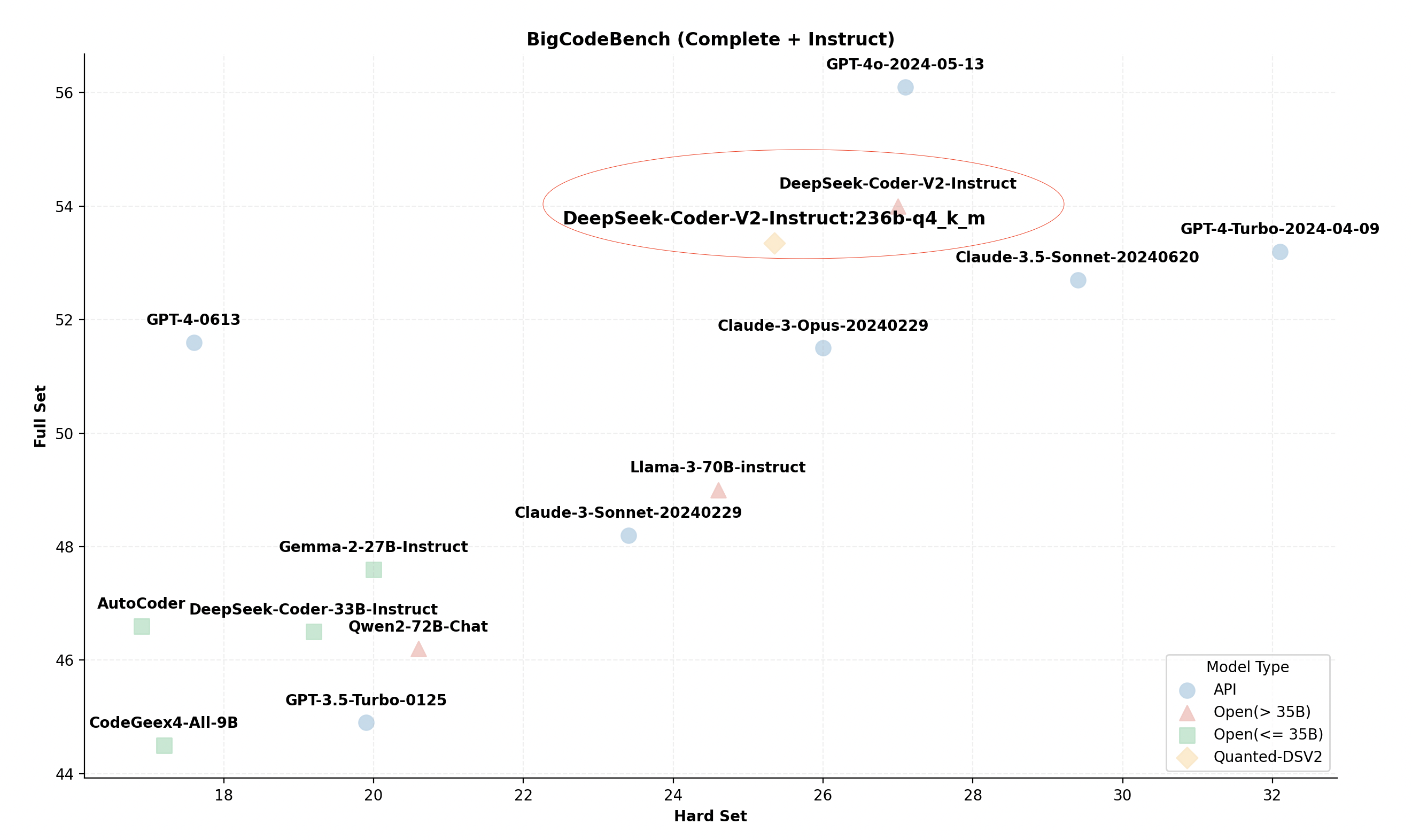
下图提供了DeepSeek-V2架构的简要概述。在其注意力层的核心,DeepSeek-V2引入了一种新颖的MLA运算符,该运算符使用一种共同的联合压缩表示来表示键值对的头,这在效率提升方面具有重要潜力。然而,MLA运算符的官方开源实现明确地解压缩了这种压缩表示,并缓存了解压缩后的键值对。这个过程不仅增大了KV缓存的大小,而且还降低了推理性能。
为了真正利用MLA的好处,我们实施了一个用于推理的优化版本。根据其原始论文,我们将解压矩阵直接吸收到q_proj和out_proj权重中。因此,压缩表示在计算注意力时无需解压。这一调整显著减少了KV缓存的大小,并提高了该操作符的计算强度,从而极大地优化了GPU计算能力的利用。
高级量化核
原始的DeepSeek-V2模型将其参数存储为BF16格式,消耗大约470GB的原始存储空间。这超过了主流台式计算机可用的RAM容量。为了解决这个问题,我们利用了成熟的GGUF社区的量化权重,以简化用户的过程。然而,量化数据类型通常不被高度优化的BLAS包支持。因此,原始HuggingFace Transformers的Torch实现必须在处理之前将这些张量解量化为支持的数据类型,这引入了不必要的计算开销,并增加了内存流量。为此,我们结合了先进的内核,直接在量化数据类型上操作,从而优化推理性能。
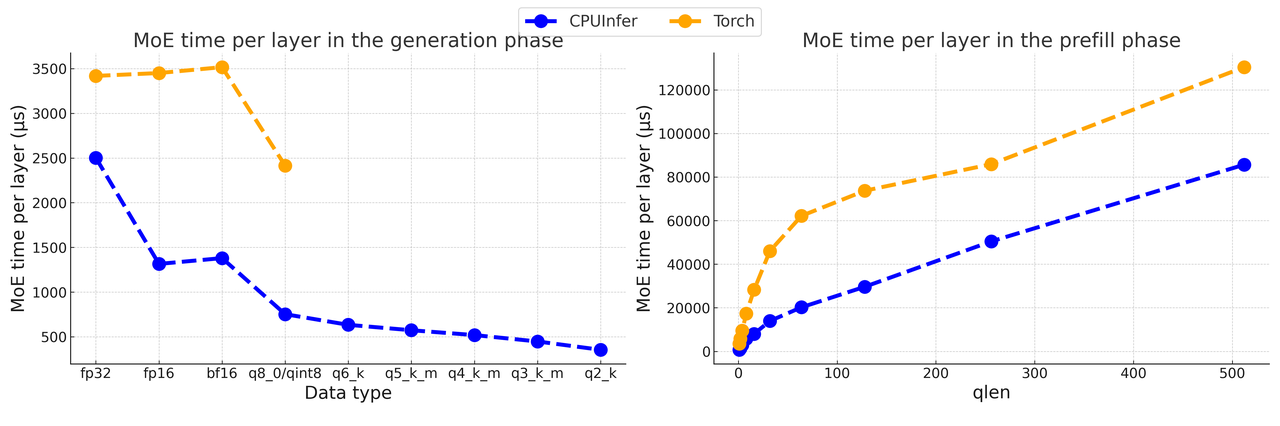
在当前版本的 KTransformers 中,我们使用 Marlin 进行 GPU 内核,使用 llamafile 进行 CPU 内核。这些内核特别设计用于利用现代 GPU 架构和现代 CPU 指令扩展,如 AVX512-BF16(AMD Zen4 或更新版本)和 AVX-VNNI(Intel Alder Lake 或更新版本),这些都是为量化数据类型和机器学习工作负载量身定制的。我们还使用专家并行和其他优化用于基于 llamafile 的 CPU MOE 推理,并将其称为 CPUInfer。如图 2 所示(引用自 Marlin),与相应的 Torch 对应物相比,Marlin 可以实现接近理想的 3.87 倍加速。如下面的图所示,我们的微基准测试表明,使用 CPUInfer 进行推理比在低位表示中使用 Torch 的速度快数倍。请注意,在实际推理中,例如使用 transformers 时,Torch 基线使用 BF16 或 FP16 作为线性权重,这会占用更多的内存资源,或者由于去量化使用量化权重时会更慢。

算术强度引导卸载
将模型的所有2360亿个参数存储在GPU VRAM中显然对本地用户来说不切实际。因此,我们有策略地仅在GPU上存储计算最密集的参数。例如,在我们的优化之后,MLA操作符包含128个头部,并具有共享的压缩键值表示,显示出512的算术强度。这使它成为最密集的操作符,特别是在较小的推理批量大小期间。因此,它被分配到GPU上,以利用张量核心的强大能力。
另一方面,如图1所示,DeepSeek-V2中的每个变压器块包含160个专家混合(MoE)专家,占总参数的96%。然而,MoE路由器仅为每个令牌激活这160个专家中的6个,这意味着在解码阶段仅利用了3.75%的MoE参数。在批次大小为1的情况下,MoE操作的算术强度大约为0.075。因此,这个主要涉及批处理的一般矩阵-向量乘法(GEMV)操作可以高效地由CPU处理。
遵循按照运算符的算术强度排列所有运算符,并尽可能将最强度的运算符放置在GPU中的原则,我们优先将MoE参数和词嵌入计算放置在CPU端,以利用其更大的内存容量。与此同时,剩余的参数,包括共享专家、注意模块中的投影和MLA,被存储在GPU的VRAM中。由于这些参数被每个标记访问,它们在GPU上的位置最大化了高内存带宽的好处。这种配置使得使用Q4_K_M版本时VRAM使用量约为20.7 GB,并在136GB DRAM内存请求的情况下,这在本地桌面上是可行的。此外,位置可以根据实际配置进行调整,遵循相同原则。
此外,作为一个可扩展的框架,KTransformers 旨在在未来的版本中支持更高级的操作符,不断增强其有效处理多样化工作负载的能力。
YAML 模板
要在KTransformers中实现上述优化,用户需要编写一个包含优化规则的YAML文件。 KTransformers将遍历模型的所有子模块,匹配YAML规则文件中指定的规则,并用指定的高级模块替换它们。
具体而言,使用以下规则:
- 用我们的 优化的 MLA Operator 替换 Attention 模块。
- 用使用Llamafile的CPUInfer内核替换路由专家。
- 用 Marlin 内核替换所有不属于注意力的线性模块。
MLA
对于注意力模块注入,我们只需使用正则表达式匹配在Transformers中使用的模块名称,并将其替换为我们预先实现的模块。YAML规则如下。
- match:
name: "^model\\.layers\\..*\\.self_attn$" # regular expression
replace:
class: ktransformers.operators.attention.KDeepseekV2Attention # optimized MLA implementation
正如我们所看到的,YAML文件中的每条规则有两个部分: match 和 replace。匹配部分指定应替换哪个模块,而替换部分指定要与初始化关键字一起注入到模型中的模块。
路由专家
对于路由专家,我们注入的模块是CPUInfer的一个封装,即KTransformersExperts。在这个封装中有几个实现,我们需要指定关键字来告诉封装我们想使用哪个实现以及我们打算如何使用它。
在KTransformers中,一些模型在预填充和生成过程中表现出不同的行为以获得更好的性能。KTransformersExperts就是其中之一。所有这些特殊模块都有一个device关键字,描述模块应该在哪个设备上初始化。其他关键字指定预填充和生成过程中的行为,并可能在使用不同注入模块时有所不同。在这里,我们指定在预填充和生成过程中希望使用哪种实现以及输出应该在哪个设备上。请注意,仅当启用层级预填充时,我们才使用这些参数;否则,预填充将使用与生成相同的配置进行。
在Transformer的原始实现中,MoE是使用 nn.ModuleList 实现的。我们不希望KTransformers迭代列表中的所有子模块,因此我们在此规则中设置 recursive: False 以防止递归注入到当前模块的子模块中。以下是YAML规则:
- match:
name: "^model\\.layers\\..*\\.mlp\\.experts$"
replace:
class: ktransformers.operators.experts.KTransformersExperts # custom MoE Kernel with expert parallelism
device: "cpu" # device to load this module on initialization
kwargs:
prefill_device: "cuda"
prefill_op: "KExpertsTorch"
generate_device: "cpu"
generate_op: "KExpertsCPU"
out_device: "cuda"
recursive: False # don't recursively inject submodules of this module
如果我们将专家列表作为自定义模块注入,我们不能将nn.ModuleList中的接口用作默认。我们需要更改FFN模块中的前向函数。最简单的方法是使用自定义前向函数实现一个新模块并注入它。我们已经实现了新模块,注入可以通过简单地添加注入规则来完成。我们可以使用class而不是name来匹配将被替换的模块。以下是YAML规则:
- match:
class: ktransformers.models.modeling_deepseek.DeepseekV2MoE
replace:
class: ktransformers.operators.experts.KDeepseekV2MoE # MLP module with custom forward function
其他线性模块
对于剩余的线性模块,我们希望使用我们的量化内核。然而,我们不想在MLA操作符中注入线性,因为我们目前不知道在MLA中使用量化的效果。 因此,我们可以更改我们的正则表达式,并在规则的匹配部分添加类检查。只有同时匹配名称和类的模块才会被注入。 我们还需要转移一些与专家注入类似的关键字。以下是YAML规则:
- match:
name: "^model\\.layers\\.(?!.*self_attn).*$" # regular expression
class: torch.nn.Linear # only match modules matching name and class simultaneously
replace:
class: ktransformers.operators.linear.KTransformersLinear # optimized Kernel on quantized data types
kwargs:
generate_device: "cuda"
prefill_device: "cuda"
generate_op: "KLinearMarlin"
prefill_op: "KLinearTorch"
预计算缓冲区
原始模型在元设备上初始化。旋转嵌入模块在初始化时预先计算一些缓冲区,在使用元设备时没有影响,也不会计算任何内容。因此,我们需要在加载模型时计算这些缓冲区。为了方便,我们用自定义模块注入了旋转嵌入模块,该模块在加载时进行预计算。以下是YAML规则:
- match:
class: ktransformers.models.modeling_deepseek.DeepseekV2YarnRotaryEmbedding
replace:
class: ktransformers.operators.RoPE.YarnRotaryEmbedding
包装您的自定义模块
我们已经实现了一些模块,但您可能需要使用 KTransformers 注入您的自定义模块。您需要做的唯一事情是包装您的自定义模块并编写 YAML 文件。我们提供了一个基本操作符,指定注入模块应该具备的接口。您只需从该模块继承并根据需要更改 __init__、forward 或 load 函数。
- 基类操作符的
__init__函数维护了KTransformers框架注入和执行所需的信息。要重写此函数,子类模块需要在自己的初始化器中调用基类操作符的__init__函数。 - 该
forward函数是在推理期间被调用的torch中的一个函数,模块作者可以自由地实现更高的性能。 load函数用于加载该模块的所有参数。默认实现是调用所有子模块的load函数。您可以修改此函数以自定义其加载方法并明确控制子模块的加载。