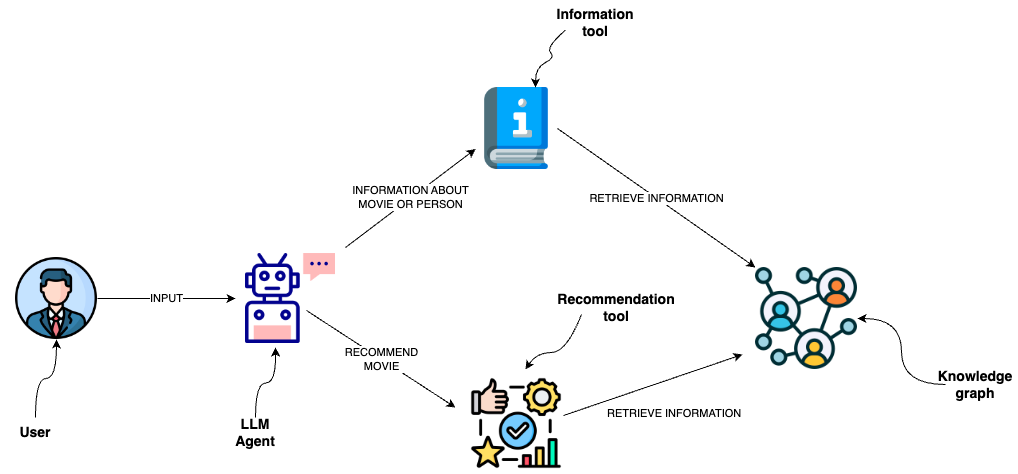
如何在图数据库上添加语义层
您可以使用数据库查询从图数据库(如 Neo4j)中检索信息。
一种选择是使用LLMs生成Cypher语句。
虽然这种选择提供了出色的灵活性,但解决方案可能会脆弱,并且无法始终生成精确的Cypher语句。
我们可以在语义层中实现Cypher模板作为工具,LLM代理可以与之交互,而不是生成Cypher语句。
设置
首先,获取所需的软件包并设置环境变量:
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
注意:您可能需要重新启动内核以使用更新后的软件包。
在本指南中,我们默认使用OpenAI模型,但您可以将其替换为您选择的模型提供商。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# 取消下面的注释以使用LangSmith。非必需。
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
········
接下来,我们需要定义Neo4j凭据。
按照这些安装步骤设置Neo4j数据库。
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
以下示例将创建与Neo4j数据库的连接,并使用关于电影及其演员的示例数据填充它。
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# 导入电影信息
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
[]
使用Cypher模板创建自定义工具
语义层由各种工具组成,LLM可以使用这些工具与知识图交互。
它们可以具有各种复杂性。您可以将语义层中的每个工具视为一个函数。
我们将要实现的功能是检索有关电影或其演员的信息。
from typing import Optional, Type
# 导入通用所需的内容
from langchain.pydantic_v1 import BaseModel, Field
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
description_query = """
MATCH (m:Movie|Person)
WHERE m.title CONTAINS $candidate OR m.name CONTAINS $candidate
MATCH (m)-[r:ACTED_IN|HAS_GENRE]-(t)
WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as names
WITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as types
WITH m, collect(types) as contexts
WITH m, "type:" + labels(m)[0] + "\ntitle: "+ coalesce(m.title, m.name)
+ "\nyear: "+coalesce(m.released,"") +"\n" +
reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as context
RETURN context LIMIT 1
"""
def get_information(entity: str) -> str:
try:
data = graph.query(description_query, params={"candidate": entity})
return data[0]["context"]
except IndexError:
return "No information was found"
您可以看到我们已经定义了用于检索信息的Cypher语句。
因此,我们可以避免生成Cypher语句,并且只需让LLM代理填充输入参数。
为了向LLM代理提供有关何时使用工具及其输入参数的附加信息,我们将函数封装为工具。
from typing import Optional, Type
# 导入通用所需的内容
from langchain.pydantic_v1 import BaseModel, Field
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
class InformationInput(BaseModel):
entity: str = Field(description="问题中提到的电影或人物")
class InformationTool(BaseTool):
name = "Information"
description = (
"当您需要回答有关各种演员或电影的问题时很有用"
)
args_schema: Type[BaseModel] = InformationInput
def _run(
self,
entity: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""使用该工具。"""
return get_information(entity)
async def _arun(
self,
entity: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""异步使用该工具。"""
return get_information(entity)
OpenAI 代理
LangChain 表达语言使得定义一个与语义层上的图数据库进行交互的代理变得非常方便。
from typing import List, Tuple
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
tools = [InformationTool()]
llm_with_tools = llm.bind(functions=[convert_to_openai_function(t) for t in tools])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that finds information about movies and recommends them. If tools require follow up questions, make sure to ask the user for clarification. Make sure to include any available options that need to be clarified in the follow up questions Do only the things the user specifically requested. ",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
def _format_chat_history(chat_history: List[Tuple[str, str]]):
buffer = []
for human, ai in chat_history:
buffer.append(HumanMessage(content=human))
buffer.append(AIMessage(content=ai))
return buffer
agent = (
{
"input": lambda x: x["input"],
"chat_history": lambda x: _format_chat_history(x["chat_history"]) if x.get("chat_history") else [],
"agent_scratchpad": lambda x: format_to_openai_function_messages(x["intermediate_steps"]),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "Who played in Casino?"})
{'input': 'Who played in Casino?',
'output': 'The movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
以上是一个使用 OpenAI 代理的示例。该代理可以根据用户的输入在语义层上的图数据库中查找信息,并给出推荐。在这个示例中,用户询问了电影《Casino》的演员阵容,代理通过调用 Information 工具返回了相关信息。
