断言与指标
断言用于将 LLM 输出与预期值或条件进行比较。虽然运行评估不需要断言,但它们是自动化分析的有用方式。
可以使用不同类型的断言以各种方式验证输出,例如检查相等性、JSON 结构、相似性或自定义函数。
在机器学习中,“准确性”是衡量模型在所有预测中正确预测比例的指标。使用 promptfoo,准确性定义为产生预期或所需输出的提示的比例。
使用断言
要在测试用例中使用断言,请在测试用例中添加一个 assert 属性,其中包含一个断言对象数组。每个断言对象应具有一个 type 属性,指示断言类型,以及该断言类型所需的其他属性。
示例:
tests:
- description: '测试输出是否等于预期值'
vars:
example: 'Hello, World!'
assert:
- type: equals
value: 'Hello, World!'
断言属性
| 属性 | 类型 | 必需 | 描述 |
|---|---|---|---|
| type | string | 是 | 断言类型 |
| value | string | 否 | 预期值,如果适用 |
| threshold | number | 否 | 阈值,仅适用于某些类型,如 similar、cost、javascript、python |
| weight | number | 否 | 断言的权重。默认为 1.0 |
| provider | string | 否 | 某些断言(相似性、llm-rubric、model-graded-*)需要 LLM 提供者 |
| rubricPrompt | string | string[] | 否 | 模型评级的 LLM 提示 |
通过断言集分组断言
可以使用 assert-set 将断言分组在一起。
示例:
tests:
- description: '测试输出是否廉价且快速'
vars:
example: 'Hello, World!'
assert:
- type: assert-set
assert:
- type: cost
threshold: 0.001
- type: latency
threshold: 200
在上面的示例中,如果 assert-set 中的所有断言都通过,则整个 assert-set 通过。
在某些情况下,您可能只需要一定数量的断言通过。这里可以使用 threshold。
示例 - 如果两个断言中的一个需要通过或 50%:
tests:
- description: '测试输出是否廉价或快速'
vars:
example: 'Hello, World!'
assert:
- type: assert-set
threshold: 0.5
assert:
- type: cost
threshold: 0.001
- type: latency
threshold: 200
断言集属性
| 属性 | 类型 | 必需 | 描述 |
|---|---|---|---|
| type | string | 是 | 必须是 assert-set |
| assert | array of asserts | 是 | 为该集运行的断言 |
| threshold | number | 否 | 断言集的成功阈值。例如,4 个等权重断言中需要 1 个通过。阈值应为 0.25 |
| weight | number | 否 | 在测试断言中对该断言集的权重。默认为 1.0 |
| metric | string | 否 | 该断言集在测试中的指标名称 |
断言类型
确定性评估指标
这些指标是针对 LLM 输出运行的程序化测试。查看所有详细信息
| 断言类型 | 返回 true 如果... |
|---|---|
| contains-all | 输出包含所有子字符串列表 |
| contains-any | 输出包含任意列出的子字符串 |
| contains-json | 输出包含有效 JSON(可选 JSON 模式验证) |
| contains-sql | 输出包含有效 SQL |
| contains-xml | 输出包含有效 XML |
| contains | 输出包含子字符串 |
| cost | 推理成本低于阈值 |
| equals | 输出完全匹配 |
| icontains-all | 输出包含所有子字符串列表,不区分大小写 |
| icontains-any | 输出包含任意列出的子字符串,不区分大小写 |
| icontains | 输出包含子字符串,不区分大小写 |
| is-json | 输出是有效 JSON(可选 JSON 模式验证) |
| is-sql | 输出是有效 SQL |
| is-xml | 输出是有效 XML |
| is-valid-openai-function-call | 确保函数调用匹配函数的 JSON 模式 |
| is-valid-openai-tools-call | 确保所有工具调用匹配工具的 JSON 模式 |
| javascript | 提供的 JavaScript 函数验证输出 |
| latency | 延迟低于阈值(毫秒) |
| levenshtein | Levenshtein 距离低于阈值 |
| perplexity | 困惑度低于阈值 |
| perplexity-score | 标准化困惑度 |
| python | 提供的 Python 函数验证输出 |
| regex | 输出匹配正则表达式 |
| starts-with | 输出以字符串开头 |
| webhook | 提供的 webhook 返回 {pass: true} |
| rouge-n | Rouge-N 分数高于给定阈值 |
每种测试类型都可以通过在前面加上 not- 来否定。例如,not-equals 或 not-regex。
模型辅助评估指标
这些指标是模型辅助的,依赖于大型语言模型(LLMs)或其他机器学习模型。
| 断言类型 | 方法 |
|---|---|
| 相似性 | 嵌入向量和余弦相似度高于阈值 |
| 分类器 | 通过分类器运行 LLM 输出 |
| llm-rubric | 使用语言模型对输出进行评分,LLM 输出符合给定的评分标准 |
| 答案相关性 | 确保 LLM 输出与原始查询相关 |
| 上下文忠实度 | 确保 LLM 输出使用上下文 |
| 上下文召回率 | 确保真实答案出现在上下文中 |
| 上下文相关性 | 确保上下文与原始查询相关 |
| 事实性 | 使用 OpenAI 评估中的事实性方法,确保 LLM 输出符合给定的事实 |
| 模型�评分封闭问答 | 使用 OpenAI 评估中的封闭问答方法,确保 LLM 输出符合给定标准 |
| 选择最佳 | 比较多个输出并选择最佳的一个 |
加权断言
在某些情况下,您可能希望根据其重要性为断言分配不同的权重。weight 属性是一个数字,用于确定断言的相对重要性。默认权重为 1。
测试用例的最终得分是所有断言得分的加权平均值,其中权重是断言的 weight 值。
以下是一个示例:
tests:
assert:
- type: equals
value: 'Hello world'
weight: 2
- type: contains
value: 'world'
weight: 1
在这个例子中,equals 断言的重要性是 contains 断言的两倍。
如果 LLM 输出是 Goodbye world,equals 断言失败但 contains 断言通过,最终得分是 0.33(1/3)。
设置分数要求
测试用例支持一个可选的 threshold 属性。如果设置,测试用例的通过/失败状态由所有断言的加权得分是否超过阈值决定。
例如:
tests:
threshold: 0.5
assert:
- type: equals
value: 'Hello world'
weight: 2
- type: contains
value: 'world'
weight: 1
如果 LLM 输出 Goodbye world,equals 断言失败但 contains 断言通过,最终得分是 0.33。由于这低于 0.5 的阈值,测试用例失败。如果阈值降低到 0.2,测试用例将成功。
从外部文件加载断言
原始文件
可以使用 file:// 语法直接从文件加载断言的 value:
- assert:
- type: contains
value: file://gettysburg_address.txt
Javascript
如果文件以 .js 结尾,将执行 Javascript:
- assert:
- type: javascript
value: file://path/to/assert.js
类型定义为:
type AssertionResponse = string | boolean | number | GradingResult;
type AssertFunction = (output: string, context: { vars: Record<string, string> }) => AssertResponse;
参见 GradingResult 定义。
以下是一个示例 assert.js:
module.exports = (output, { vars }) => {
console.log(`Received ${output} using variables ${JSON.stringify(vars)}`);
return {
pass: true,
score: 0.5,
reason: 'Some custom reason',
};
};
你也可以在非javascript类型的断言中使用Javascript文件。例如,在contains断言中使用Javascript文件将检查输出是否包含Javascript返回的字符串。
Python
如果文件以.py结尾,将执行Python代码:
- assert:
- type: python
value: file://path/to/assert.py
断言期望的输出是bool、float或JSON格式的GradingResult。
例如:
import sys
import json
output = sys.argv[1]
context = json.loads(sys.argv[2])
# 使用`output`和`context['vars']`来确定结果...
print(json.dumps({
'pass': False,
'score': 0.5,
'reason': '一些自定义原因',
}))
从CSV加载断言
测试文件是一种可选格式,允许你在主配置文件之外指定测试用例。
要在变量文件中的测试用例添加断言,请使用特殊的__expected列。
以下是一个示例tests.csv:
| text | __expected |
|---|---|
| Hello, world! | Bonjour le monde |
| Goodbye, everyone! | fn:output.includes('Au revoir'); |
| I am a pineapple | grade:doesn't reference any fruits besides pineapple |
所有断言类型都可以在__expected中使用。该列仅支持一个断言。
is-json和contains-json直接支持,不需要任何值fn表示javascript类型。例如:fn:output.includes('foo')file://表示相对于配置的外部文件。例如:file://custom_assertion.py或file://customAssertion.jssimilar接受一个阈值值。例如:similar(0.8):hello worldgrade表示llm-rubric。例如:grade: does not mention being an AI- 默认情况下,
__expected将使用equals类型
当提供__expected字段时,评估摘要中的成功和失败统计将基于是否满足预期标准。
要运行多个断言,请使用列名__expected1、__expected2、__expected3等。
对于更高级的测试用例,我们建议使用Jest或Vitest或Mocha等测试框架,并使用promptfoo作为库。
使用模板重用断言
如果你有一组想要应用于多个测试用例的常见断言,可以创建断言模板并在配置中重复使用它们。
assertionTemplates:
containsMentalHealth:
type: javascript
value: output.toLowerCase().includes('mental health')
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- localai:chat:vicuna
tests:
- vars:
input: Tell me about the benefits of exercise.
assert:
- $ref: "#/assertionTemplates/containsMentalHealth"
- vars:
input: How can I improve my well-being?
assert:
- $ref: "#/assertionTemplates/containsMentalHealth"
在这个例子中,containsMentalHealth断言模板在配置文件顶部定义,然后在两个测试用例中重复使用。这种方法有助于保持一致性并减少配置中的重复。
定义命名指标
每个断言都支持一个metric字段,允许你按自己喜欢的方式标记结果。使用此功能将相关断言组合成聚合指标。
例如,这些断言将结果聚合到两个指标Tone和Consistency中。
tests:
- assert:
- type: equals
value: Yarr
metric: Tone
- assert:
- type: icontains
value: grub
metric: Tone
- assert:
- type: is-json
metric: Consistency
- assert:
- type: python
value: max(0, len(output) - 300)
metric: Consistency
- type: similar
value: Ahoy, world
metric: Tone
- assert:
- type: llm-rubric
value: Is spoken like a pirate
metric: Tone
这些指标将在UI中显示:
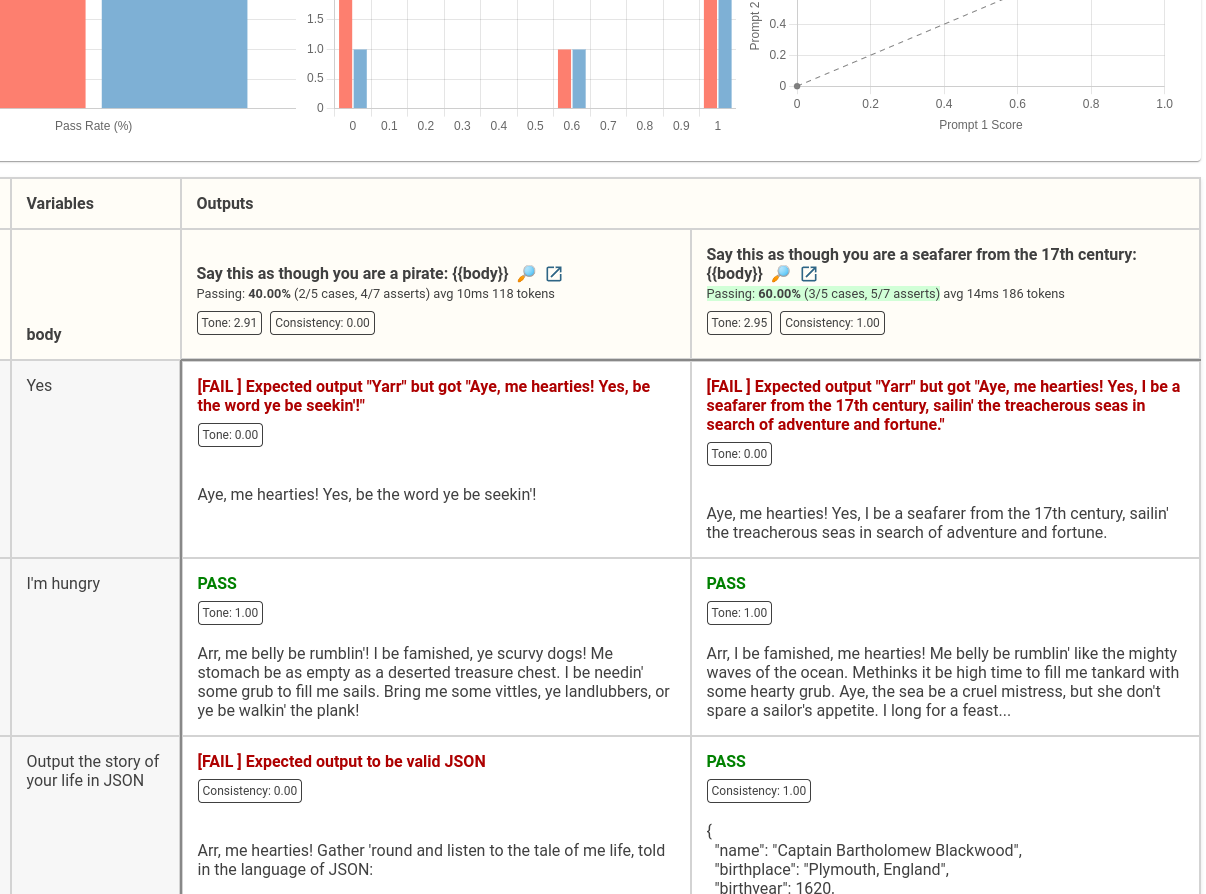
参见命名指标示例。
创建派生指标
派生指标,也称为复合或计算指标,是基于其他指标在运行时计算的。它们被聚合并显示为命名指标(见上文)。
派生指标在所有单个测试评估完成后计算。它们可以使用数学表达式或自定义函数定义,这些函数聚合或转换在测试期间收集的命名分数。
配置派生指标
要在测试套件中配置派生指标,您需要向 TestSuite 对象添加一个 derivedMetrics 数组。该数组中的每个条目都是一个对象,用于指定指标的名称和用于计算该指标的公式或函数。
用法
每个派生指标具有以下属性:
- name: 指标的名称。这用于输出结果中的标识符。
- value: 指标的计算方法。这可以是一个表示数学表达式的字符串,或者是一个函数,该函数接受当前分数和评估上下文作为参数,并返回一个数值。
示例
以下是如何在测试套件配置中定义派生指标的示例:
derivedMetrics:
- name: 'EfficiencyAdjustedPerformance'
value: '(PerformanceScore / InferenceTime) * EfficiencyFactor'
# - ...
在此示例中,EfficiencyAdjustedPerformance 使用一个简单的数学表达式计算,该表达式使用了现有的命名分数。
需要了解:
- 派生指标按提供的顺序计算。您可以引用之前的派生指标。
- 为了引用基本指标,您必须为其命名(参见上面的命名分数)。
- 为了在数学表达式中使用,命名分数不能包含任何空格或特殊字符。
直接对输出运行断言
如果您已经有 LLM 输出并希望对其运行断言,eval 命令支持独立的断言文件。
将您的输出放入 JSON 字符串数组中,例如 output.json:
["Hello world", "Greetings, planet", "Salutations, Earth"]
并创建一个断言列表 (asserts.yaml):
- type: icontains
value: hello
- type: javascript
value: 1 / (output.length + 1) # 偏好较短的输出
- type: model-graded-closedqa
value: 确保输出包含问候语
然后运行 eval 命令:
promptfoo eval --assertions asserts.yaml --model-outputs outputs.json
标记输出
Promptfoo 接受稍微复杂的 JSON 结构,其中包括模型的输出字段 output 和关联的标签字段 tags。这些标签在 Web UI 中显示为逗号分隔的列表。如果您想跟踪某些输出属性,这很有用:
[
{ "output": "Hello world", "tags": ["foo", "bar"] },
{ "output": "Greetings, planet", "tags": ["baz", "abc"] },
{ "output": "Salutations, Earth", "tags": ["def", "ghi"] }
]
处理和格式化输出
如果您需要对输出进行任何处理/格式化,请使用 Javascript 提供者、Python 提供者 或 自定义脚本。