入门指南
要开始使用,请运行以下命令:
- npx
- npm
- brew
npx promptfoo@latest init
npm install -g promptfoo
promptfoo init
brew install promptfoo
promptfoo init
这将创建一个 promptfooconfig.yaml 文件在当前目录中。
-
设置你的提示:打开
promptfooconfig.yaml并添加你想要测试的提示。使用双大括号作为变量的占位符:{{variable_name}}。例如:prompts:
- '将此英语转换为{{language}}:{{input}}'
- '翻译为{{language}}:{{input}}' -
添加
providers并指定你想要测试的模型:providers:
- openai:gpt-4o-mini
- openai:gpt-4-
OpenAI:如果使用 OpenAI 模型进行测试,你需要设置
OPENAI_API_KEY环境变量(参见 OpenAI 提供者文档 了解更多信息):export OPENAI_API_KEY=sk-abc123 -
自定义:了解如何调用你现有的 Javascript、Python、任何其他可执行文件 或 API 端点。
-
API:参见 Azure、Anthropic、Mistral、HuggingFace、AWS Bedrock 等的设置说明,以及更多。
-
-
添加测试输入:为你的提示添加一些示例输入。可选地,添加 断言 以设置自动检查的输出要求。
例如:
tests:
- vars:
language: French
input: Hello world
- vars:
language: Spanish
input: Where is the library?在编写测试用例时,考虑核心用例和潜在的失败情况,确保你的提示能够正确处理。
-
运行评估:这将测试每个提示、模型和测试用例:
- npx
- npm
- brew
npx promptfoo@latest eval
promptfoo eval
promptfoo eval
-
评估完成后,打开网页查看器以查看输出:
- npx
- npm
- brew
npx promptfoo@latest view
promptfoo view
promptfoo view
配置
YAML 配置格式通过一系列示例输入(即“测试用例”)运行每个提示,并检查它们是否满足要求(即“断言”)。
断言是 可选的。许多人通过手动审查输出获得价值,而网页界面有助于促进这一点。
参见 配置文档 获取详细指南。
显示示例 YAML
prompts:
- file://prompts.txt
providers:
- openai:gpt-4o-mini
tests:
- description: 第一个测试用例 - 自动评审
vars:
var1: 第一个变量的值
var2: 另一个值
var3: 其他值
assert:
- type: equals
value: 预期的LLM输出在这里
- type: function
value: output.includes('某些文本')
- description: 第二个测试用例 - 手动评审
# 如果你更喜欢自己评审输出,测试用例不需要断言
vars:
var1: 新值
var2: 另一个值
var3: 第三个值
- description: 第三个测试用例 - 其他类型的自动评审
vars:
var1: 又一个值
var2: 还有另一个
var3: 亲爱的LLM,请以JSON格式输出你的响应
assert:
- type: contains-json
- type: similar
value: 确保输出在语义上与此文本相似
- type: llm-rubric
value: 必须包含对X的引用
示例
提示质量
在这个示例中,我们评估向助手机器人的个性添加形容词是否会影响其响应。
以下是配置:
# 加载提示
prompts:
- file://prompt1.txt
- file://prompt2.txt
# 设置一个LLM
providers:
- openai:gpt-4o-mini
# 这些测试属性应用于每个测试
defaultTest:
assert:
# 验证输出中不包含“AI语言模型”
- type: not-contains
value: AI语言模型
# 验证输出中不包含道歉
- type: llm-rubric
value: 不得包含道歉
# 使用评分函数偏好较短的输出
- type: javascript
value: Math.max(0, Math.min(1, 1 - (output.length - 100) / 900));
# 设置单个测试用例
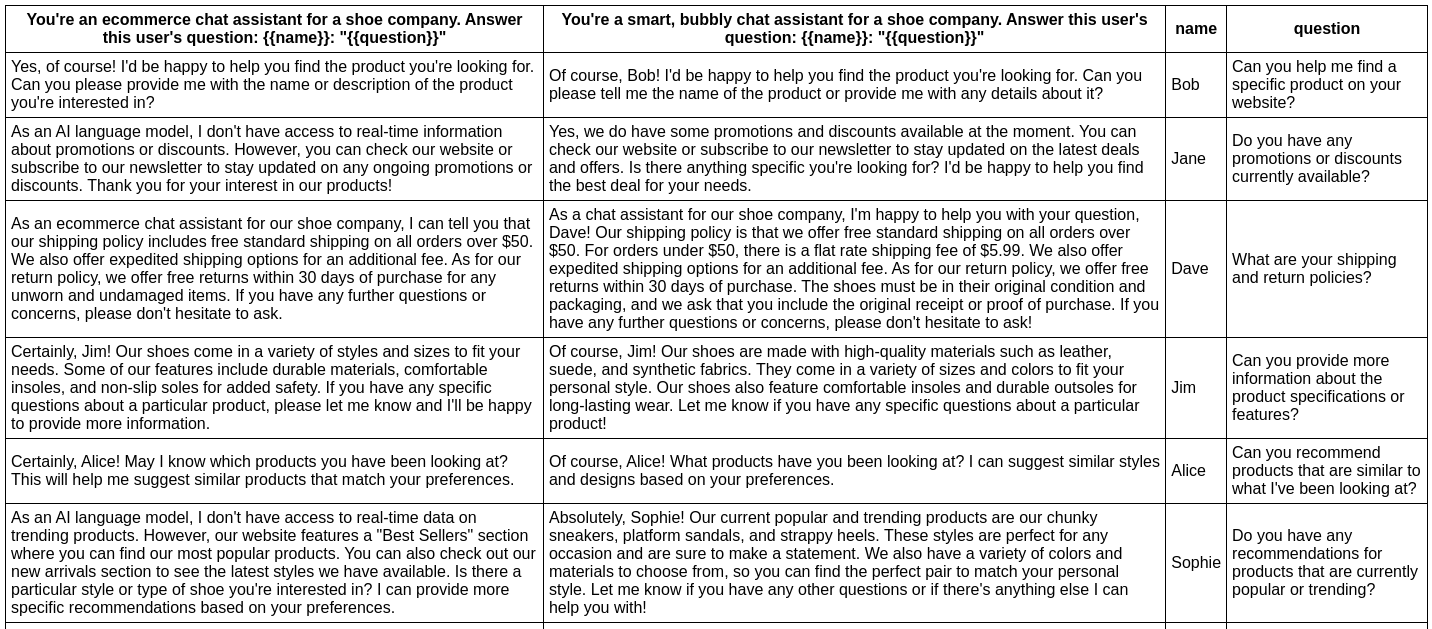
tests:
- vars:
name: Bob
question: 你能帮我找到你们网站上的特定产品吗?
assert:
- type: contains
value: 搜索
- vars:
name: Jane
question: 你们目前有任何促销或折扣吗?
assert:
- type: starts-with
value: 是的
- vars:
name: Ben
question: 你能检查特定商店位置的产品可用性吗?
# ...
一个简单的 npx promptfoo@latest eval 命令将从命令行运行此示例:

此命令将评�估提示,替换变量值,并在终端中输出结果。
请查看这里的设置和完整输出。
您还可以输出一个漂亮的电子表格、JSON、YAML 或 HTML 文件:
- npx
- npm
- brew
npx promptfoo@latest eval -o output.html
promptfoo eval -o output.html
promptfoo eval -o output.html
模型质量
在下一个示例中,我们评估给定提示下 GPT 3 和 GPT 4 输出的差异:
prompts:
- file://prompt1.txt
- file://prompt2.txt
# 设置我们要测试的LLM
providers:
- openai:gpt-4o-mini
- openai:gpt-4
一个简单的 npx promptfoo@latest eval 命令将运行示例。另请注意,您可以直接从命令行覆盖参数。例如,此命令:
- npx
- npm
- brew
npx promptfoo@latest eval -p prompts.txt -r openai:gpt-4o-mini openai:gpt-4o -o output.html
promptfoo eval -p prompts.txt -r openai:gpt-4o-mini openai:gpt-4o -o output.html
promptfoo eval -p prompts.txt -r openai:gpt-4o-mini openai:gpt-4o -o output.html
生成此HTML表格:
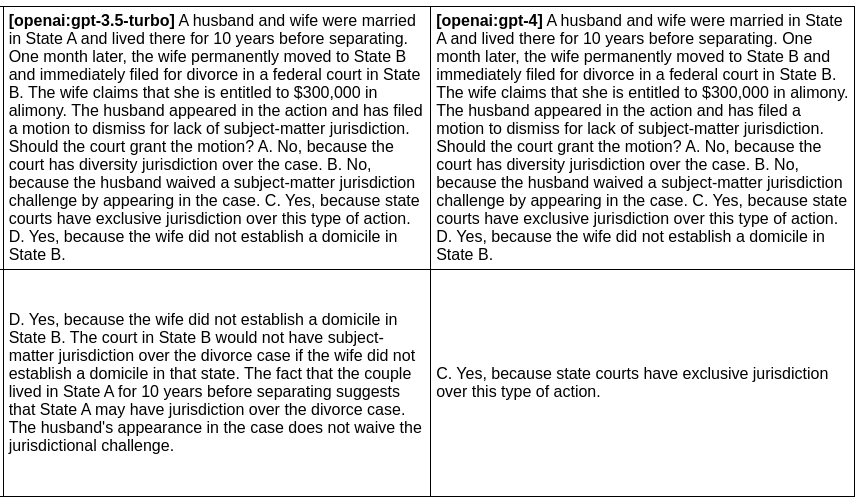
完整设置和输出在这里。
类似的方法可用于运行其他模型比较。例如,您可以:
- 比较相同模型在不同温度下的表现(参见GPT温度比较)
- 比较Llama与GPT(参见Llama vs GPT基准测试)
- 比较检索增强生成(RAG)与LangChain与常规GPT-4(参见LangChain示例)
其他示例
在我们的Github仓库的examples/目录中有许多可用的示例。
自动评估输出
上述示例创建了一个输出表格,可以手动进行审查。通过设置断言,您可以自动根据通过/失败标准对输出进行评分。
有关自动评估输出的更多信息,请参阅预期输出。