选择最佳GPT模型:基于自有数据的基准测试
本指南将引导您如何比较OpenAI的GPT-4o和GPT-4o-mini,这两个模型是目前最强大和有效的GPT模型的有力竞争者。通过此测试框架,您将有机会测试这些模型的推理能力、成本和延迟。
新模型发布时通常在基准测试中表现良好。但通用基准测试适用于通用用例。如果您正在构建一个LLM应用,您应该基于自己的数据评估这些模型,并根据您的特定需求做出明智的决策。
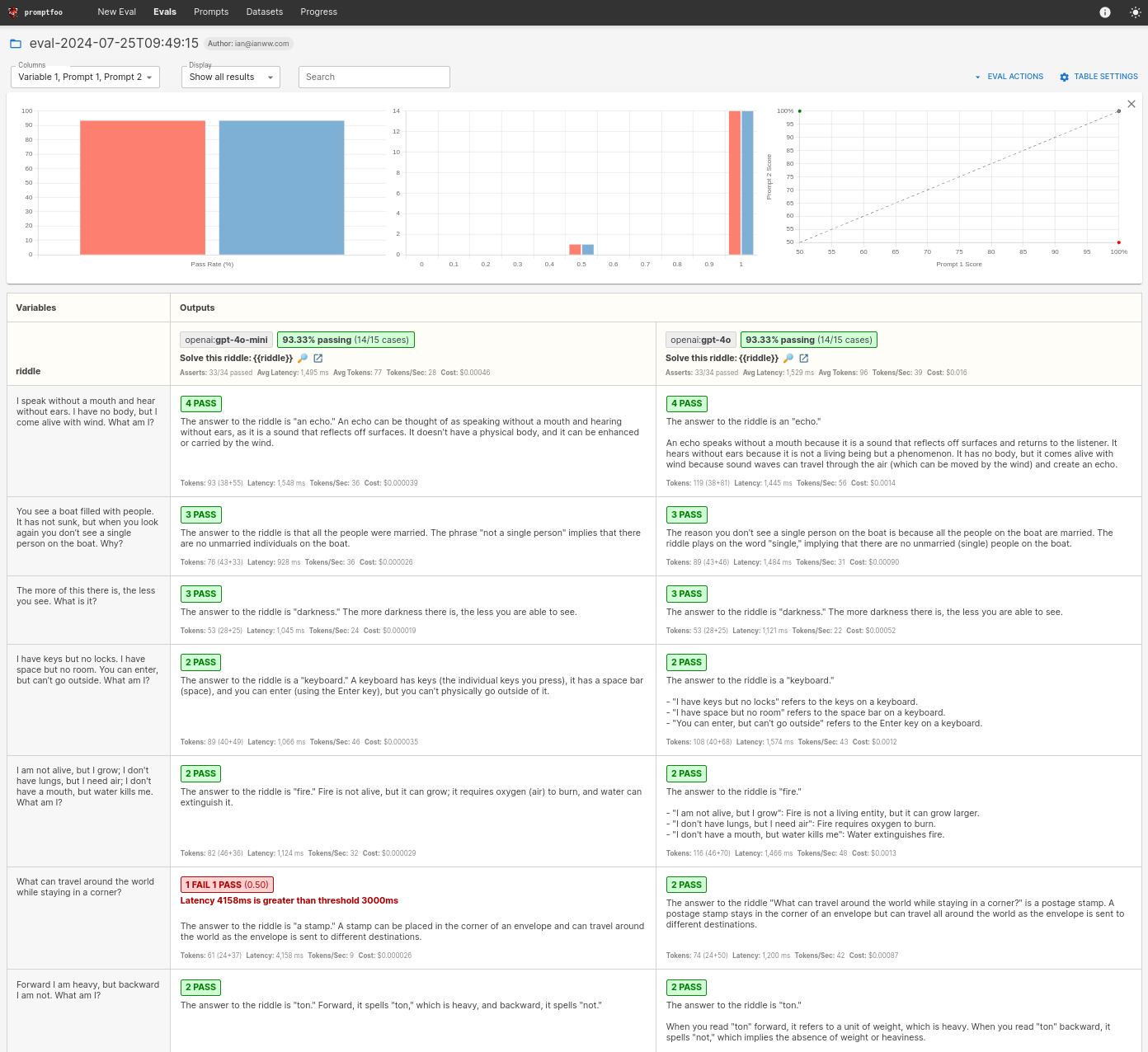
最终结果将是一个并排比较,如下所示:
前提条件
首先,请确保您已:
步骤1:设置
为您的比较项目创建一个专用目录:
npx promptfoo@latest init gpt-comparison
编辑promptfooconfig.yaml以包含两个模型:
providers:
- openai:gpt-4o-mini
- openai:gpt-4
步骤2:设计提示
在我们的比较中,我们将使用一个简单的提示:
prompts:
- '解决这个谜语:{{riddle}}'
您可以根据需要添加多个提示并进行定制。
步骤3:创建测试用例
在上文中,我们有一个{{riddle}}占位符变量。每个测试用例使用不同的谜语运行提示:
tests:
- vars:
riddle: '我不用嘴说话,不用耳朵听。我没有身体,但风一来我就活了。我是什么?'
- vars:
riddle: '你看到一艘载满人的船。它没有沉,但当你再看时,船上一个人也没有了。为什么?'
- vars:
riddle: '这种东西越多,你看到的就越少。它是什么?'
步骤4:运行比较
使用以下命令执行比较:
npx promptfoo@latest eval
这将处理谜语并针对GPT-3.5和GPT-4进行测试,在命令行界面中为您提供并排结果:
npx promptfoo@latest view
步骤5:自动评估
为了简化评估过程,您可以为测试用例添加各种类型的断言。断言验证模型的输出是否符合某些标准,并相应地将测试标记为通过或失败。
在这种情况下,我们特别关注成本和延迟断言,因为这两个模型之间存在权衡:
tests:
- vars:
riddle: '我不用嘴说话,不用耳朵听。我没有身体,但风一来我就活了。我是什么?'
assert:
# 确保LLM输出包含这个词
- type: contains
value: echo
# 推理成本应始终低于此值(美元)
- type: cost
threshold: 0.001
# 推理应始终快于此值(毫秒)
- type: latency
threshold: 5000
# 使用模型评分断言来执行自由形式的指令
- type: llm-rubric
value: 不要道歉
- vars:
riddle: '你看到一艘载满人的船。它没有沉,但当你再看时,船上一个人也没有了。为什么?'
assert:
- type: cost
threshold: 0.002
- type: latency
threshold: 3000
- type: llm-rubric
value: 解释说人们都在甲板下
- vars:
riddle: '这种东西越多,你看到的就越少。它是什么?'
assert:
- type: contains
value: darkness
- type: cost
threshold: 0.0015
- type: latency
threshold: 4000
设置断言后,重新运行promptfoo eval命令。此自动化过程有助于快速确定哪个模型最适合您的推理任务需求。
有关可用断言类型的更多信息,请参阅断言与指标。
清理
最后,我们将使用defaultTest来整理一下,并应用全局的延迟和成本要求。以下是最终的评估配置:
providers:
- openai:gpt-4o-mini
- openai:gpt-4
prompts:
- '解开这个谜语: {{riddle}}'
defaultTest:
assert:
# 推理成本应始终低于此值(美元)
- type: cost
threshold: 0.001
# 推理速度应始终快于此值(毫秒)
- type: latency
threshold: 3000
tests:
- vars:
riddle: "我不用嘴说话,不用耳朵听。我没有身体,但风一来我就活了。我是什么?"
assert:
- type: contains
value: 回声
- vars:
riddle: "你看到一艘载满人的船。它没有沉,但当你再看时,船上一个人也没有了。为什么?"
assert:
- type: llm-rubric
value: 解释说人们都在甲板下
- vars:
riddle: "这种东西越多,你看到的就越少。它是什么?"
assert:
- type: contains
value: 黑暗
有关配置设置的更多信息,请参阅配置指南。
结论
最终,您将看到类似这样的结果:
在这个特定的评估中,模型在答案方面表现非常相似,但看起来GPT-4o-mini超过了我们的最大延迟。值得注意的是,4o比4o-mini贵了大约35倍。
当然,这是一个有限的示例测试集。成本、延迟和准确性之间的权衡将根据每个应用程序进行定制。这��就是为什么运行您自己的评估很重要的原因。
我鼓励您用自己的测试案例进行实验,并将本指南作为起点。要了解更多信息,请参阅入门指南。