Claude 3.5 vs GPT-4o:基于您自己的数据进行基准测试
在评估大型语言模型(LLM)的性能时,通用基准只能让您走这么远。对于Claude与GPT的比较尤其如此,因为有许多关于它们效能的拆分评估(主观的和客观的)。
您应该在这些模型上测试与您的特定用例相关的任务,而不是仅仅依赖公开的基准。
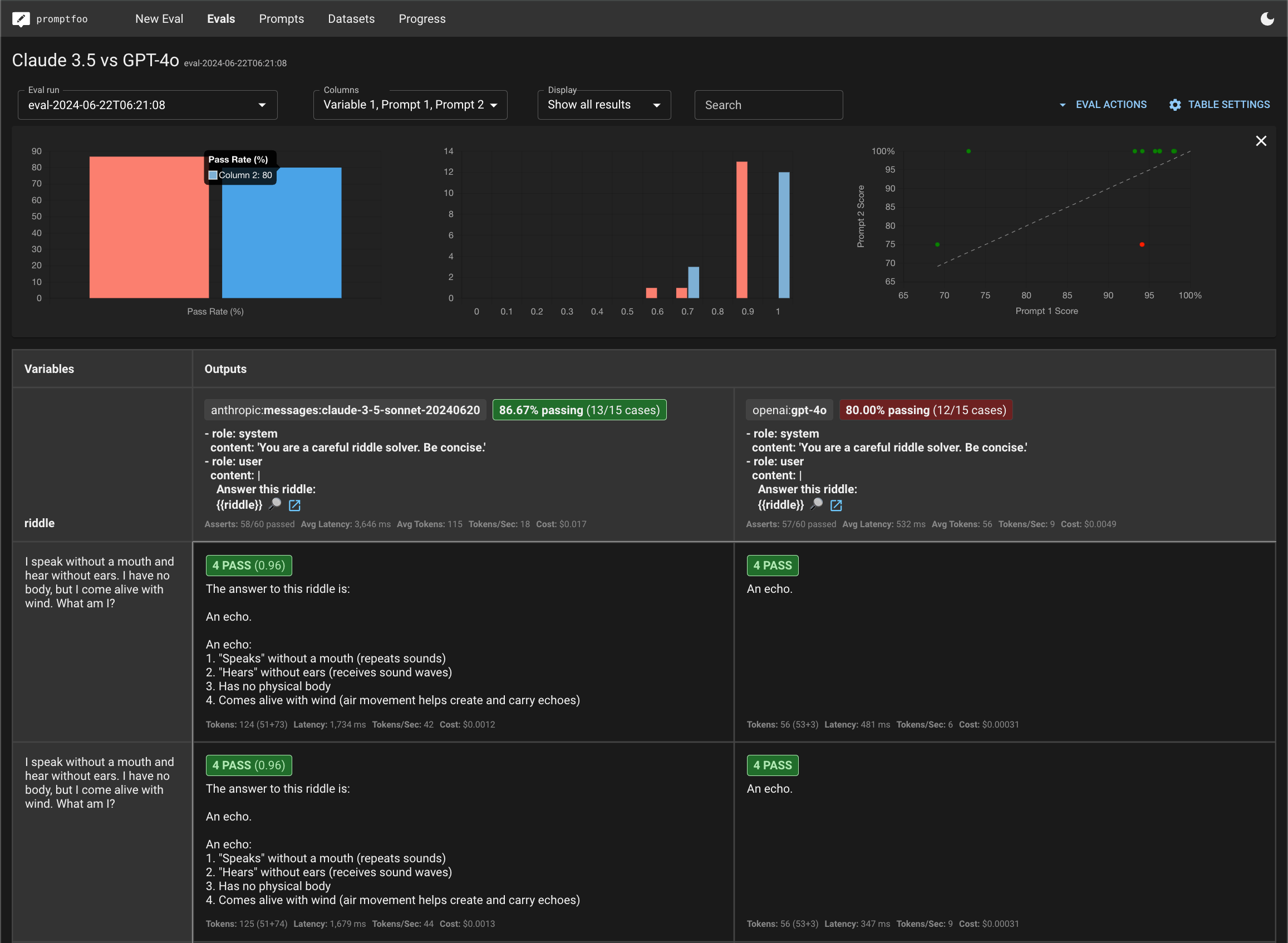
本指南将引导您使用promptfoo设置Anthropic的Claude 3.5和OpenAI的GPT-4o之间的比较。最终结果是这些模型在自定义任务上的并排评估:
前提条件
在开始之前,请确保您已具备以下条件:
- 已安装
promptfooCLI(安装说明) - Anthropic(
ANTHROPIC_API_KEY)和OpenAI(OPENAI_API_KEY)的API密钥
步骤1:设置您的评估
为您的比较项目创建一个新目录:
npx promptfoo@latest init claude3.5-vs-gpt4o
cd claude3.5-vs-gpt4o
打开生成的promptfooconfig.yaml文件。这是您将配置要测试的模型、要使用的提示以及要运行的测试用例的地方。
配置模型
在providers下指定Claude 3.5和GPT-4o的模型ID:
providers:
- anthropic:messages:claude-3-5-sonnet-20240620
- openai:chat:gpt-4o
您可以选择为每个模型设置温度和最大令牌数等参数:
providers:
- id: anthropic:messages:claude-3-5-sonnet-20240620
config:
temperature: 0.3
max_tokens: 1024
- id: openai:chat:gpt-4o
config:
temperature: 0.3
max_tokens: 1024
定义您的提示
接下来,定义您希望在模型上测试的提示。在这个例子中,我们将使用一个简单的提示:
prompts:
- 'Answer this riddle: {{riddle}}
如果需要,您可以使用在单独的prompt.yaml或prompt.json文件中定义的提示模板。这使得设置系统消息等更加容易:
prompts:
- file://prompt.yaml
prompt.yaml的内容:
- role: system
content: 'You are a careful riddle solver. Be concise.'
- role: user
content: |
Answer this riddle:
{{riddle}}
{{riddle}}占位符将由测试用例变量填充。
步骤2:创建测试用例
现在是时候创建一组代表您的应用程序需要处理的查询类型的测试用例了。
关键是要专注于对您的应用程序最重要的案例进行分析。考虑边缘案例和您在LLM中需要的特定能力。
在这个例子中,我们将使用几个谜语来测试模型的推理和语言理解能力:
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
assert:
- type: icontains
value: echo
- vars:
riddle: "You see a boat filled with people. It has not sunk, but when you look again you don't see a single person on the boat. Why?"
assert:
- type: llm-rubric
value: explains that the people are below deck or they are all in a relationship
- vars:
riddle: 'The more of this there is, the less you see. What is it?'
assert:
- type: icontains
value: darkness
# ... 更多测试用例
assert块允许您自动检查模型输出中预期的内容。这对于在您优化提示时跟踪性能非常有用。
promptfoo支持非常广泛的断言,从基本断言到模型评分断言,再到专门用于RAG应用程序的断言。
步骤3:运行评估
配置完成后,您可以开始评估:
npx promptfoo@latest eval
这将针对Claude 3.5和GPT-4o运行每个测试用例并记录结果。
要查看结果,启动promptfoo查看器:
npx promptfoo@latest view
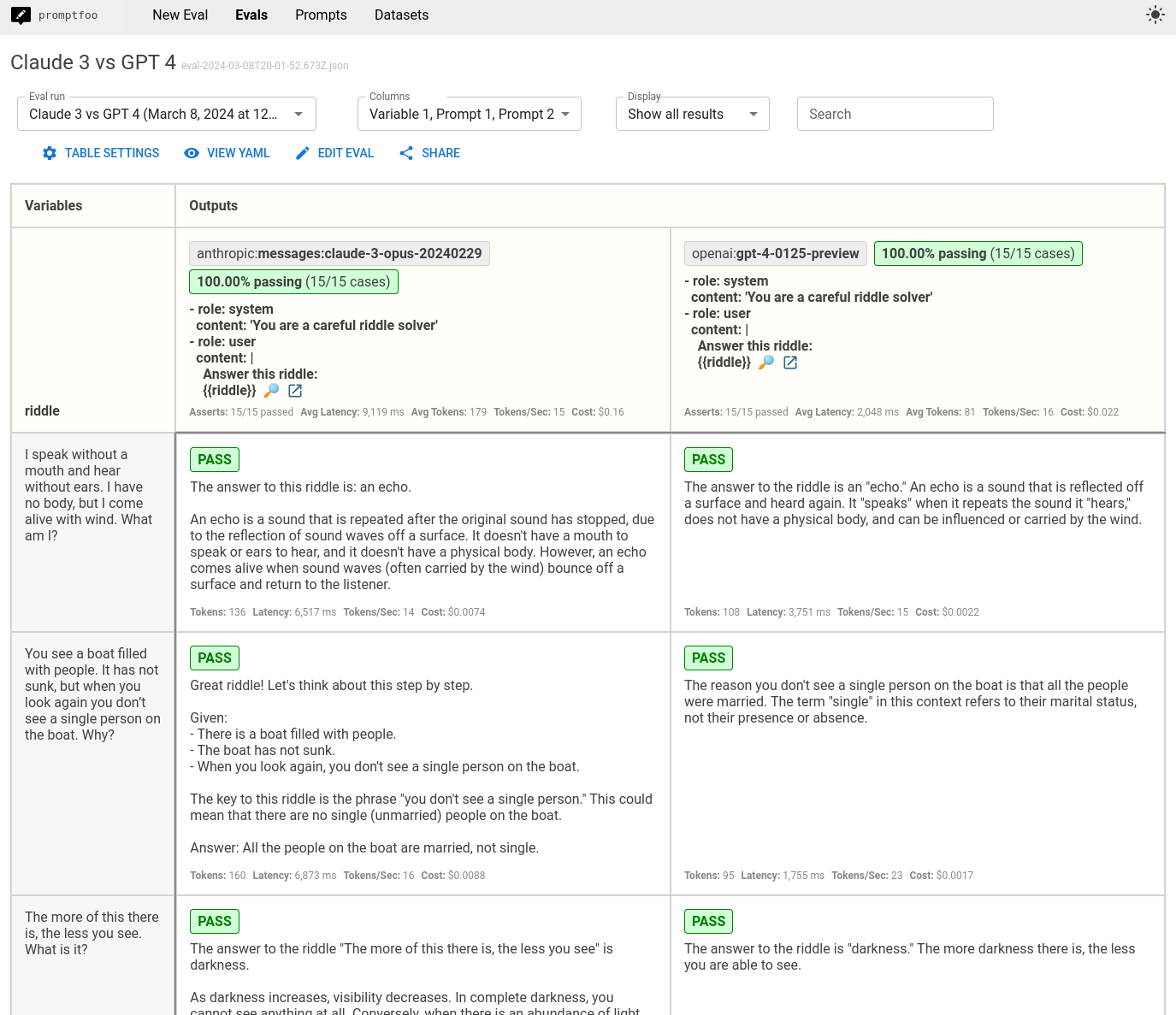
这将显示一个比较视图,展示Claude 3.5和GPT-4o在每个测试用例上的表现:
您还可以将原始结果数据输出到文件:
npx promptfoo@latest eval -o results.json
步骤4:分析结果
评估完成后,是时候深入研究结果,看看模型在您的测试用例上的比较情况了。
需要注意的一些关键事项:
- 在测试断言中,哪个模型的总体通过率更高?在这种情况下,两个模型在获取答案方面表现相当,这很好——这些谜题通常会让像GPT 3.5和Claude 2这样的较弱模型陷入困境。
- 是否有特定的测试案例中,一个模型明显优于另一个?
- 模型在其他输出质量指标上如何比较?
- 除了质量外,还要考虑模型的速度和成本等属性。
以下是我们示例谜题测试集的一些观察结果:
- GPT 4o的回答往往较短,而Claude 3.5通常包含额外的评论
- GPT 4o的速度大约快7�倍
- GPT 4o的成本大约便宜3倍
添加我们关心的内容的断言
基于上述观察,让我们为本次评估中的所有测试添加以下断言:
- 延迟必须低于2000毫秒
- 成本必须低于$0.0025
- 滑动比例的Javascript函数,惩罚长响应
defaultTest:
assert:
- type: cost
threshold: 0.0025
- type: latency
threshold: 2000
- type: javascript
value: 'output.length <= 100 ? 1 : output.length > 1000 ? 0 : 1 - (output.length - 100) / 900'
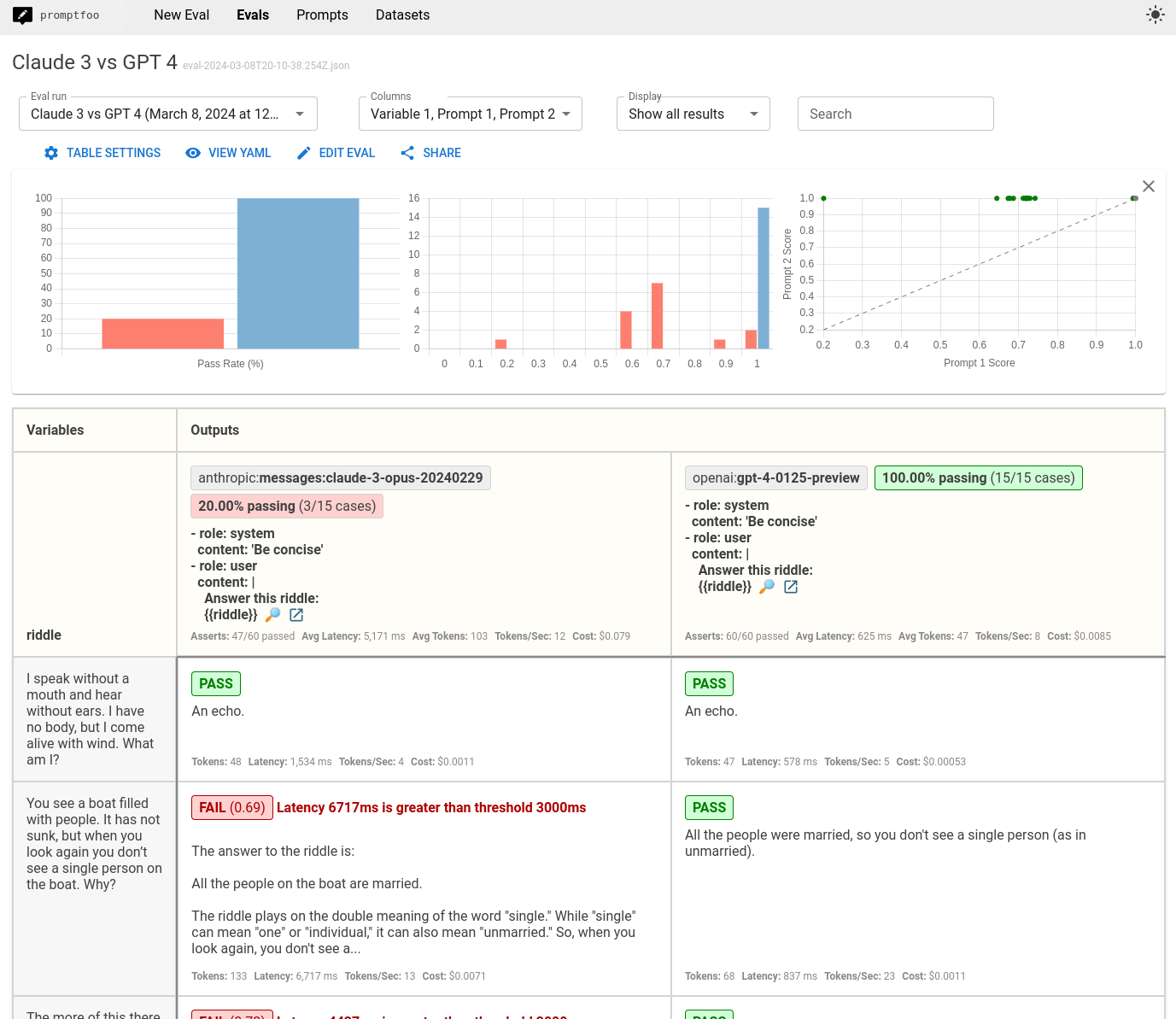
我们还将更新系统提示为“保持简洁”。
结果是Claude 3.5经常无法满足我们的延迟要求:
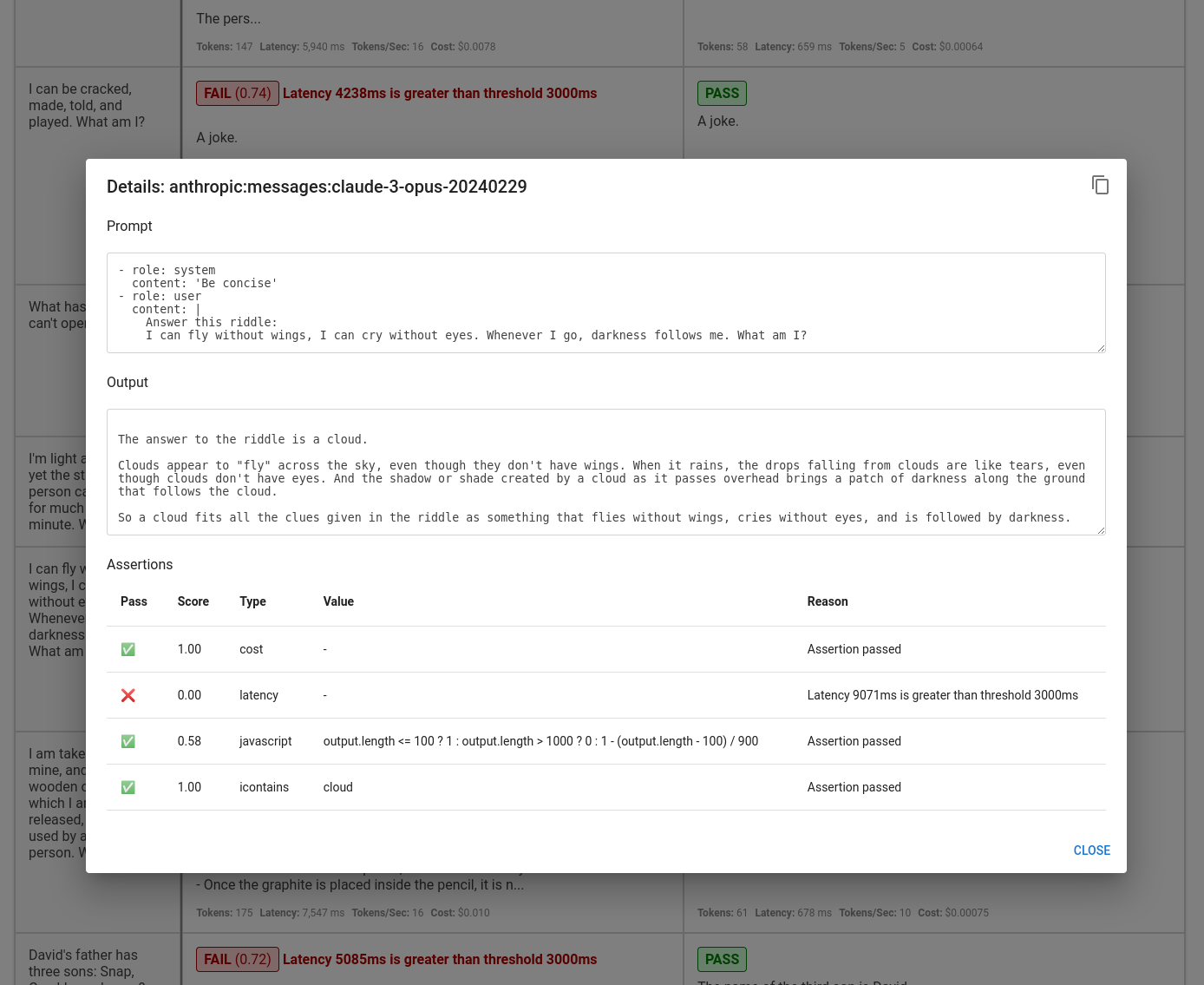
点击进入特定测试案例,显示单个测试结果:
当然,我们的要求与您的不同。您应该根据您的使用情况自定义这些值。
结论
通过运行这种针对性的评估,您可以获得有关Claude 3.5和GPT-4o在您的应用程序实际数据和任务中可能表现的宝贵见解。
promptfoo使得设置可重复的评估管道变得容易,因此您可以在模型不断发展时测试它们,并衡量模型和提示更改的影响。
最终目标:根据实证数据选择最适合您使用情况的基础模型。