Command R vs GPT vs Claude: 创建你自己的基准测试
虽然公开的基准测试提供了能力的一般感知,但真正了解哪个模型最适合你的特定应用的唯一方法是自己运行定制评估。
本指南将向你展示如何在 Cohere 的 Command-R/Command-R Plus 上执行定制基准测试,将其与 GPT-4 和 Claude Opus 进行比较,重点关注对你最重要的用例。
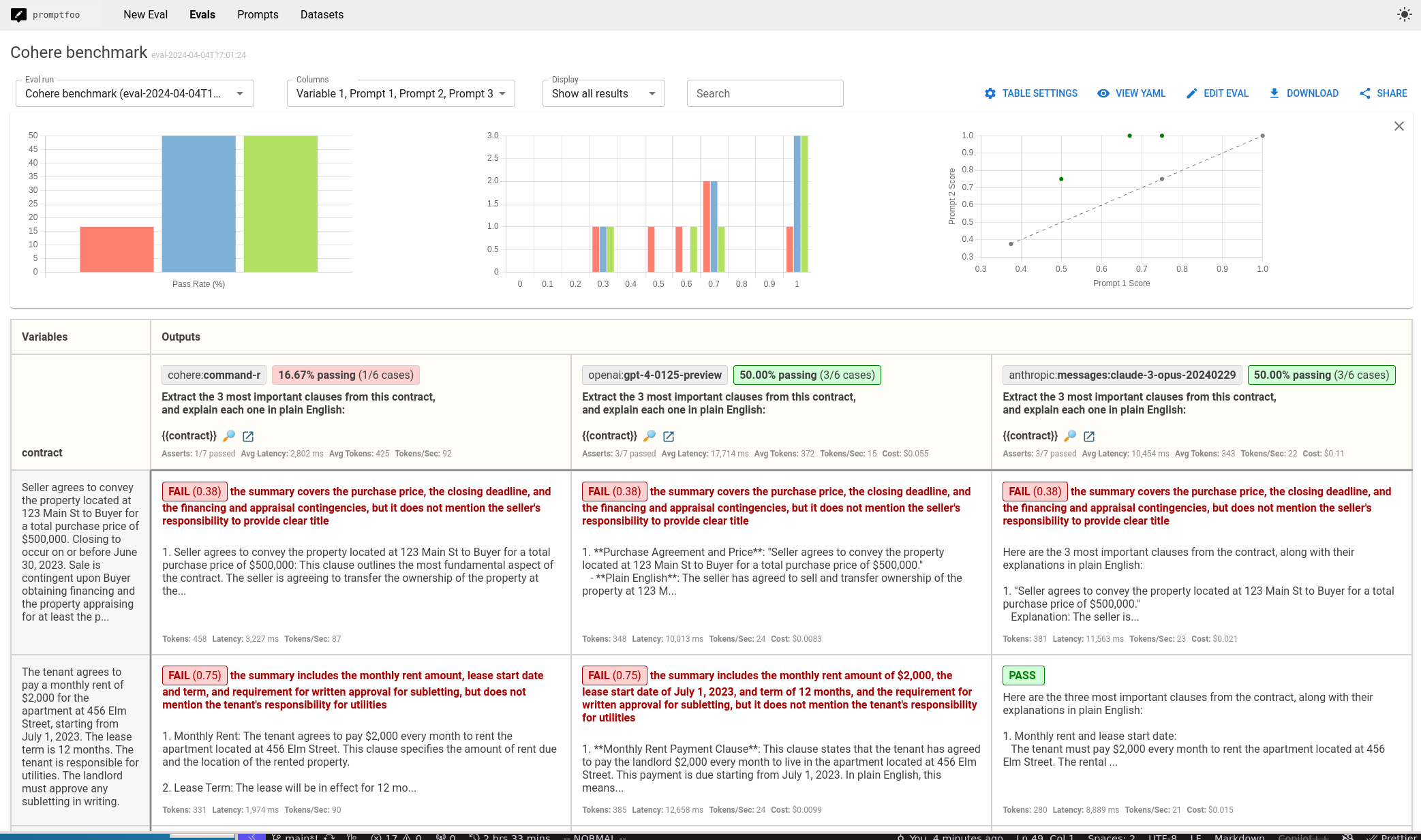
最终结果是一个并排比较的视图,如下所示:
要求
- Cohere API 密钥用于 Command-R
- OpenAI API 密钥用于 GPT-4
- Anthropic API 密钥用于 Claude Opus
- Node 18+
步骤 1: 初始设置
创建一个新的 promptfoo 项目:
npx promptfoo@latest init cohere-benchmark
cd cohere-benchmark
步骤 2: 配置模型
编辑 promptfooconfig.yaml 以指定要比较的模型:
providers:
- id: cohere:command-r # 或 command-r-plus
- id: openai:gpt-4o
- id: anthropic:messages:claude-3-5-sonnet-20240620
设置 API 密钥:
export COHERE_API_KEY=your_cohere_key
export OPENAI_API_KEY=your_openai_key
export ANTHROPIC_API_KEY=your_anthropic_key
可选地配置模型参数,如温度和最大令牌数:
providers:
- id: cohere:command-r
config:
temperature: 0
- id: openai:gpt-4o
config:
temperature: 0
- id: anthropic:messages:claude-3-5-sonnet-20240620
config:
temperature: 0
更多详情请参见 Cohere、OpenAI 和 Anthropic 文档。
步骤 3: 设置提示
定义要测试的提示。发挥创意——这是你了解模型如何处理应用程序独特查询的机会!
例如,让我们看看每个模型如��何从法律合同中总结关键点:
prompts:
- |
Extract the 3 most important clauses from this contract,
and explain each one in plain English:
{{contract}}
步骤 4: 添加测试用例
提供测试用例输入和预期输出以评估性能:
tests:
- vars:
contract: |
Seller agrees to convey the property located at 123 Main St
to Buyer for a total purchase price of $500,000. Closing to
occur on or before June 30, 2023. Sale is contingent upon
Buyer obtaining financing and the property appraising for
at least the purchase price. Seller to provide a clear
title free of any liens or encumbrances...
assert:
- type: llm-rubric
value: |
The summary should cover:
- The purchase price of $500,000
- The closing deadline of June 30, 2023
- The financing and appraisal contingencies
- Seller's responsibility to provide clear title
- type: javascript
value: output.length < 500
步骤 5: 运行评估
运行基准测试:
npx promptfoo@latest eval
并查看结果:
npx promptfoo@latest view
你将看到以下内容:
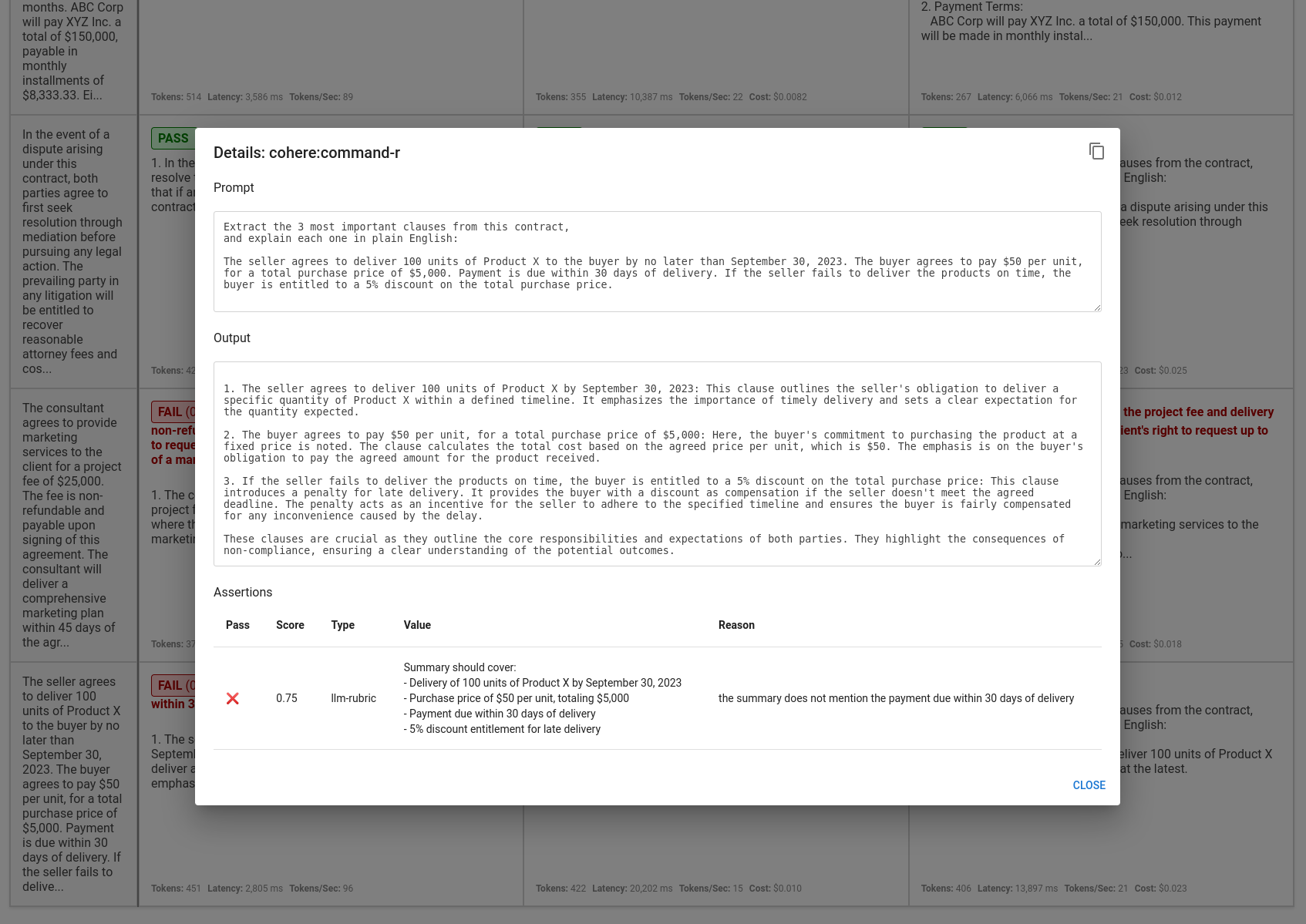
点击单元格查看推理作业的详细信息:
分析
使用视图和断言结果,做出明智的决定,确定哪个模型将为你的应用提供最佳体验。
在这个特定情况下,Command-R 表现不佳,仅通过了 16.67% 的测试用例,而 GPT-4 和 Claude Opus 的通过率为 50%。这并不意味着它是一个糟糕的模型——只是可能不适合这个用例。
值得注意的是,Command-R 分别比 Claude Opus 和 GPT-4 快 5-8 倍,而且成本低得多。每个模型都有权衡。
参见 入门 设置你自己的本地评估并了解更多信息。