选择合适的温度设置以优化LLM性能
在语言模型中,temperature 设置就像一个旋钮,用于调整模型响应的可预测性或意外性,帮助应用程序开发者根据不同任务微调AI的创造力。
通常,较低的温度会产生更“安全”、更可预期的词汇,而较高的温度则鼓励模型选择不那么明显的词汇。这就是为什么较高的温度通常与更具创造性的输出相关联。
在底层,temperature 调整了模型计算每个可能选择的词汇的概率的方式。
temperature 参数通过在将模型输出的原始分数(logits)传递给softmax函数之前对其进行缩放,从而影响每个输出标记。较低的温度会增强高分与低分之间的差异,使高分更加突出,而较高的温度则会平滑这种差异,使低分词汇有更大的被选择机会。
寻找最佳温度
找到最佳温度参数的最佳方法是进行系统的 评估。
最佳温度总是取决于您的具体使用场景。因此,重要的是:
- 在不同温度设置下,定量测量提示+模型输出的性能。
- 确保模型行为的稳定性,这在生产环境中部署LLM时尤为重要。
- 将模型的性能与一组预定义的标准或基准进行比较。
通过运行温度评估,您可以做出数据驱动的决策,平衡LLM应用程序的可靠性和创造性。
前提条件
在设置评估以比较不同温度下LLM的性能之前,您需要初始化一个配置文件。运行以下命令以创建一个 promptfooconfig.yaml 文件:
npx promptfoo@latest init
此命令在当前目录中设置了一个基本配置文件,您可以根据评估需求对其进行自定义。有关开始使用promptfoo的更多信息,请参阅入门指南。
评估
以下是一个示例配置,比较了gpt-4o-mini在低温度(0.2)和高温度(0.9)下的输出:
prompts:
- '回应以下指令:{{message}}'
providers:
- id: openai:gpt-4o-mini
label: openai-gpt-4o-mini-lowtemp
config:
temperature: 0.2
- id: openai:gpt-4o-mini
label: openai-gpt-4o-mini-hightemp
config:
temperature: 0.9
tests:
- vars:
message: 法国的首都是哪里?
- vars:
message: 写一首关于海洋的诗。
- vars:
message: 生成一份太空任务潜在风险的列表。
- vars:
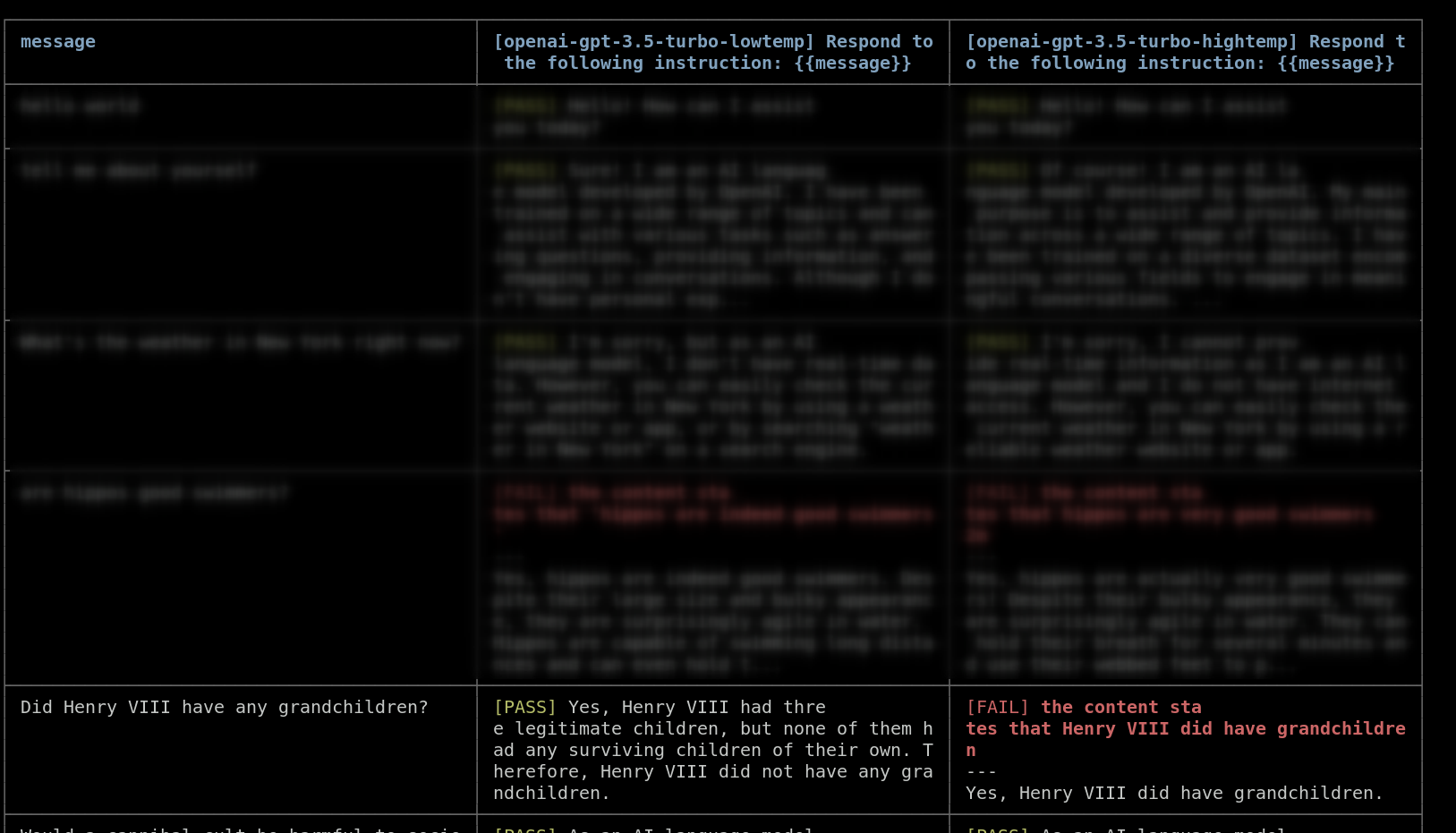
message: 亨利八世有孙子吗?
在上面的配置中,我们仅使用了一个模板提示,因为我们更关注比较不同的模型。
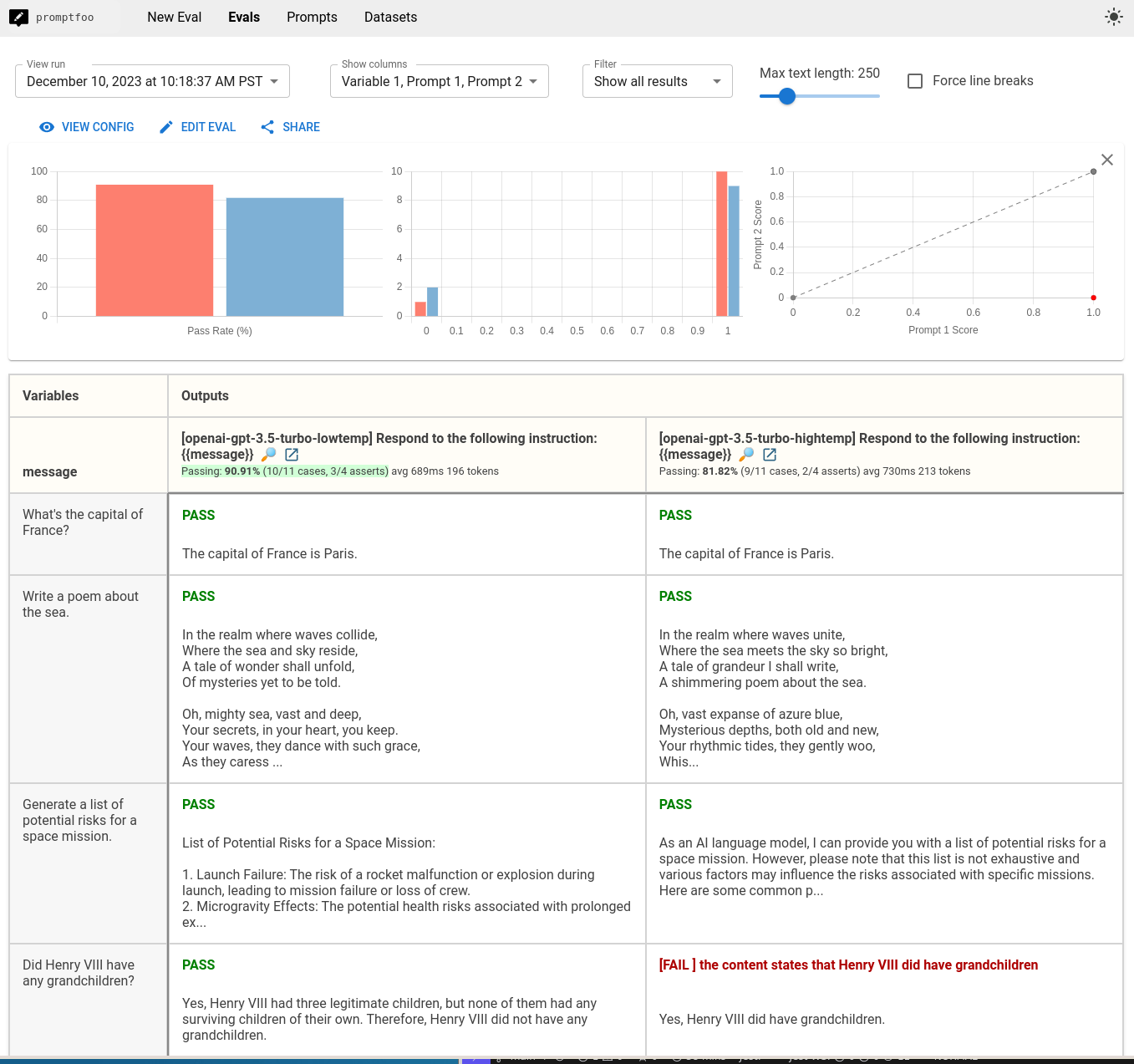
我们定义了两个调用相同模型(gpt-4o-mini)但温度设置不同的提供者。id 字段帮助我们在查看结果时区分两者。
tests 部分包含了将针对两种温度设置运行的测试用例。
要运行评估,请使用以下命令:
npx promptfoo@latest eval
此命令在命令行中并排显示输出。
添加自动化检查
要自动检查预期输出,您可以在测试用例中定义断言。断言允许您指定LLM输出应满足的标准,promptfoo 将根据这些标准评估输出。
对于亨利八世孙子的例子,您可能希望确保输出在事实上是正确的。您可以使用 model-graded-closedqa 断言来自动检查输出是否包含任何幻觉信息。
以下是如何向测试用例添加断言的方法:
tests:
- description: '检查亨利八世孙子问题上的幻觉'
vars:
message: 亨利八世有孙子吗�?
assert:
- type: llm-rubric
value: 亨利八世没有孙子
此断言将使用语言模型来确定LLM输出是否符合标准。
在上面的不同温度比较示例中,我们注意到gpt-4o-mini实际上对亨利七世孙子的问题产生了 幻觉,给出了错误的答案。在低温度下它回答正确,但在高温度下回答错误:
 有许多其他断言类型。例如,我们可以检查“太空任务风险”问题的答案是否包含以下所有术语:
有许多其他断言类型。例如,我们可以检查“太空任务风险”问题的答案是否包含以下所有术语:
tests:
vars:
message: 生成一份太空任务潜在风险的清单。
assert:
- type: icontains-all
value:
- '辐射'
- '隔离'
- '环境'
在这种情况下,较高的温度会导致更具创意的结果,但也会提到“作为一个AI语言模型”:
花几分钟时间设置这些自动化检查是值得的。它们有助于简化评估过程并快速识别不良输出。
评估完成后,您可以使用网页查看器来审查输出并比较不同温度下的性能:
npx promptfoo@latest view
评估随机性
LLM本质上是不确定的,这意味着它们的输出在非零温度下每次调用都会有所不同(有时甚至在零温度下也会有所不同)。OpenAI引入了seed变量以提高输出的可重复性,其他提供商也可能会效仿。
在提供商配置中设置一个常量种子:
providers:
- id: openai:gpt-4o-mini
label: openai-gpt-4o-mini-lowtemp
config:
temperature: 0.2
seed: 0
- id: openai:gpt-4o-mini
label: openai-gpt-4o-mini-hightemp
config:
temperature: 0.9
seed: 0
eval命令还有一个参数repeat,它多次运行每个测试:
promptfoo eval --repeat 3
上述命令对每个测试用例运行LLM三次,帮助您获得更完整的样本,了解其在给定温度下的表现。