评估 RAG 管道
检索增强生成是一种通过相关数据丰富 LLM 提示的方法。通常,用户提示将被转换为嵌入,并从向量存储中获取匹配的文档。然后,LLM 会使用这些匹配的文档作为提示的一部分进行调用。
在设计 RAG 应用的评估策略时,您应该评估以下两个步骤:
- 从向量存储中检索文档
- 生成 LLM 输出
分别评估这些步骤非常重要,因为将 RAG 分解为多个步骤可以更容易地定位问题。
有几种标准用于评估 RAG 应用:
- 基于输出的
- 事实性(也称为正确性):衡量 LLM 输出是否基于提供的真实数据。参见
factuality指标。 - 答案相关性:衡量答案直接回答问题的程度。参见
answer-relevance或similar指标。
- 事实性(也称为正确性):衡量 LLM 输出是否基于提供的真实数据。参见
- 基于上下文的
- 上下文遵循(也称为基础或忠实度):衡量 LLM 输出是否基于提供的上下文。参见
context-adherence指标。 - 上下文召回率:衡量上下文是否包含正确的信息,以便与提供的真实数据进行比较,从而生成答案。参见
context-recall指标。 - 上下文相关性:衡量回答给定查询��所需的上下文量。参见
context-relevance指标。
- 上下文遵循(也称为基础或忠实度):衡量 LLM 输出是否基于提供的上下文。参见
- 自定义指标:您比任何人都更了解您的应用。创建专注于对您重要的事物的测试用例(例如:是否引用了某个文档,响应是否过长等)
本指南展示了如何使用 promptfoo 来评估您的 RAG 应用。如果您是 promptfoo 的新手,请前往 入门指南。
您还可以跳转到 GitHub 上的 完整 RAG 示例。
评估文档检索
文档检索是 RAG 的第一步。可以单独评估检索步骤,以确保获取最佳文档。
假设我们有一个简单的文件 retrieve.py,它接受查询并输出文档列表及其内容:
import vectorstore
def call_api(query, options, context):
# 获取相关文档并将它们连接成字符串结果。
documents = vectorstore.query(query)
output = "\n".join(f'{doc.name}: {doc.content}' for doc in documents)
result = {
"output": output,
}
# 根据需要包含错误处理和令牌使用报告
# if some_error_condition:
# result['error'] = "处理过程中发生错误"
#
# if token_usage_calculated:
# result['tokenUsage'] = {"total": token_count, "prompt": prompt_token_count, "completion": completion_token_count}
return result
实际上,您的检索逻辑可能比上述内容更复杂(例如查询转换和扇出)。将 retrieval.py 替换为您自己的脚本,该脚本准备查询并与您的数据库通信。
配置
我们将设置一个评估,针对向量数据库运行实时文档检索。
在下面的示例中,我们正在评估一个用于企业内网的 RAG 聊天机器人。我们添加了几个测试,以确保预期的子字符串出现在文档结果中。
首先,创建 promptfooconfig.yaml。我们将使用一个带有单个 {{ query }} 变量的占位符提示。此文件指示 promptfoo 通过检索脚本运行多个测试用例。
prompts:
- '{{ query }}'
providers:
- file://retrieve.py
tests:
- vars:
query: What is our reimbursement policy?
assert:
- type: contains-all
value:
- 'reimbursement.md'
- 'hr-policies.html'
- 'Employee Reimbursement Policy'
- vars:
query: How many weeks is maternity leave?
assert:
- type: contains-all
value:
- 'parental-leave.md'
- 'hr-policies.html'
- 'Maternity Leave'
在上面的示例中,contains-all 断言确保 retrieve.py 的输出包含所有列出的子字符串。context-recall 断言使用 LLM 模型来确保检索表现良好。
如果您设置自己的评估测试用例,您将从中获得最大价值。 查看其他可用的 断言类型。
比较向量数据库
为了在评估中比较多个向量数据库,请为每个数据库创建检索脚本,并将它们添加到 providers 列表中:
providers:
- file://retrieve_pinecone.py
- file://retrieve_milvus.py
- file://retrieve_pgvector.py
运行 promptfoo eval 将创建 Pinecone、Milvus 和 PGVector 之间的比较视图:
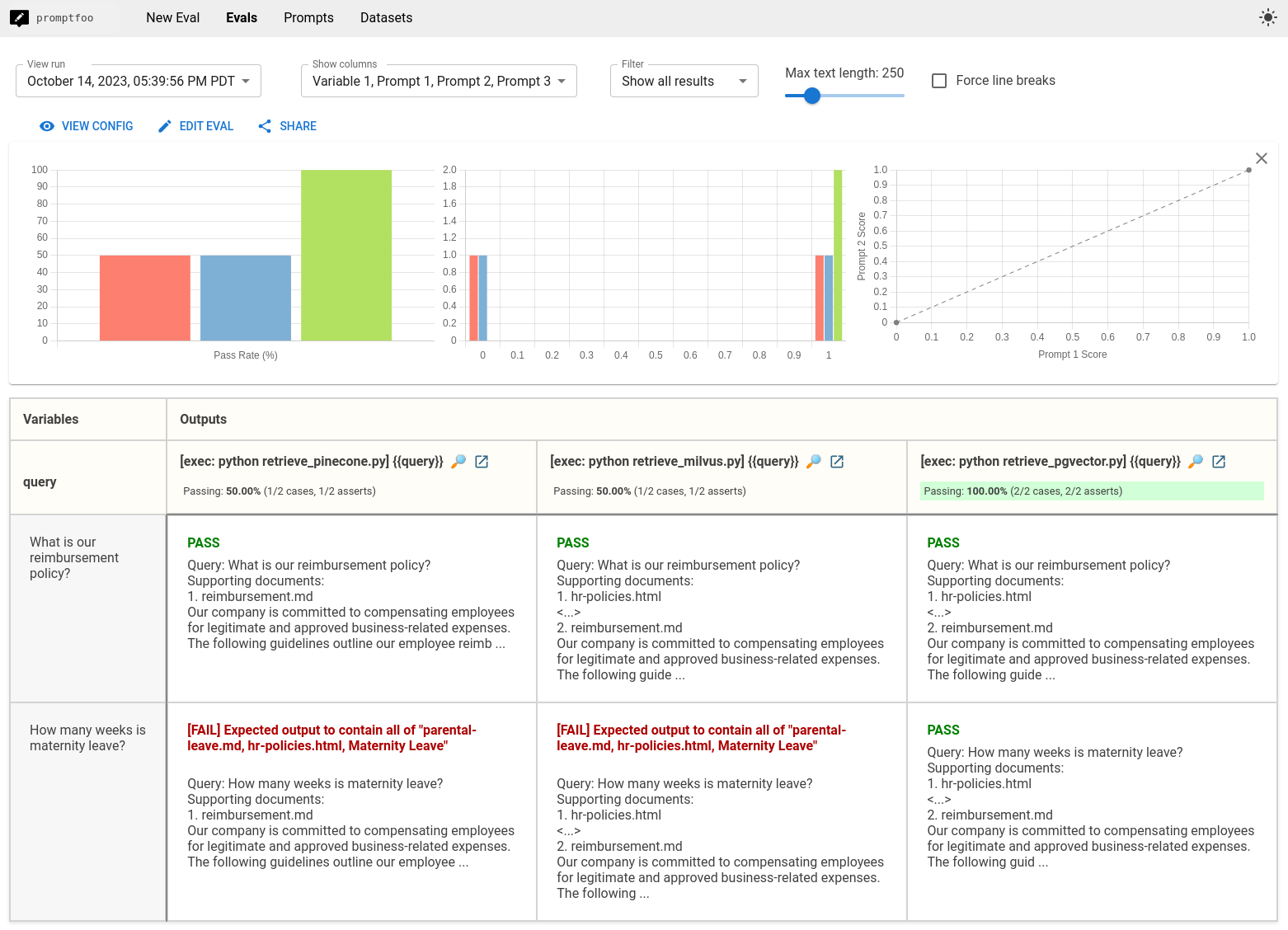
在这个特定的例子中,我们设置的指标表明 PGVector 表现最佳。但结果会根据您如何调整数据库以及在将查询发送到数据库之前如何格式化或转换查询而有所不同。
评估 LLM 输出
一旦您确信检索步骤表现良好,就可以开始评估 LLM 本身了。
在这一步中,我们专注于评估在给定查询和一组文档的情况下,LLM 输出是否正确。
我们将使用内置功能来调用 LLM API,而不是使用外部脚本提供程序。如果您的 LLM 输出逻辑复杂,您可以使用如上所示的 python 提供程序。
首先,让我们通过创建一个 prompt1.txt 文件来设置我们的提示:
您是一个企业内部网聊天助手。用户提出了以下问题:
<QUERY>
{{ query }}
</QUERY>
您已经检索了一些文档来帮助您回复:
<DOCUMENTS>
{{ context }}
</DOCUMENTS>
仔细思考并简洁准确地回应用户。
现在我们已经构建了一个提示,让我们设置一些测试用例。在这个例子中,评估将使用提示模板格式化每个测试用例,并将其发送到 LLM API:
prompts: [prompt1.txt]
providers: [openai:gpt-4o-mini]
tests:
- vars:
query: 无需批准的最大购买金额是多少?
context: file://docs/reimbursement.md
assert:
- type: contains
value: '$500'
- type: factuality
value: 员工经理负责审批
- type: answer-relevance
threshold: 0.9
- vars:
query: 产假有多少周?
context: file://docs/maternity.md
assert:
- type: factuality
value: 产假为 4 个月
- type: answer-relevance
threshold: 0.9
- type: similar
value: 符合条件的员工可以请最多 4 个月的假
在这个配置中,我们假设存在一些测试夹具 docs/reimbursement.md 和 docs/maternity.md。您也可以直接在配置中硬编码这些值。
factuality 和 answer-relevance 断言使用 OpenAI 的模型评分提示来评估输出的准确性,使用 LLM。如果您更喜欢确定性评分,可以使用其他支持的字符串或基于正则表达式的断言类型(文档)。
similar 断言使用嵌入来评估 RAG 输出与预期结果的相关性。
使用动态上下文
您可以定义一个 Python 脚本,根据测试用例中的其他变量获取 context。如果您想为每个测试用例检索特定文档,这很有用。
以下是如何修改 promptfooconfig.yaml 并创建一个 load_context.py 脚本来实现这一点:
- 更新
promptfooconfig.yaml文件:
# ...
tests:
- vars:
question: '家长假政策是什么?'
context: file://./load_context.py
- 创建
load_context.py脚本:
def retrieve_documents(question: str) -> str:
# 计算嵌入,搜索向量数据库...
return f'<与 {question} 相关的文档>'
def get_var(var_name, prompt, other_vars):
question = other_vars['question']
context = retrieve_documents(question)
return {
'output': context
}
# 如果发生错误:
# return {
# 'error': '错误信息'
# }
load_context.py 脚本定义了两个函数:
get_var(var_name, prompt, other_vars):这是一个特殊函数,promptfoo 在加载动态变量时会查找它。retrieve_documents(question: str) -> str:此函数以question作为输入,并根据问题检索相关文档。您可以在这里实现自己的逻辑来搜索向量数据库或执行其他操作以获取上下文。
运行评估
promptfoo eval 命令将运行评估并检查您的测试是否通过。使用 Web 查看器查看测试输出。您可以点击测试用例以查看完整提示以及测试结果。

比较提示
假设我们对上述提示的性能不满意,并且我们想将其与另一个提示进行比较。也许我们想要要求引用。让我们创建 prompt2.txt:
你是一名企业内网研究员。用户提出了以下问题:
<QUERY>
{{ query }}
</QUERY>
你已经检索了一些文档来帮助你回答:
<DOCUMENTS>
{{ documents }}
</DOCUMENTS>
仔细思考并简洁准确地回应用户。对于你回答中的每一个事实陈述,请在方括号中输出一个数字引用[0]。在你的回答底部,列出每个引用的文档名称。
现在,更新配置以列出多个提示:
prompts:
- file://prompt1.txt
- file://prompt2.txt
我们还可以引入一个指标
promptfoo eval 的输出将比较两个提示的性能,以便您可以选择最佳的一个:
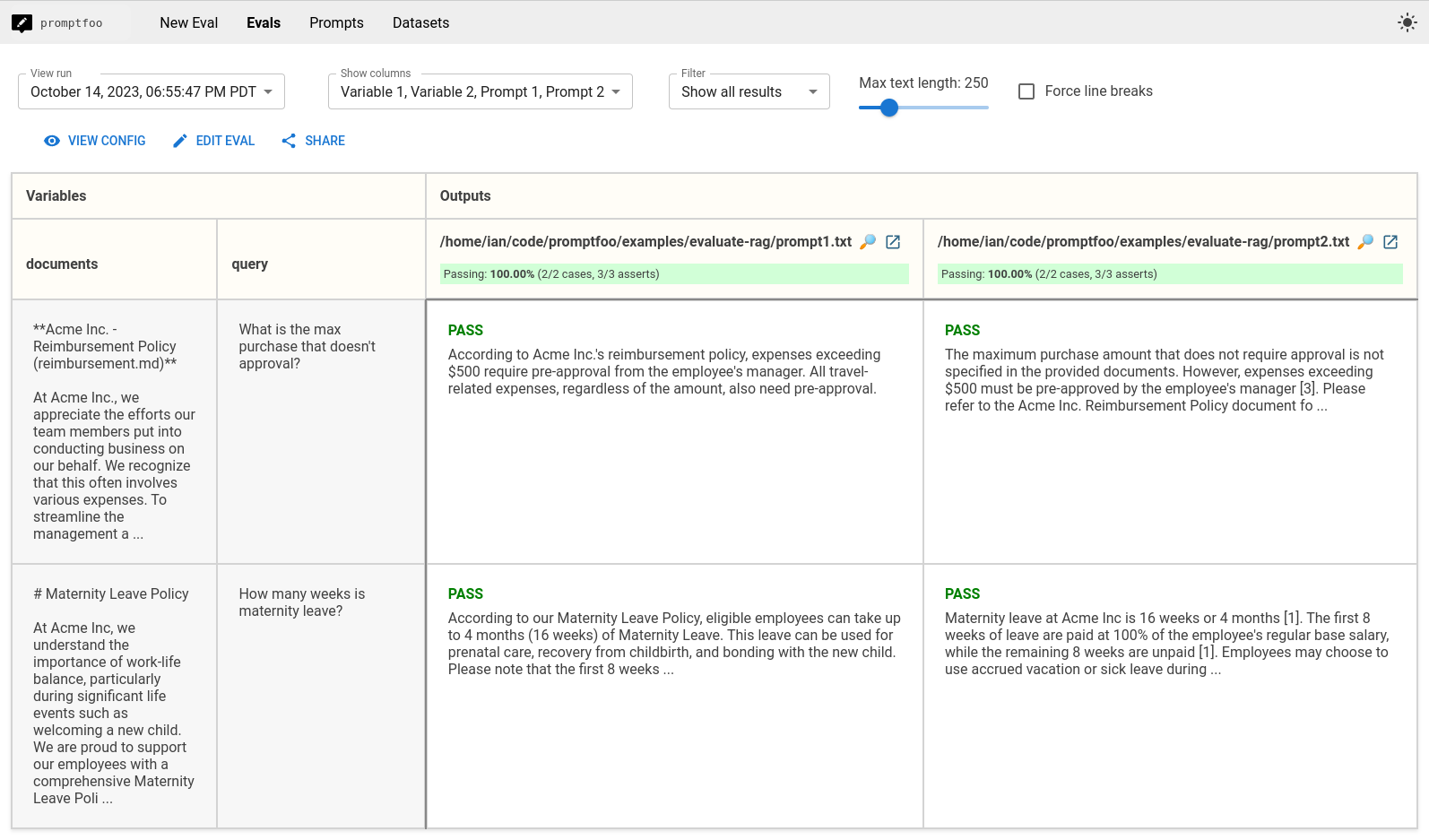
在上面的例子中,两个提示都表现良好。因此我们可能会选择提示1,它更短并且使用更少的令牌。
比较模型
假设我们在探索预算,并想比较 GPT-4 和 Llama 的性能。更新 providers 配置以列出每个模型:
providers:
- openai:gpt-4o-mini
- openai:gpt-4o
- ollama:llama3.1
我们还添加了一个倾向于较短输出的启发式方法。使用 defaultTest 指令,我们将其应用于所有 RAG 测试:
defaultTest:
assert:
- type: python
value: max(0, min(1, 1 - (len(output) - 100) / 900))
以下是最终配置:
prompts: [prompt1.txt]
providers: [openai:gpt-4o-mini, openai:gpt-4o, ollama:llama3.1]
defaultTest:
assert:
- type: python
value: max(0, min(1, 1 - (len(output) - 100) / 900))
tests:
- vars:
query: What is the max purchase that doesn't require approval?
context: file://docs/reimbursement.md
assert:
- type: contains
value: '$500'
- type: factuality
value: the employee's manager is responsible for approvals
- type: answer-relevance
threshold: 0.9
- vars:
query: How many weeks is maternity leave?
context: file://docs/maternity.md
assert:
- type: factuality
value: maternity leave is 4 months
- type: answer-relevance
threshold: 0.9
- type: similar
value: eligible employees can take up to 4 months of leave
输出显示,基于我们设置的测试用例,GPT-4 表现最佳,而 Llama-2 表现最差:
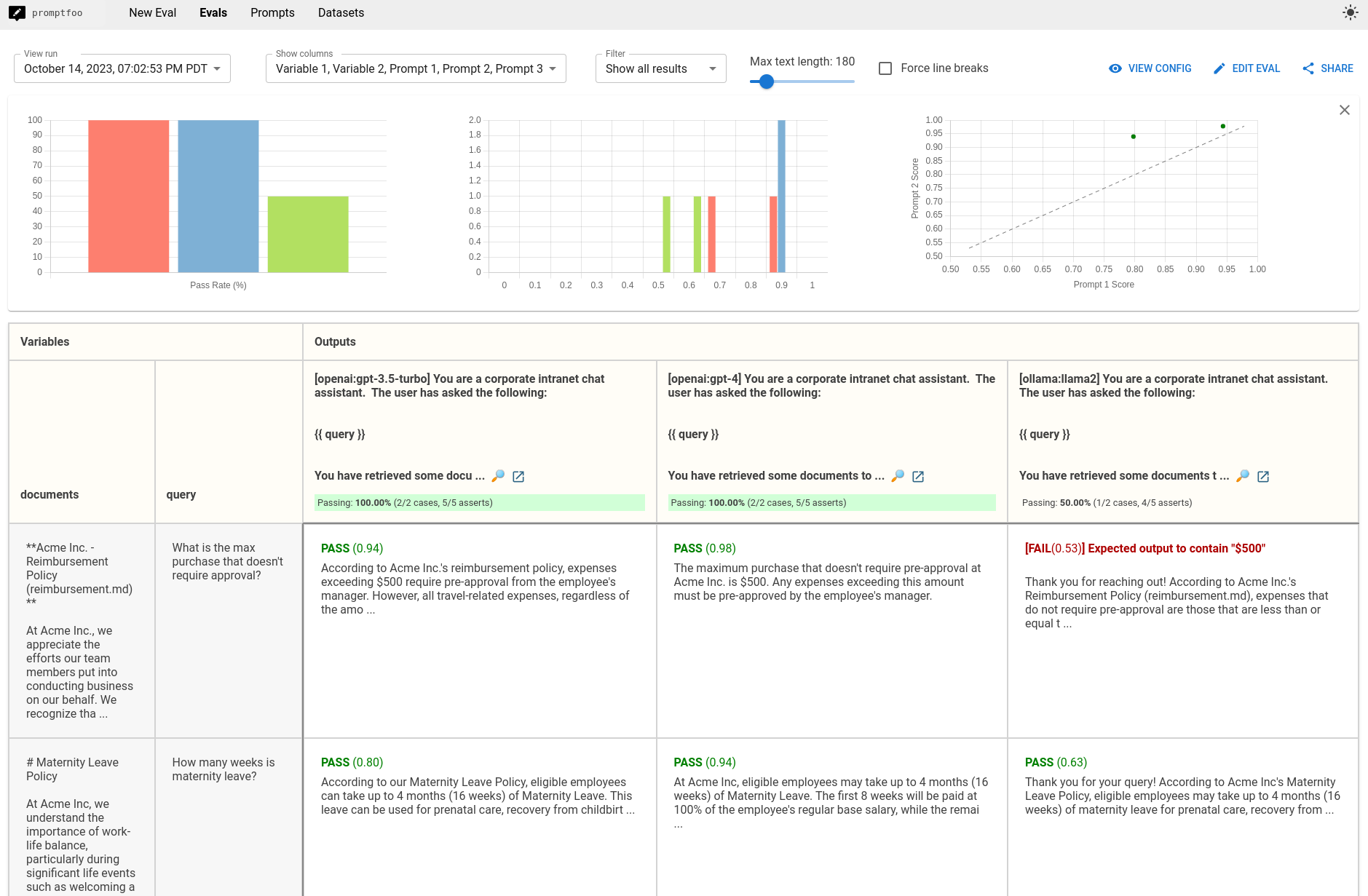
记住,评估是你自己设定的——你应该始终开发专注于你在意的指标的测试用例。
评估端到端性能
我们已经介绍了如何分别测试检索和生成步骤。你可能想知道如何端到端地测试所有内容。
这样做的方法类似于上面的“评估文档检索”步骤。你需要创建一个执行文档检索并调用 LLM 的脚本,然后设置如下配置:
# 测试不同的提示以找到最佳的
prompts: [prompt1.txt, prompt2.txt]
# 测试不同的检索和生成方法以找到最佳的
providers:
- file://retrieve_and_generate_v1.py
- file://retrieve_and_generate_v2.py
tests:
# ...
通过遵循这种方法并在 预期输出 上设置测试,你可以确保你的 RAG 管道的质量在提高,并防止回归。
请参阅 GitHub 上的 RAG 示例 以获取一个完全可用的端到端示例。