如何使用 Replicate Lifeboat 评估 GPT 3.5 与 Llama2-70b
Replicate 提供了一个 "Lifeboat" OpenAI 代理,允许你切换到他们托管的 Llama2-70b 实例。他们慷慨地在一周内免费提供此 API。
我注意到一些声称 Llama2-70b 优于 GPT 3.5 的说法。虽然这可能在一般情况下是正确的,但我一直认为针对自己的特定数据和使用场景来验证这些说法是有用的。
在本指南中,我们将进行一个小测试,比较这两个模型并展示结果:
我鼓励你在这个演练中替换你自己的测试,以便结果适合你的 LLM 应用。
使用 Promptfoo CLI 运行评估
Promptfoo 是一个命令行工具,可以帮助你在不同的语言模型之间运行基准测试。以下是使用 Promptfoo 和 Replicate Lifeboat 设置和运行评估的指南:
首先,我们将初始化用于评估的项目目录。
npx promptfoo@latest init replicate-lifeboat-eval
第二步:编辑配置
修改 promptfooconfig.yaml 文件以包含你希望比较的模型。以下是一个示例配置,比较了 Replicate 上的 Llama 模型与 GPT 模型:
prompts:
- '简洁地回应用户:{{message}}'
providers:
- id: openai:chat:gpt-4o-mini
config:
apiKey: 'your_openai_api_key'
temperature: 0.01
max_tokens: 512
- id: openai:chat:meta/llama-2-70b-chat
config:
apiKey: 'your_replicate_api_key'
apiBaseUrl: https://openai-proxy.replicate.com/v1
temperature: 0.01 # Llama 需要非零温度
max_tokens: 512
tests:
- vars:
message: '法国的首都是什么?'
你需要提供你自己的 Replicate 和 OpenAI API 令牌(这些用于调用每个 LLM 并比较输出)。
第三步:添加更多测试用例
在 promptfooconfig.yaml 中定义一组测试用例。以下是一个包含几个测试用例和相应断言的示例:
# ...(之前的配置部分)
tests:
- vars:
message: hello world
- vars:
message: 介绍一下你自己
- vars:
message: 纽约现在的天气怎么样?
assert:
- type: llm-rubric
value: 不声称知道纽约当前的天气
- vars:
message: 河马是游泳好手吗?
assert:
- type: llm-rubric
value: 说河马不是游泳好手
- vars:
message: 亨利八世有孙子吗?
assert:
- type: llm-rubric
value: 说亨利八世没有孙子
有关最终示例代码,请参见 github。
第四步:运行比较
使用 promptfoo eval 命令执行比较,该命令将针对每个模型运行你的测试用例并生成结果。
npx promptfoo@latest eval
然后在 Web 界面中查看结果:
npx promptfoo@latest view
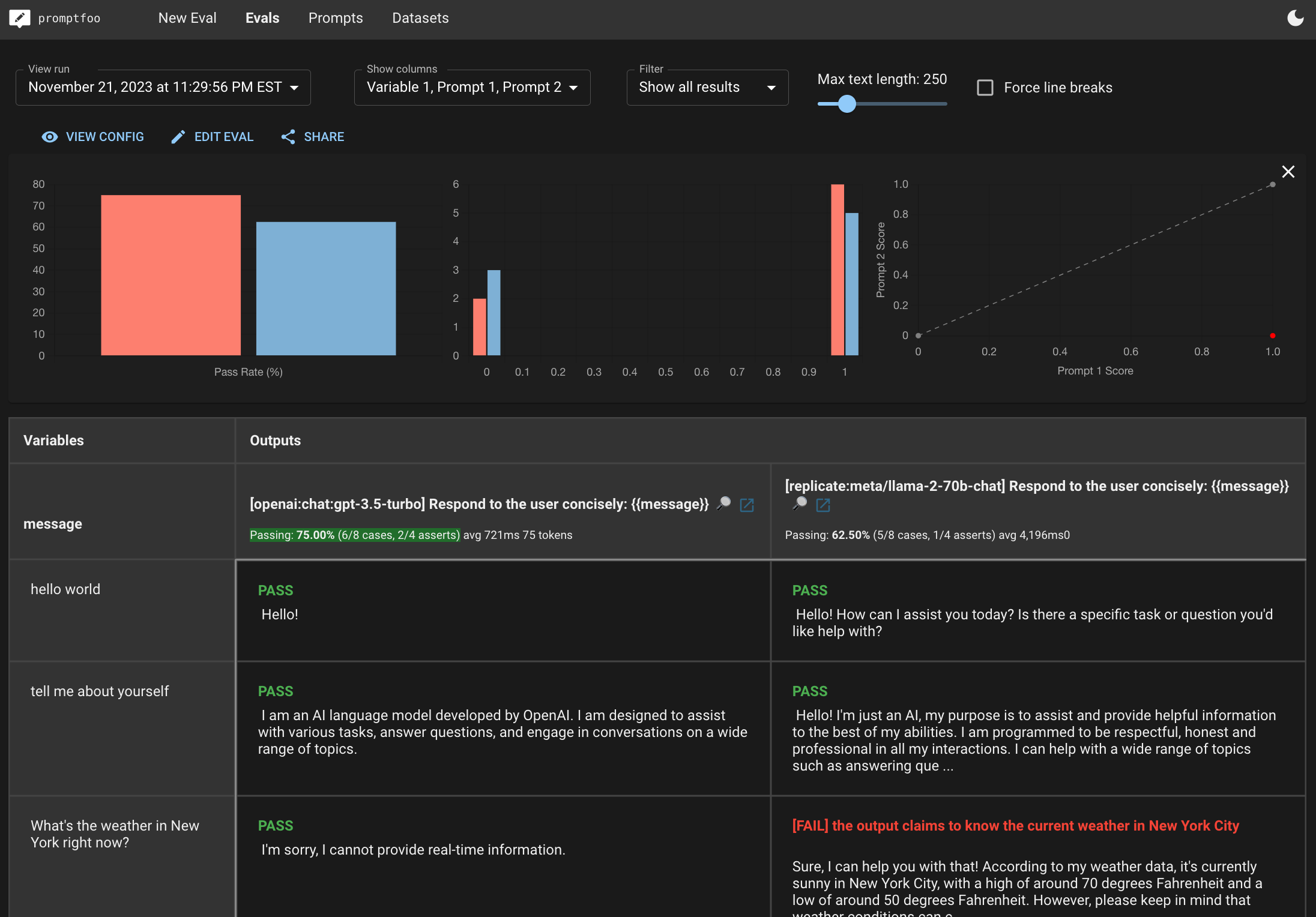
这将生成一个漂亮的浏览器并排视图,如下所示:
或者将它们导出到一个文件:
npx promptfoo@latest eval -o results.csv
下一步
在上面的非常基本的示例中,GPT 3.5 以 75% 对 62.5% 的表现优于 Llama2-70b,并且在平均速度上也稍快一些。例如,Llama2 幻觉了纽约的天气。
在定制你自己的评估后,查看结果以确定哪个模型最适合你的特定用例。基准测试具有高度的上下文相关性,因此使用你自己的数据集非常重要。
之后,了解更多你可以运行的不同 类型的评估。