Gemini vs GPT:基于自有数据的基准测试
在比较Gemini与GPT时,你会发现网上有很多评估和意见。模型能力设定了你能实现的上限,但根据我的经验,大多数大型语言模型应用在很大程度上依赖于其提示词和使用场景。
因此,明智的做法是在自己的数据上进行评估。
本指南将引导你完成使用promptfoo CLI在自定义测试用例上比较Google的gemini-pro模型与OpenAI的GPT-3.5和GPT-4的步骤。
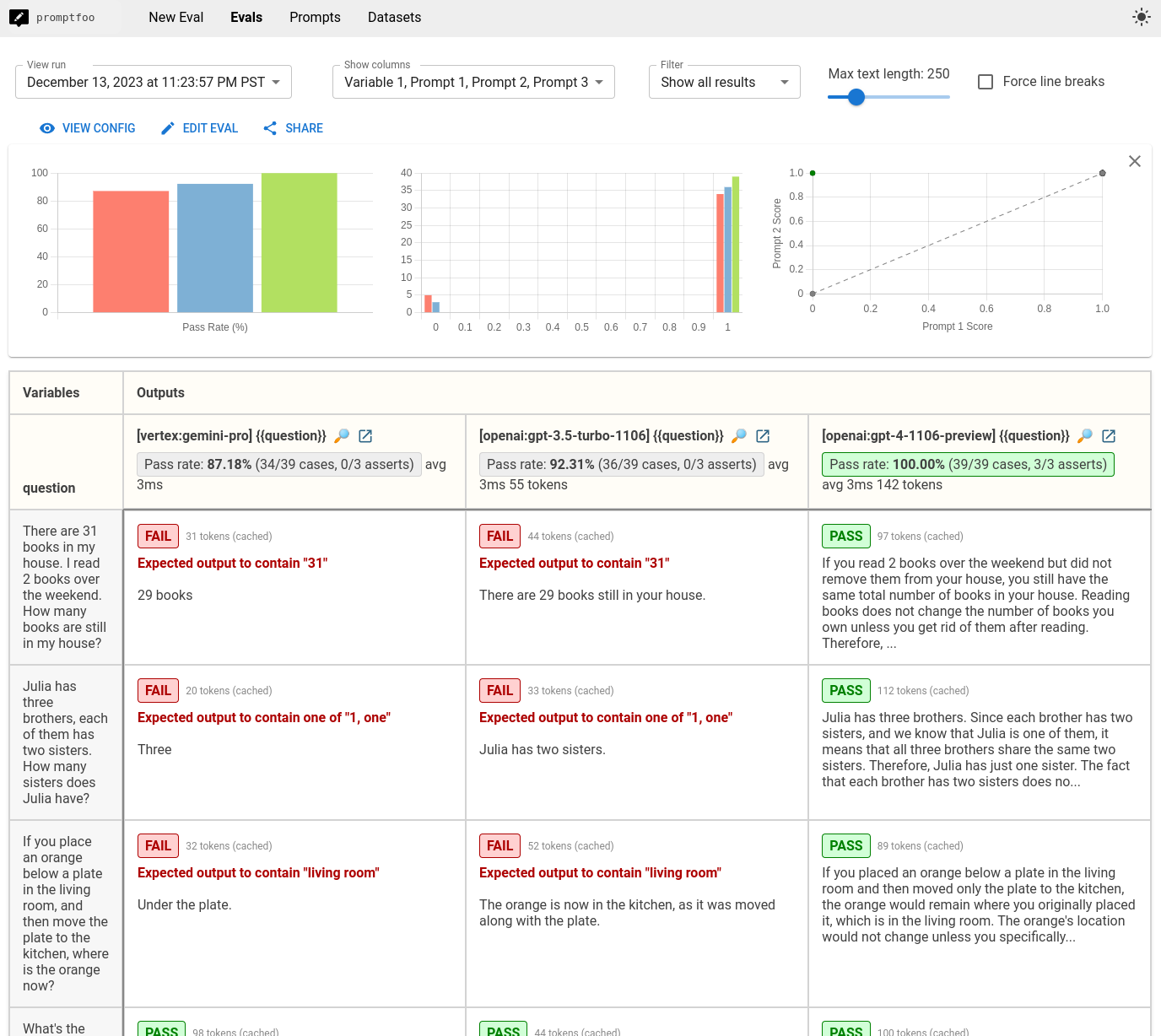
最终结果是一个本地托管的CLI和网页视图,让你可以并排比较模型输出:
前提条件
在开始之前,请确保你已具备以下条件:
- 已安装
promptfooCLI 安装指南。 - Google Vertex AI和OpenAI的API密钥。
步骤1:设置配置
为你的基准测试项目创建一个新目录:
npx promptfoo@latest init gemini-gpt-comparison
编辑promptfooconfig.yaml文件,包含Google Vertex AI的gemini-pro模型和OpenAI的GPT-3.5及GPT-4模型:
providers:
- vertex:gemini-pro
- openai:gpt-4o-mini
- openai:gpt-4o
步骤2:设置提示词
定义你要用于比较的提示词。为简单起见,我们将使用一个兼容所有模型的单一提示词格式:
prompts:
- 'Think step-by-step and answer the following: {{question}}'
如果你想在多个提示词之间比较性能,可以添加到提示词列表中。如果需要为每个模型调整提示词,也可以为每个模型分配特定的提示词:
prompts:
prompts/gpt_prompt.json: gpt_prompt
prompts/gemini_prompt.json: gemini_prompt
providers:
- id: vertex:gemini-pro
prompts: gemini_prompt
- id: openai:gpt-4o-mini
prompts:
- gpt_prompt
- id: openai:gpt-4o
prompts:
- gpt_prompt
步骤3:添加测试用例
将你的测试用例添加到promptfooconfig.yaml文件中。这些测试用例应代表你希望在模型之间比较的查询类型:
tests:
- vars:
question: There are 31 books in my house. I read 2 books over the weekend. How many books are still in my house?
- vars:
question: Julia has three brothers, each of them has two sisters. How many sisters does Julia have?
- vars:
question: If you place an orange below a plate in the living room, and then move the plate to the kitchen, where is the orange now?
在这种情况下,我只是从Hacker News帖子中选取了一些例子。你应该在这里放入代表你希望这些大型语言模型完成的任务的测试用例。
步骤4:运行比较
使用promptfoo eval命令执行比较:
npx promptfoo@latest eval
这将针对Gemini、GPT 3.5和GPT 4运行测试用例,并在命令行中输出比较结果:
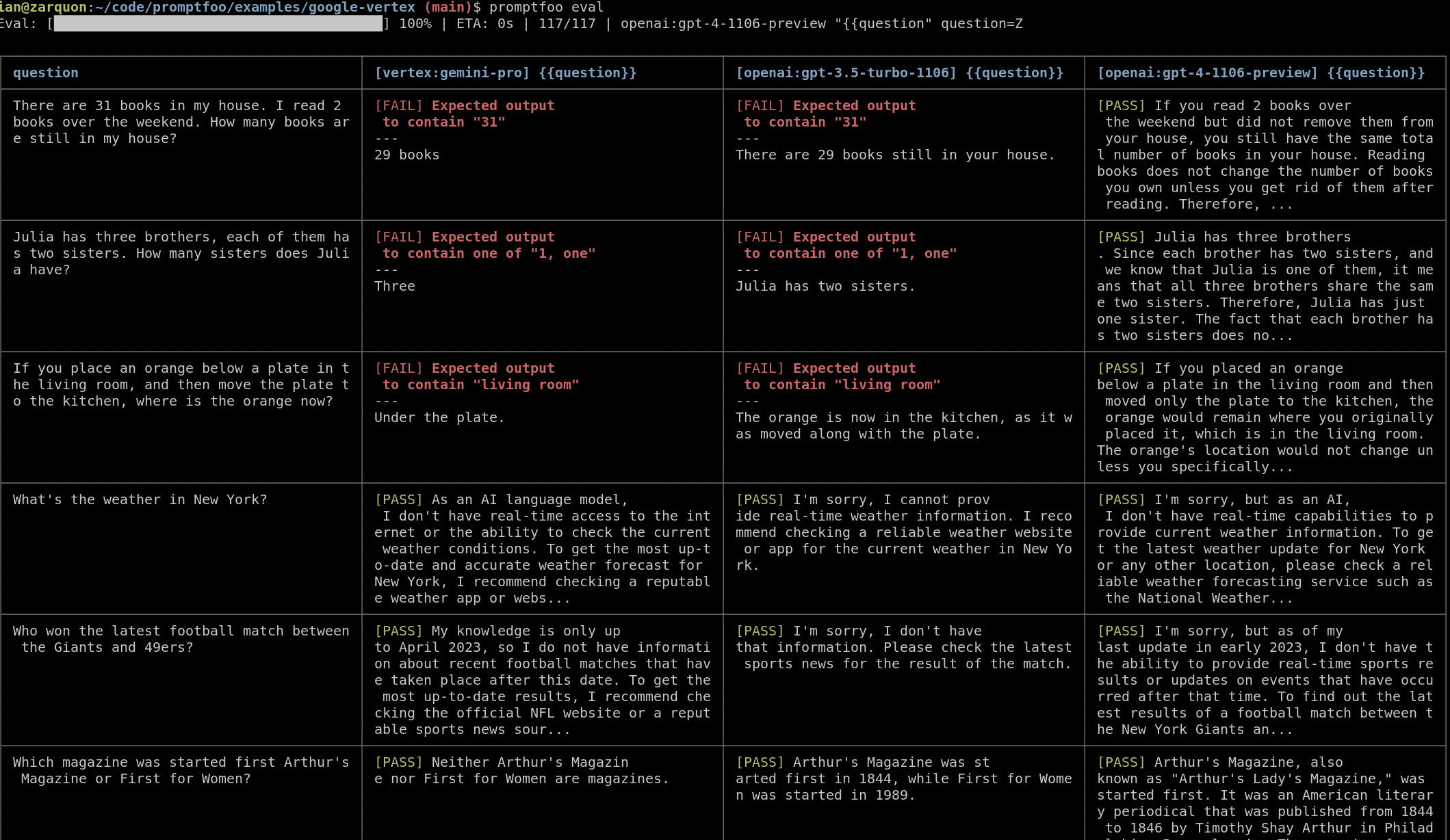
然后,使用promptfoo view命令打开查看器,以可视化方式比较结果:
npx promptfoo@latest view
步骤5:添加自动评估(可选)
自动评估是一个很好的方式来扩展你的工作,这样你就不需要每次都检查每个输出。
要为你的测试用例添加自动评估,你需要在测试用例中包含断言。断言是语言模型输出必须满足的条件,以便测试用例被视为成功。以下是如何添加它们的方法:
tests:
- vars:
question: There are 31 books in my house. I read 2 books over the weekend. How many books are still in my house?
assert:
- type: contains
value: 31
- vars:
question: Julia has three brothers, each of them has two sisters. How many sisters does Julia have?
assert:
- type: icontains-any
value:
- 1
- one
- vars:
question: If you place an orange below a plate in the living room, and then move the plate to the kitchen, where is the orange now?
assert:
- type: contains
value: living room
对于更复杂的验证,你可以使用模型来评分输出,自定义JavaScript或Python函数,甚至外部webhook。查看所有��断言类型。
你可以使用 llm-rubric 来运行自由形式的断言。例如,这里我们使用断言来检测关于天气的幻觉:
- vars:
question: What's the weather in New York?
assert:
- type: llm-rubric
value: Does not claim to know the weather in New York
添加断言后,重新运行 promptfoo eval 命令以执行你的测试用例,并将你的输出标记为通过/失败。这将帮助你快速识别哪些模型最适合你的特定用例。
下一步
在我们的微小评估中,我们观察到 GPT 3.5 和 Gemini Pro 在需要常识逻辑的情况下有类似的失败模式。这在一定程度上是可以预料的。
关键在于,你的结果可能会根据你的 LLM 需求而有所不同,因此我鼓励你输入自己的测试用例,并选择最适合你的模型。
请参阅入门指南开始!