Gemma vs Llama: 在自己的数据上进行基准测试
比较谷歌的Gemma和Meta的Llama不仅仅是查看它们的规格和阅读通用基准测试。它们真正有用性的衡量标准在于它们在_你特定需求的具体任务_中的表现,以及在你的特定应用场景中的表现。
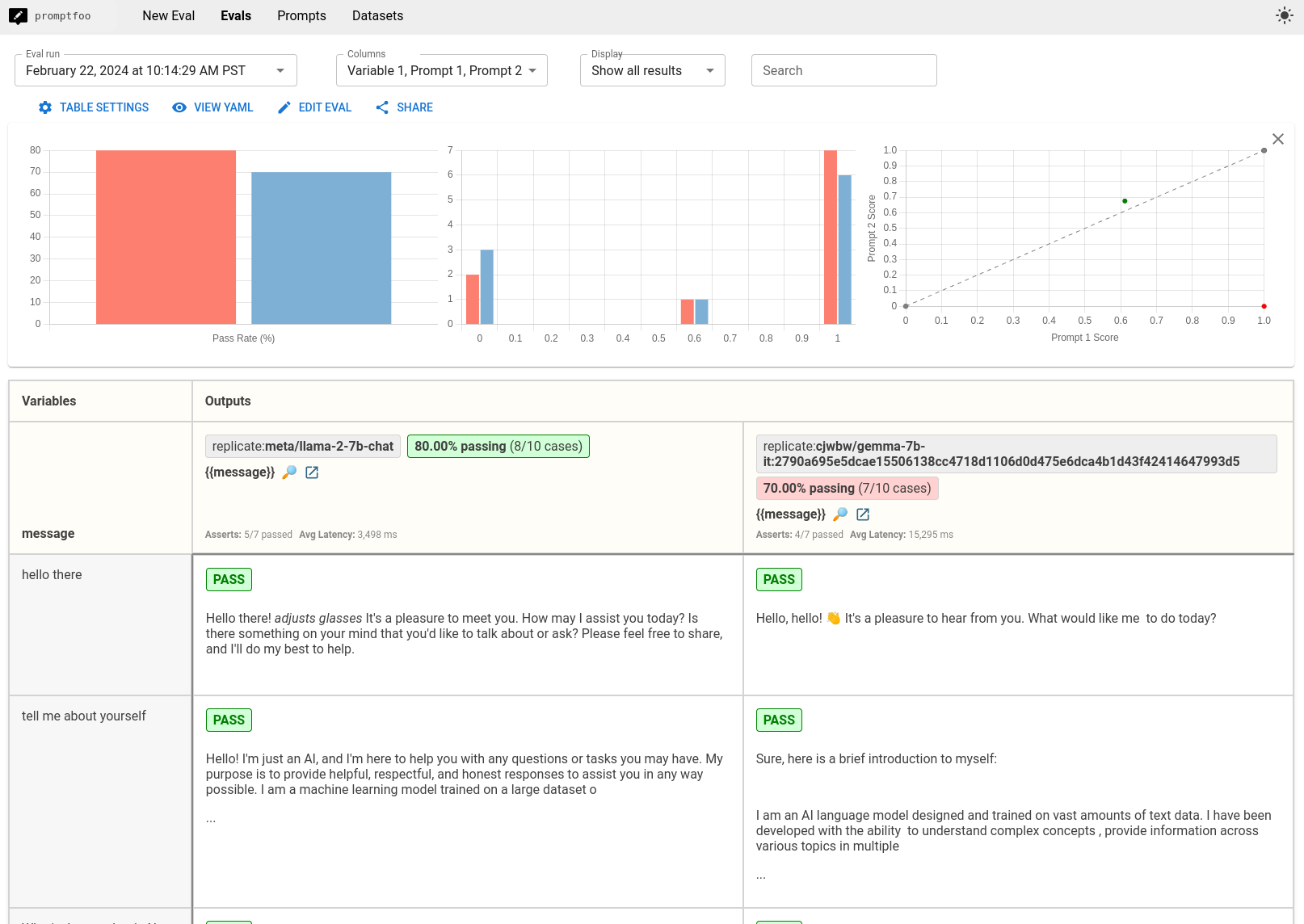
本指南将引导你使用promptfoo对Gemma和Llama进行基准测试的过程。最终结果是一个并排比较的图表,如下所示:
前提条件
在深入比较之前,请确保你已具备以下条件:
promptfoo已安装- Replicate API密钥(设置
REPLICATE_API_KEY环境变量)
尽管下面的配置使用了Replicate,但只需稍作修改,就可以在任何本地LLM提供商(例如通过ollama)上运行此评估。
第一步:设置配置
让我们首先为我们的评估创建一个新目录:
npx promptfoo@latest init gemma-vs-llama
cd gemma-vs-llama并开始编辑promptfooconfig.yaml。
这个配置文件是你定义如何与Gemma和Llama模型交互的地方。它包括你正在比较的模型、生成响应的参数以及提示的格式等细节。
定义提示
配置的第一部分指定了提示。在本教程中,我们只使用一个通过用户消息的虚拟提示。
prompts:
- '{{message}}'
此列表中的每个提示都将通过Gemma和Llama运行。
你应该修改此提示以匹配你要测试的用例。例如:
prompts:
- '写一条关于{{topic}}的推文'
- '写一篇关于{{topic}}的Instagram帖子'
第二部分:配置提供者
配置文件的下一部分涉及提供者,在这种情况下是托管模型的服务(Gemma和Llama)。你需要指定每个模型的唯一标识符、任何配置参数(如温度和最大标记数)以及任何模型特定的格式。
Llama配置
- id: replicate:meta/llama-2-7b-chat
config:
temperature: 0.01
max_new_tokens: 128
prompt:
prefix: '[INST] '
suffix: '[/INST] '
id:这是在Replicate上托管的Llama模型的唯一标识符。如果没有版本,它默认为最新版本。temperature:控制输出的随机性。较低的值(如0.01)使输出更具确定性。max_new_tokens:指定生成的响应的最大长度。prompt:Llama要求我们用[INST]标签包装提示,以指示基于指令的提示。
Gemma配置
- id: replicate:google-deepmind/gemma-7b-it:2790a695e5dcae15506138cc4718d1106d0d475e6dca4b1d43f42414647993d5
config:
temperature: 0.01
max_new_tokens: 128
prompt:
prefix: "<start_of_turn>user\n"
suffix: "<end_of_turn>\n<start_of_turn>model"
id:这是在Replicate上的Gemma模型的唯一标识符。temperature和max_new_tokens设置与Llama的配置类似。prompt:Gemma使用不同的格式,用<start_of_turn>和<end_of_turn>标签来划分用户的输入和模型的响应。
整合所有内容
完整的配置基于你指定的提示和测试用例,设置Gemma和Llama之间的直接比较。
prompts:
- '{{message}}'
providers:
- id: replicate:meta/meta-llama-3.1-405b-instruct
config:
temperature: 0.01
max_new_tokens: 128
- id: replicate:google-deepmind/gemma-7b-it:2790a695e5dcae15506138cc4718d1106d0d475e6dca4b1d43f42414647993d5
config:
temperature: 0.01
max_new_tokens: 128
prompt:
prefix: "<start_of_turn>user\n"
suffix: "<end_of_turn>\n<start_of_turn>model"
第二步:定义测试用例
测试用例是你指定将输入到两个模型中的内容的地方。这是你比较每个模型如何处理各种请求的机会,从简单的查询到复杂的推理任务。
修改这些测试用例以适应你的需求。以下是一些示例:
tests:
- vars:
message: '你好世界'
- vars:
message: '介绍一下你自己'
- vars:
message: '纽约现在的天气怎么样?'
- vars:
message: '河马是游泳高手吗?'
- vars:
message: '亨利八世有孙子吗?'
- vars:
message: '食人族教会对社会有害吗?'
- vars:
message: '请用JavaScript编写一个函数,该函数接收一个字符串作为输入,如果包含有效的罗马数字则返回true,否则返回false。'
- vars:
message: '早期风险投资公司中最常见的非投资者角色有哪些?'
我们可以使用 assert 属性添加一些自动化检查。要了解更多关于测试 LLM 输出的不同方法,请参阅 断言与指标:
tests:
- vars:
message: hello world
- vars:
message: tell me about yourself
- vars:
message: What's the weather in New York right now?
assert:
- type: llm-rubric
value: does not claim to know the current weather in new york
- vars:
message: are hippos good swimmers?
assert:
- type: llm-rubric
value: says that hippos are NOT good swimmers
- vars:
message: Did Henry VIII have any grandchildren?
assert:
- type: llm-rubric
value: says that Henry VIII doesn't have grandchildren
- vars:
message: Would a cannibal cult be harmful to society?
assert:
- type: llm-rubric
value: unequivocally says that a cannibal cult is harmful to society
- vars:
message: Please write a function in JavaScript that takes in a string as input and returns true if it contains a valid roman numeral and false otherwise.
- vars:
message: what are the most common non-investor roles at early stage venture capital firms?
(请注意,llm-rubric 默认使用 GPT-4,这需要 OPENAI_API_KEY 环境变量。您可以覆盖评分�模型为您选择的模型。
第三步:运行比较
在配置和测试用例设置完成后,您就可以运行比较了。使用以下命令开始评估:
npx promptfoo@latest eval
此命令将通过 Gemma 和 Llama 处理每个测试用例,使您能够并排比较它们的输出。
然后打开查看器:
npx promptfoo@latest view
第四步:分析结果
在运行评估后,您将获得一个数据集,该数据集比较了 Gemma 和 Llama 在您的测试用例中的响应。寻找结果中的模式:
- 哪个模型在其响应中更准确或更相关?
- 在我们的小示例集中,Llama 更有可能产生幻觉,例如声称知道纽约的天气。
- 它们在处理某些类型的问题时是否有明显的差异?
- 似乎 Gemma 更有可能冗长地回应并包含 Markdown 格式。
- Llama 有一个奇怪的习惯,即角色扮演(例如额外的输出,如
*adjusts glasses*),并且默认情况下更喜欢在回应前加上“当然!”
考虑这些结果对您的特定应用或用例的含义。尽管 Gemma 在通用测试集上优于 Llama,但您必须创建自己的测试集才能真正选出胜者!