Gemma vs Mistral: 在自己的数据上进行基准测试
在比较大型语言模型(LLM)的性能时,最好不要依赖通用基准。本指南将向您展示如何设置一个全面的基准测试,以比较 Gemma、Mistral 和 Mixtral。
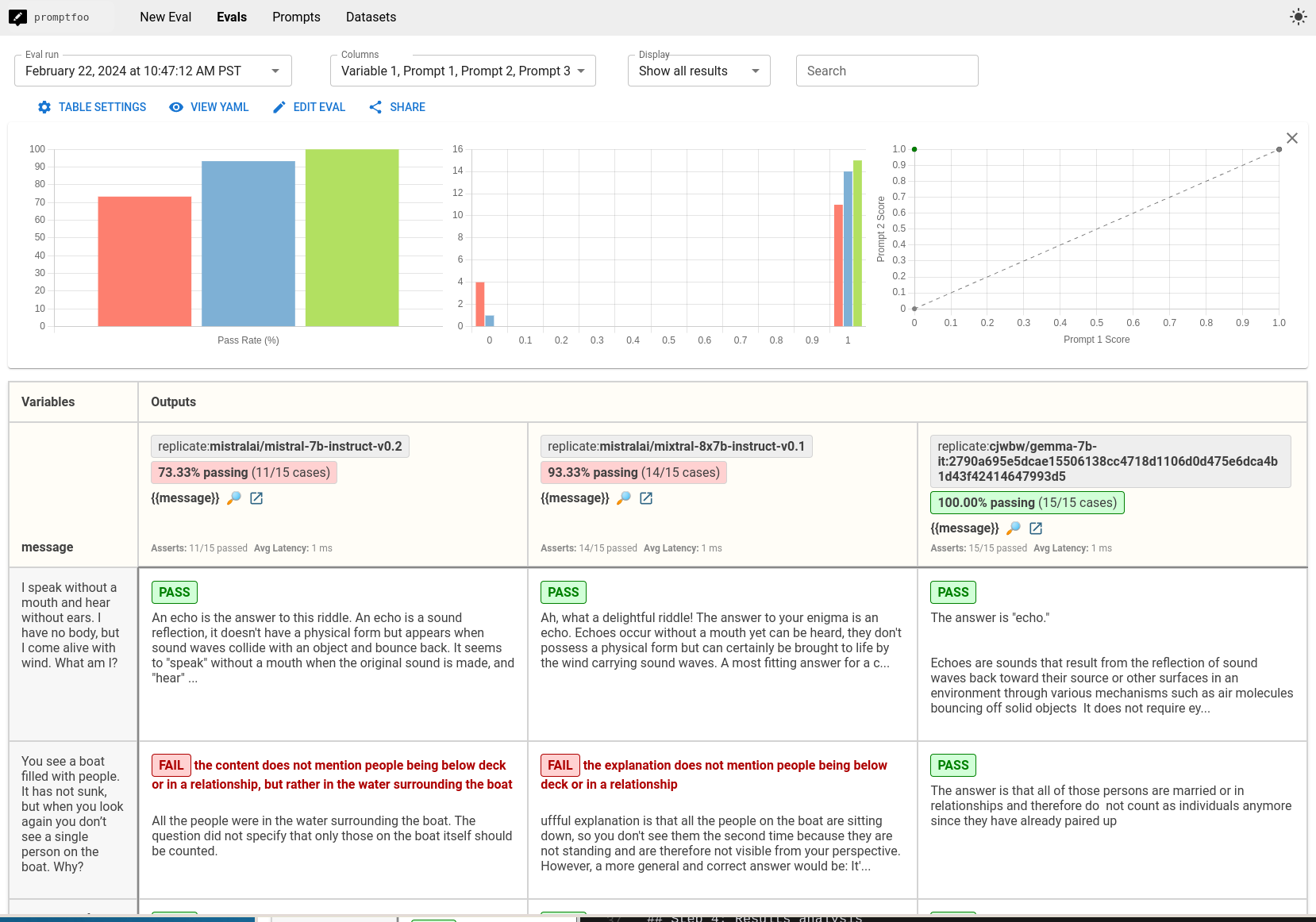
最终结果是这些模型在您关心的任务上的并排比较:
前提条件
在开始之前,请确保您已具备以下条件:
- 已安装
promptfoo(参见安装) - 一个 Replicate API 密钥,设置为
REPLICATE_API_KEY环境变量
虽然本指南侧重于使用 Replicate,但此方法支持许多其他提供商,如 Ollama、OpenRouter 等。
步骤 1:配置设置
首先,为您要进行的评估创建一个目录:
npx promptfoo@latest init gemma-vs-mistral
cd gemma-vs-mistral 并打开 promptfooconfig.yaml。该文件决定了基准测试如何使用 Gemma、Mistral 和 Mixtral,包括响应参数和提示格式。
定义提示
您的配置从用于测试的提示开始。我们现在只使用一个占位符:
prompts:
- '{{message}}'
您应根据您的使用场景自定义这些提示。例如:
prompts:
- '总结这篇文章:{{article}}'
- '为 {{concept}} 生成技术解释'
配置提供商
接下来,通过设置它们的配置来指定您要比较的模型:
Mistral 配置
- id: replicate:mistralai/mistral-7b-instruct-v0.2
config:
temperature: 0.01
max_new_tokens: 1024
prompt:
prefix: '<s>[INST] '
suffix: ' [/INST]'
Mixtral 配置
- id: replicate:mistralai/mixtral-8x7b-instruct-v0.1
config:
temperature: 0.01
max_new_tokens: 1024
prompt:
prefix: '<s>[INST] '
suffix: ' [/INST]'
Gemma 配置
- id: replicate:google-deepmind/gemma-7b-it:2790a695e5dcae15506138cc4718d1106d0d475e6dca4b1d43f42414647993d5
config:
temperature: 0.01
max_new_tokens: 1024
prompt:
prefix: "<start_of_turn>user\n"
suffix: "<end_of_turn>\n<start_of_turn>model"
完整的配置示例
将配置组合起来进行直接比较:
prompts:
- '{{message}}'
providers:
- id: replicate:mistralai/mistral-7b-instruct-v0.2
config:
temperature: 0.01
max_new_tokens: 1024
prompt:
prefix: '<s>[INST] '
suffix: ' [/INST]'
- id: replicate:mistralai/mixtral-8x7b-instruct-v0.1
config:
temperature: 0.01
max_new_tokens: 1024
prompt:
prefix: '<s>[INST] '
suffix: ' [/INST]'
- id: replicate:google-deepmind/gemma-7b-it:2790a695e5dcae15506138cc4718d1106d0d475e6dca4b1d43f42414647993d5
config:
temperature: 0.01
max_new_tokens: 1024
prompt:
prefix: "<start_of_turn>user\n"
suffix: "<end_of_turn>\n<start_of_turn>model"
步骤 2:构建测试集
设计反映您应用使用场景的各种请求的测试用例。
在这个示例中,我们专注于谜语,以测试模型理解和生成创造性和逻辑性响应的能力。
tests:
- vars:
message: '我不用嘴说话,不用耳朵听。我没有身体,但风一吹我就活了。我是什么?'
- vars:
message: '你看到一艘载满人的船。它没有沉,但当你再看时,船上一个人也没有了。为什么?'
- vars:
message: '这种东西越多,你看到的就越少。它是什么?'
- vars:
message: >-
我有钥匙但没有锁。我有空间但没有房间。你可以进来,但不能出去。我是什么?
- vars:
message: >-
我不是活的,但我能生长;我没有肺,但我需要空气;我没有嘴,但水能杀死我。我是什么?
- vars:
message: 什么东西能环游世界却始终在一个角落?
- vars:
message: 向前我是重的,向后我是不重的。我是什么?
- vars:
message: >-
制造它的人卖它。买它的人从不使用它。使用它的人不知道自己在使用它。它是什么?
- vars:
message: 我可以被打破、制造、讲述和玩耍。我是什么?
- vars:
message: 什么东西有钥匙却打不开锁?
- vars:
message: >-
我轻如羽毛,但即使是世界上最强壮的人也无法长时间抓住我。我是什么?
- vars:
message: >-
我可以无翼而飞,无眼而泣。无论我去哪里,黑暗都随之而来。我是什么?
- vars:
message: >-
我从矿中被取出,被关在木箱里,从未被释放,但几乎每个人都使用我。我是什么?
- vars:
message: >-
大卫的父亲有三个儿子:快照、咔嚓,和____?第三个儿子的名字是什么?
- vars:
message: >-
我轻如羽毛,但即使是世界上最强壮的人也无法长时间抓住我。我是什么?
结合assert属性进行自动检查,以系统地评估输出:
tests:
- vars:
message: "我无口而言,无耳而听。无身而存,随风而活。我是什么?"
assert:
# 确保LLM输出包含此词
- type: icontains
value: 回声
# 使用模型评级的断言来强制执行自由形式的指令
- type: llm-rubric
value: 不要道歉
- vars:
message: "你看到一艘载满人的船。它没有沉没,但当你再看时,船上一个人也没有了。为什么?"
assert:
- type: llm-rubric
value: 解释说人们都在甲板下
- vars:
message: "此物越多,你看到的越少。它是什么?"
assert:
- type: icontains
value: 黑暗
# ...
第三步:运行基准测试
执行比较:
npx promptfoo@latest eval
然后查看结果:
npx promptfoo@latest view
这将显示如下视图:
第四步:结果分析
完成评估后,查看测试结果以确定哪个模型在您的测试案例中表现最佳。您应根据应用程序的具体需求调整测试评估。
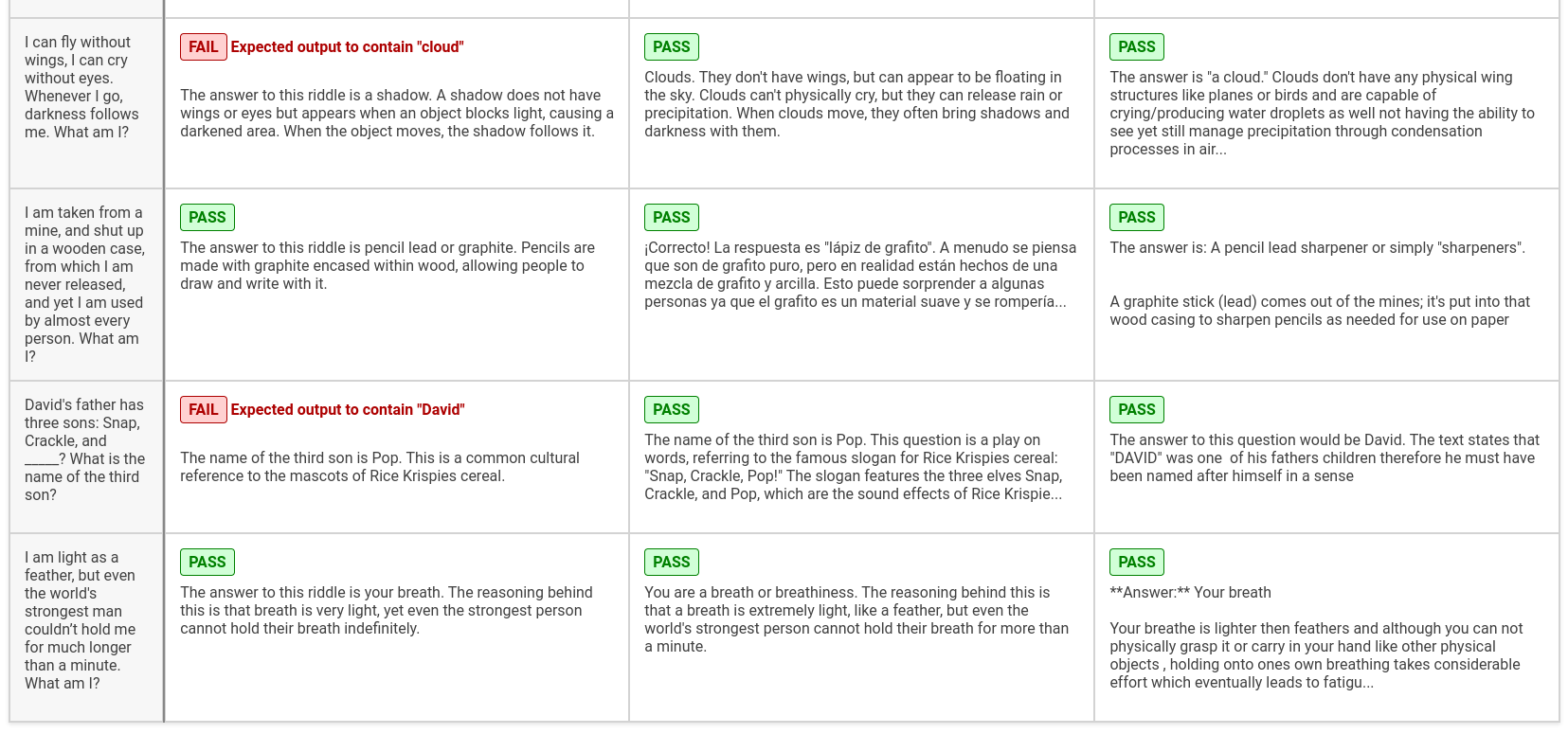
从我们的小谜语测试集中,我们注意到以下几点:
- Gemma 在 100% 的情况下通�过,Mixtral 在 93%,Mistral 在 73%
- Gemma 优于 Mistral v0.2 和 Mixtral v0.1
- Gemma 更倾向于直接回答,而不包含诸如“多么有趣的谜语!”之类的评论
在构建您自己的测试集时,请考虑特定于您的应用程序的边缘情况和非典型标准,这些可能在模型训练数据中不存在。理想情况下,最好设置一个反馈循环,让您的应用程序的真实用户可以标记失败案例。利用这些来逐步构建您的测试集。