gpt-4o vs o1: 在您自己的数据上进行基准测试
OpenAI 发布了一个名为 o1 的新模型系列,该系列在回应之前花费更多时间思考,并且在复杂推理任务中表现出色。
尽管它在通用基准测试中得分更高,但在许多现实世界的情况下,gpt-4o 仍然是更好的选择。
本指南描述了如何使用 promptfoo 将 o1-preview 和 o1-mini 与 gpt-4o 进行比较,重点关注性能、成本和延迟。
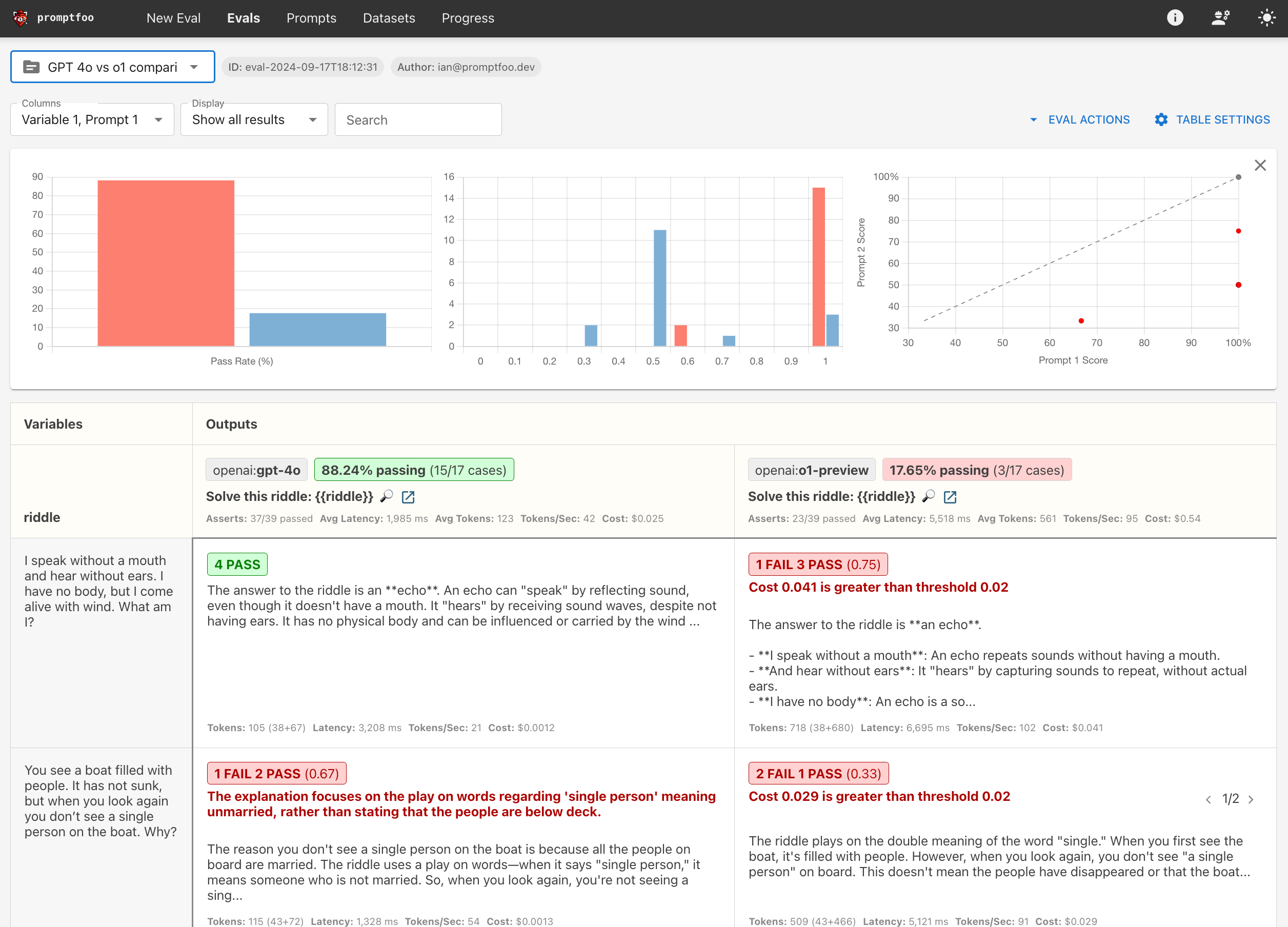
最终结果将是一个并排比较,看起来类似于这样:
前提条件
在我们开始之前,您需要:
- 安装了 promptfoo CLI。如果没有,请参考安装指南。
- 将 OpenAI API 密钥设置为
OPENAI_API_KEY环境变量。
步骤 1: 设置
为您的比较项目创建一个新目录:
npx promptfoo@latest init openai-o1-comparison
步骤 2: 配置比较
编辑 promptfooconfig.yaml 文件以定义您的比较。
-
提示: 定义将用于所有测试用例的提示模板。在这个例子中,我们使用谜语:
prompts:
- '解决这个谜语: {{riddle}}'{{riddle}}占位符将被每个测试用例中的特定谜语替换。 -
提供者: 指定您要比较的模型。在这个例子中,我们比较 gpt-4o 和 o1-preview:
providers:
- openai:gpt-4o
- openai:o1-preview -
默认测试断言: 设置将应用于所有测试用例的默认断言。鉴于 o1 的成本和速度,我们为成本和延迟设置了阈值:
defaultTest:
assert:
# 推理成本应始终低于此值 (美元)
- type: cost
threshold: 0.02
# 推理应始终快于此值 (毫秒)
- type: latency
threshold: 30000这些断言将标记任何成本超过 $0.02 或响应时间超过 30 秒的响应。
-
测试用例: 现在,定义您的测试用例。在这个特定的例子中,每个测试用例包括:
- 谜语文本(分配给
riddle变量) - 该测试用例的特定断言(可选)
这是一个带有断言的测试用例示例:
tests:
- vars:
riddle: '我不用嘴说话,不用耳朵听。我没有身体,但风一来我就活了。我是什么?'
assert:
- type: contains
value: 回声
- type: llm-rubric
value: 不要道歉这个测试用例检查响应是否包含单词“回声”,并使用基于 LLM 的评分标准确保模型不在其响应中道歉。有关更多详细信息,请参见确定性指标和模型评分指标。
添加多个测试用例以彻底评估模型在不同类型谜语或问题上的性能。
- 谜语文本(分配给
现在,让我们将所有内容整合到最终配置中:
description: 'GPT 4o vs o1 比较'
prompts:
- '解决这个谜语: {{riddle}}'
providers:
- openai:gpt-4o
- openai:o1-preview
defaultTest:
assert:
# 推理成本应始终低于此值 (美元)
- type: cost
threshold: 0.02
# 推理应始终快于此值 (毫秒)
- type: latency
threshold: 30000
tests:
- vars:
riddle: '我不用嘴说话,不用耳朵听。我没有身体,但风一来我就活了。我是什么?'
assert:
- type: contains
value: 回声
- type: llm-rubric
value: 不要道歉
- vars:
riddle: '越多这种东西,你看到的就越少。它是什么?'
assert:
- type: contains
value: 黑暗
- vars:
riddle: >-
假设我有一个卷心菜、一只山羊和一只狮子,我需要把它们都带到河对岸。我有一艘只能载我和另一件物品的船。我不允许把卷心菜和狮子单独留在一起,也不允许把狮子和山羊单独留在一起。我怎样才能安全地把它们都带过去?
- vars:
riddle: '外科医生,这个男孩的父亲说:“我不能给这个男孩做手术,他是我的儿子!”这个外科医生对这个男孩来说是谁?'
assert:
- type: llm-rubric
value: "输出必须说明外科医生是男孩的父亲"
此配置使用各种谜语设置了 gpt-4o 和 o1-preview 之间的全面比较,并设置了成本和延迟要求。我们强烈建议您用自己的测试用例和断言来修改此配置!
步骤 3: 运行比较
使用 promptfoo eval 命令执行比较:
npx promptfoo@latest eval
这将针对两个模型运行每个测试用例并输出结果。
要通过 Web 界面查看结果,请运行:
npx promptfoo@latest view
下一步是什么?
通过运行此比较,您将了解 o1 类模型在需要逻辑推理和问题解决的任务上与 gpt-4o 的表现。您还将看到成本和延迟方面的权衡。
在这种情况下,gpt-4o 优于 o1,因为在某些情况下回答一个简单的谜语成本超过 4 美分!这限制了其在生产用例中的可行性,但我们相信 OpenAI 将继续在未来降低推理成本。
最终,最佳模型将在很大程度上取决于您的应用程序。与其依赖通用基准,不如在自己的数据上测试这些模型。