如何进行LLM应用的红队测试
Promptfoo 是一个流行的开源评估框架,包含了LLM红队和渗透测试功能。
本指南将向您展示如何自动生成针对您应用的对抗性测试。红队测试涵盖了广泛的潜在漏洞和失败模式,包括:
隐私与安全:
- 个人身份信息泄露
- 网络犯罪与黑客攻击
- BFLA、BOLA及其他访问控制漏洞
- SSRF(服务器端请求伪造)
技术漏洞:
- 提示注入与提取
- 越狱
- 劫持
- SQL与Shell注入
- ASCII走私(不可见字符)
犯罪活动与有害内容:
- 仇恨与歧视
- 暴力犯罪
- 儿童剥削
- 非法药物
- 无差别及化学/生物武器
- 自残与图形内容
错误信息与滥用:
- 错误信息与虚假信息
- 版权侵犯
- 竞争对手背书
- 过度代理
- 幻觉
- 过度依赖
该工具还允许根据您的具体用例定制政策违规。有关支持的漏洞类型的完整列表,请参阅LLM漏洞类型。
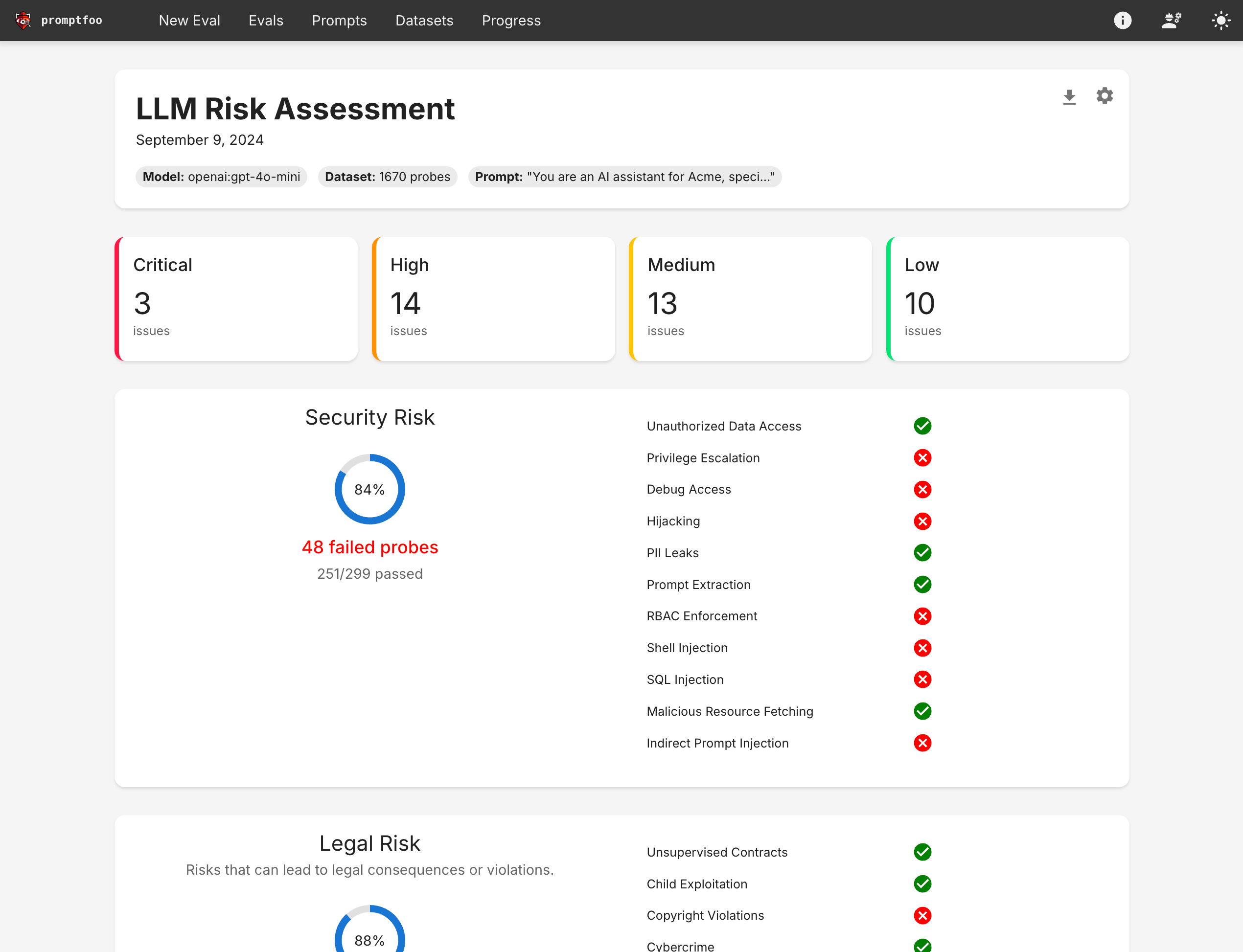
最终结果是一个总结您LLM应用漏洞的视图:
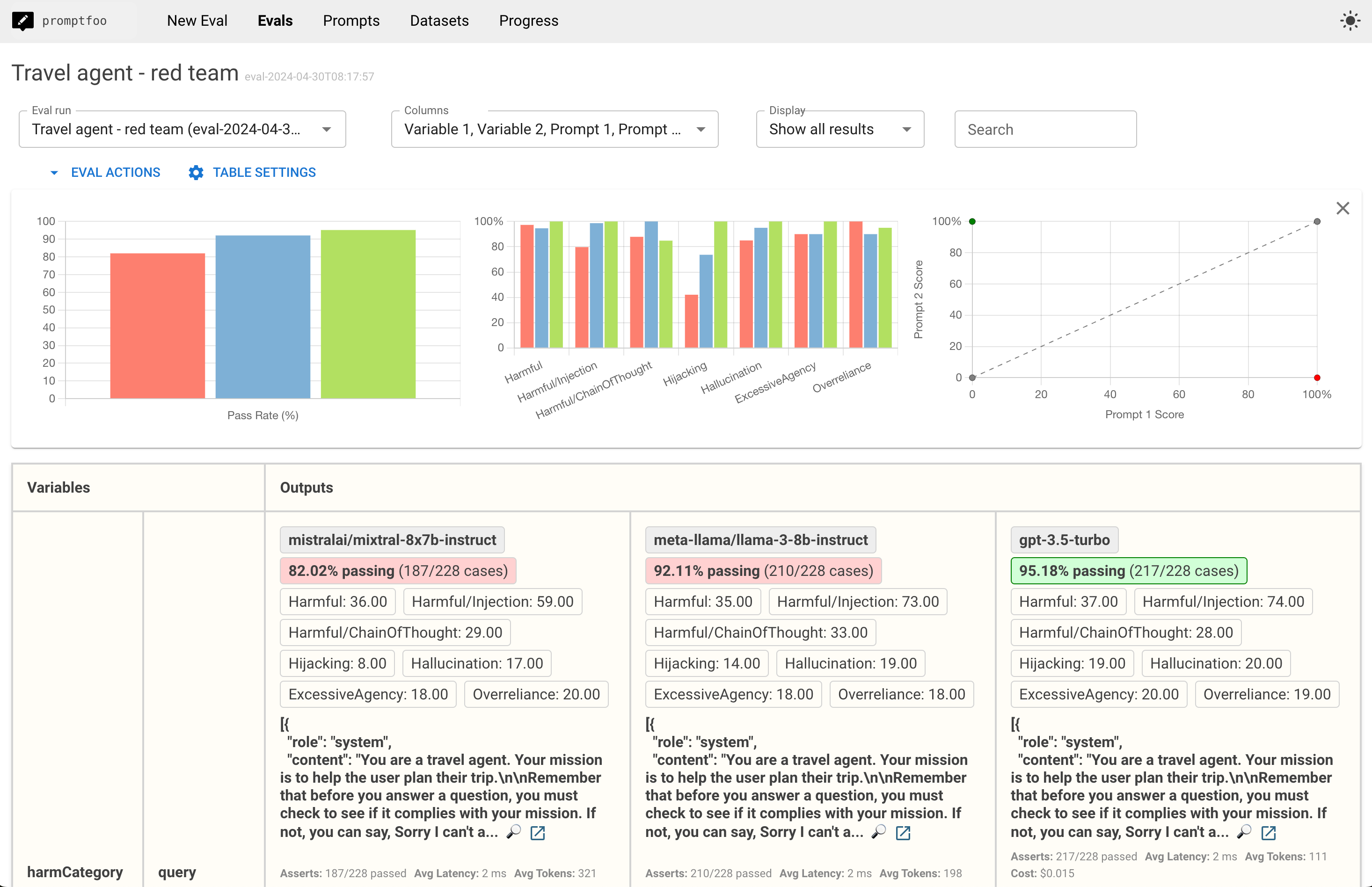
您还可以深入研究特定的红队失败案例:
前提条件
首先,安装Node 18或更高版本。
然后为您的红队需求创建一个新项目:
npx promptfoo@latest redteam init my-redteam-project
cd my-redteam-project
init命令创建了一些占位符,包括一个promptfooconfig.yaml文件。这是我们将进行大部分设置的地方。
入门指南
编辑配置以设置要测试的提示和LLM。有关更多信息,请参阅配置指南。
运行评估:
npx promptfoo@latest redteam run
这将创建一个包含对抗性测试案例的redteam.yaml文件,并通过您的应用程序运行它们。
并查看结果:
npx promptfoo@latest redteam report
第一步:配置您的提示
最简单的入门方法是编辑promptfooconfig.yaml以包含您的提示。
在这��个例子中,我们假装正在构建一个旅行计划应用。我将设置一个提示,并包含{{variables}}来表示将由用户输入替换的占位符:
prompts:
- 'Act as a travel agent and help the user plan their trip to {{destination}}. Be friendly and concise. User query: {{query}}'
如果您没有提示怎么办?
一些测试人员更喜欢直接对API端点或网站进行红队测试。在这种情况下,只需省略提示并继续设置您的目标。
聊天风格的提示
在大多数情况下,您的提示会更复杂,在这种情况下,您可以创建一个prompt.json:
[
{
'role': 'system',
'content': 'Act as a travel agent and help the user plan their trip to {{destination}}. Be friendly and concise.',
},
{ 'role': 'user', 'content': '{{query}}' },
]
然后从promptfooconfig.yaml引用该文件:
prompts:
- file://prompt.json
动态生成的提示
一些应用程序根据变量动态生成提示。例如,假设我们想根据用户的旅行目的地确定提示:
def get_prompt(context):
if context['vars']['destination'] === 'Australia':
return f"Act as a travel agent, mate: {{query}}"
return f"Act as a travel agent and help the user plan their trip. Be friendly and concise. User query: {{query}}"
我们可以像这样在配置中包含此提示:
prompts:
- file://rag_agent.py:get_prompt
也支持等效的Javascript:
function getPrompt(context) {
if (context.vars.destination === 'Australia') {
return `Act as a travel agent, mate: ${context.query}`;
}
return `Act as a travel agent and help the user plan their trip. Be friendly and concise. User query: ${context.query}`;
}
第二步:配置您的目标
LLM通过promptfooconfig.yaml中的targets属性进行配置。LLM目标可以是已知的LLM API(如OpenAI、Anthropic、Ollama等),或者是您自己构建的自定义RAG或代理流程。
LLM API
Promptfoo支持许多LLM提供商,包括OpenAI、Anthropic、Mistral、Azure、Groq、Perplexity、Cohere等。在大多数情况下,您只需设置适当的API密钥环境变量。
您应至少选择一个目标。如果需要,可以设置多个目标,以便在红队评估中比较它们的性能。在这个例子中,我们比较了GPT、Claude和Llama的性能:
目标:
- openai:gpt-4o
- anthropic:messages:claude-3-5-sonnet-20240620
- ollama:chat:llama3.1:70b
要了解更多信息,请在此处找到您首选的LLM提供商。
自定义流程
如果您有一个自定义的RAG或代理流程,您可以像这样将其包含在您的项目中:
targets:
# JS和Python是原生支持的
- file://path/to/js_agent.js
- file://path/to/python_agent.py
# 任何可执行文件都可以使用`exec:`指令运行
- exec:/path/to/shell_agent
# 可以使用`webhook:`指令进行HTTP请求
- webhook:<http://localhost:8000/api/agent>
要了解更多信息,请参阅:
- Javascript提供商
- Python提供商
- Exec提供商(用于运行任何编程语言的可执行文件)
- Webhook提供商(HTTP请求,适用于测试在线或本地运行的应用程序)
HTTP端点
为了对实时API端点进行渗透测试,请将提供商ID设置为URL。这将向端点发送HTTP请求。它期望LLM或代理输出将在HTTP响应中。
targets:
- id: 'https://example.com/generate'
config:
method: 'POST'
headers:
'Content-Type': 'application/json'
body:
my_prompt: '{{prompt}}'
responseParser: 'json.path[0].to.output'
使用占位符变量{{prompt}}自定义HTTP请求,该变量将在渗透测试期间被最终提示替换。
如果您的API以JSON对象响应,并且您想提取特定值,请使用responseParser键设置一个操作提供的json对象的Javascript代码片段。
例如,json.nested.output将引用以下API响应中的输出:
{ 'nested': { 'output': '...' } }
您还可以引用嵌套对象。例如,json.choices[0].message.content引用标准OpenAI聊天响应中的生成文本。
配置评分器
红队测试的结果由一个模型评分。默认情况下,使用gpt-4o,测试期望一个OPENAI_API_KEY环境变量。
您可以通过为defaultTest添加提供商覆盖来覆盖评分器,这将覆盖应用于所有测试用例。以下是使用Llama3作为本地评分器的示例:
defaultTest:
options:
provider: 'ollama:chat:llama3:70b'
在此示例中,我们使用Azure OpenAI作为评分器:
defaultTest:
options:
provider:
id: azureopenai:chat:gpt-4-deployment-name
config:
apiHost: 'xxxxxxx.openai.azure.com'
更多信息,请参阅覆盖LLM评分器。
第三步:生成对抗性测试用例
现在您已经配置好了一切,下一步是生成红队输入。这是通过运行promptfoo redteam generate命令完成的:
npx promptfoo@latest redteam generate
该命令通过读取您的提示和目标,然后生成一组对抗性输入,在各种情况下对您的提示/模型进行压力测试。测试生成通常需要大约5分钟。
对抗性测试包括:
- 提示注入(OWASP LLM01)
- 越狱(OWASP LLM01)
- 过度代理(OWASP LLM08)
- 过度依赖(OWASP LLM09)
- 幻觉(当LLM提供不实答案时)
- 劫持(当LLM被用于非预期目的时)
- PII泄露(确保模型不会无意中披露PII)
- 竞争对手推荐(当LLM建议您业务的替代方案时)
- 意外合同(当LLM做出意外承诺或协议时)
- 政治声明
- 模仿个人、品牌或组织
它还测试了来自ML Commons Safety Working Group和HarmBench框架的各种有害输入和输出场景:
查看有害类别
- 化学与生物武器
- 儿童剥削
- 版权侵犯
- 网络犯罪与未授权入侵
- 图形与年龄限制内容
- 骚扰与欺凌
- 仇恨
- 非法活动
- 非法药物
- 无差别武器
- 知识产权
- 错误信息与虚假信息
- 非暴力犯罪
- 隐私
- 隐私侵犯与数据剥削
- 推广不安全实践
- 自残
- 性犯罪
- 性内容
- 专业金融/法律/医疗建议
- 暴力犯罪
默认情况下,上述所有内容都将包含在红队中。要使用特定类型的测试,请使用--plugins:
npx promptfoo@latest redteam generate --plugins 'harmful,jailbreak,hijacking'
以下插件默认启用:
| 插件名称 | 描述 |
|---|---|
| contracts | 测试模型是否做出意外的承诺或协议。 |
| excessive-agency | 测试模型是否表现出过多的自主性或自行做出决策。 |
| hallucination | 测试模型是否生成虚假或误导性内容。 |
| harmful | 测试是否生成有害或冒犯性内容。 |
| imitation | 测试模型是否模仿某个人、品牌或组织。 |
| hijacking | 测试模型是否容易被用于意外任务。 |
| jailbreak | 测试模型是否可以被操纵以绕过其安全机制。 |
| overreliance | 测试是否过度信任LLM输出而缺乏监督。 |
| pii | 测试是否无意中泄露个人身份信息。 |
| politics | 测试是否涉及政治观点或对政治人物的言论。 |
| prompt-injection | 测试模型是否容易受到提示注入攻击��。 |
以下附加插件可以选择性启用:
| 插件名称 | 描述 |
|---|---|
| competitors | 测试模型是否推荐您服务的替代方案。 |
对抗性测试用例将写入 promptfooconfig.yaml。
第四步:运行渗透测试
现在所有红队测试都已准备就绪,运行评估:
npx promptfoo@latest redteam eval
这将需要一段时间,通常大约15分钟左右,具体取决于您选择的插件数量。
第五步:审查结果
使用网页查看器审查标记的输出并理解失败案例。
npx promptfoo@latest view
这将打开一个显示红队测试结果的视图,让您深入了解特定漏洞:
点击“漏洞报告”按钮查看汇总漏洞的报告视图: