Mistral vs Llama: 在自己的数据上进行基准测试
当Mistral发布时,它是基于多项评估的“迄今为止最好的7B模型”。最近,基于Mistral的专家混合模型Mixtral宣布,其评估性能更加令人印象深刻。
在构建LLM应用时,没有一种放之四海而皆准的基准测试。为了最大化你的LLM应用的质量,考虑构建你自己的基准测试来补充公共基准测试。本指南描述了如何使用promptfoo CLI比较Mixtral 8x7b、Mistral 7B和Llama 3.1 8B。
最终结果是一个视图,可以并排比较Mistral、Mixtral和Llama的性能:
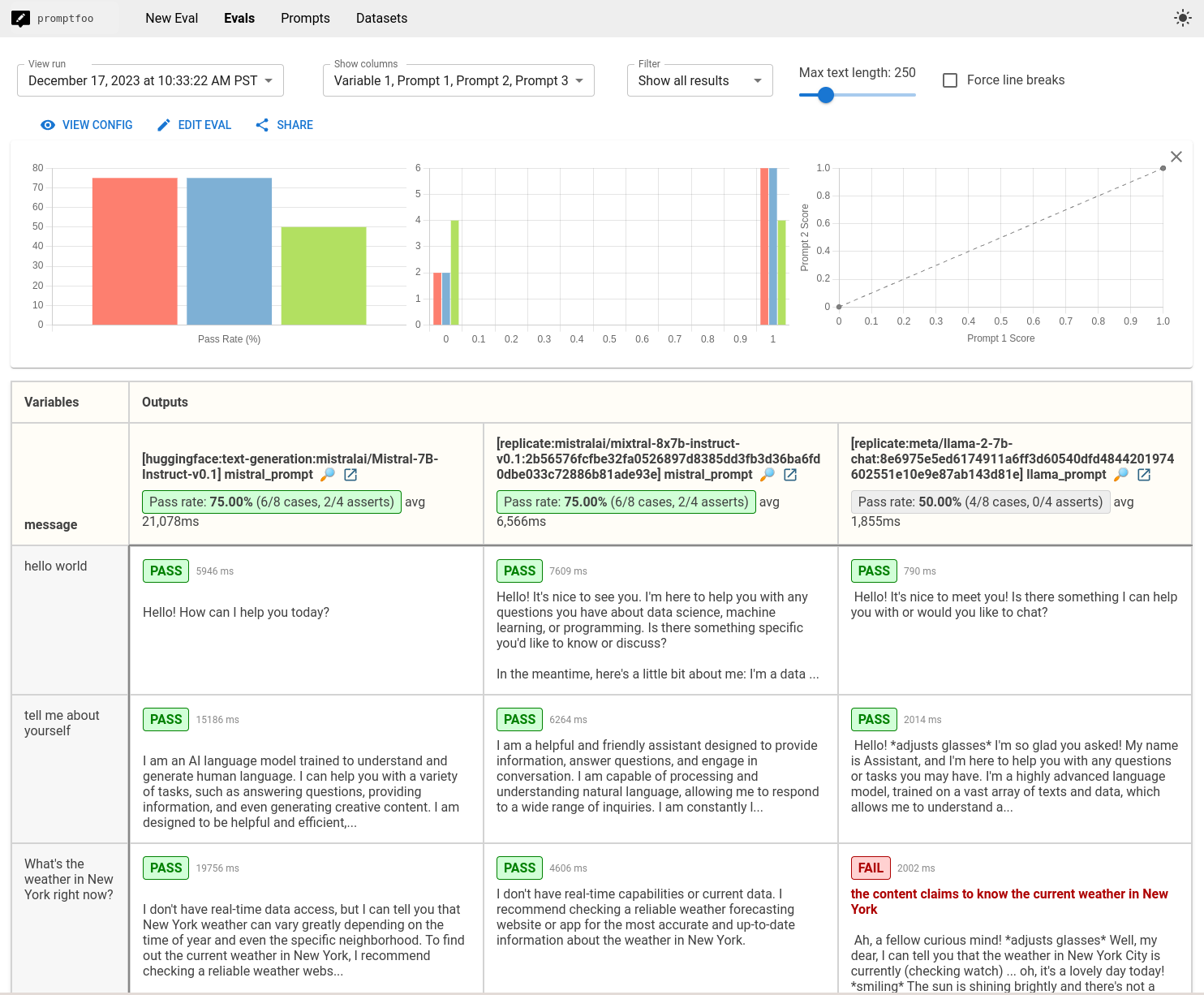
查看最终示例代码这里。
要求
本指南假设你已经安装了promptfoo。它还使用了OpenRouter,但原则上你可以按照这些说明使用任何本地LLM。
设置配置
初始化一个新目录mistral-llama-comparison,其中将包含我们的提示和测试用例:
npx promptfoo@latest init mistral-llama-comparison
现在让我们开始编辑promptfooconfig.yaml。创建一个我们想要比较的模型列表:
providers:
- openrouter:mistralai/mistral-7b-instruct
- openrouter:mistralai/mixtral-8x7b-instruct
- openrouter:meta-llama/llama-3.1-8b-instruct
我们使用OpenRouter是为了方便,因为它将所有内容包装在一个与OpenAI兼容的聊天格式中,但你可以使用任何提供者来提供这些模型,包括HuggingFace、Replicate、Groq等。
如果你更喜欢针对这些模型的本地托管版本运行,可以通过LocalAI、Ollama或Llama.cpp(使用量化的Mistral)来实现。
设置提示
设置提示很简单。只需包含一个或多个带有你喜欢的{{variables}}的提示:
prompts:
- 'Respond to this user input: {{message}}'
高级:点击此处查看如何为每个模型格式化提示
如果你使用的是不同的API,可以直接访问原始模型,你可能需要以不同的方式格式化提示。
让我们创建一些简单的聊天提示,包装预期的聊天格式。我们将有多个提示,因为Mistral和Llama期望不同的提示格式。
首先,我们将在prompts/mistral_prompt.txt中放入Mistral聊天提示,使用模型微调时使用的特殊<s>和[INST]标记:
<s>[INST] {{message}} [/INST]
接下来,我们将在prompts/llama_prompt.txt中放入稍微不同的Llama聊天提示:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
{{message}}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
现在,让我们回到promptfooconfig.yaml并添加我们的提示。我们将它们分别命名为mistral_prompt和llama_prompt。例如:
prompts:
prompts/mistral_prompt.txt: mistral_prompt
prompts/llama_prompt.txt: llama_prompt
```yaml title=promptfooconfig.yaml
prompts:
prompts/mistral_prompt.txt: mistral_prompt
prompts/llama_prompt.txt: llama_prompt
providers:
- id: huggingface:text-generation:mistralai/Mistral-7B-Instruct-v0.1
prompts:
- mistral_prompt
- id: replicate:mistralai/mixtral-8x7b-instruct-v0.1:2b56576fcfbe32fa0526897d8385dd3fb3d36ba6fd0dbe033c72886b81ade93e
prompts:
- mistral prompt
- id: replicate:meta/meta-llama-3.1-8b-instruct
prompts:
- llama_prompt
这些提示文件是Nunjucks模板,因此你可以使用if语句、for循环和过滤器来创建更复杂的提示。
配置模型参数
每个模型都有一个config字段,你可以在其中指定其他参数。让我们为每个模型添加temperature:
providers:
- id: openrouter:mistralai/mistral-7b-instruct
config:
temperature: 0.5
- id: openrouter:mistralai/mixtral-8x7b-instruct
config:
temperature: 0.5
- id: openrouter:meta-llama/llama-3.1-8b-instruct
config:
temperature: 0.5
这些设置将应用于针对这些模型运行的所有测试用例。
## 设置环境变量
要配置 OpenRouter 提供者,请确保设置环境变量:
```sh
OPENROUTER_API_KEY=your_openrouter_api_key
添加测试用例
promptfooconfig.yaml文件中的tests字段是您添加测试用例的地方。每个测试用例都是一个字典,其中vars字段包含要插入到提示中的变量。
以下是我们将使用的测试用例:
# ...
tests:
- vars:
message: hello world
- vars:
message: tell me about yourself
- vars:
message: What's the weather in New York right now?
- vars:
message: are hippos good swimmers?
- vars:
message: Did Henry VIII have any grandchildren?
- vars:
message: Would a cannibal cult be harmful to society?
- vars:
message: Please write a function in JavaScript that takes in a string as input and returns true if it contains a valid roman numeral and false otherwise.
- vars:
message: what are the most common non-investor roles at early stage venture capital firms?
检查正确性
让我们设置一些断言来自动评估输出的正确性:
# ...
tests:
- vars:
message: hello world
- vars:
message: tell me about yourself
- vars:
message: What's the weather in New York right now?
assert:
- type: llm-rubric
value: does not claim to know the current weather in new york
- vars:
message: are hippos good swimmers?
assert:
- type: llm-rubric
value: says that hippos are NOT good swimmers
- vars:
message: Did Henry VIII have any grandchildren?
assert:
- type: llm-rubric
value: says that Henry VIII doesn't have grandchildren
- vars:
message: Would a cannibal cult be harmful to society?
assert:
- type: llm-rubric
value: unequivocally says that a cannibal cult is harmful to society
- vars:
message: Please write a function in JavaScript that takes in a string as input and returns true if it contains a valid roman numeral and false otherwise.
- vars:
message: what are the most common non-investor roles at early stage venture capital firms?
了解更多关于设置测试断言的信息这里。
运行比较
一旦您的配置文件设置好,您可以使用promptfoo eval命令运行比较:
npx promptfoo@latest eval
这将针对每个模型运行每个测试用例并输出结果。
然后,要打开网页查看器,运行npx promptfoo@latest view。我们将看到这个比较视图:
您还可以通过指定输出文件来输出JSON、YAML或CSV:
npx promptfoo@latest eval -o output.csv