Mixtral vs GPT: 使用您自己的数据运行基准测试
在本指南中,我们将逐步介绍如何比较三个大型语言模型(LLM):Mixtral、GPT-4o-mini 和 GPT-4o。我们将使用 promptfoo,一个命令行界面(CLI)工具,来运行评估并根据一组提示和测试用例比较这些模型的性能。
要求
- 在您的系统上安装了
promptfooCLI。 - 访问 Replicate 以获取 Mixtral。
- 访问 OpenAI 以获取 GPT-4o-mini 和 GPT-4o。
- Replicate 的 API 密钥 (
REPLICATE_API_TOKEN) 和 OpenAI 的 API 密钥 (OPENAI_API_KEY)。
步骤 1:初始设置
为您的比较项目创建一个新目录,并使用 promptfoo init 进行初始化。
npx promptfoo@latest init mixtral-gpt-comparison
步骤 2:配置模型
编辑您的 promptfooconfig.yaml 以包含您要比较的模型。以下是一个包含 Mixtral、GPT-4o-mini 和 GPT-4o 的示例配置:
providers:
- replicate:mistralai/mixtral-8x7b-instruct-v0.1:2b56576fcfbe32fa0526897d8385dd3fb3d36ba6fd0dbe033c72886b81ade93e
- openai:gpt-4o-mini
- openai:gpt-4o
将您的 API 密钥设置为环境变量:
export REPLICATE_API_TOKEN=your_replicate_api_token
export OPENAI_API_KEY=your_openai_api_key
在此示例中,我们使用的是 Replicate,但您也可以使用 HuggingFace、TogetherAI 等提供商:
- huggingface:text-generation:mistralai/Mistral-7B-Instruct-v0.1
- id: openai:chat:mistralai/Mixtral-8x7B-Instruct-v0.1
config:
apiBaseUrl: https://api.together.xyz/v1
可选:配置模型参数
通过设置 temperature 和 max_tokens 或 max_length 等参数来自定义每个模型的行为:
providers:
- id: openai:gpt-4o-mini
config:
temperature: 0
max_tokens: 128
- id: openai:gpt-4o
config:
temperature: 0
max_tokens: 128
- id: replicate:mistralai/mixtral-8x7b-instruct-v0.1:2b56576fcfbe32fa0526897d8385dd3fb3d36ba6fd0dbe033c72886b81ade93e
config:
temperature: 0.01
max_new_tokens: 128
步骤 3:设置提示
设置您希望为每个模型运行的提示。在这种情况下,我们将只使用一个简单的提示,因为我们想要比较模型的性能。
prompts:
- '尽可能好地回答这个问题:{{query}}'
如果需要,您可以测试多个提示(只需在列表中添加更多提示),或为每个模型测试 不同的提示。
步骤 4:添加测试用例
定义您希望用于评估的测试用例。这包括设置将插入到提示中的变量:
tests:
- vars:
query: '法国的首都是什么?'
assert:
- type: contains
value: '巴黎'
- vars:
query: '解释相对论理论。'
assert:
- type: contains
value: '爱因斯坦'
- vars:
query: '写一首关于大海的诗。'
assert:
- type: llm-rubric
value: '这首诗应该唤起波浪或海洋等意象。'
- vars:
query: '吃苹果的健康益处是什么?'
assert:
- type: contains
value: '维生素'
- vars:
query: "将 'Hello, how are you?' 翻译成西班牙语。"
assert:
- type: similar
value: 'Hola, ¿cómo estás?'
- vars:
query: '输出一个颜色的 JSON 列表'
assert:
- type: is-json
- type: latency
threshold: 5000
可选地,您可以设置断言来自动评估输出的正确性。
步骤 5:运行比较
配置完成后,使用 promptfoo CLI 运行评估:
npx promptfoo@latest eval
此命令将对每个配置的模型执行每个测试用例并记录结果。
要可��视化结果,请使用 promptfoo 查看器:
npx promptfoo@latest view
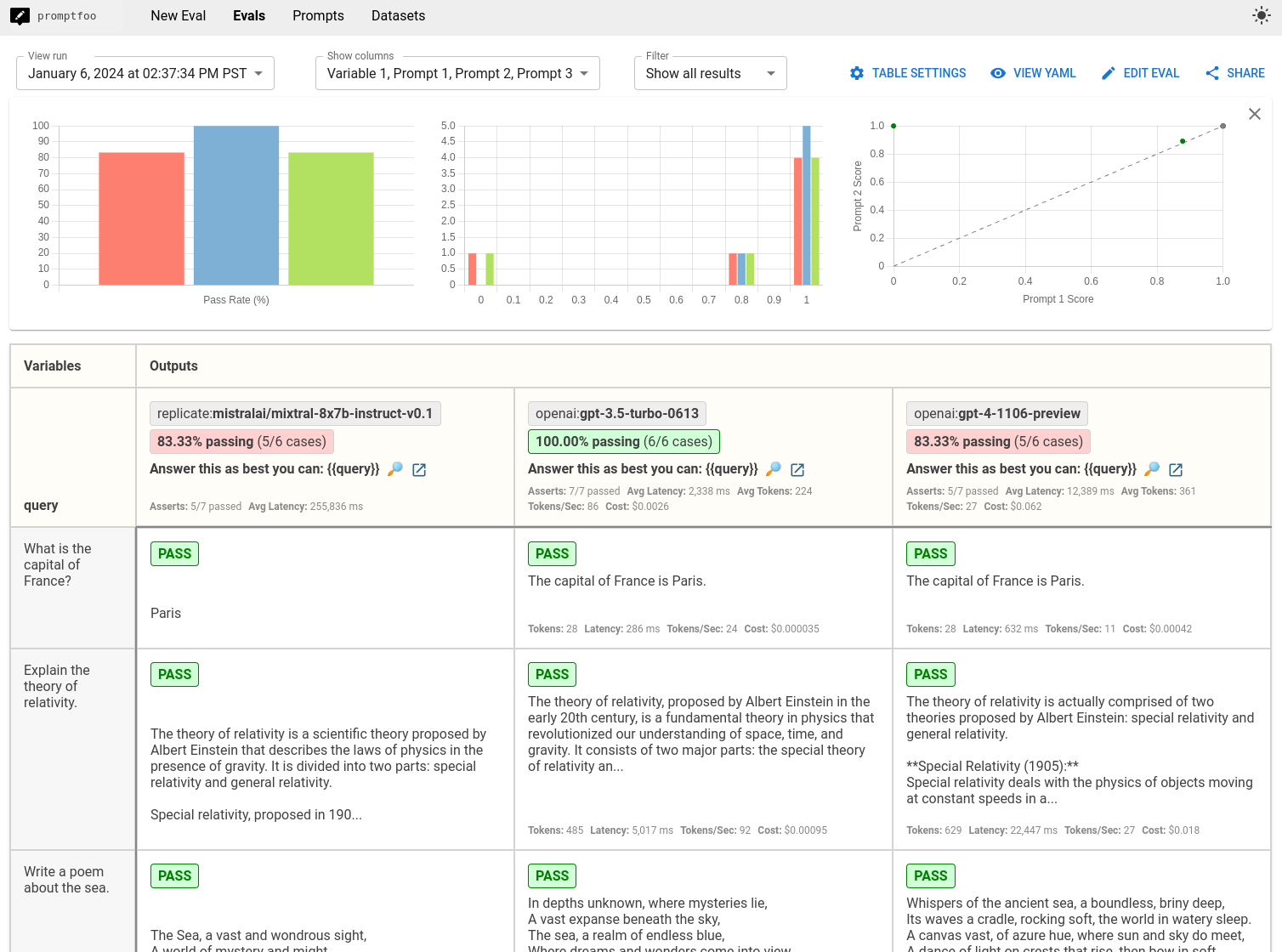
它将显示如下结果:
您还可以将结果输出到各种格式的文件中,如 JSON、YAML 或 CSV:
npx promptfoo@latest eval -o results.csv
结论
比较将为您提供基于您的测试用例的 Mixtral、GPT-4o-mini 和 GPT-4o 的并排性能视图。使用此数据来做出明智的决策,确定哪个 LLM 最适合您的应用程序。 与此相比,Chatbot Arena排行榜上的公开基准如下:
| 模型 | 竞技场评分 | MT-bench评分 |
|---|---|---|
| gpt-4o | 1243 | 9.32 |
| Mixtral-8x7b-Instruct-v0.1 | 1121 | 8.3 |
| gpt-4o-mini | 1074 | 8.32 |
虽然公开基准能告诉你这些模型在_通用_任务上的表现,但它们无法替代在你_自己_的数据和使用场景上进行的基准测试。
上述例子突显了GPT在某些情况下优于Mixtral的几个案例:特别是,GPT-4在遵循JSON输出指令方面表现更佳。但GPT 3.5由于我们在其中一个测试案例中加入了延迟要求,获得了最高的评估分数。总体而言,最佳选择将很大程度上取决于你构建的测试案例以及你自己的应用约束。