Phi vs Llama: 在自己的数据上进行基准测试
在选择像Phi 3和Llama 3.1这样的大型语言模型时,重要的是要在特定的使用场景上进行基准测试,而不是仅仅依赖公开的基准测试。当模型在同一水平线上时,具体的应用场景会产生很大的差异。
本指南将引导你使用promptfoo + Ollama设置Llama和Phi的综合基准测试。
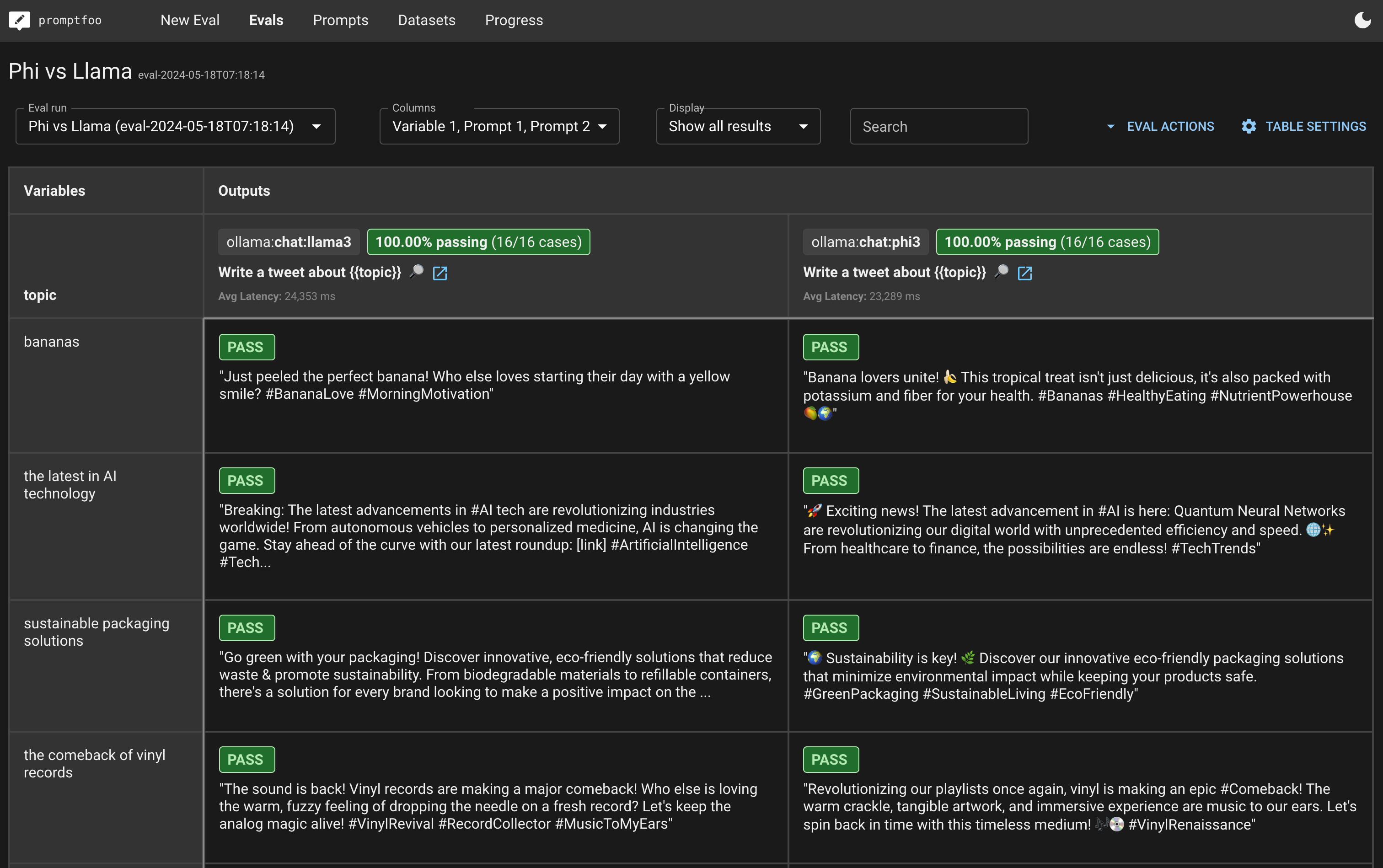
最终,你将能够创建一个并排的评估视图,看起来像这样:
要求
在开始之前,请确保你已经具备以下条件:
步骤1:初始化
首先,为你的基准测试创建一个新的目录:
npx promptfoo@latest init phi-vs-llama
cd phi-vs-llama
步骤2:配置
打开promptfooconfig.yaml并设置你想要比较的模型。我们将使用ollama:chat:phi3和ollama:chat:llama3端点。
定义提示
首先定义你将用于测试的提示。在这个例子中,我们只是传递一个单一的message变量:
prompts:
- '{{message}}'
配置提供者
接下来,指定模型及其配置:
prompts:
- '{{message}}'
providers:
- id: ollama:chat:phi3
config:
temperature: 0.01
num_predict: 128
- id: ollama:chat:llama3.1
config:
temperature: 0.01
num_predict: 128
步骤3:构建测试集
测试用例应代表你的应用程序的使用场景。以下是一些示例测试用例:
tests:
- vars:
message: 'Tell me a joke.'
- vars:
message: 'What is the capital of France?'
- vars:
message: 'Explain the theory of relativity in simple terms.'
- vars:
message: 'Translate "Good morning" to Spanish.'
- vars:
message: 'What are the benefits of a healthy diet?'
- vars:
message: 'Write a short story about a dragon and a knight.'
添加断言(可选)
你可以使用assert属性添加自动检查,以自动确保输出是正确的。
tests:
- vars:
message: 'Tell me a joke.'
assert:
- type: llm-rubric
value: Contains a setup and a punch line.
- vars:
message: 'What is the capital of France?'
assert:
- type: icontains
value: Paris
- vars:
message: 'Explain the theory of relativity in simple terms.'
assert:
- type: llm-rubric
value: Simplifies complex concepts
- vars:
message: 'Translate "Good morning" to Spanish.'
assert:
- type: icontains
value: Buenos días
- vars:
message: 'What are the benefits of a healthy diet?'
assert:
- type: llm-rubric
value: Lists health benefits
- vars:
message: 'Write a short story about a dragon and a knight.'
assert:
- type: llm-rubric
value: Creative storytelling
步骤4:运行基准测试
使用以下命令执行比较:
npx promptfoo@latest eval
然后,查看结果:
npx promptfoo@latest view
这将打开一个网页查看器,显示模型性能的并排比较。它看起来会像这样(具体外观会根据你的测试用例和评分机制而有所不同):
步骤5:分析结果
运行评估后,分析结果以确定哪个模型最适合你的特定使用场景。寻找输出中的模式,如准确性、创造性和对提示的遵循程度。