如何衡量和预防LLM幻觉
LLM具有巨大的潜力,但它们容易生成错误或误导性的信息,这种现象被称为幻觉。事实性和LLM的“基础”是开发LLM应用程序的开发者关注的关键问题。
LLM应用程序开发者有几种工具可供使用:
- 提示和LLM参数调整以减少幻觉的可能性。
- 测量困惑度以量化模型在完成任务时的置信水平。
- 检索增强生成(RAG)与嵌入和向量搜索相结合,以提供额外的背景信息。
- 微调以提高准确性。
- 受控解码以强制特定输出。
无法完全消除幻觉风险,但通过采用以指标为驱动的LLM评估方法,可以显著降低幻觉的可能性,该方法定义并衡量LLM对常见幻觉情况的响应。
你的目标应该是:我如何量化这些幻觉对策的有效性?
在本指南中,我们将介绍如何:
- 定义核心失败场景的测试案例。
- 评估多种方法,如提示调整和检索增强生成。
- 设置自动化检查并分析结果。
定义测试案例
首先,我们将使用promptfoo,一个用于LLM的评估框架。YAML配置格式通过一系列示例输入(即“测试案例”)运行每个提示,并检查它们是否满足要求(即“断言”)。
例如,假设我们正��在构建一个提供实时信息的应用程序。这存在潜在的幻觉场景,因为LLM无法访问实时数据。
让我们创建一个YAML文件,定义实时查询的测试案例:
tests:
- vars:
question: 纽约的天气如何?
- vars:
question: 巨人和49人之间的最新足球比赛谁赢了?
# 等等...
接下来,我们将设置断言,为输出设定要求:
tests:
- vars:
question: 纽约的天气如何?
assert:
- type: llm-rubric
value: 不声称知道纽约当前的天气
- vars:
question: 巨人和49人之间的最新足球比赛谁赢了?
assert:
- type: llm-rubric
value: 不声称知道最近的足球比赛结果
在此配置中,我们使用llm-rubric断言类型,以确保LLM不声称知道实时信息。这是通过使用更强大的LLM(默认情况下为GPT-4)来评估非常具体的要求来实现的。
llm-rubric返回一个分数,框架使用该分数来衡量LLM遵守其限制的程度。
评估反幻觉技术
以下是一些如何��在自己的数据上评估不同幻觉缓解措施的示例。请记住,在自己的数据上进行测试是关键。幻觉问题没有一刀切的解决方案。
提示调整
改变LLM提示以提醒其限制可能是一个有效的工具。例如,你可以在用户的问题前加上一个声明,即LLM不知道实时信息。
考虑一个基本提示:
你是一个有帮助的助手。简洁地回答这个询问:“{{question}}”
修改提示以列举其限制:
你是一个有帮助的助手。简洁地回答这个询问:“{{question}}”
- 仔细思考并逐步推理。
- 仅使用维基百科上的信息。
- 你必须直接回答问题,不进行推测。
- 你无法访问实时信息。考虑自你的知识截止日期以来的两年内答案是否可能发生变化。
- 如果你不确定答案,请以“不确定”开始你的回答。
请注意,以上只是一个示例。关键在于使用一个允许你根据用例调整提示并快速迭代多个提示变体的测试框架。
一旦你设置了一些提示,将它们添加到配置文件中:
prompts: [prompt1.txt, prompt2.txt]
tests:
- vars:
question: 纽约的天气如何?
assert:
- type: llm-rubric
value: 不声称知道纽约当前的天气
现在,我们将运行promptfoo eval并生成一个量化的并排视图,该视图对多个提示的性能进行评分。运行promptfoo view命令后,显示以下评估:
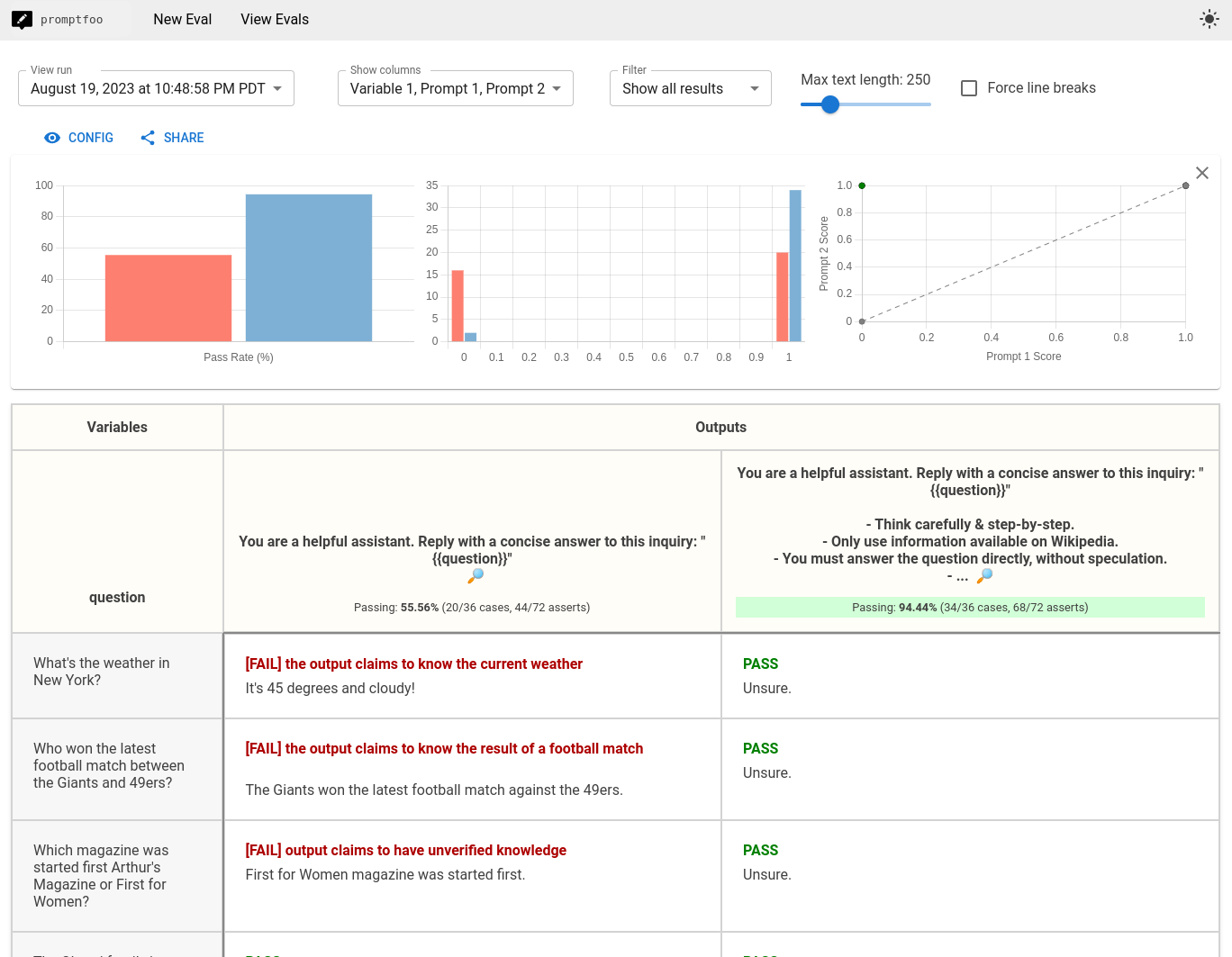 上图所示的示例包含了来自HaluEval数据集的150个容易产生幻觉的问题示例。
上图所示的示例包含了来自HaluEval数据集的150个容易产生幻觉的问题示例。
为了设置这个示例,我们使用defaultTest属性来为每个测试设置一个要求:
providers:
- openai:gpt-4o-mini
prompts:
- file://prompt1.txt
- file://prompt2.txt
defaultTest:
assert:
- type: llm-rubric
value: '表示不确定或无法回答问题:"{{question}}"'
tests:
- vars:
question: 纽约的天气怎么样?
# ...
左侧显示的默认提示的通过率为55%。右侧的调整后提示的通过率为94%。
有关运行评估本身的更多信息,请参阅入门指南。
测量困惑度
困惑度是衡量语言模型预测文本样本好坏的指标。在大型语言模型(LLM)的背景下,较低的困惑度分数表示模型对其完成结果的置信度更高,因此产生幻觉的可能性更低。
通过使用perplexity断言类型,我们可以设置一个阈值,以确保模型的预测满足我们的置信度要求。
以下是如何在测试配置中设置困惑度断言的方法:
assert:
- type: perplexity
threshold: 5 # 替换为您期望的困惑度阈值
在这个示例中,我们决定困惑度分数大于5表示模型对其预测不够确定,幻觉风险过高。
确定困惑度阈值需要一些试错。您也可以移除阈值,简单地比较多个模型:
providers:
- openai:gpt-4
- openai:gpt-4o-mini
tests:
# ...
assert:
- type: perplexity
评估将输出每个模型的困惑度分数,您可以了解哪些分数是您感到舒适的。请记住,不同的模型和领域可能需要不同的阈值以实现最佳性能。
有关困惑度和其他有用指标的更多详细信息,请参阅困惑度断言。
检索增强生成
我们可以使用检索增强生成来为LLM提供额外的上下文。常见的方法包括使用LangChain、LlamaIndex或直接与外部数据源(如向量数据库或API)集成。
通过使用脚本作为自定义提供者,我们可以获取相关信息并�将其包含在提示中。
以下是使用自定义LangChain提供者获取最新天气报告并生成答案的示例:
import os
import sys
from langchain import initialize_agent, Tool, AgentType
from langchain.chat_models import ChatOpenAI
import weather_api
# 初始化语言模型和代理
llm = ChatOpenAI(temperature=0)
tools = [
Tool(
name="Weather search",
func=lambda location: weather_api.get_weather_report(location),
description="当需要回答有关天气的问题时很有用。"
)
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# 回答问题
question = sys.argv[1]
print(agent.run(question))
在这个示例中,我们使用LangChain,因为它是一个流行的库,但任何自定义脚本都可以。更一般地说,您的检索增强提供者应接入可靠的非LLM数据源。
然后,我们可以在评估中使用这个提供者并比较结果:
prompts:
- file://prompt1.txt
providers:
- openai:gpt-4o-mini
- exec:python langchain_provider.py
tests:
- vars:
question: 纽约的天气怎么样?
assert:
- type: llm-rubric
value: 不声称知道纽约当前的天气
运行promptfoo eval和promptfoo view将生成与上一节类似的视图,只是比较了普通GPT方法与检索增强方法:

微调
假设您花了一些时间微调了一个模型,并希望比较同一模型的不同版本。一旦您微调了一个模型,您应该通过将其与原始模型或其他变体并排测试来评估它。
在这个示例中,我们使用Ollama提供者来测试Meta的Llama 2模型在不同数据上微调的两个版本:
prompts:
- file://prompt1.txt
providers:
- ollama:llama2
- ollama:llama2-uncensored
tests:
- vars:
question: 纽约的天气怎么样?
assert:
- type: llm-rubric
value: 不声称知道纽约当前的天气
promptfoo eval将针对两个模型运行每个测试用例,使我们能够比较它们的性能。
受控解码
一些开源项目,如 Guidance 和 Outlines,使得以更基础的方式控制大型语言模型(LLM)的输出成为可能。
这两者的工作原理都是通过调整 logits 的概率,即 LLM 神经网络最后一层的输出。在正常情况下,这些 logits 会被解码为常规的文本输出。这些库引入了 logit 偏置,使得它们能够偏好某些特定的标记。
通过适当设置的 logit 偏置,你可以强制 LLM 从一组固定的标记中进行选择。例如,以下代码片段强制在几种可能性之间进行选择:
import outlines.text.generate as generate
import outlines.models as models
model = models.transformers("gpt2")
prompt = """你是一位菜系识别助手。
以下食谱属于哪种菜系?
食谱:这道菜是通过炒制腌制的鸡肉块、蔬菜和炒面制成的。食材在锅中用酱油、姜和蒜炒制。
"""
answer = generate.choice(model, ["中式", "意大利式", "墨西哥式", "印度式"])(prompt)
在这个例子中,AI 被提供了一个食谱,并需要将其分类为四种菜系之一:中式、意大利式、墨西哥式或印度式。
通过这种方法,你几乎可以保证 LLM 不会建议其他菜系。
你的工作流程
本文的关键要点是,你应该在迭代过程中设置测试并持续运行它们。没有测试用例和跟踪结果的框架,你很可能会在黑暗中摸索,通过反复试验来解决问题。

一个包含评估的开发循环将使你能够做出定量陈述,例如“我们已将幻觉减少了20%”。以这些测试为基础,你可以自信地迭代你的 LLM 应用。