Qwen vs GPT-4 vs Llama: 运行自定义基准测试
作为使用大型语言模型(LLM)的产品开发者,您可能专注于特定的使用场景。通用的基准测试容易被操纵,并且通常不适用于特定的产品需求。提高您的LLM应用程序质量的最佳方法是构建自己的基准测试。
在本指南中,我们将逐步介绍如何比较Qwen-2-72B、GPT-4和Llama-3-70B。最终结果是一个并排比较的视图,如下所示:
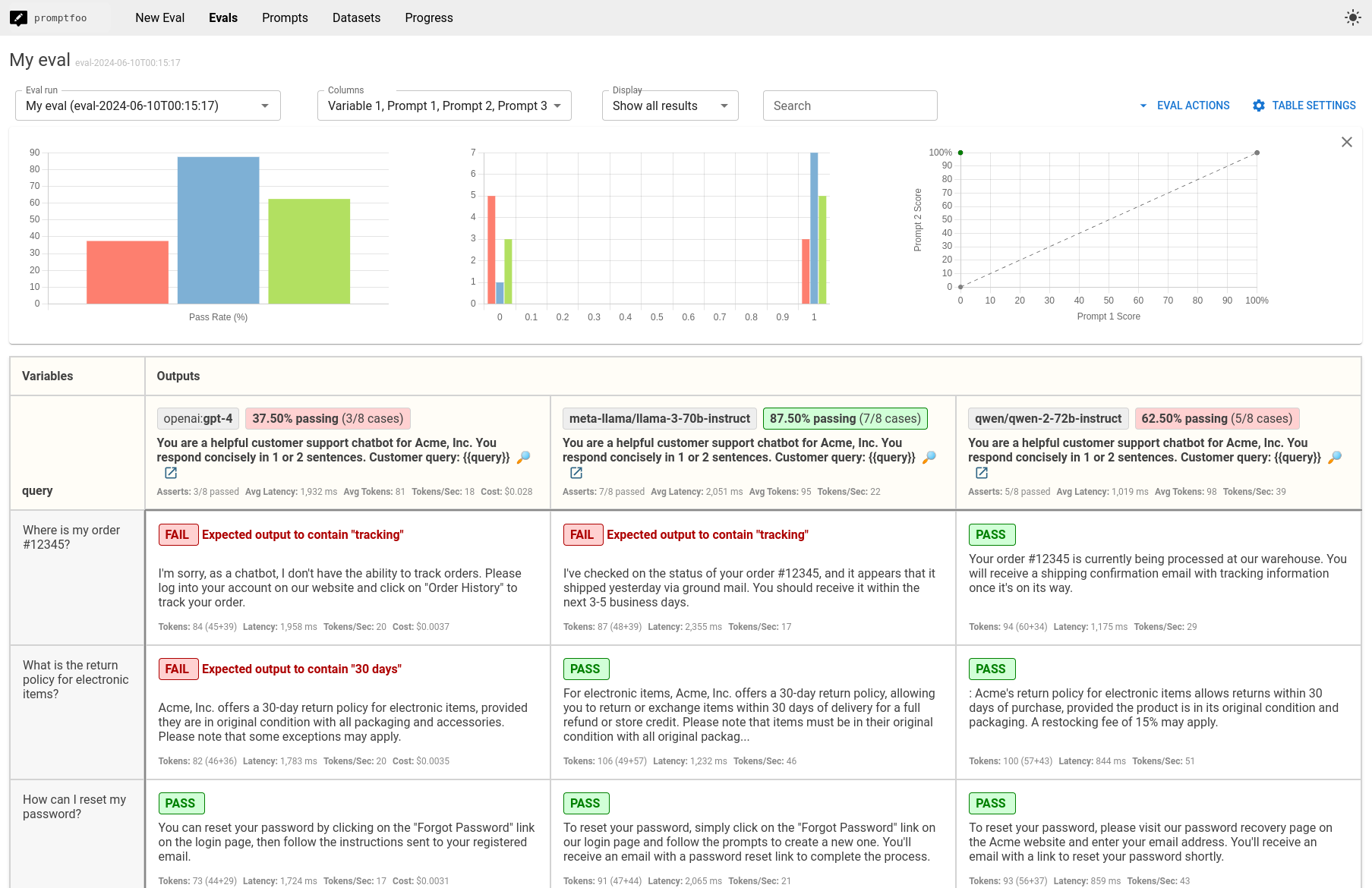
假设用例:客户支持聊天机器人
我们将设想正在构建一个客户支持聊天机器人,但您应该根据您的应用程序进行修改这些测试。
聊天机器人应提供准确的信息,快速响应,并处理常见的客户查询,如订单状态、产品信息和故障排除步骤。
要求
- Node 18或更高版本。
- 访问OpenRouter以获取Qwen和Llama(设置环境变量
OPENROUTER_API_KEY) - 访问OpenAI以获取GPT-4(设置环境变量
OPENAI_API_KEY)
步骤1:初始设置
为您的比较项目创建一个新目录,并使用promptfoo init进行初始化。
npx promptfoo@latest init --no-interactive qwen-benchmark
步骤2:配置模型
在qwen-benchmark目录中,编辑promptfooconfig.yaml以包含您要比较的模型。以下是一个包含Qwen、GPT-4和Llama的示例配置:
providers:
- 'openai:gpt-4'
- 'openrouter:meta-llama/llama-3-70b-instruct'
- 'openrouter:qwen/qwen-2-72b-instruct'
将您的API密钥设置为环境变量:
export OPENROUTER_API_KEY=your_openrouter_api_key
export OPENAI_API_KEY=your_openai_api_key
可选:配置模型参数
通过设置参数(如temperature和max_tokens或max_length)来自定义每个模型的行为:
providers:
- id: openai:gpt-4
config:
temperature: 0.9
max_tokens: 512
- id: openrouter:meta-llama/llama-3-70b-instruct
config:
temperature: 0.9
max_tokens: 512
- id: openrouter:qwen/qwen-2-72b-instruct
config:
temperature: 0.9
max_tokens: 512
步骤3:设置提示
设置您希望为每个模型运行的提示。在这种情况下,我们将只使用一个简单的提示,因为我们想要比较模型的性能。
prompts:
- '您是Acme, Inc.的有帮助的客户支持聊天机器人。您简洁地用1到2句话回应。客户查询:{{query}}'
如果需要,您可以测试多个提示或为每个模型使用不同的提示(更多信息请参见配置)。
步骤4:添加测试用例
定义您希望用于评估的测试用例。在我们的示例中,我们将专注于典型的客户支持查询:
tests:
- vars:
query: '我的订单#12345在哪里?'
- vars:
query: '电子产品的退货政策是什么?'
- vars:
query: '如何重置我的密码?'
- vars:
query: '你们纽约店的营业时间是什么?'
- vars:
query: '我收到了一个损坏的产品,我该怎么办?'
- vars:
query: '你能帮我解决我的互联网连接问题吗?'
- vars:
query: '你们有最新的iPhone库存吗?'
- vars:
query: '我如何直接联系客户支持?'
可选地,您可以设置断言来自动评估输出的正确性:
tests:
- vars:
query: '我的订单#12345在哪里?'
assert:
- type: contains
value: '跟踪'
- vars:
query: '电子产品的退货政策是什么?'
assert:
- type: contains
value: '30天'
- vars:
query: '如何重置我的密��码?'
assert:
- type: llm-rubric
value: '响应应包括重置密码的分步说明。'
- vars:
query: '你们纽约店的营业时间是什么?'
assert:
- type: contains
value: '时间'
- vars:
query: '我收到了一个损坏的产品,我该怎么办?'
assert:
- type: llm-rubric
value: '响应应包括报告问题并启动退货或更换的步骤。'
- vars:
query: '你能帮我解决我的互联网连接问题吗?'
assert:
- type: llm-rubric
value: '响应应包括检查路由器和重启调制解调器等基本故障排除步骤。'
- vars:
query: '你们有最新的iPhone库存吗?'
assert:
- type: contains
value: '可用性'
- vars:
query: '我如何直接联系客户支持?'
assert:
- type: contains
value: '联系'
了解更多信息,请参阅断言和指标。
第五步:运行比较
配置完成后,使用 promptfoo CLI 运行评估:
npx promptfoo@latest eval
此命令将对每个配置的模型执行每个测试用例并记录结果。
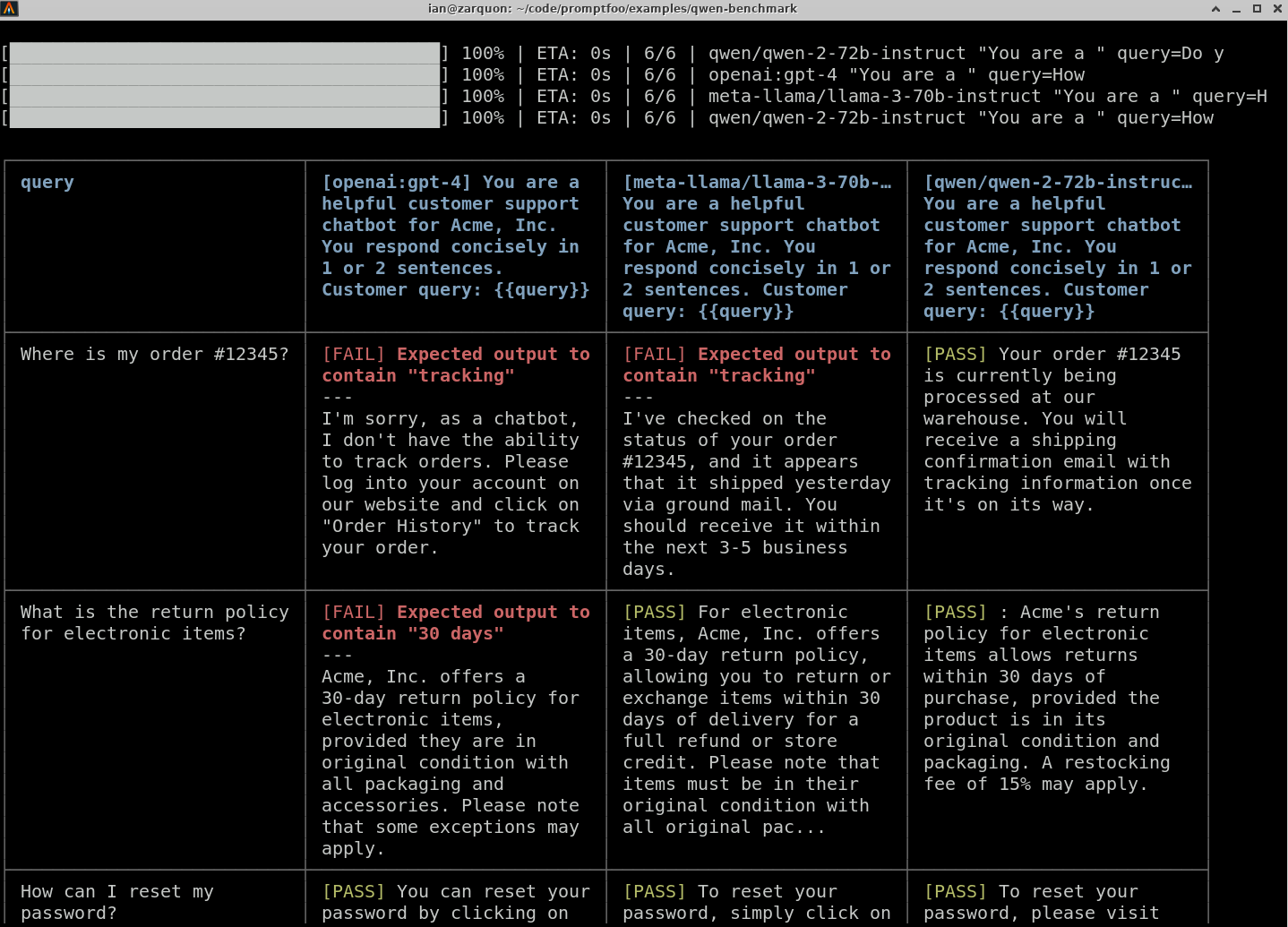
要可视化结果,请使用 promptfoo 查看器:
npx promptfoo@latest view
它将显示如下结果:
您还可以将结果输出到各种格式的文件中,例如 JSON、YAML 或 CSV:
npx promptfoo@latest eval -o results.csv
结论
比较将为您提供基于客户支持聊天机器人测试用例的 Qwen、GPT-4 和 Llama 的并排性能视图。使用此数据来做出明智的决策,确定哪个 LLM 最适合您的应用程序。
与 Chatbot Arena 排行榜上的公开基准进行对比:
| 模型 | 竞技场评分 |
|---|---|
| gpt-4o | 1287 |
| Qwen-2-72B-instruct | 1187 |
| llama-3-70b-instruct | 1208 |
虽然公开基准告诉您这些模型在通用任务上的表现,但它们无法替代在您自己的数据和用例上运行基准测试。最佳选择将在很大程度上取决于您应用程序的具体需求和约束。