LLM生成代码的沙盒评估
你正在使用LLM生成代码片段、函数,甚至是整个程序。盲目信任并在我们的生产环境——甚至开发环境中——执行这些生成的代码,可能会带来严重的安全风险。
这就是沙盒评估的用武之地。通过在受控的隔离环境中运行LLM生成的代码,我们可以:
- 安全地评估代码的正确性。
- 基准测试不同的LLM或提示,找出哪个生成最可靠的代码。
- 在代码影响主机系统之前捕获潜在的错误、无限循环或资源密集型操作。
在本教程中,我们将使用promptfoo设置一个自动化管道,通过LLM生成Python代码,使用epicbox在安全沙盒中执行代码,并评估结果。
前提条件
确保你已安装以下内容:
- Node.js 和 npm
- Python 3.9+
- Docker
- promptfoo (
npm install -g promptfoo) - epicbox (
pip install epicbox) - urllib3 < 2 (
pip install 'urllib3<2')
拉取你想要使用的Docker镜像,使其在本地可用。在本教程中,我们将使用一个通用的Python镜像,但如果你愿意,可以使用自定义镜像:
docker pull python:3.9-alpine
配置
创建promptfoo配置文件
创建一个名为promptfooconfig.yaml的文件:
prompts: code_generation_prompt.txt
providers:
- ollama:chat:llama3:70b
- openai:gpt-4o
tests:
- vars:
problem: 'Write a Python function to calculate the factorial of a number'
function_name: 'factorial'
test_input: '5'
expected_output: '120'
- vars:
problem: 'Write a Python function to check if a string is a palindrome'
function_name: 'is_palindrome'
test_input: "'racecar'"
expected_output: 'True'
- vars:
problem: 'Write a Python function to find the largest element in a list'
function_name: 'find_largest'
test_input: '[1, 5, 3, 9, 2]'
expected_output: '9'
defaultTest:
assert:
- type: python
value: file://validate_and_run_code.py
此配置做了几件重要的事情:
- 它告诉promptfoo使用我们的提示模板。
- 我们正在测试GPT-4o和Llama 3(你可以用你选择的提供者替换它。Promptfoo支持本地和商业提供者)。
- 它定义了编码问题。对于每个问题,它指定了函数名称、测试输入和预期输出。
- 它设置了一个基于Python的断言,该断言将针对每个测试用例运行,验证生成的代码。
创建提示模板
创建一个名为code_generation_prompt.txt的文件,内容如下:
你是一个Python代码生成器。编写一个Python函数来解决以下问题:
{{problem}}
使用以下函数名称:{{function_name}}
只提供函数代码,不要提供任何解释或额外文本。将你的代码用三重反引号包裹。
此提示将发送给LLM,{{variables}}将相应地替换(此提示是一个jinja兼容的模板)。
设置Python断言脚本
创建一个名为validate_and_run_code.py的文件。这将是一个Python断言,通过使用epicbox在Docker容器中运行代码,动态评分每个编码问题。
import epicbox
import re
# 替换为你偏好的 Docker 镜像
DOCKER_IMAGE = 'python:3.9-alpine'
def get_assert(output, context):
# 从 LLM 输出中提取 Python 函数
function_match = re.search(r'```python\s*\n(def\s+.*?)\n```', output, re.DOTALL)
if not function_match:
return {'pass': False, 'score': 0, 'reason': '未找到函数定义'}
function_code = function_match.group(1)
epicbox.configure(
profiles=[
epicbox.Profile('python', DOCKER_IMAGE)
]
)
function_name = context['vars']['function_name']
test_input = context['vars']['test_input']
expected_output = context['vars']['expected_output']
# 创建一个 Python 脚本来调用 LLM 编写的函数
test_code = f"""
{function_code}
# 测试函数
result = {function_name}({test_input})
print(result)
"""
files = [{'name': 'main.py', 'content': test_code.encode('utf-8')}]
limits = {'cputime': 1, 'memory': 64}
# 运行它
result = epicbox.run('python', 'python main.py', files=files, limits=limits)
# 检查结果
if result['exit_code'] != 0:
return {'pass': False, 'score': 0, 'reason': f"执行错误: {result['stderr'].decode('utf-8')}"}
actual_output = result['stdout'].decode('utf-8').strip()
if actual_output == str(expected_output):
return {'pass': True, 'score': 1, 'reason': f'正确输出: 得到 {expected_output}'}
else:
return {'pass': False, 'score': 0, 'reason': f"输出不正确。预期: {expected_output}, 实际: {actual_output}"}
运行评估
在终端中执行以下命令:
promptfoo eval
该命令将:
- 使用LLM为每个问题生成Python代码
- 提取生成的代码
- 在Docker沙盒环境中运行代码
- 判断输出是否正确
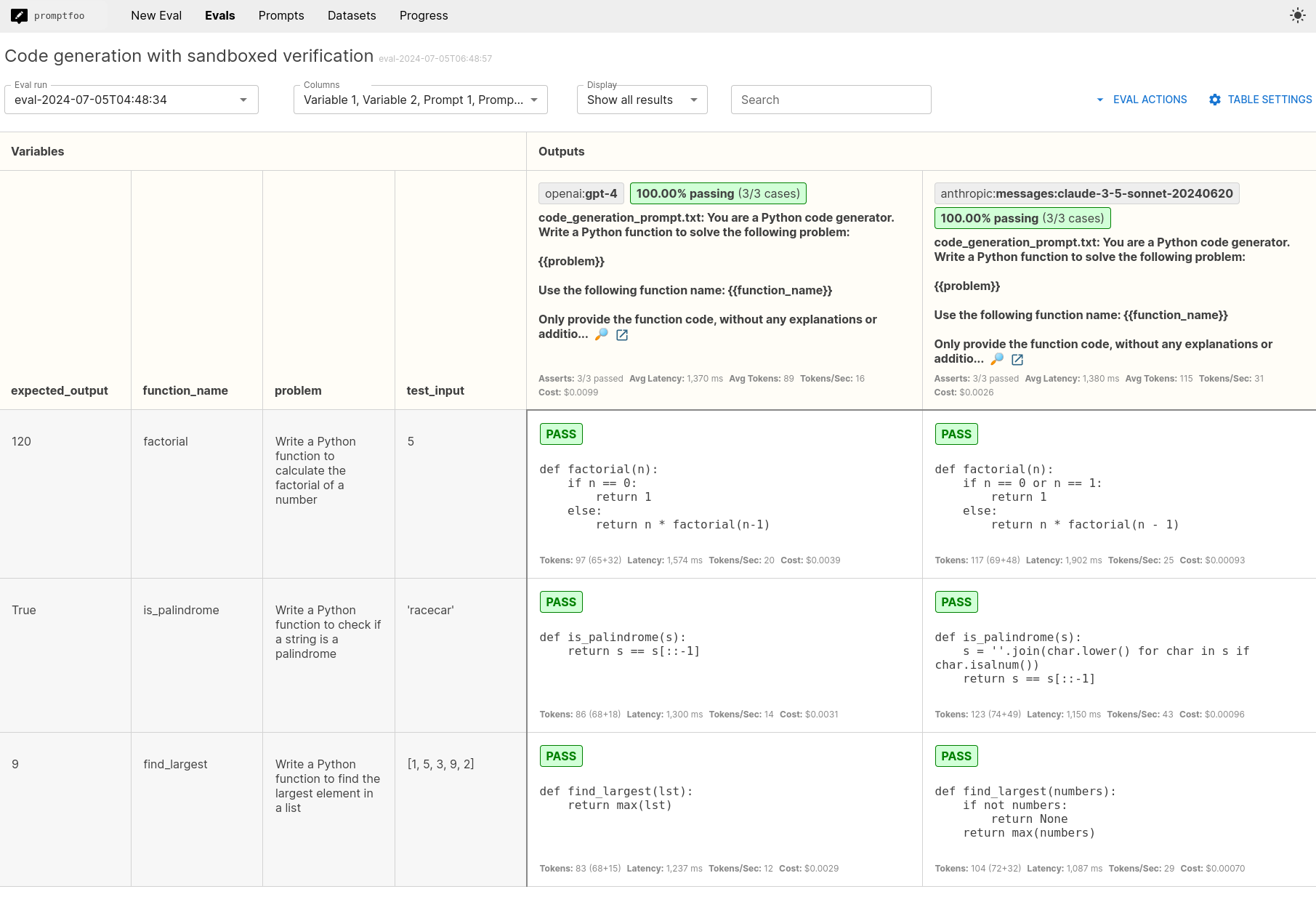
分析结果
运行评估后,打开Web查看器:
promptfoo view
这将显示结果的摘要。您可以分析:
- 生成代码的整体通过率
- LLM成功或失败的特定测试用例
- 失败测试的错误消息或错误输出
下一步
要进一步探索promptfoo的功能,请考虑:
- 测试不同的LLM 提供者
- 修改您的提示
- 扩展编码问题和测试用例的范围