from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
import random
import numpy as np
import pandas as pd
from pathlib import Path
from pytorch_tabular.utils import print_metrics, load_covertype_dataset
np.random.seed(42)
random.seed(42)
%load_ext autoreload
%autoreload 2
加载覆盖类型数据集¶
仅根据制图变量预测森林覆盖类型(不使用遥感数据)。给定观察(30 x 30 米单元格)的实际森林覆盖类型是根据美国森林局(USFS)第二区域资源信息系统(RIS)数据确定的。独立变量是从最初获得的美国地质调查局(USGS)和USFS数据中导出的。数据为原始形式(未缩放),并包含用于定性独立变量(荒野地区和土壤类型)的二进制(0 或 1)数据列。
该研究区域包括位于科罗拉多州北部罗斯福国家森林的四个荒野地区。这些区域代表了人类造成的干扰最小的森林,因此现有的森林覆盖类型更多地是生态过程的结果,而不是森林管理实践的结果。
该数据集来自 UCI ML Repository
# 将数据分割为用于自监督学习的数据和用于微调的数据
ssl, finetune = train_test_split(data, random_state=42, test_size=0.001)
# 训练和验证数据集划分
ssl_train, ssl_val = train_test_split(ssl, random_state=42)
finetune_train, finetune_test = train_test_split(finetune, random_state=42)
finetune_train, finetune_val = train_test_split(finetune_train, random_state=42)
print(f"Unlabelled Data: {ssl.shape[0]} rows | Labelled Data: {finetune.shape[0]}")
导入库¶
from pytorch_tabular import TabularModel
from pytorch_tabular.models import CategoryEmbeddingModelConfig
from pytorch_tabular.config import DataConfig, OptimizerConfig, TrainerConfig, ExperimentConfig
from pytorch_tabular.models.common.heads import LinearHeadConfig
from pytorch_tabular.ssl_models.dae import DenoisingAutoEncoderConfig
自监督学习¶
Yann LeCun 和 Ishan Mishra 的文章摘录将作为这里一个不错的引入: > 监督学习是构建更智能的通用模型的瓶颈,这些模型能够执行多项任务并在没有大量标记数据的情况下获取新技能。实际上,标记世界上的所有事物是不可能的。某些任务的标记数据也非常不足,例如为低资源语言训练翻译系统。
> 作为婴儿,我们主要通过观察来学习世界是如何运作的。我们通过学习物体永久性和重力等概念来形成关于世界中物体的概括性预测模型。随着生活的深入,我们观察世界,采取行动,再次观察,并通过试错建立假设,以解释我们的行动如何改变环境。
> 常识帮助人们学习新技能,而不需要对每一项任务进行大量的教学。例如,如果我们向小孩展示几幅牛的图画,他们最终能够识别他们看到的任何牛。相反,使用监督学习训练的人工智能系统需要许多牛的图像示例,仍可能在不寻常的情况下(例如躺在海滩上)无法识别牛。人类如何在大约 20 小时的实践中以极少的监督学会驾驶汽车,而完全自动驾驶仍然难倒我们最好的人工智能系统,尽管它们已基于数千小时的人类驾驶数据进行训练?简而言之,人类依赖于他们已经获得的关于世界运作的背景知识。
> 我们如何让机器做到这一点?
> 我们相信自监督学习 (SSL) 是建立这种背景知识并在人工智能系统中近似某种常识的最有前途的方法之一。
完整文章 是一次非常有趣的阅读。
SSL 在自然语言处理 (NLP) 中被成功使用(所有创建魔法的大型语言模型都是通过 SSL 学习的),并在计算机视觉中也取得了一些成功。但我们能否在表格数据中做到这一点?答案是肯定的。
有许多研究论文讨论了此类模型:
- TabNet 讲述了它如何用于 SSL
- VIME: 将自我及半监督学习的成功扩展到表格领域 也提出了另一种用于表格的 SSL 模型
- SubTab: 表格数据的特征子集以进行自监督表示学习 也是如此
在这些之前,还有 去噪自编码器,它在许多表格竞技竞赛中用作获胜解决方案。
PyTorch Tabular 提供了受 https://github.com/ryancheunggit/tabular_dae 启发的去噪自编码器实现。让我们看看我们如何使用它。
去噪自编码器具有以下架构 (来源):
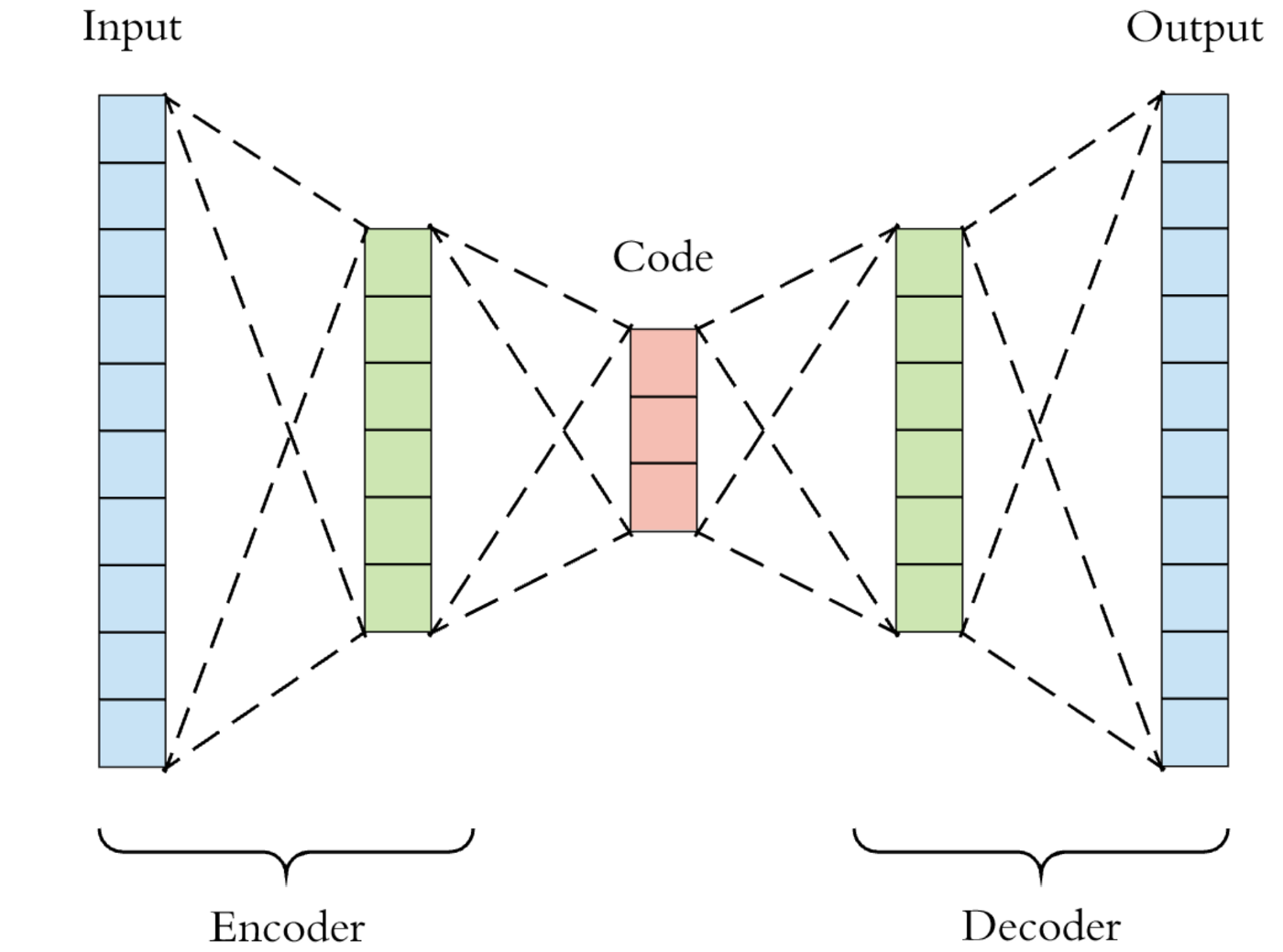
我们对左侧的输入进行干扰,并要求模型学习预测原始的去噪输入。通过这个过程,网络被迫学习一个压缩瓶颈(标记为 code),该瓶颈捕捉了输入数据的大部分特征,即输入数据的健壮表示。
在 PyTorchTabular 中的 DenoisingAutoencoder 实现中,噪声有两种引入方式:
1. swap - 在这种策略中,通过用从其余行随机抽样的相同特征的其他值替换特征中的值来引入噪声。
zero- 在这里,噪声通过将值替换为零来引入。
此外,我们还可以设置 noise_probabilities,以定义将噪声引入特征的概率。我们可以将此参数设置为形如 {featurename: noise_probability} 的字典。或者,我们还可以通过使用 default_noise_probability 为所有特征轻松设置一个单一概率。
一旦我们有了这种健壮的表示,我们可以在其他下游任务中使用这种表示,如回归或分类。
一个典型的 SSL 工作流程将拥有一个没有标签的大型数据集,以及一个较小的带标签的数据集用于微调。
- 我们首先使用未标记数据进行预训练
- 然后我们使用预训练模型(图中的
code)进行诸如回归或分类的下游任务
i. 我们创建一个以预训练模型为基础的新模型,并为预测创建一个头部
ii. 我们在少量带标签的数据上训练新模型(微调)
这种方法通常比仅使用少量带标签数据的纯监督模型效果更佳。
完全监督模型¶
首先,让我们使用大约5000行标记数据训练一个完全监督的模型。这可以作为一个基准。
data_config = DataConfig(
target=[target_name],
continuous_cols=num_col_names,
categorical_cols=cat_col_names,
normalize_continuous_features=True,
)
trainer_config = TrainerConfig(
batch_size=2048,
max_epochs=1000,
early_stopping="valid_loss", # 关闭提前停止
checkpoints="valid_loss", # 保存最佳检查点以监控验证损失
load_best=True, # 训练完成后,加载最佳检查点
)
optimizer_config = OptimizerConfig()
model_config = CategoryEmbeddingModelConfig(
task="classification",
layers="2000-1000",
activation="ReLU",
dropout=0.1,
initialization="kaiming",
head="LinearHead",
head_config={
"layers": "",
"activation": "ReLU",
},
learning_rate = 1e-3
)
tabular_model = TabularModel(
data_config=data_config,
model_config=model_config,
optimizer_config=optimizer_config,
trainer_config=trainer_config,
verbose=False
)
去噪自编码器¶
预训练¶
现在,我们使用约575k的未标记数据进行自监督学习。
ssl_data_config = DataConfig(
target=None, #Setting target as None because we don't need the target for SSL
continuous_cols=num_col_names,
categorical_cols=cat_col_names,
normalize_continuous_features=True,
handle_missing_values=False, # For SSL tasks, missing values and unknwon categories will not be handled automatically
handle_unknown_categories=False, # Not Setting these configs to False will throw and error when initializing TabularModel
)
ssl_trainer_config = TrainerConfig(
batch_size=batch_size,
max_epochs=epochs,
early_stopping="valid_loss", # Turning off Early Stopping
checkpoints="valid_loss", # Save best checkpoint monitoring val_loss
load_best=True, # After training, load the best checkpoint
)
# Setting OneCycleLR schedule
ssl_optimizer_config = OptimizerConfig(
lr_scheduler="OneCycleLR",
lr_scheduler_params={
"max_lr":1e-2,
"epochs": epochs,
"steps_per_epoch":steps_per_epoch
}
)
# Setting the encoder config
encoder_config = CategoryEmbeddingModelConfig(
task="backbone",
layers="4000-2000-1000-512", # Number of nodes in each layer
activation="ReLU", # Activation between each layers
head=None, # If not set to None, it will throw a warning
)
# Setting the decoder config.
# NOTE: the last dimension in encoder layers should be first dimension in decoder layers
# i.e. last encoder layer dim = 512, first decoder layer dim = 512
decoder_config = CategoryEmbeddingModelConfig(
task="backbone",
layers="512-2048-4096", # Number of nodes in each layer
activation="ReLU", # Activation between each layers
head=None, # If not set to None, it will throw a warning
)
# DAE Config. No need to set task because it is hardcoded to SSL
# Can't set any loss or metrics as well because for the SSL task
# (特别是对于DAE),损失和指标是固定的。
ssl_model_config = DenoisingAutoEncoderConfig(
noise_strategy="swap", # Can be 'zero' as well. Defines if noise is swapping features or making features zero
default_noise_probability = 0.7, # 噪声引起腐败的概率
include_input_features_inference=True, # 将其设置为 True 将会在解码器中的连接层中包含输入特征
encoder_config=encoder_config,
decoder_config=decoder_config,
learning_rate=1e-3)
ssl_tabular_model = TabularModel(
data_config=ssl_data_config,
model_config=ssl_model_config,
optimizer_config=ssl_optimizer_config,
trainer_config=ssl_trainer_config,
verbose=False
)
微调¶
现在我们使用预训练的权重创建一个微调模型,并使用大约5000个标记数据对模型进行分类任务的微调。
ft_optimizer_config = OptimizerConfig(
lr_scheduler="OneCycleLR",
lr_scheduler_params={
"max_lr":1e-3,
"epochs": epochs,
"steps_per_epoch":steps_per_epoch
}
)
finetune_model = ssl_tabular_model.create_finetune_model(
task="classification",
train=finetune_train,
validation=finetune_val,
target=[target_name], #提供目标列名称作为列表
head="LinearHead",
head_config={
"layers": "256-64",
"activation": "ReLU",
},
trainer_config=ft_trainer_config,# Overriding previous trainer config
optimizer_config=ft_optimizer_config,
optimizer=QHAdam, # 使用自定义优化器
optimizer_params={"nus": (0.7, 1.0), "betas": (0.95, 0.998)}
)
我们可以看到,自监督方法具有更低的损失。这不是一个确定的现象,它取决于我们在预训练期间能多好地学习到表示。