指标概览
指标是一种用于评估AI应用性能的量化标准。通过指标可以评估应用程序及其组成模块在给定测试数据下的表现情况。它们为整个应用开发和部署过程中的比较、优化和决策提供了数值依据。指标对于以下方面至关重要:
- 组件选择: 指标可用于比较AI应用的不同组件,如LLM、检索器、智能体配置等,并根据您自己的数据从不同选项中选择最佳方案。
- 错误诊断与调试: 指标能帮助识别应用程序中导致错误或性能不佳的部分,使调试和优化更加容易。
- 持续监控与维护: 指标能够追踪AI应用程序随时间变化的性能表现,帮助检测并应对数据漂移、模型退化或用户需求变化等问题。
不同类型的评估指标
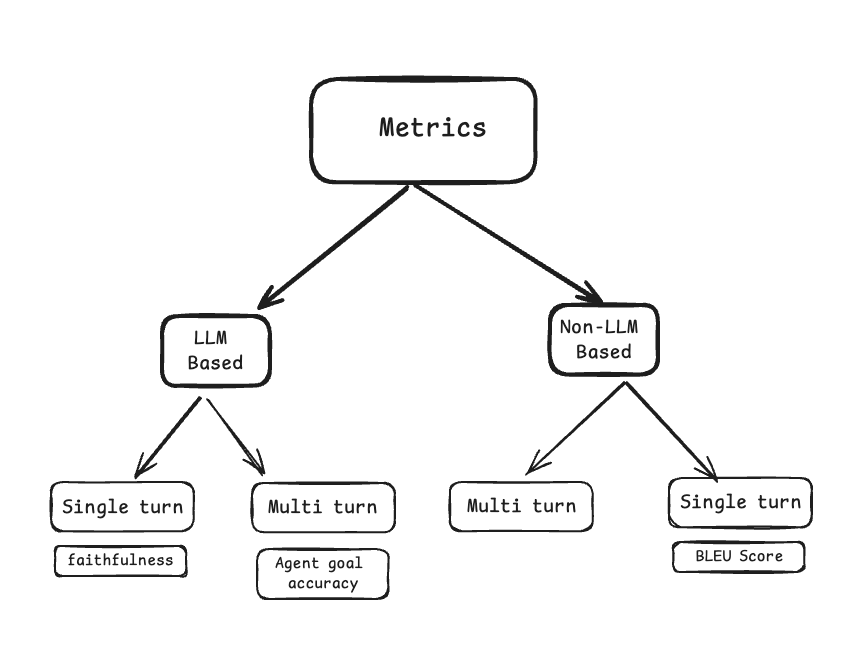
根据底层使用机制的不同,指标可分为两大类:
基于LLM的指标: 这些指标底层使用LLM进行评估。可能需要执行一次或多次LLM调用来得出分数或结果。由于LLM对于相同输入可能不会总是返回相同结果,这些指标可能具有一定的不确定性。另一方面,这些指标已被证明更准确且更接近人工评估。
ragas中所有基于LLM的指标都继承自MetricWithLLM类。这些指标在评分前需要设置一个LLM对象。
每个基于LLM的指标也会附带使用Prompt Object编写的相关提示词。
非基于LLM的指标: 这些指标底层不使用LLM进行评估。这些指标是确定性的,可用于在不使用LLM的情况下评估AI应用的性能。这些指标依赖传统方法来评估AI应用的性能,例如字符串相似度、BLEU分数等。正因如此,这些指标被认为与人类评估的相关性较低。
ragas中所有基于LLM的指标都继承自Metric类。
根据评估的数据类型,指标可大致分为两类:
单轮评估指标: 这些指标基于用户与AI之间的单轮交互来评估AI应用的性能。ragas中所有支持单轮评估的指标都继承自SingleTurnMetric类,并通过single_turn_ascore方法进行评分。它还需要一个Single Turn Sample对象作为输入。
from ragas.metrics import FactualCorrectness
scorer = FactualCorrectness()
await scorer.single_turn_ascore(sample)
多轮对话指标: 这些指标基于用户与AI之间的多轮交互来评估AI应用的性能。ragas中所有支持多轮评估的指标都继承自MultiTurnMetric类,并通过multi_turn_ascore方法进行评分。该方法还要求输入一个Multi Turn Sample对象。
from ragas.metrics import AgentGoalAccuracy
from ragas import MultiTurnSample
scorer = AgentGoalAccuracy()
await scorer.multi_turn_ascore(sample)
指标设计原则
为AI应用设计有效的评估指标需要遵循一系列核心原则,以确保其可靠性、可解释性和相关性。以下是我们在ragas中设计指标时遵循的五个关键原则:
1. 单一维度聚焦
单个指标应仅针对AI应用性能的某一个特定方面。这确保了指标既具有可解释性又具备可操作性,能够清晰反映所测量的内容。
2. 直观且可解释
指标设计应当易于理解和解释。清晰直观的指标能更简单地传达结果并得出有意义的结论。
3. 高效的提示流程
在使用大语言模型(LLMs)开发评估指标时,应采用与人工评估高度契合的智能提示流程。将复杂任务分解为具有特定提示的较小子任务,可以提高指标的准确性和相关性。
4. 鲁棒性
确保基于LLM的指标包含足够反映预期结果的少量示例。通过为LLM提供上下文和指导,这增强了指标的鲁棒性。
5. 一致的评分范围
将指标评分值标准化或确保其落在特定范围内(如0到1)至关重要。这有助于不同指标之间的比较,并保持评估框架的一致性和可解释性。
这些原则为创建评估指标奠定了基础,这些指标不仅能有效评估AI应用,还具有实用性和意义。