YOLO11模型的ONNX导出
通常,在部署计算机视觉模型时,您需要一种既灵活又兼容多种平台的模型格式。
将Ultralytics YOLO11模型导出为ONNX格式可以简化部署过程,并确保在各种环境中实现最佳性能。本指南将向您展示如何轻松将YOLO11模型转换为ONNX格式,并增强其在实际应用中的可扩展性和有效性。
ONNX和ONNX Runtime
ONNX,即开放神经网络交换,是由Facebook和Microsoft最初开发的一个社区项目。ONNX的持续开发是由IBM、亚马逊(通过AWS)和谷歌等多家组织支持的协作努力。该项目旨在创建一种开放的文件格式,用于以跨不同AI框架和硬件的方式表示机器学习模型。
ONNX模型可以无缝地在不同框架之间转换。例如,在PyTorch中训练的深度学习模型可以导出为ONNX格式,然后轻松导入到TensorFlow中。
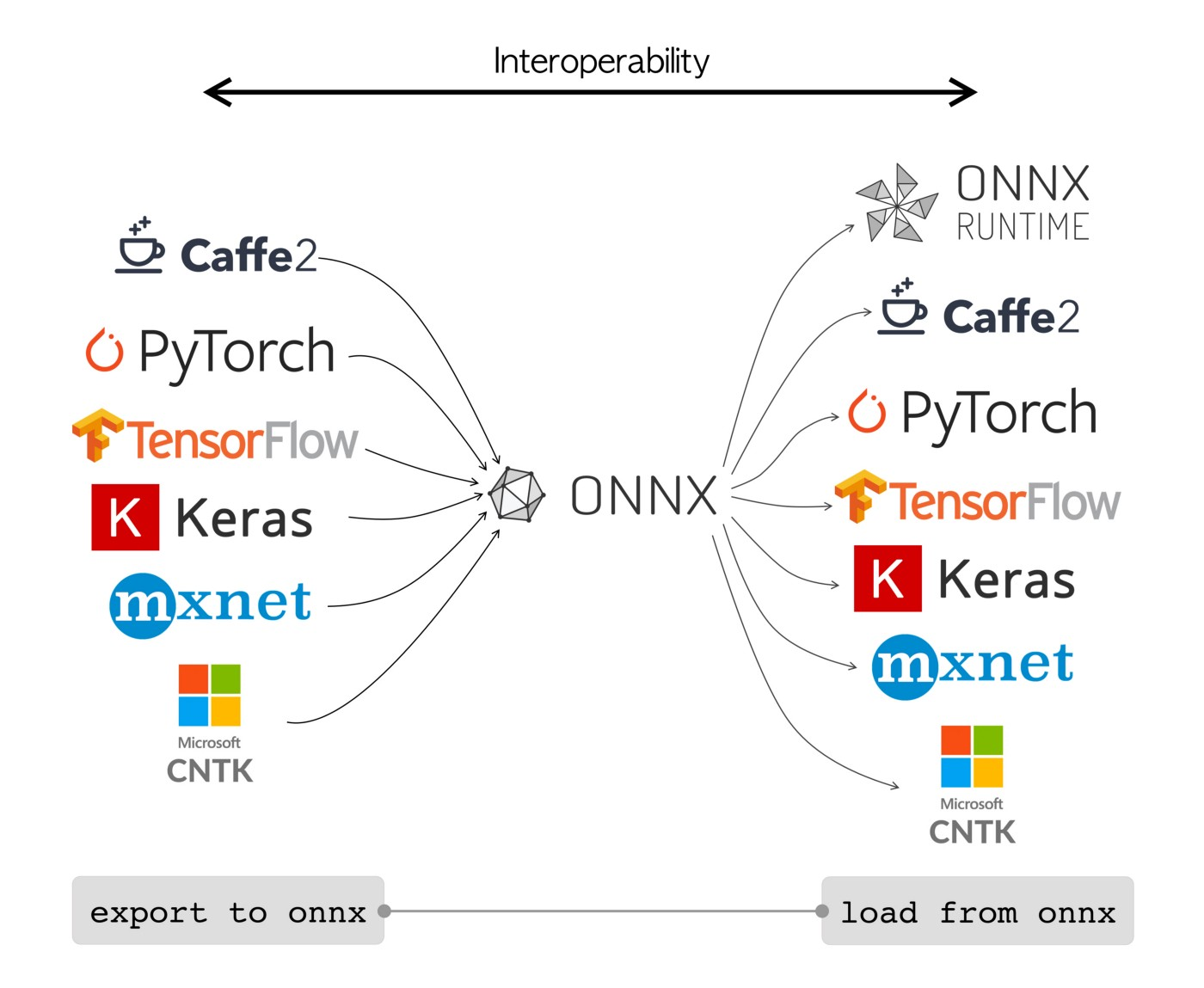
或者,ONNX模型可以与ONNX Runtime一起使用。ONNX Runtime是一个跨平台的机器学习模型加速器,兼容PyTorch、TensorFlow、TFLite、scikit-learn等框架。
ONNX Runtime通过利用硬件特定的功能优化ONNX模型的执行。这种优化使得模型能够在各种硬件平台上高效运行,包括CPU、GPU和专用加速器。
无论是独立使用还是与ONNX Runtime结合使用,ONNX都为机器学习模型部署和兼容性提供了灵活的解决方案。
ONNX模型的关键特性
ONNX能够处理各种格式,归功于以下关键特性:
-
通用模型表示:ONNX定义了一组通用的运算符(如卷积、层等)和标准数据格式。当模型转换为ONNX格式时,其架构和权重被翻译成这种通用表示。这种统一性确保了任何支持ONNX的框架都能理解该模型。
-
版本控制和向后兼容性:ONNX为其运算符维护了一个版本控制系统。这确保了即使标准不断发展,在旧版本中创建的模型仍然可用。向后兼容性是一个关键特性,防止模型迅速过时。
-
基于图的模型表示:ONNX将模型表示为计算图。这种基于图的结构是表示机器学习模型的通用方式,其中节点表示操作或计算,边表示在它们之间流动的张量。这种格式很容易适应也以图表示模型的各种框架。
-
工具和生态系统:围绕ONNX有一套丰富的工具生态系统,用于模型转换、可视化和优化。这些工具使开发者更容易使用ONNX模型,并在不同框架之间无缝转换模型。
ONNX的常见用途
在我们深入了解如何将YOLO11模型导出为ONNX格式之前,让我们先看看ONNX模型通常用于哪些场景。
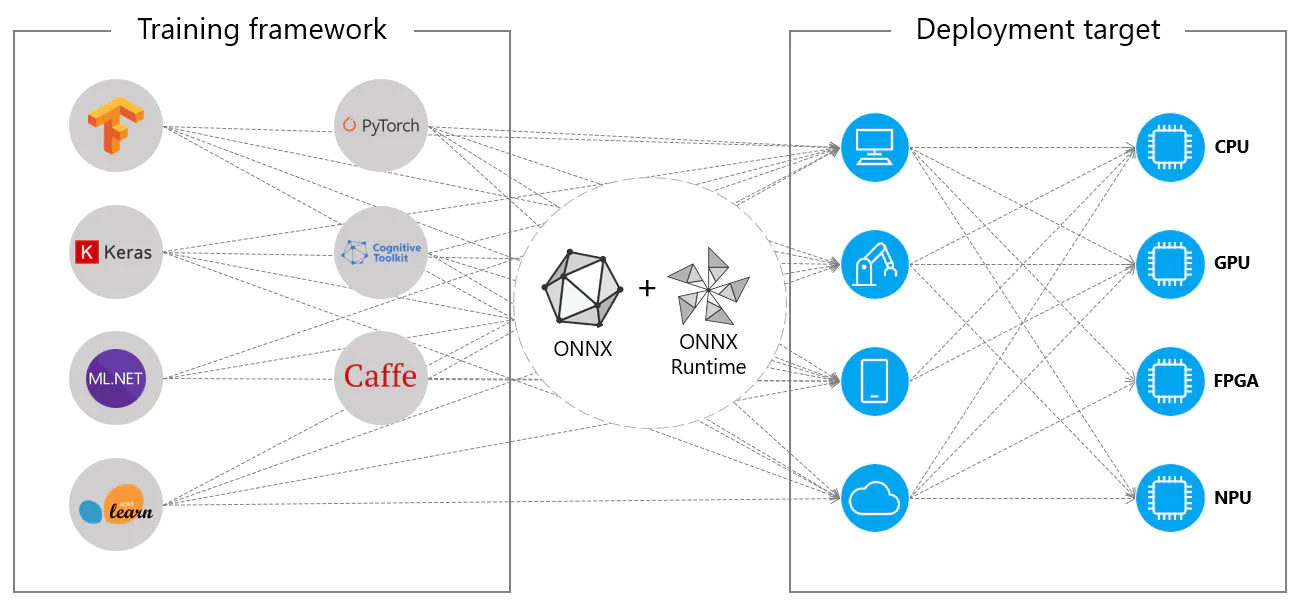
CPU部署
ONNX模型通常部署在CPU上,因为它们与ONNX Runtime兼容。该运行时针对CPU执行进行了优化。它显著提高了推理速度,使得实时CPU部署成为可能。
支持的部署选项
虽然ONNX模型通常用于CPU,但它们也可以部署在以下平台上:
- GPU加速:ONNX完全支持GPU加速,特别是NVIDIA CUDA。这使得在需要高计算能力的任务中在NVIDIA GPU上高效执行成为可能。
-
边缘和移动设备: ONNX 扩展到边缘和移动设备,非常适合设备上和实时推理场景。它轻量且兼容边缘硬件。
-
网页浏览器: ONNX 可以直接在网页浏览器中运行,为基于网页的交互式和动态 AI 应用提供动力。
将 YOLO11 模型导出为 ONNX
通过将 YOLO11 模型转换为 ONNX 格式,您可以扩展模型的兼容性和部署灵活性。
安装
要安装所需的包,请运行:
有关安装过程的详细说明和最佳实践,请查看我们的 YOLO11 安装指南。在安装 YOLO11 所需的包时,如果遇到任何困难,请参考我们的 常见问题指南 以获取解决方案和提示。
使用
在深入使用说明之前,请务必查看 Ultralytics 提供的 YOLO11 模型范围。这将帮助您为项目需求选择最合适的模型。
使用
有关导出过程的更多详细信息,请访问 Ultralytics 导出文档页面。
部署导出的 YOLO11 ONNX 模型
一旦您成功将 Ultralytics YOLO11 模型导出为 ONNX 格式,下一步是在各种环境中部署这些模型。有关部署 ONNX 模型的详细说明,请查看以下资源:
-
ONNX Runtime Python API 文档: 本指南提供了使用 ONNX Runtime 加载和运行 ONNX 模型的基本信息。
-
在边缘设备上部署: 查看此文档页面,了解在边缘部署 ONNX 模型的不同示例。
-
ONNX GitHub 上的教程: 一系列全面的教程,涵盖了在不同场景中使用和实现 ONNX 模型的各个方面。
总结
在本指南中,您学习了如何将 Ultralytics YOLO11 模型导出为 ONNX 格式,以增加它们在各种平台上的互操作性和性能。您还了解了 ONNX Runtime 和 ONNX 部署选项。
有关更多详细信息,请访问 ONNX 官方文档。
此外,如果您想了解更多关于其他 Ultralytics YOLO11 集成的信息,请访问我们的 集成指南页面。您将在那里找到大量有用的资源和见解。
常见问题
如何使用 Ultralytics 将 YOLO11 模型导出为 ONNX 格式?
要使用 Ultralytics 将 YOLO11 模型导出为 ONNX 格式,请按照以下步骤操作:
使用
有关更多详细信息,请访问 导出文档。
使用 ONNX Runtime 部署 YOLO11 模型有哪些优势?
使用 ONNX Runtime 部署 YOLO11 模型具有以下几个优势:
- 跨平台兼容性: ONNX Runtime 支持多种平台,如 Windows、macOS 和 Linux,确保您的模型在不同环境中平稳运行。
- 硬件加速:ONNX Runtime 可以利用针对 CPU、GPU 和专用加速器的硬件特定优化,提供高性能推理。
- 框架互操作性:在流行的框架(如 PyTorch 或 TensorFlow)中训练的模型可以轻松转换为 ONNX 格式,并使用 ONNX Runtime 运行。
了解更多信息,请查看 ONNX Runtime 文档。
YOLO11 模型导出到 ONNX 后有哪些部署选项?
导出到 ONNX 的 YOLO11 模型可以在多种平台上部署,包括:
- CPU:利用 ONNX Runtime 进行优化的 CPU 推理。
- GPU:利用 NVIDIA CUDA 实现高性能 GPU 加速。
- 边缘设备:在边缘和移动设备上运行轻量级模型,实现实时设备内推理。
- Web 浏览器:直接在 Web 浏览器中执行模型,用于交互式基于 Web 的应用程序。
更多信息,请浏览我们的 模型部署选项指南。
为什么我应该使用 ONNX 格式来部署 Ultralytics YOLO11 模型?
使用 ONNX 格式部署 Ultralytics YOLO11 模型提供了诸多好处:
- 互操作性:ONNX 允许模型在不同的机器学习框架之间无缝传输。
- 性能优化:ONNX Runtime 可以通过利用硬件特定优化来提升模型性能。
- 灵活性:ONNX 支持多种部署环境,使您能够在不同平台上使用相同的模型而无需修改。
请参阅关于 将 YOLO11 模型导出到 ONNX 的综合指南。
如何解决将 YOLO11 模型导出到 ONNX 时遇到的问题?
在将 YOLO11 模型导出到 ONNX 时,您可能会遇到依赖项不匹配或不支持的操作等常见问题。要解决这些问题:
- 确认已安装正确版本的所需依赖项。
- 查看官方 ONNX 文档 以了解支持的运算符和功能。
- 查看错误信息以获取线索,并参考 Ultralytics 常见问题指南。
如果问题仍然存在,请联系 Ultralytics 支持以获得进一步帮助。



