SAM 2: 分割一切模型2
SAM 2是Meta的分割一切模型(SAM)的继任者,是一款专为图像和视频中的全面对象分割而设计的尖端工具。它通过统一的、可提示的模型架构处理复杂的视觉数据,支持实时处理和零样本泛化。

关键特性
观看: 如何使用Ultralytics运行Meta的SAM2推理 | 逐步指南 🎉
统一模型架构
SAM 2将图像和视频分割的能力结合在一个模型中。这种统一简化了部署,并允许在不同媒体类型之间保持一致的性能。它利用灵活的基于提示的接口,使用户能够通过各种提示类型(如点、边界框或掩码)指定感兴趣的对象。
实时性能
该模型实现了实时推理速度,每秒处理约44帧。这使得SAM 2适用于需要即时反馈的应用,如视频编辑和增强现实。
零样本泛化
SAM 2可以分割它从未遇到过的对象,展示了强大的零样本泛化能力。这在多样或不断发展的视觉领域特别有用,其中预定义的类别可能无法涵盖所有可能的对象。
交互式优化
用户可以通过提供额外的提示迭代优化分割结果,从而对输出进行精确控制。这种交互性对于在视频标注或医学成像等应用中微调结果至关重要。
高级视觉挑战处理
SAM 2包括管理常见视频分割挑战(如对象遮挡和重新出现)的机制。它使用复杂的记忆机制来跟踪跨帧的对象,确保即使在对象暂时被遮挡或退出并重新进入场景时也能保持连续性。
要深入了解SAM 2的架构和能力,请参阅SAM 2研究论文。
性能和技术细节
SAM 2在领域中树立了新的标杆,在各种指标上优于之前的模型:
| 指标 | SAM 2 | 之前的SOTA |
|---|---|---|
| 交互式视频分割 | 最佳 | - |
| 所需的人类交互 | 少3倍 | 基线 |
| 图像分割 准确性 | 改进 | SAM |
| 推理速度 | 快6倍 | SAM |
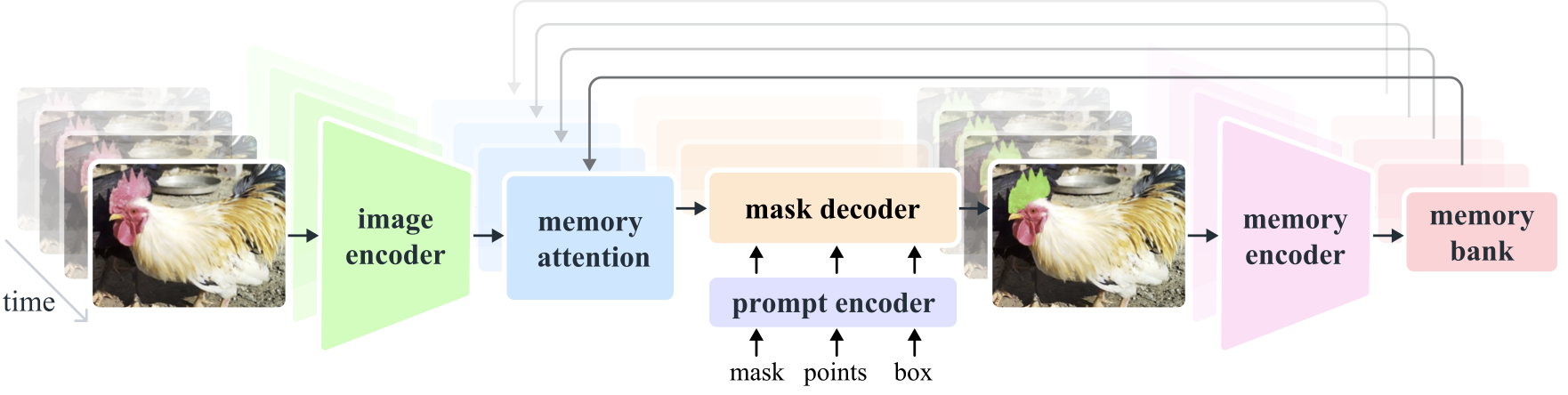
模型架构
核心组件
- 图像和视频编码器: 利用基于transformer的架构从图像和视频帧中提取高级特征。该组件负责在每个时间步理解视觉内容。
- 提示编码器: 处理用户提供的提示(点、框、掩码)以指导分割任务。这使得SAM 2能够适应用户输入并在场景中定位特定对象。
- 记忆机制: 包括记忆编码器、记忆库和记忆注意力模块。这些组件共同存储和利用过去帧的信息,使模型能够随着时间的推移保持一致的对象跟踪。
- 掩码解码器: 根据编码的图像特征和提示生成最终的分割掩码。在视频中,它还使用记忆上下文以确保跨帧的准确跟踪。
记忆机制与遮挡处理
记忆机制使SAM 2能够处理视频数据中的时间依赖性和遮挡问题。随着物体的移动和互动,SAM 2将它们的特征记录在记忆库中。当物体被遮挡时,模型可以依赖这个记忆来预测物体重新出现时的位置和外观。遮挡头专门处理物体不可见的情况,预测物体被遮挡的可能性。
多掩码模糊性解决
在存在模糊性的情况下(例如,重叠物体),SAM 2可以生成多个掩码预测。这一功能对于准确表示复杂场景至关重要,因为在这些场景中,单一掩码可能不足以充分描述场景的细微差别。
SA-V数据集
为SAM 2的训练开发的SA-V数据集是可用的大型且多样化的视频分割数据集之一。它包括:
- 51,000+视频:跨越47个国家拍摄,提供了广泛的现实世界场景。
- 600,000+掩码注释:详细的时空掩码注释,称为“掩码片段”,覆盖整个物体和部分。
- 数据集规模:它比之前最大的数据集多出4.5倍的视频和53倍的注释,提供了前所未有的多样性和复杂性。
基准测试
视频对象分割
SAM 2在主要视频分割基准测试中展示了卓越的性能:
| 数据集 | J&F | J | F |
|---|---|---|---|
| DAVIS 2017 | 82.5 | 79.8 | 85.2 |
| YouTube-VOS | 81.2 | 78.9 | 83.5 |
交互式分割
在交互式分割任务中,SAM 2展示了显著的效率和准确性:
| 数据集 | NoC@90 | AUC |
|---|---|---|
| DAVIS Interactive | 1.54 | 0.872 |
安装
要安装SAM 2,请使用以下命令。所有SAM 2模型将在首次使用时自动下载。
如何使用SAM 2:图像和视频分割的多功能性
下表详细列出了可用的SAM 2模型、它们的预训练权重、支持的任务以及与不同操作模式(如推理、验证、训练和导出)的兼容性。
| 模型类型 | 预训练权重 | 支持的任务 | 推理 | 验证 | 训练 | 导出 |
|---|---|---|---|---|---|---|
| SAM 2 tiny | sam2_t.pt | 实例分割 | ✅ | ❌ | ❌ | ❌ |
| SAM 2 small | sam2_s.pt | 实例分割 | ✅ | ❌ | ❌ | ❌ |
| SAM 2 base | sam2_b.pt | 实例分割 | ✅ | ❌ | ❌ | ❌ |
| SAM 2 large | sam2_l.pt | 实例分割 | ✅ | ❌ | ❌ | ❌ |
SAM 2预测示例
SAM 2可以在广泛的领域中使用,包括实时视频编辑、医学成像和自主系统。它能够分割静态和动态视觉数据,使其成为研究人员和开发人员的通用工具。
使用提示进行分割
使用提示进行分割
使用提示在图像或视频中分割特定对象。
分割所有内容
分割所有内容
无需特定提示即可分割整个图像或视频内容。
- 此示例展示了在没有提供任何提示(边界框/点/掩码)的情况下,如何使用SAM 2来分割图像或视频的全部内容。
SAM 2 与 YOLOv8 的比较
在这里,我们将Meta最小的SAM 2模型SAM2-t与Ultralytics最小的分割模型YOLOv8n-seg进行比较:
| 模型 | 大小 (MB) |
参数 (M) |
速度 (CPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 161440 |
| Meta SAM2-b | 162 | 80.8 | 121923 |
| Meta SAM2-t | 78.1 | 38.9 | 85155 |
| MobileSAM | 40.7 | 10.1 | 98543 |
| FastSAM-s with YOLOv8 backbone | 23.7 | 11.8 | 140 |
| Ultralytics YOLOv8n-seg | 6.7 (11.7倍更小) | 3.4 (11.4倍更少) | 79.5 (1071倍更快) |
此比较展示了模型大小和速度之间的数量级差异。虽然SAM提供了自动分割的独特能力,但它并不是YOLOv8分割模型的直接竞争对手,后者更小、更快、更高效。
测试在2023年配备16GB内存的Apple M2 Macbook上运行,使用torch==2.3.1和ultralytics==8.3.82。要重现此测试:
Example
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# 分析SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# 分析FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# 分析YOLOv8n-seg
model = YOLO("yolov8n-seg.pt")
model.info()
model(ASSETS)
自动标注:高效的数据集创建
自动标注是SAM 2的一个强大功能,使用户能够通过利用预训练模型快速准确地生成分割数据集。此功能特别适用于创建大型高质量数据集,而无需大量手动工作。
如何使用SAM 2进行自动标注
要使用SAM 2自动标注您的数据集,请按照以下示例操作:
自动标注示例
| 参数 | 类型 | 描述 | 默认值 |
|---|---|---|---|
data |
str |
包含待标注图像的文件夹路径。 | |
det_model |
str, 可选 |
预训练的YOLO检测模型。默认为'yolov8x.pt'。 | 'yolov8x.pt' |
sam_model |
str, 可选 |
预训练的SAM 2分割模型。默认为'sam2_b.pt'。 | 'sam2_b.pt' |
device |
str, 可选 |
运行模型的设备。默认为空字符串(CPU或GPU,如果可用)。 | |
output_dir |
str, None, 可选 |
保存标注结果的目录。默认为与'data'同一目录下的'labels'文件夹。 | None |
此功能有助于快速创建高质量的分割数据集,非常适合希望加速其项目的研究人员和开发者。
局限性
尽管SAM 2具有优势,但它也有一定的局限性:
- 跟踪稳定性:SAM 2在长时间序列或显著视角变化时可能会丢失对象的跟踪。
- 对象混淆:模型有时会混淆外观相似的对象,特别是在拥挤的场景中。
- 多对象处理效率:由于缺乏对象间通信,处理多个对象时的分割效率会降低。
- 细节 准确性:可能会遗漏精细细节,特别是在快速移动的物体上。额外的提示可以部分解决这个问题,但不保证时间上的平滑性。
引用和致谢
如果 SAM 2 是您研究或开发工作的关键部分,请使用以下参考文献进行引用:
@article{ravi2024sam2,
title={SAM 2: Segment Anything in Images and Videos},
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
journal={arXiv preprint},
year={2024}
}
我们向 Meta AI 表示感谢,感谢他们通过这一开创性的模型和数据集为 AI 社区做出的贡献。
常见问题
什么是 SAM 2,它如何改进原始的 Segment Anything Model (SAM)?
SAM 2 是 Meta 的 Segment Anything Model (SAM) 的继任者,是一款用于图像和视频中全面对象分割的前沿工具。它通过一个统一的、可提示的模型架构,在处理复杂视觉数据方面表现出色,支持实时处理和零样本泛化。SAM 2 在原始 SAM 的基础上提供了多项改进,包括:
- 统一的模型架构:在一个模型中结合了图像和视频分割能力。
- 实时性能:每秒处理约 44 帧,适用于需要即时反馈的应用。
- 零样本泛化:分割从未遇到过的对象,适用于多样化的视觉领域。
- 交互式细化:允许用户通过提供额外提示来迭代细化分割结果。
- 高级视觉挑战处理:管理常见的视频分割挑战,如对象遮挡和重新出现。
有关 SAM 2 架构和能力的更多详细信息,请参阅 SAM 2 研究论文。
如何使用 SAM 2 进行实时视频分割?
SAM 2 可以通过利用其可提示的接口和实时推理能力用于实时视频分割。以下是一个基本示例:
使用提示进行分割
使用提示在图像或视频中分割特定对象。
有关更全面的用法,请参阅 如何使用 SAM 2 部分。
用于训练 SAM 2 的数据集是什么,它们如何增强其性能?
SAM 2 是在 SA-V 数据集上训练的,这是目前最大且最多样化的视频分割数据集之一。SA-V 数据集包括:
- 51,000+ 视频:在 47 个国家拍摄,提供了广泛的现实世界场景。
- 600,000+ 掩码标注:详细的时空掩码标注,称为“masklets”,覆盖整个对象和部分。
- 数据集规模:比之前最大的数据集多 4.5 倍的视频和 53 倍的标注,提供了前所未有的多样性和复杂性。
这个广泛的数据集使 SAM 2 在主要视频分割基准上实现了卓越的性能,并增强了其零样本泛化能力。更多信息请参阅 SA-V 数据集 部分。
SAM 2 如何处理视频分割中的遮挡和对象重新出现?
SAM 2 包含一个复杂的记忆机制,用于管理视频数据中的时间依赖性和遮挡。记忆机制包括:
- 记忆编码器和记忆库:存储过去帧的特征。
- 记忆注意力模块:利用存储的信息来保持随时间一致的对象跟踪。
- 遮挡头:专门处理对象不可见的情况,预测对象被遮挡的可能性。
这种机制确保了即使对象暂时被遮挡或退出并重新进入场景,也能保持连续性。更多详细信息请参阅 记忆机制和遮挡处理 部分。
SAM 2 与其他分割模型(如 YOLOv8)相比如何?
SAM 2 和 Ultralytics YOLOv8 服务于不同的目的,并在不同领域表现出色。虽然 SAM 2 设计用于全面的对象分割,具备零样本泛化和实时性能等高级功能,但 YOLOv8 则针对目标检测和分割任务的速度和效率进行了优化。以下是它们的比较:
| 模型 | 大小 (MB) |
参数 (M) |
速度 (CPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 161440 |
| Meta SAM2-b | 162 | 80.8 | 121923 |
| Meta SAM2-t | 78.1 | 38.9 | 85155 |
| MobileSAM | 40.7 | 10.1 | 98543 |
| FastSAM-s with YOLOv8 backbone | 23.7 | 11.8 | 140 |
| Ultralytics YOLOv8n-seg | 6.7 (11.7x smaller) | 3.4 (11.4x less) | 79.5 (1071x faster) |
更多详情,请参阅 SAM 2 与 YOLOv8 的比较 部分。




