提高可靠性的技巧
当 GPT-3 在某个任务上失败时,你应该怎么做?
- 寻找一个能引发更可靠答案的更好提示?
- 投入数千个示例来微调一个定制模型?
- 假设模型无法完成该任务,然后继续前进?
没有简单的答案——这取决于具体情况。然而,如果你的任务涉及逻辑推理或复杂性,可以考虑尝试本文中的技巧来构建更可靠、高性能的提示。
为什么 GPT-3 在复杂任务上失败
如果你被要求计算 13 乘以 17,答案会立即出现在你的脑海中吗?对于我们大多数人来说,可能不会。但这并不意味着人类无法进行两位数的乘法。只需几秒钟,再加上纸和笔,计算出 13 x 17 = 130 + 70 + 21 = 221 并不太费力。
同样地,如果你给 GPT-3 一个过于复杂的任务,以至于它在计算下一个标记的时间内无法完成,它可能会虚构一个错误的猜测。然而,类似于人类,这并不一定意味着模型无法完成该任务。如果有时间和空间进行推理,模型仍然可能可靠地回答。
例如,如果你向 gpt-3.5-turbo-instruct 提出以下关��于杂耍球的数学问题,它会给出错误答案:
Q: 一个杂耍者有 16 个球。其中一半是高尔夫球,而高尔夫球中有一半是蓝色的。有多少个蓝色高尔夫球?
A:
有 8 个蓝色高尔夫球。
这是否意味着 GPT-3 不能解决简单的数学问题?不;事实上,通过向模型提示 让我们一步一步来思考,模型可以可靠地解决问题:
Q: 一个杂耍者有 16 个球。其中一半是高尔夫球,而高尔夫球中有一半是蓝色的。有多少个蓝色高尔夫球?
A: 让我们一步一步来思考。
总共有 16 个球。
其中一半是高尔夫球。
这意味着有 8 个高尔夫球。
其中一半是蓝色的。
这意味着有 4 个蓝色高尔夫球。
当然,仅从一个例子很难判断 让我们一步一步来思考 这个技巧是否普遍有效,或者只是在这个特定问题上碰巧成功。但它的确有效。在一个文字数学问题的基准测试中,让我们一步一步来思考 这个技巧将 GPT-3 的解决率大幅提升,从毫无价值的 18% 提高到不错的 79%!
模型的能力取决于上下文
在学习如何使用 GPT-3 时,一个常见的概念性错误是认为其能力在所有上下文中都是固定的。例如,如果 GPT-3 在一个简单的逻辑问题上出错,那么它一定无法处理简单的逻辑。
但正如 让我们一步一步来思考 的例子所示,GPT-3 的明显失败有时可以通过更好的提示来弥补,帮助模型引导自己走向正确的输出。
如何提高复杂任务的可靠性
本文的其余部分分享了提高大型语言模型在复杂任务上可靠性的技巧。虽然其中一些技巧特定于某些类型的问题,但许多技巧都是基于可以广泛应用于各种任务的通用原则,例如:
- 给出更清晰的指令
- 将复杂任务分解为更简单的子任务
- 构建指令以保持模型在任务上
- 提示模型在回答前进行解释
- 要求对多种可能的答案进行论证,然后综合
- 生成多个输出,然后使用模型选择最佳的一个
- 微调定制模型以最大化性能
将复杂任务分解为更简单的任务
给模型更多时间和空间思��考的一种方法是分解任务为更简单的部分。
例如,考虑一个任务,我们要求模型回答关于某些文本的多项选择题——在这种情况下,是一个《线索》游戏。当直接提问时,gpt-3.5-turbo-instruct 无法将线索 3 和 5 结合起来,并给出错误答案:
使用以下线索回答以下多项选择题。
线索:
1. 斯卡利特小姐是唯一在休息室的人。
2. 拿着烟斗的人在厨房。
3. 穆斯塔德上校是唯一在瞭望台的人。
4. 普兰教授不在图书馆也不在台球室。
5. 拿着烛台的人在瞭望台。
问题:穆斯塔德上校在瞭望台拿着烛台吗?
(a) 是的;穆斯塔德上校在瞭望台拿着烛台
(b) 不是;穆斯塔德上校不在瞭望台拿着烛台
(c) 未知;没有足够的信息来确定穆斯塔德上校是否在瞭望台拿着烛台
解决方案:
(c) 未知;没有足够的信息来确定穆斯塔德上校是否在瞭望台拿着烛台
尽管线索3和线索5表明Mustard上校是唯一在观察室的人,并且持有烛台的人也在观察室,但模型未能将这两条线索结合起来得出正确答案(a)是。
然而,我们可以将任务分解为三个部分,而不是直接要求答案:
- 首先,逐一检查线索,考虑线索是否可能相关
- 其次,结合相关线索推理出问题的答案
- 最后,写出最终答案:(a)、(b)或(c)
使用以下线索回答以下多项选择题,按照以下步骤进行:
(1)首先,逐一检查线索,考虑线索是否可能相关
(2)其次,结合相关线索推理出问题的答案
(3)最后,将答案映射到多项选择答案之一:(a)、(b)或(c)
线索:
1. Scarlett小姐是唯一在休息室的人。
2. 持有烟斗的人在厨房。
3. Mustard上校是唯一在观察室的人。
4. Plum教授不在图书馆也不在台球室。
5. 持有烛台的人在观察室。
问题:Mustard上校在观察室里拿着烛台吗?
(a)是;Mustard上校在观察室里拿着烛台
(b)否;Mustard上校不在观察室里拿着烛台
(c)未知;没有足够的信息来确定Mustard上校是否在观察室里拿着烛台
解决方案:
(1)首先,逐一检查线索,考虑线索是否可能相关:
线索1:Scarlett小姐是唯一在休息室的人。这条线索不相关。
线索2:持有烟斗的人在厨房。这条线索不相关。
线索3:Mustard上校是唯一在观察室的人。这条线索相关。
线索4:Plum教授不在图书馆也不在台球室。这条线索不相关。
线索5:持有烛台的人在观察室。这条线索相关。
(2)其次,结合相关线索推理出问题的答案:
线索3和线索5都表明持有烛台的人在观察室。Mustard上校是唯一��在观察室的人,所以Mustard上校就是持有烛台的人。
(3)最后,写出最终答案:
(a)是;Mustard上校在观察室里拿着烛台
通过给模型更多的时间和空间来思考,并引导它按照推理计划进行,它能够得出正确答案(a)是。
将复杂指令分解为更小的子任务的另一个好处是,它可以帮助模型专注于每个子任务。
例如,如果我们要求gpt-3.5-turbo-instruct用原文语言总结一段文字,模型可能会回到英语:
用原文语言总结这段文字。摘要应为一句话。
文字:
"""
La estadística (la forma femenina del término alemán Statistik, derivado a su vez del italiano statista, "hombre de Estado") es una ciencia que estudia la variabilidad, colección, organización, análisis, interpretación, y presentación de los datos, así como el proceso aleatorio que los genera siguiendo las leyes de la probabilidad. La estadística es una ciencia formal deductiva, con un conocimiento propio, dinámico y en continuo desarrollo obtenido a través del método científico formal. En ocasiones, las ciencias fácticas necesitan utilizar técnicas estadísticas durante su proceso de investigación factual, con el fin de obtener nuevos conocimientos basados en la experimentación y en la observación. En estos casos, la aplicación de la estadística permite el análisis de datos provenientes de una muestra representativa, que busca explicar las correlaciones y dependencias de un fenómeno físico o natural, de ocurrencia en forma aleatoria o condicional.
"""
摘要:
这段文字解释了统计学是一门研究数据的可变性、收集、组织、分析、解释和呈现的科学,以及遵循概率定律的随机过程。
然而,如果我们首先要求模型识别文本的语言,然后再总结文本,它会变得更可靠:
First, identify the language of the text. Second, summarize the text using the original language of the text. The summary should be one sentence long.
Text:
"""
La estadística (la forma femenina del término alemán Statistik, derivado a su vez del italiano statista, "hombre de Estado") es una ciencia que estudia la variabilidad, colección, organización, análisis, interpretación, y presentación de los datos, así como el proceso aleatorio que los genera siguiendo las leyes de la probabilidad. La estadística es una ciencia formal deductiva, con un conocimiento propio, dinámico y en continuo desarrollo obtenido a través del método científico formal. En ocasiones, las ciencias fácticas necesitan utilizar técnicas estadísticas durante su proceso de investigación factual, con el fin de obtener nuevos conocimientos basados en la experimentación y en la observación. En estos casos, la aplicación de la estadística permite el análisis de datos provenientes de una muestra representativa, que busca explicar las correlaciones y dependencias de un fenómeno físico o natural, de ocurrencia en forma aleatoria o condicional.
"""
Language:
Spanish
La estadística es una ciencia que estudia la variabilidad, colección, organización, análisis, interpretación, y presentación de los datos, así como el proceso aleatorio que los genera siguiendo las leyes de la probabilidad.
提示模型在回答前进行解释
另一种提高答案可靠性的强大技术是提示模型逐步推理出答案,而不是立即跳到最终答案。通过“自言自语”,模型更有可能得出正确答案。
零样本
方法
由 Takeshi Kojima 等人在 2022 年发表,提示模型推理出答案的最简单方法是简单地在答案前加上 让我们一步一步来思考。 图 2 展示了一个例子:
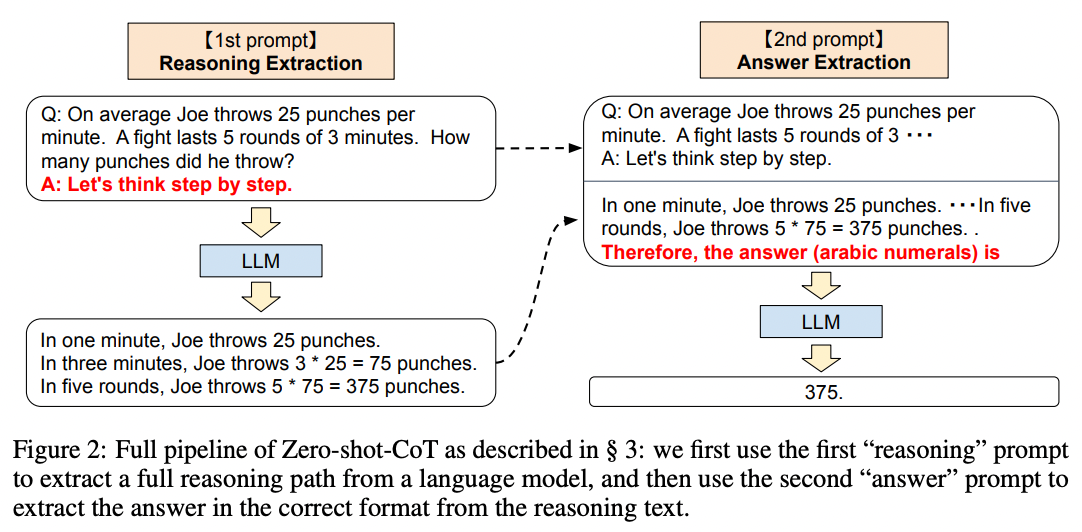 来源:Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
来源:Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
结果
将这个简单的技巧应用于 MultiArith 数学数据集,作者发现 让我们一步一步来思考 使准确率提高了四倍,从 18% 提高到 79%!
 来源:Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
来源:Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
影响
尽管 让我们一步一步来思考 技巧在数学问题上效果良好,但它并非对所有任务都有效。作者发现它对多步骤算术问题、符号推理问题、策略问题和其他推理问题最有帮助。它对简单数学问题或常识问题没有帮助,并且据推测对许多其他非推理任务也没有帮助。
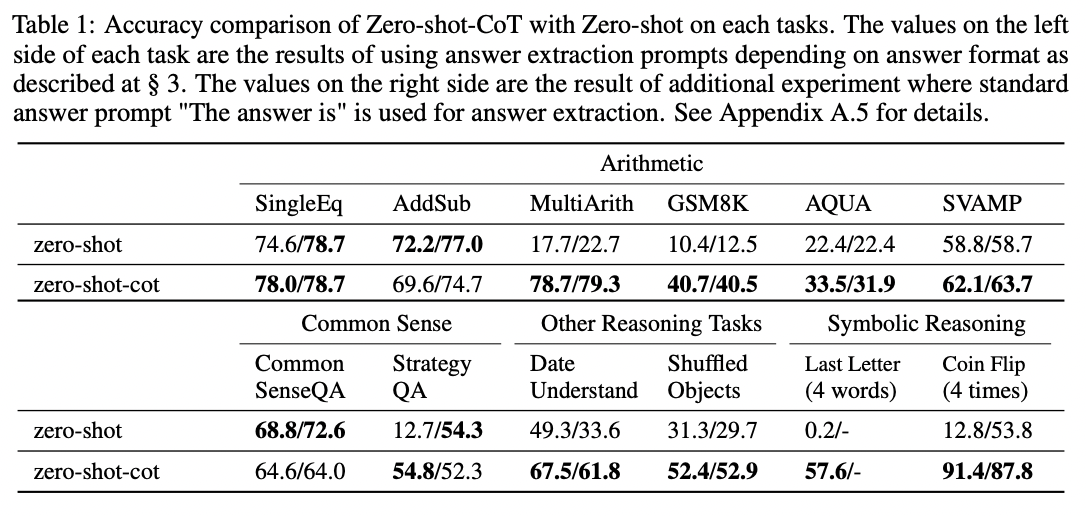 来源:Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
来源:Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
了解更多,请阅读 完整论文。
如果你��将这种技术应用于自己的任务,不要害怕尝试定制指令。让我们一步一步来思考 相当通用,因此你可能会发现更严格的格式定制指令能带来更好的性能。例如,你可以尝试更结构化的变体,如 首先,一步一步思考为什么 X 可能是真的。其次,一步一步思考为什么 Y 可能是真的。第三,一步一步思考 X 或 Y 哪个更有道理。 你甚至可以给模型一个示例格式,帮助它保持正轨,例如:
根据以下 IRS 指南,使用以下格式回答以下问题:
(1) 对于每个标准,确定车辆购买是否符合
- {标准} 让我们一步一步来思考。{解释} {是或否,或者如果问题不适用则 N/A}。
(2) 在依次考虑每个标准后,将最终答案表述为“因为 {原因},答案很可能是 {是或否}。”
IRS 指南:
"""
如果您购买的汽车或卡车符合以下标准,您可能有资格获得第 30D 条下的联邦税收抵免:
- 车辆是否有至少四个轮子?
- 车辆是否重量小于 14,000 磅?
- 车辆是否从至少 4 千瓦时的电池中获取能量,该电池可从外部源充电?
- 车辆是否在 2022 年之前购买?
- 如果是,制造商是否销售了少于 200,000 辆合格车辆?(特斯拉和通用汽车已销售超过 200,000 辆合格车辆。)
- 车辆是否在 2022 年之后购买?
- 如果是,车辆是否出现在以下北美组装车辆列表中?(唯一在北美组装的电动汽车是奥迪 Q5、宝马 330e、宝马 X5、雪佛兰 Bolt EUV、雪佛兰 Bolt EV、克莱斯勒 Pacifica PHEV、福特 Escape PHEV、福特 F 系列、福特 Mustang MACH E、福特 Transit Van、GMC Hummer Pickup、GMC Hummer SUV、Jeep Grand Cherokee PHEV、Jeep Wrangler PHEV、林肯 Aviator PHEV、林肯 Corsair Plug-in、Lucid Air、日产 Leaf、Rivian EDV、Rivian R1S、Rivian R1T、特斯拉 Model 3、特斯拉 Model S、特斯拉 Model X、特斯拉 Model Y、沃尔沃 S60、宝马 330e、Bolt EV、凯迪拉克 Lyriq、梅赛德斯 EQS SUV 和日产 Leaf。)
"""
问题:我可以在 2021 年购买的丰田 Prius Prime 上申请联邦税收抵免吗?
解决方案:
(1) 对于每个标准,确定车辆购买是否符合
- 车辆是否有至少四个轮子? 让我们一步一步来思考。
丰田普锐斯Prime有四个轮子,所以答案是肯定的。
- 车辆重量是否小于14,000磅?让我们一步一步来思考。丰田普锐斯Prime的重量小于14,000磅,所以答案是肯定的。
- 车辆是否从至少4千瓦时的电池中获取能量,并且该电池可以通过外部源充电?让我们一步一步来思考。丰田普锐斯Prime有一个至少4千瓦时的电池,可以通过外部源充电,所以答案是肯定的。
- 车辆是否在2022年之前购买?让我们一步一步来思考。丰田普锐斯Prime是在2021年购买的,这是在2022年之前,所以答案是肯定的。
- 车辆是否在2022年之后购买?不适用
- 如果是这样,车辆是否出现在以下北美组装车辆的列表中?不适用
(2) 在逐一考虑每个标准后,将最终答案表述为“由于{原因},答案很可能是{是或否}。”
因为丰田普锐斯Prime符合所有联邦税收抵免的标准,答案很可能是肯定的。
少样本示例
方法
引导模型推理出答案的方法有很多种。一种方法是使用几个示例(即“少样本”)进行演示,正如Google的Jason Wei和Denny Zhou等人所研究的那样。以下是一个少样本思维链提示的示例:
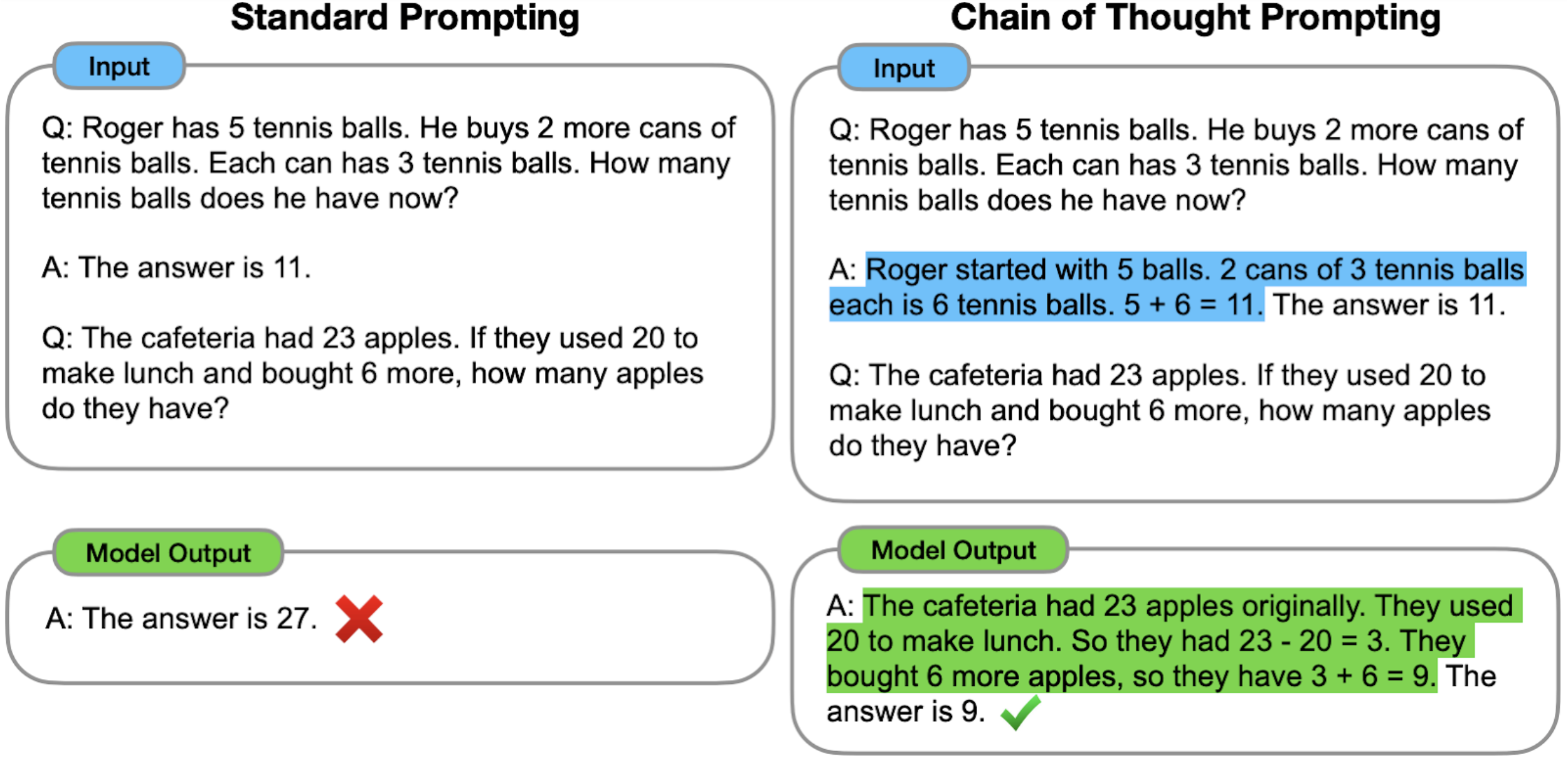 来源:《思维链提示在大规模语言模型中引发推理》Jason Wei和Denny Zhou等人(2022)
来源:《思维链提示在大规模语言模型中引发推理》Jason Wei和Denny Zhou等人(2022)
更多由人类标注者编写的推理链演示:
 来源:《思维链提示在大规模语言模�型中引发推理》Jason Wei和Denny Zhou等人(2022)
来源:《思维链提示在大规模语言模�型中引发推理》Jason Wei和Denny Zhou等人(2022)
(需要注意的是,梨是否真的会浮在水面上已被质疑)来源
结果
在小学数学问题的测试中,作者发现思维链提示将解决率从18%提高到了57%。
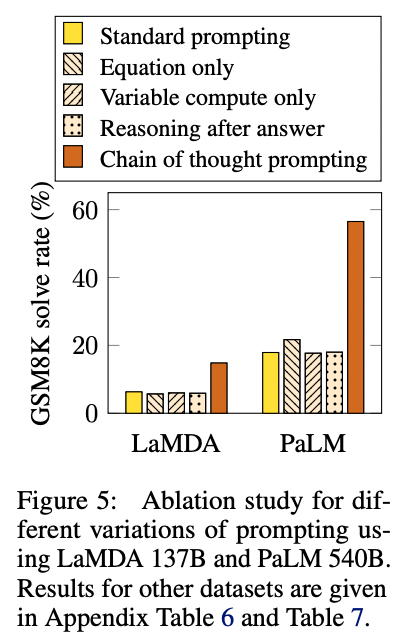 来源:《思维链提示在大规模语言模型中引发推理》Jason Wei和Denny Zhou等人(2022)
来源:《思维链提示在大规模语言模型中引发推理》Jason Wei和Denny Zhou等人(2022)
除了数学问题,思维链提示还在与体育理解、硬币翻转追踪和最后一个字母拼接相关的问题上提升了性能。在大多数情况下,不需要很多示例就能达到性能提升的饱和点(少于8个)。
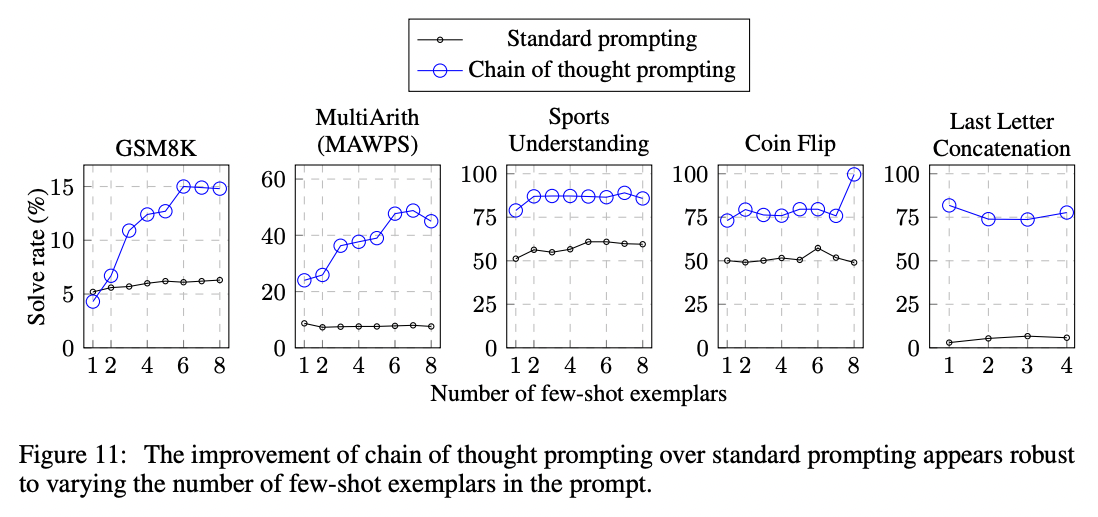 来源:《思维链提示在大规模语言模型中引发推理》Jason Wei和Denny Zhou等人(2022)
来源:《思维链提示在大规模语言模型中引发推理》Jason Wei和Denny Zhou等人(2022)
了解更多,请阅读完整论文。
影响
相对于“让我们一步一步来思考”的技术,少样本示例方法的一个优势是你可以更容易地指定模型在得出最终答案之前应执行的推理格式、长度和风格。这在模型最初没有以正确的方式或深度进行推理的情况下特别有用。
微调
方法
一般来说,要在某个任务上发挥最大性能,你需要对自定义模型进行微调。然而,使用解释进行模型微调可能需要成千上万的示例解释,这些解释编写成本高昂。
2022年,Eric Zelikman和Yuhuai Wu等人发布了一种巧妙的过程,使用少样本提示生成可用于微调模型的解释数据集。其思路是使用少样本提示生成候选解释,只保留那些产生正确答案的解释。然后,对于一些错误的答案,重新尝试少样本提示,但这次将正确答案作为问题的一部分给出。作者称他们的过程为STaR(自我教学推理者):
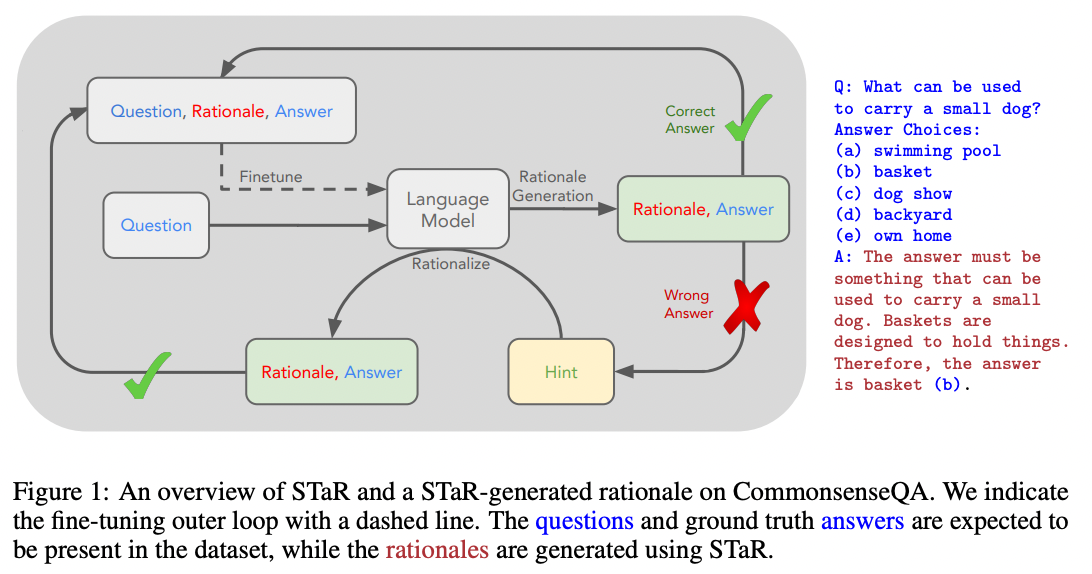 来源:《STaR:通过推理进行推理的自举》Eric Zelikman和Yujuai Wu等人(2022)
来源:《STaR:通过推理进行推理的自举》Eric Zelikman和Yujuai Wu等人(2022)
通过这种技术,你可以结合微调和思维链提示的好处,而不需要编写成千上万的示例解释。
结果
当作者将这种技术应用于一个常识问答数据集时,他们发现STaR的表现优于单独的思维链提示(73% > 37%)和单独的微调(73% > 60%):
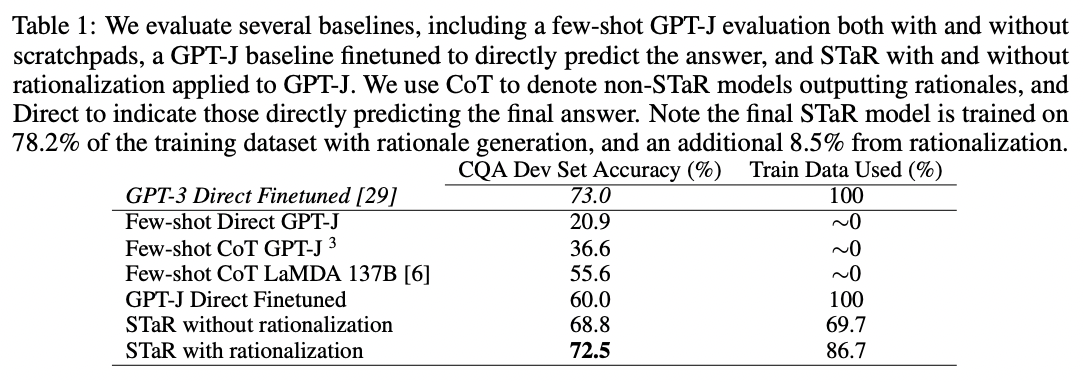 来源:《STaR:通过推理进行推理的自举》Eric Zelikman和Yujuai Wu等人(2022)
来源:《STaR:通过推理进行推理的自举》Eric Zelikman和Yujuai Wu等人(2022)
了解更多,请阅读完整论文。
影响
使用少样本提示扩展或修改微调数据集的想法可以推广到解释编写之外。例如,如果你有大量非结构化文本想要用于训练,你可能会发现使用提示从非结构化文本中提取结构化数据集的机会,然后在该结构化数据集上微调自定义模型。
思维链提示的扩展
思维链提示的许多扩展也被发表了。
选择-推理提示
方法
由Antonia Creswell等人发表的一项扩展技术,将生成解释和答案的单一提示拆分为更小的部分。首先,一个提示从文本中选择相关的事实子集('选择提示')。接着,第二个提示从选定的事实中推断出结论('推理提示')。这些提示随后在一个循环中交替使用,以生成多步推理,并最终得出最终答案。作者在下图中展示了这一想法:
 来源:Antonia Creswell等人(2022年)的《选择-推理:利用大型语言模型进行可解释的逻辑推理》
来源:Antonia Creswell等人(2022年)的《选择-推理:利用大型语言模型进行可解释的逻辑推理》
结果
在应用于一个70亿参数的模型时,作者发现,相较于思维链提示,选择-推理提示在bAbi和Proof Writer基准任务(两者均需要较长的推理步骤序列)上显著提升了性能。他们达到的最佳性能是将选择-推理提示与微调相结合。
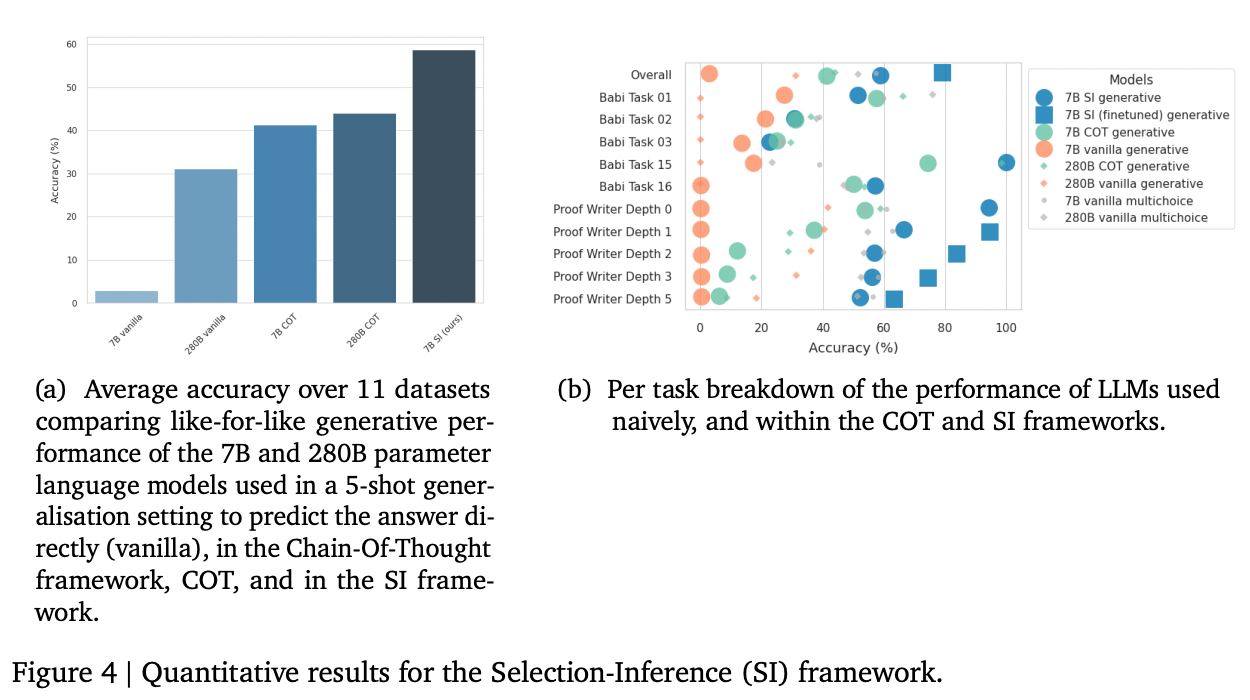 来源:Antonia Creswell等人(2022年)的《选择-推理:利用大型语言模型进行可解释的逻辑推理》
来源:Antonia Creswell等人(2022年)的《选择-推理:利用大型语言模型进行可解释的逻辑推理》
影响
尽管在这些基准测试上的提升显著,但这些测试之所以被选中,是因为它们需要较长的推理序列。对于不需要多步推理的问题,提升可能较小。
这些结果突显了几个与大型语言模型工作相关的普遍教训。首先,将复杂任务分解为更小的任务是提高可靠性和性能的好方法;任务越原子化,模型出错的空间就越小。其次,要获得最大性能,往往意味着将微调与你选择的任何方法相结合。
了解更多,请阅读完整论文。
忠实推理架构
在发表选择-推理提示技术几个月后,作者在后续论文中对该技术进行了扩展,提出了以下想法:
- 确定何时应停止或继续选择-推理循环
- 增加一个价值函数,以帮助在多条推理路径中进行搜索
- 通过微调模型,使其基于句子标签(如sen1)进行推理,而不是直接写出句子,从而减少虚假事实的幻觉
方法
在原始的选择-推理技术中,专门的选择和推理提示交替使用,以选择事实并从这些事��实中进行推理,结合生成一系列推理步骤。
作者通过增加两个额外组件来扩展这一技术。
首先,作者增加了一个“终止器”模型,在每一步推理后,询问迄今为止的推理是否足以回答问题。如果是,则模型生成最终答案。
终止器模型带来了几个优势:
- 它可以根据需要指示选择-推理过程停止或继续。
- 如果过程永不终止,你将得不到答案,这通常比幻觉猜测更可取
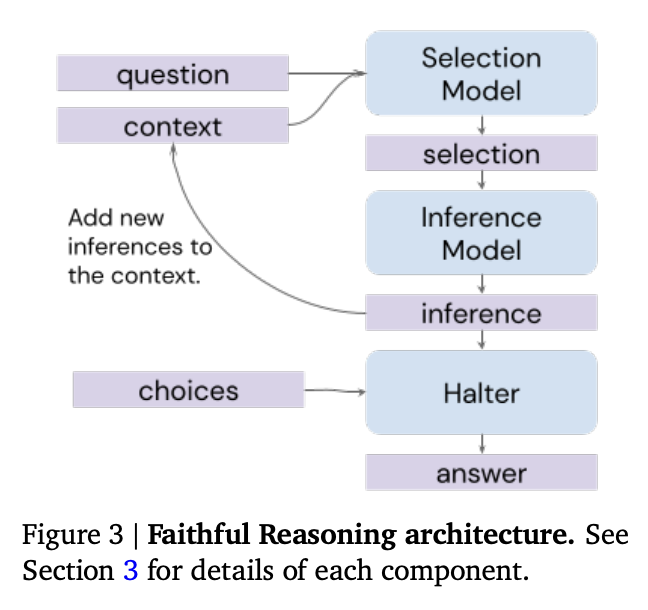 来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
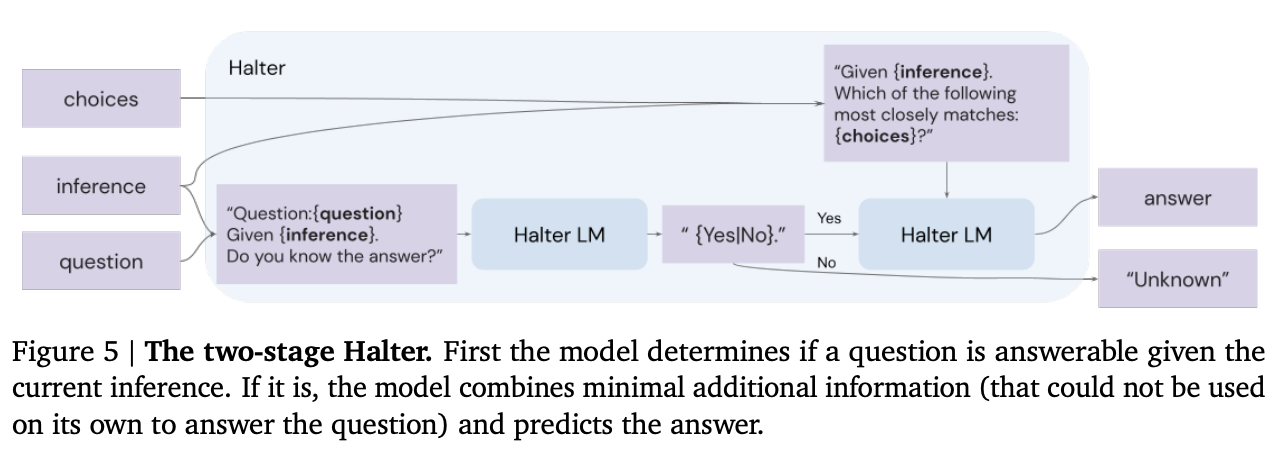 来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
其次,作者增加了一个价值函数,用于评估推理步骤的质量并在多条推理轨迹中进行搜索。这呼应了一个提高可靠性的常见主题;与其从模型中生成单一答案,不如生成一组答案,然后使用某种类型的价值函数/判别器/验证器模型来选择最佳答案。
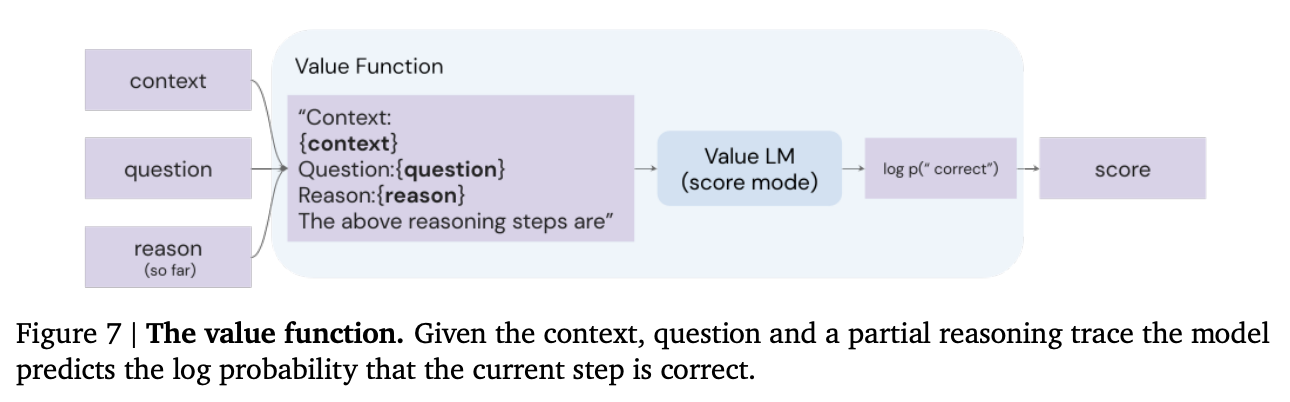 来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
除了这两个扩展外,作者还使用了一�个技巧来减少虚假事实的幻觉。他们不是让模型写出事实句子,而是微调模型以处理句子标签(如sen1)。这有助于防止模型在提示上下文中幻觉出未提及的虚假事实。
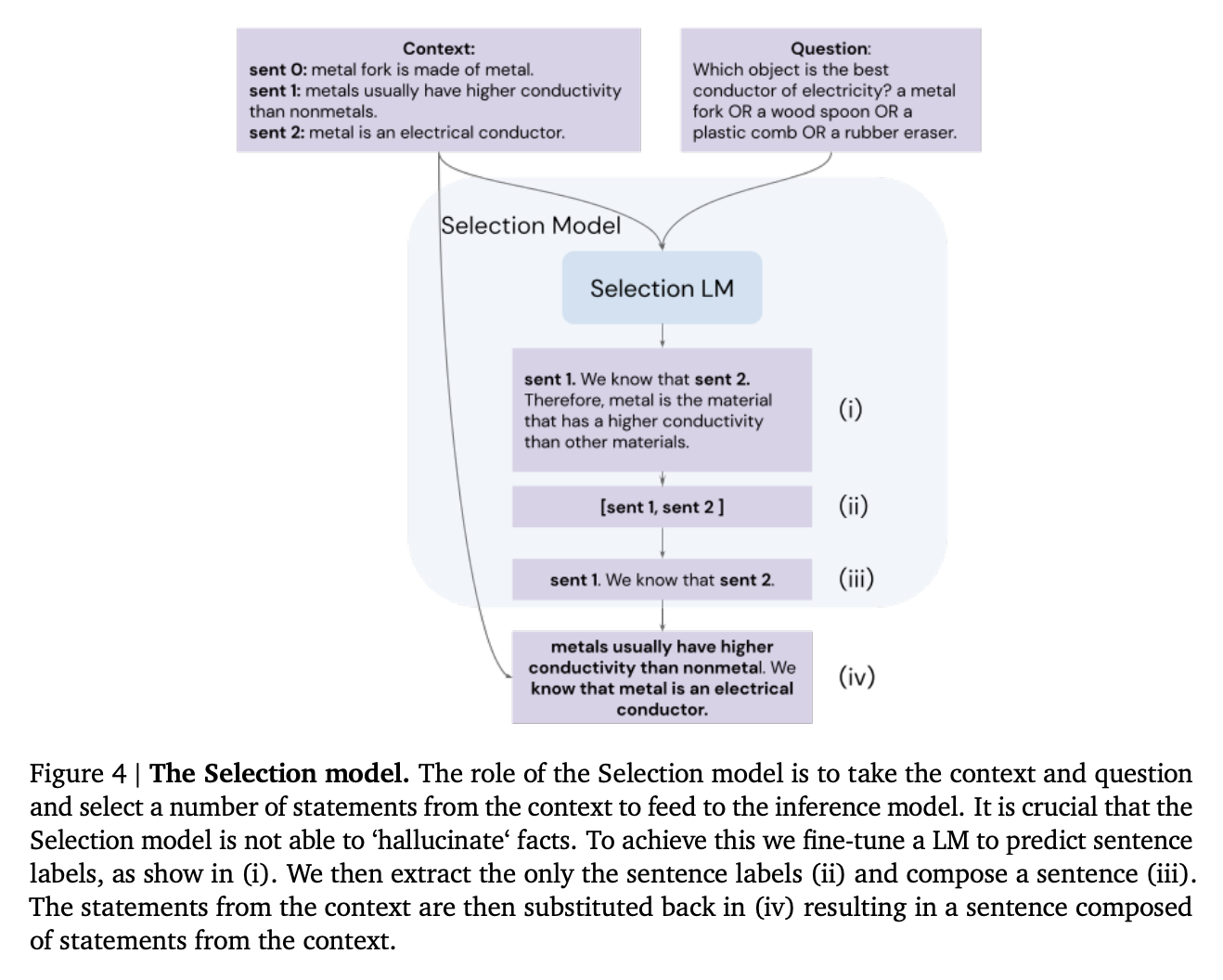 来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
来源:Antonia Creswell等人(2022年)的《利用大型语言模型进行忠实推理》
结果
作者们在两个基准任务上评估了他们的技术:ProofWriter 任务(未展示)和 EntailmentBankQA(展示)。这项技术显著提高了准确性,尤其是在更复杂的推理问题上。
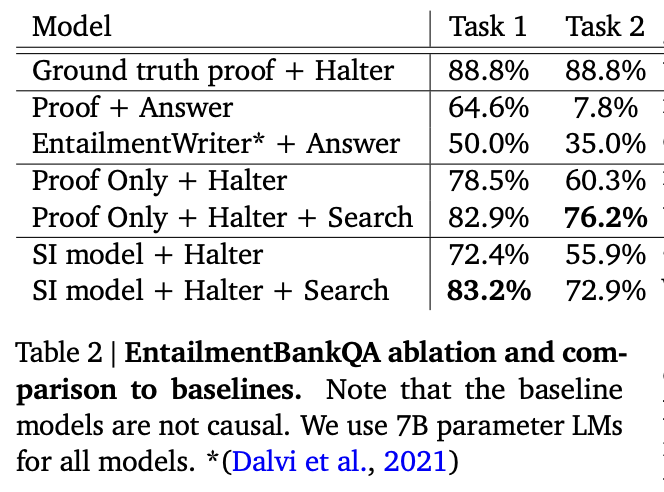 来源:使用大型语言模型进行忠实推理 作者 Antonia Creswell 等人(2022)](https://arxiv.org/abs/2208.14271)
来源:使用大型语言模型进行忠实推理 作者 Antonia Creswell 等人(2022)](https://arxiv.org/abs/2208.14271)
此外,他们的句子标签操纵技巧基本上消除了幻觉现象!
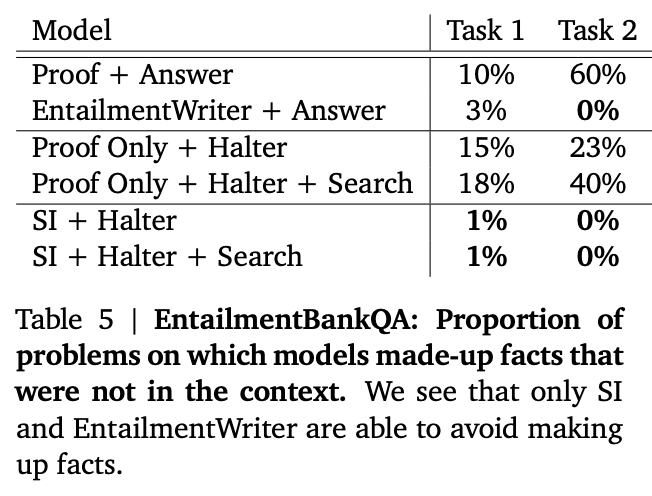 来源:使用大型语言模型进行忠实推理 作者 Antonia Creswell 等人(2022)](https://arxiv.org/abs/2208.14271)
来源:使用大型语言模型进行忠实推理 作者 Antonia Creswell 等人(2022)](https://arxiv.org/abs/2208.14271)
启示
这篇论文展示了许多有助于提高大型语言模型可靠性的有益教训:
- 将复杂任务分解为更小、更可靠的子任务
- 以逐步的方式生成答案,并在过程中进行评估
- 生成多个可能的答案,并使用另一个模型或函数来挑选看起来最好的答案
- 通过限制模型能说什么(例如,使用句子标签而不是句子)来减少幻觉
- 通过在专业任务上微调模型来最大化模型性能
了解更多,请阅读完整论文。
从易到难提示法
除了在长推理链上表现不佳(选择-推理在此处表现出色),思维链提示法在示例简短但任务冗长时尤其困难。
方法
从易到难提示法是另一种将推理任务分解为更小、更可靠子任务的技术。其思路是通过提示模型类似于 要解决 {问题},我们需要首先解决:“ 的内容来引发一个子任务。然后,利用这个子任务,模型可以生成一个解决方案。该解决方案被附加到原始问题中,并重复此过程,直到产生最终答案。
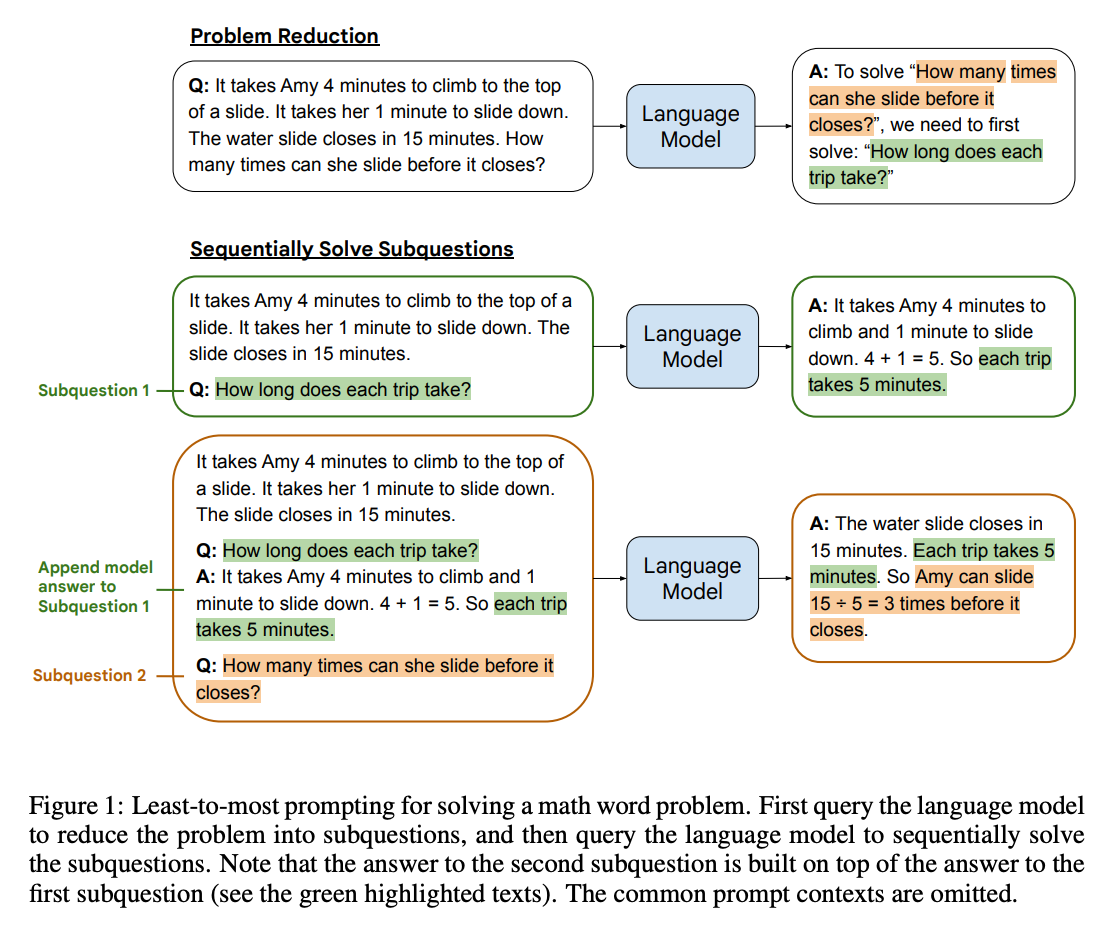 来源:从易到难提示法使大型语言模型实现复杂推理 作者 Denny Zhou 等人(2022)
来源:从易到难提示法使大型语言模型实现复杂推理 作者 Denny Zhou 等人(2022)
结果
当应用于涉及长推理链的基准测试时,使用 code-davinci-002(针对代码优化但仍能理解文本),作者们测得高达 16% -> 99.7% 的增益!
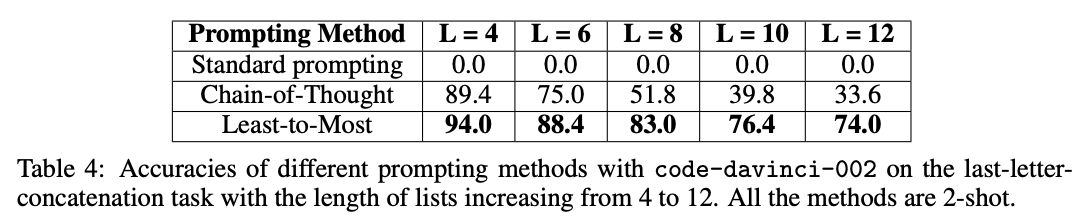

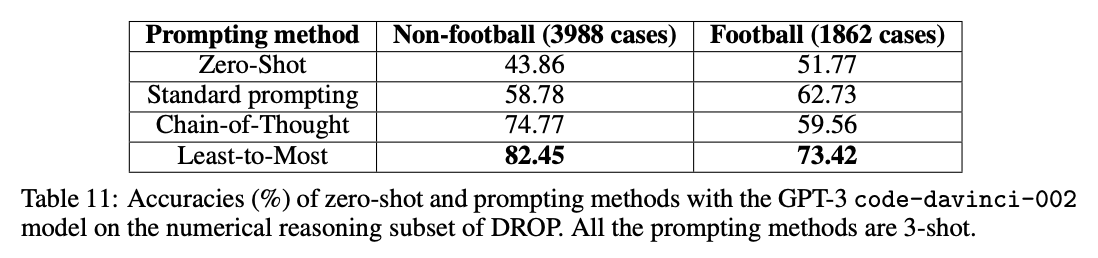 来源:从易到难提示法使大型语言模型实现复杂推理 作者 Denny Zhou 等人(2022)
来源:从易到难提示法使大型语言模型实现复杂推理 作者 Denny Zhou 等人(2022)
启示
尽管从易到难提示法带来的上述增益令人印象深刻,但它们是在需要长推理链的非常狭窄的任务集上测量的。
尽管如此,它们展示了一个共同主题:通过(a)将复杂任务分解为更小的子任务和(b)给模型更多时间和空间来推导答案,从而提高可靠性。
了解更多,请阅读完整论文。
相关想法
助产式提示法
方法
与前述试图最大化正确答案可能性的技术相反,另一种方法是使用 GPT-3 生成一系列可能的解释(包括正确和错误的),然后分析它们之间的关系来猜测哪一组是正确的。这一技术由 Jaehun Jung 等人在 2022 年 5 月 提出,称为助产式提示法(maieutic prompting)(maieutic 与苏格拉底式提问法相关,即通过提问引出想法)。
该方法较为复杂,具体如下:
- 首先,构建一个助产树,其中每个节点都是一个可能为真或假的陈述:
- 从一个多选题或真/假陈述开始(例如
战争不能有平局) - 对于问题的每个可能答案,使用模型生成相应的解释(例如
战争不能有平局?真的,因为) - 然后,用问题和生成的解释提示模型,并要求它给出答案。如果反转解释(例如
说 {解释} 是错误的)反转了答案,则该解释被认为是“逻辑上完整的”。 - 如果一个解释不是逻辑上完整的,则递归地重复上述过程,将每个解释转化为一个真或假的问题,并为每个新问题生成更多解释。
- 在所有递归解释完成后,你最终会得到一个解释树,其中每个叶子节点都具有反转解释会反转模型答案的属性。
- 从一个多选题或真/假陈述开始(例如
- 其次,将树转换为关系图:
- 对于树中的每个节点,计算模型对每个节点的相对信念(从给定解释得到
True答案的概率推断)- 对于树中的每对节点,利用模型判断它们是否存在蕴含(暗示)或矛盾关系
- 第三步,找出最一致的信念集合,并将其视为真实:
- 具体来说,利用每个节点的信念强度及其之间的逻辑关系,将问题形式化为加权最大可满足性问题(MAX-SAT)
- 使用求解器找到最自洽的信念集合,并将其视为真实
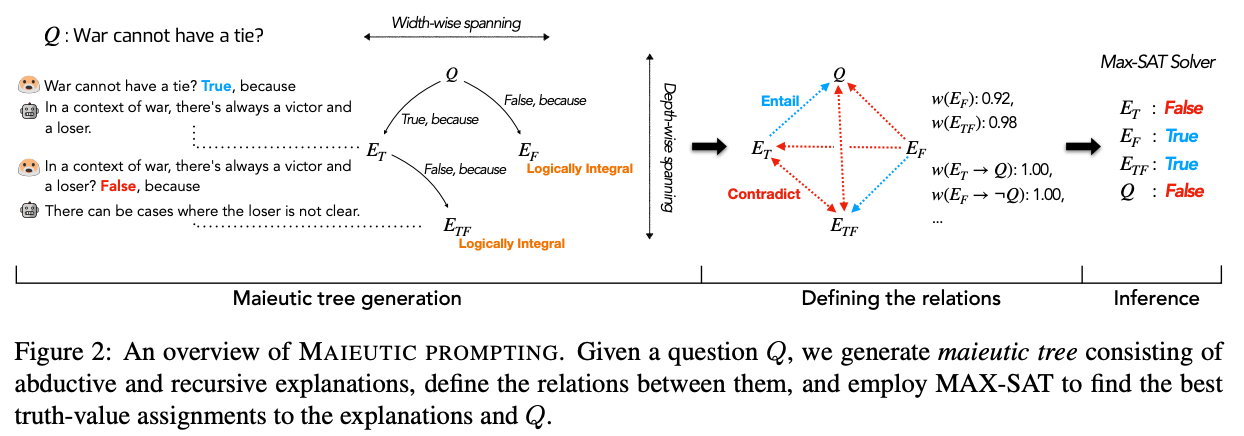
 来源:Jaehun Jung 等人的论文《Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations》(2022)
来源:Jaehun Jung 等人的论文《Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations》(2022)结果
 来源:Jaehun Jung 等人的论文《Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations》(2022)
来源:Jaehun Jung 等人的论文《Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations》(2022)影响
除了复杂性之外,这种方法的一个局限性在于它似乎仅适用于可以作为多项选择题提出的问题。
了解更多,请阅读完整论文。
扩展
自洽性
方法
对于具有离散答案集的任务,提高可靠性的一个简单方法是利用模型(使用正温度)采样多个解释和答案,然后选择出现频率最高的最终答案。
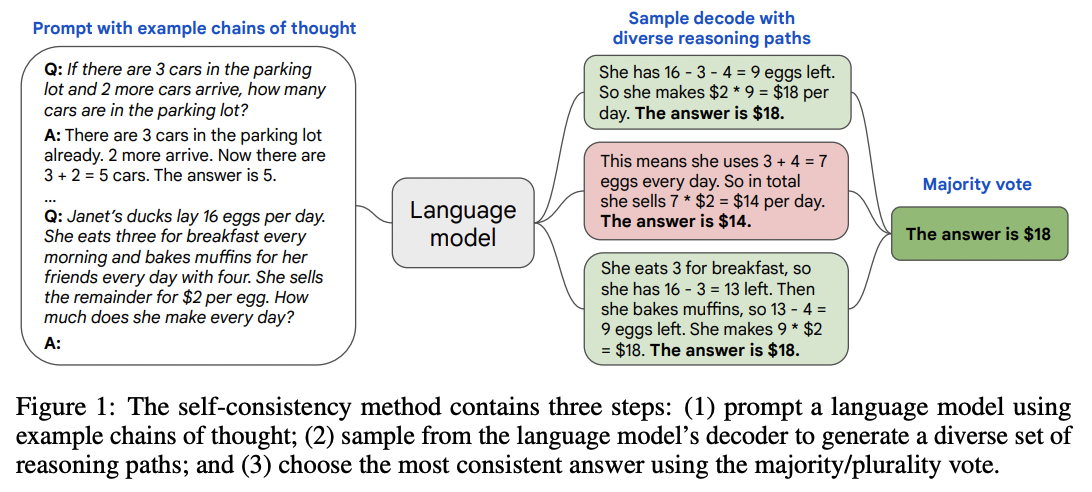 来源:Xuezhi Wang 等人的论文《Self-Consistency Improves Chain of Thought Reasoning in Language Models》(2022)
来源:Xuezhi Wang 等人的论文《Self-Consistency Improves Chain of Thought Reasoning in Language Models》(2022)
结果
这项技术在数学和推理基准测试中将准确率提高了 1 到 24 个百分点。(下图显示了 Google 的 LaMDA 模型的结果;使用 Google 更大的 PaLM 模型,基线更高,但增益略小。)
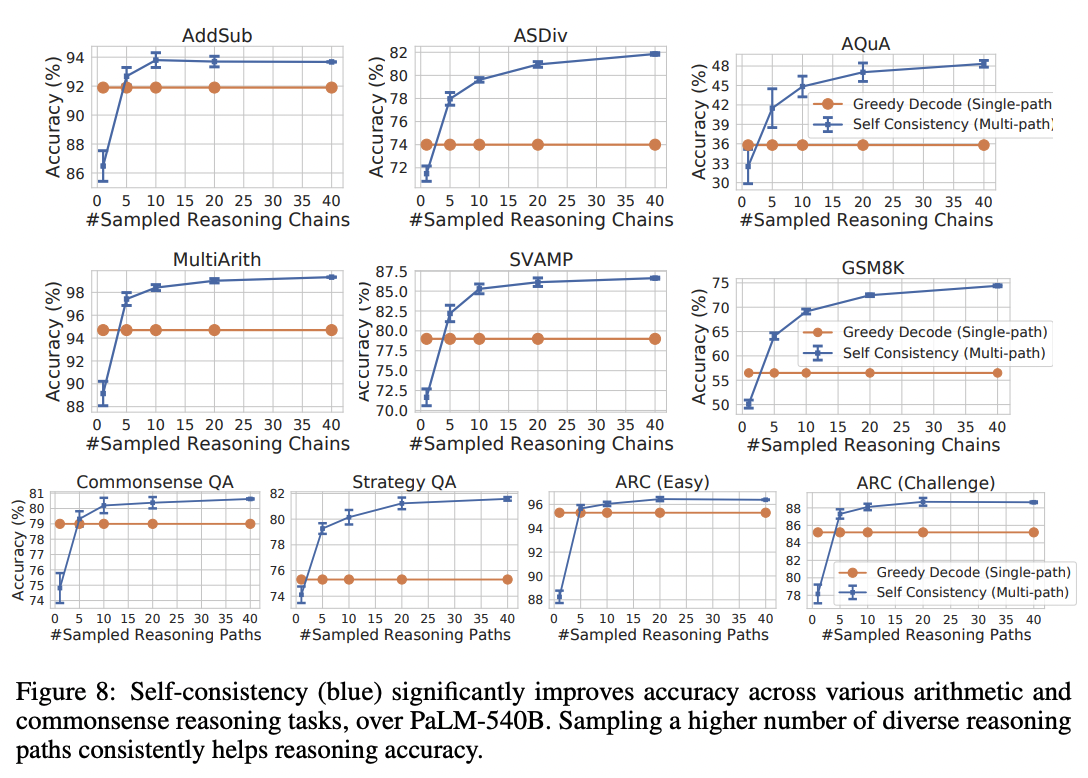 来源:Xuezhi Wang 等人的论文《Self-Consistency Improves Chain of Thought Reasoning in Language Models》(2022)
来源:Xuezhi Wang 等人的论文《Self-Consistency Improves Chain of Thought Reasoning in Language Models》(2022)
影响
尽管这项技术易于实施,但成本可能较高。生成一组 10 个答案将使成本增加 10 倍。
此外,与许多此类技术一样,它仅适用于具有有限答案集的任务。对于每个答案都独一无二的开放式任务(如写诗),选择最常见的答案并不明确。
最后,这项技术在有多种路径或表述方式达到答案时最为有益;如果只有一条路径,那么这项技术可能毫无帮助。一个极端例子:如果任务是生成单个令牌答案,那么从 100 次生成中选择最常见的令牌与在温度=0 时选择具有最高对数概率的令牌并无区别。
验证器
提高任务表现的另一个关键技术是训练一个验证器或判别模型,用于评估主要生成模型的输出。如果判别模型拒绝输出,则可以重新采样生成模型,直到获得可接受的输出。在很多情况下,判断一个答案比创造一个答案更容易,这解释了这种方法的强大之处。
方法
2021 年,OpenAI 的研究人员将此技术应用于小学数学问题,采用以下步骤:
- 首先,他们在问题和解答上对模型进行微调
- 对于训练集中的每个问题,他们生成了 100 个解答
- 根据最终答案是否正确,自动将这 100 个解答标记为正确或错误
- 利用这些解答(部分标记为正确,部分标记为错误),他们对一个验证器模型进行微调,以判断问题和候选解答是否正确
- 最后,在测试时,生成模型为每个问题创建 100 个解答,并根据验证器模型得分最高的解答作为最终答案
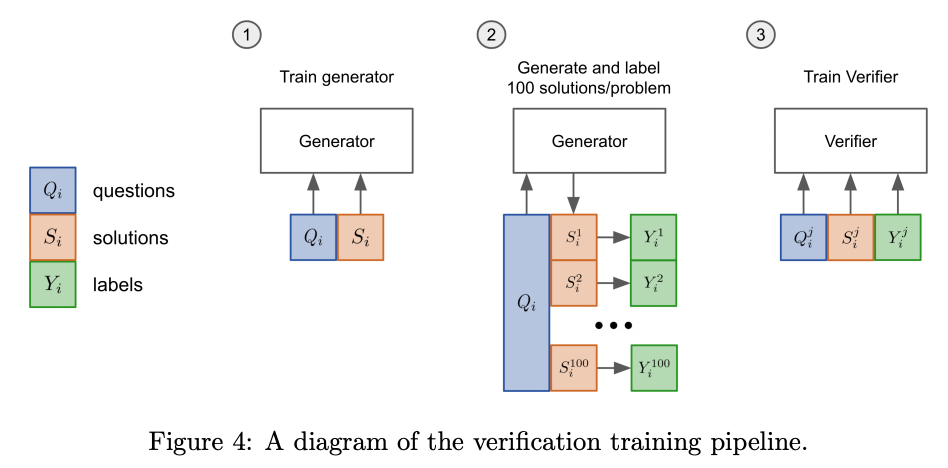 来源:Karl Cobbe 等人的论文《Training Verifiers to Solve Math Word Problems》(2021)
来源:Karl Cobbe 等人的论文《Training Verifiers to Solve Math Word Problems》(2021)
结果
使用 175B 的 GPT-3 模型和 8,000 个训练样本,这项技术将小学数学准确率从约 33% 大幅提升至约 55%。
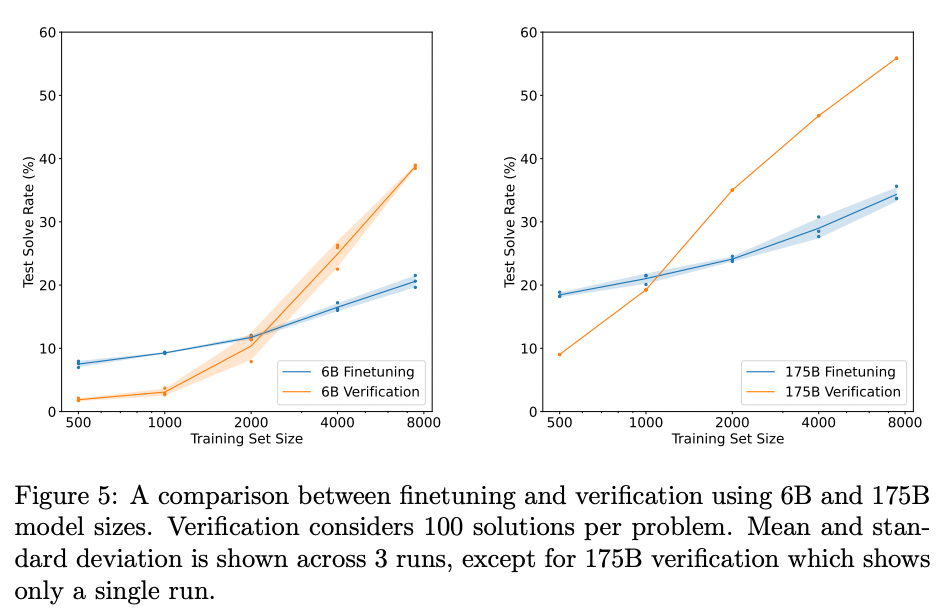 来源:Karl Cobbe 等人的论文《Training Verifiers to Solve Math Word Problems》(2021)
来源:Karl Cobbe 等人的论文《Training Verifiers to Solve Math Word Problems》(2021)
影响
与自洽技术类似,这种方法可能会变得昂贵,因为为每个任务生成例如100个解决方案将使成本增加大约~100倍。
可靠性理论
尽管上述技术在方法上各异,但它们都有一个共同的目标:提高在复杂任务上的可靠性。主要通过以下方式实现:
- 将不可靠的操作分解为更小、更可靠的操作(例如,选择-推理提示)
- 使用多个步骤或多个关系,使系统的可靠性超过任何单一组件(例如,助产式提示)
概率图模型
这种试图通过不太可靠的组件构建可靠系统的范式,让人联想到概率编程,该领域的许多分析技术都可以应用于此。
在论文《语言模型级联》中,David Dohan等人将上述技��术解释为概率图模型范式:
思维链提示
 来源:David Dohan等人的《语言模型级联》(2022)
来源:David Dohan等人的《语言模型级联》(2022)
微调思维链提示 / 自学推理者
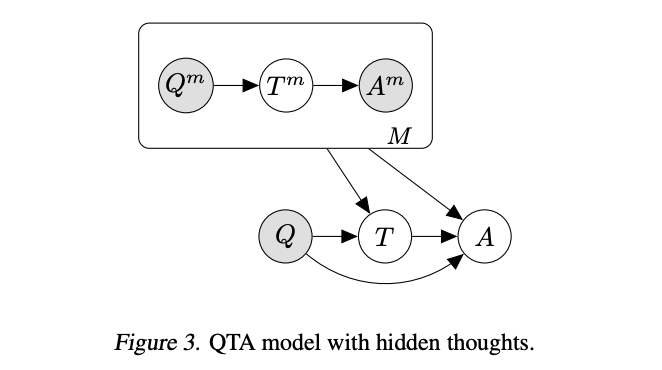 来源:David Dohan等人的《语言模型级联》(2022)
来源:David Dohan等人的《语言模型级联》(2022)
选择-推理提示
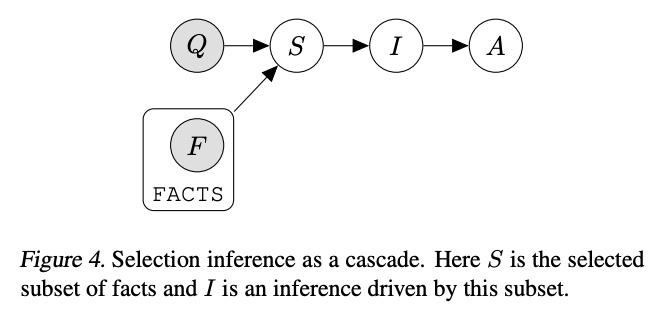 来源:David Dohan等人的《语言�模型级联》(2022)
来源:David Dohan等人的《语言�模型级联》(2022)
验证器
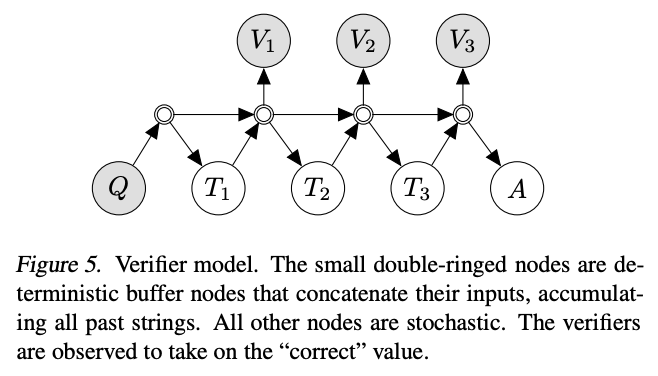 来源:David Dohan等人的《语言模型级联》(2022)
来源:David Dohan等人的《语言模型级联》(2022)
影响
尽管将这些技术形式化为概率图模型可能不会立即对解决任何特定问题有用,但该框架可能在选择、组合和发现新技巧方面有所帮助。
结束思考
大型语言模型的研究非常活跃且发展迅速。研究人员不仅继续改进模型,还继续提高我们对如何最好地使用这些模型的理解。为了强调这些发展的速度,请注意,上述所有论文都是在过去12个月内发表的(我在2022年9月写作时)。
未来,预计会有更好的模型和更好的技术被发表。即使这里提到的具体技术被未来的最佳实践所超越,它们背后的普遍原则很可能仍然是任何专家用户工具包的关键部分。
参考文献
| 课程 | 论文 | 日期 |
|---|---|---|
| 将复杂任务分解为更简单的子任务(并考虑向用户展示中间输出) | AI链:通过链接大型语言模型提示实现透明和可控的人机交互 | 2021年10月 |
| 通过生成多个候选方案,然后选择看起来最好的一个,可以提高输出质量 | 训练验证器解决数学应用题 | 2021年10月 |
| 在推理任务中,模型在回答前进行逐步推理会表现得更好 | 思维链提示在大规模语言模型中引发推理 | 2022年1月 |
| 通过生成多个解释-答案输出,并选择最受欢迎的答案,可以提高逐步推理的质量 | 自洽性改善语言模型中的思维链推理 | 2022年3月 |
| 如果你想微调一个逐步推理者,你可以仅使用多项选择题和答案数据来完成 | STaR:通过推理引导推理 | 2022年3月 |
| 即使在没有示例的情况下,逐步推理方法也能表现出色 | 大型语言模型是零样本推理者 | 2022年5月 |
| 通过交替使用‘选择’提示和‘推理’提示,你可以超越单纯的逐步推理 | 选择-推理:利用大型语言模型进行可解释的逻辑推理 | 2022年5月 |
| 在处理长推理问题时,通过将问题分解为小块并逐步解决,可以改进逐步推理方法 | 最少到最多提示法使大型语言模型实现复杂推理 | 2022年5月 |
| 可以让模型分析好的和虚假的解释,以确定哪一组解释最为一致 | 启发式提示法:利用递归解释实现逻辑一致的推理 | 2022年5月 |
| 可以将这些技术视为概率编程,其中系统由不可靠的组件构成 | 语言模型级联 | 2022年7月 |
| 通过句子标签操纵可以消除幻觉,通过使用‘终止’提示可以减少错误答案 | 利用大型语言模型进行可靠推理 | 2022年8月 |