为 RAG 生成合成数据集
RAG 设置的合成数据
在机器学习工程师的生活中,往往存在标记数据不足或非常有限的问题。通常情况下,一旦意识到这一点,项目就会开始漫长的数据收集和标记过程。只有经过几个月的时间,才能开始开发解决方案。
然而,随着大型语言模型(LLM)的出现,一些产品的范式发生了变化:现在可以依赖于LLM的泛化能力,几乎立即测试一个想法或开发一个基于人工智能的功能。如果结果(几乎)符合预期,那么传统的开发流程就可以开始了。

RAG(检索增强生成) 是一种新兴方法之一。它用于知识密集型任务,其中不能仅依赖于模型的知识。RAG将信息检索组件与文本生成模型相结合。要了解更多关于这种方法的信息,请参考指南中相关章节。
RAG的关键组件是一个检索模型,它识别相关文档并将其传递给LLM进行进一步处理。检索模型的性能越好,产品或功能的结果就越好。理想情况下,检索应该立即起效。然而,其性能在不同语言或特定领域中往往会下降。
想象一下:您需要创建一个基于捷克法律和法律实践回答问题的聊天机器人(当然是用捷克语)。或者设计一个针对印度市场量身定制的税务助手(这是OpenAI在GPT-4演示中提出的一个用例)。您可能会发现,检索模型经常会错过最相关的文档,并且整体表现不佳,从而限制了系统的质量。
但是有一个解决方案。一种新兴的趋势涉及使用现有的LLM合成数据,用于训练新一代的LLM/检索器/其他模型。这个过程可以被视为通过基于提示的查询生成将LLM提炼成标准大小的编码器。虽然提炼过程计算密集,但它大大降低了推理成本,可能会极大地提高性能,特别是在资源稀缺的语言或专业领域。
在本指南中,我们将依赖于最新的文本生成模型,如ChatGPT和GPT-4,它们可以根据指示生成大量合成内容。Dai等人(2022)提出了一种方法,仅通过8个手动标记的示例和大量未标记数据(用于检索的文档,例如所有解析的法律),就可以实现接近最新技术水平的性能。这项研究证实,合成生成的数据有助于训练特定任务的检索器,特别是在由于数据稀缺而使得领域内监督微调成为挑战的任务中。
领域特定数据集生成
要利用LLM,需要提供简短描述并手动标记一些示例。重要的是要注意,不同的检索任务具有不同的搜索意图,这意味着“相关性”的不同定义。换句话说,对于相同的(查询,文档)对,基于搜索意图,它们的相关性可能完全不同。例如,一个论证检索任务可能寻求支持性论点,而其他任务则需要反对性论点(如ArguAna数据集中所见)。
考虑下面的例子。尽管以英文撰写以便更容易理解,但请记住,数据可以是任何语言,因为ChatGPT/GPT-4可以高效处理甚至是资源稀缺的语言。
提示:
任务:找出给定论点的反驳观点。
论点 #1:{插入段落 X1}
与论点 #1 相关的简明反驳观点查询:{手动准备的查询 Y1}
论点 #2:{插入段落 X2}
与论点 #2 相关的简明反驳观点查询:{手动准备的查询 Y2}
<- 在这里粘贴你的例子 ->
论点 N:即使罚款与收入成比例,也无法达到你所期望的影响平等。这是因为影响并不仅仅与收入成比例,而必须考虑许多其他因素。例如,有家庭负担的人将面临比没有家庭负担的人更大的影响,因为他们的可支配收入较少。此外,基于收入的罚款忽略了整体财富(即某人实际拥有多少钱:某人可能拥有大量资产,但收入并不高)。这一提议未考虑这些不平等因素,而这些因素可能产生更大的扭曲效应,因此该论点应用不一致。
与论点 #N 相关的简明反驳观点查询:
输出:
惩罚措施将使罚款与收入挂钩
一般来说,这样的提示可以表示为:
,其中 和分别是特定任务的文档和查询描述,是ChatGPT/GPT-4的特定任务提示/指令,是一个新文档,LLM将为其生成一个查询。
整个流程概述:
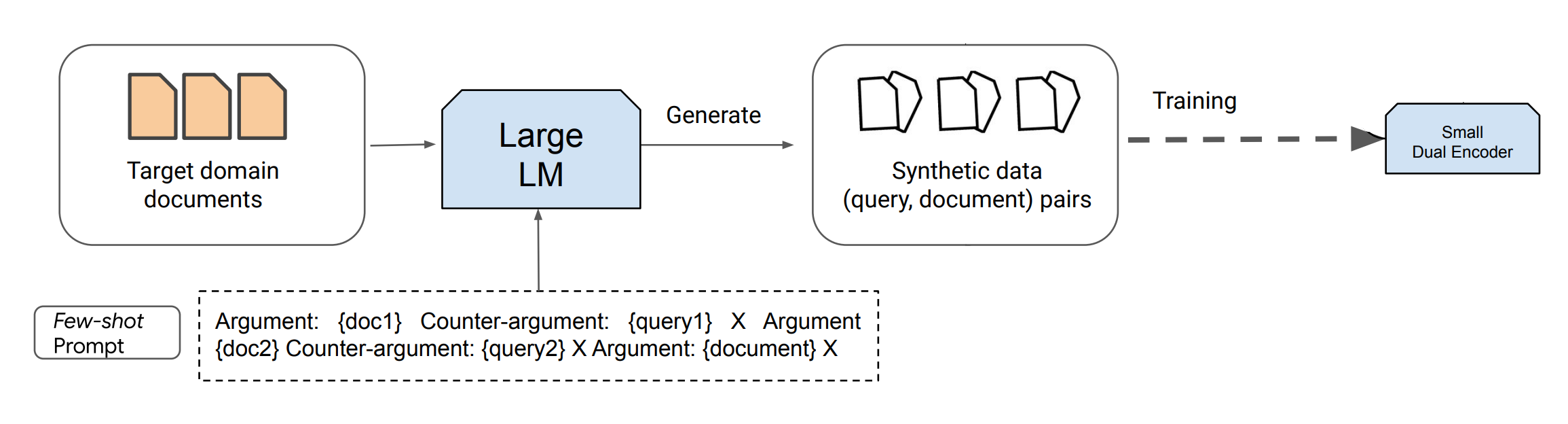
图片来源:Dai et al. (2022)
负责处理示例的手动注释非常重要。最好准备更多示例(例如20个),然后随机选择其中的2-8个添加到提示中。这样做可以增加生成数据的多样性,而在注释方面的时间成本并不会显著增加。然而,这些示例应该具有代表性,格式正确,甚至详细说明目标查询的长度或语气。示例和说明越精确,用于训练Retriever的合成数据质量就越好。低质量的少样本示例可能会对训练模型的质量产生负面影响。
在大多数情况下,使用像ChatGPT这样的更经济的模型就足够了,因为它在非英语领域和其他语言中表现良好。比如,带有说明和4-5个示例的提示通常占用700个标记(假设每个段落由于Retriever的限制不超过128个标记),生成的查询占用25个标记。因此,为了对本地模型进行微调,为一个包含50,000个文档的语料库生成合成数据的成本为:50,000 * (700 * 0.001 * $0.0015 + 25 * 0.001 * $0.002) = 55,其中$0.0015和$0.002是GPT-3.5 Turbo API每1,000个标记的成本。甚至可以为同一文档生成2-4个查询示例。然而,通常进一步训练的好处是值得的,特别是如果你使用Retriever不是用于一般领域(比如英语新闻检索),而是用于特定领域(比如捷克法律,如前所述)。
50,000这个数字并非随意。在Dai et al. (2022)的研究中指出,这大约是模型达到与在合成数据上训练的模型质量相匹配所需的手动标记数据数量。想象一下,要在推出产品之前收集至少10,000个示例!这将至少需要一个月的时间,而且劳动成本肯定会超过一千美元,远远超过生成合成数据和训练本地Retriever模型的成本。现在,有了今天学到的技术,你可以在短短几天内实现两位数的指标增长!
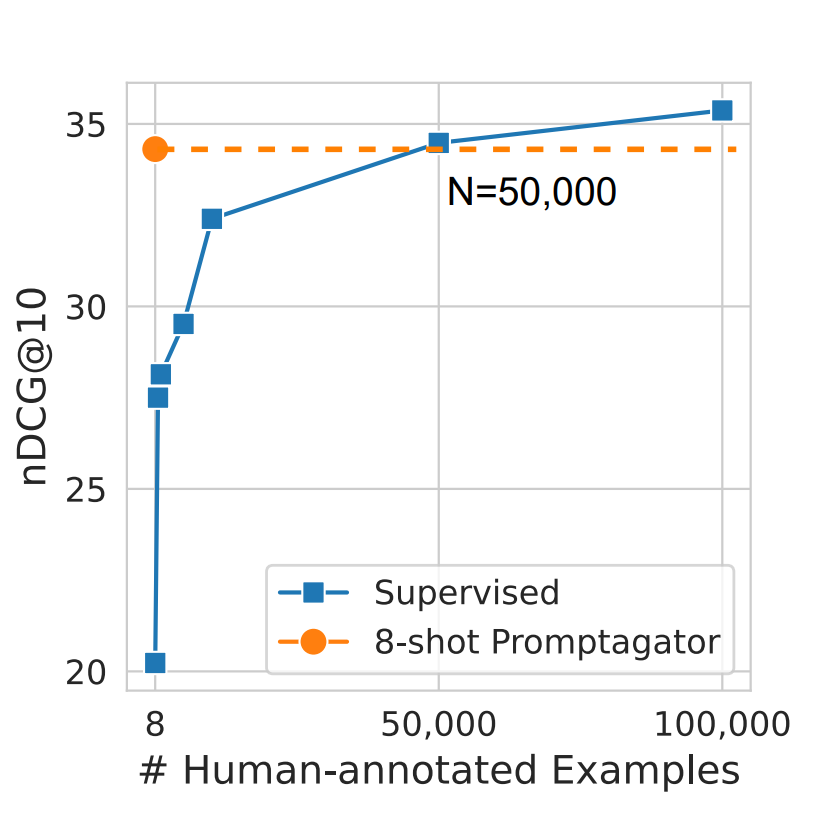
图片来源:Dai et al. (2022)
以下是来自同一篇论文的一些BeIR基准数据集的提示模板。

图片来源:Dai et al. (2022)