在 AWS Fargate 上部署机器学习流水线
在 AWS Fargate 上部署机器学习流水线
作者:Moez Ali

回顾
在我们上一篇关于在云端部署机器学习流水线的文章中,我们展示了如何使用 PyCaret 开发机器学习流水线,将其容器化为 Docker,并使用 Google Kubernetes Engine 将其作为 Web 应用程序提供。如果你之前没有听说过 PyCaret,请阅读这篇公告以了解更多信息。
在本教程中,我们将使用之前构建和部署的相同的机器学习流水线和 Flask 应用程序。这次我们将演示如何使用 AWS Fargate 将机器学习流水线容器化并部署为无服务器应用。
👉 本教程的学习目标
- 什么是容器?什么是 Docker?什么是 Kubernetes?
- 什么是亚马逊弹性容器服务(ECS)?
- 什么是 AWS Fargate 和无服务器部署?
- 构建并推送 Docker 镜像到亚马逊弹性容器注册表。
- 使用 AWS 托管的基础设施(即 AWS Fargate)创建和执行任务定义。
- 查看一个使用训练好的机器学习流水线实时预测新数据点的 Web 应用程序。
本教程将涵盖从本地构建 Docker 镜像、上传到亚马逊弹性容器注册表、创建集群,然后使用 AWS 托管的基础设施(即 AWS Fargate)定义和执行任务的整个工作流程。
在过去,我们已经介绍了在其他云平台上的部署,比如 Azure 和 Google。如果你对这些感兴趣,可以阅读以下文章:
💻 本教程的工具
PyCaret
PyCaret 是一个开源的、低代码的 Python 机器学习库,用于训练和部署机器学习流水线和模型到生产环境中。可以使用 pip 简单地安装 PyCaret。
pip install pycaret
Flask
Flask 是一个允许你构建 Web 应用程序的框架。Web 应用程序可以是商业网站、博客、电子商务系统,或者是一个使用训练好的模型实时提供数据预测的应用程序。如果你还没有安装 Flask,可以使用 pip 进行安装。
Windows 10 Home 的 Docker Toolbox
Docker 是一个旨在通过使用容器来更轻松地创建、部署和运行应用程序的工具。容器用于将应用程序及其所需的所有组件(如库和其他依赖项)打包成一个包,并将其作为一个整体进行传输。如果你之前没有使用过 Docker,本教程还涵盖了在 Windows 10 Home 上安装 Docker Toolbox(旧版)。在之前的教程中,我们介绍了如何在 Windows 10 Pro 版本上安装 Docker Desktop��。
亚马逊云服务(AWS)
亚马逊云服务(AWS)是由亚马逊提供的一个全面且广泛采用的云平台。它拥有超过 175 个功能齐全的服务,分布在全球各地的数据中心。如果你之前没有使用过 AWS,可以注册一个免费账户。
✔️ 让我们开始吧……
什么是容器?
在我们开始使用 AWS Fargate 进行实现之前,让我们先了解一下什么是容器以及为什么我们需要它?

你是否遇到过这样的问题:你的代码在你的电脑上运行正常,但是当你的朋友尝试运行完全相同的代码时,却无法正常工作?如果你的朋友重复了完全相同的步骤,他或她应该得到相同�的结果,对吗?这个问题的答案是——环境。你朋友的环境与你的环境不同。
环境包括什么?→ 编程语言,如 Python,以及使用该语言构建和测试应用程序时所使用的所有库和依赖项的确切版本。 如果我们能够创建一个可以转移到其他机器上的环境(例如:你朋友的电脑或者像谷歌云平台这样的云服务提供商),我们就可以在任何地方重现结果。因此,容器是一种软件类型,它将应用程序及其所有依赖项打包起来,以便应用程序可以在不同的计算环境中可靠地运行。
什么是Docker?
Docker是一家提供软件(也称为Docker)的公司,允许用户构建、运行和管理容器。虽然Docker的容器是最常见的,但还有其他不太出名的替代品,如LXD和LXC。

现在你理论上了解了容器是什么,以及Docker如何用于容器化应用程序,让我们想象一个场景:你需要在一群机器上运行多个容器,以支持一个企业级的机器学习应用程序,在白天和晚上有不同的工作负载。这在现实生活中非常常见,尽管听起来很简单,但手动完成这项工作是非常繁琐的。
你需要在正确的时间启动正确的容器,找出它们如何相互通信,处理存储考虑事项,处理失败的容器或硬件以及其他无数的事情!
管理数百甚至数千个容器以保持应用程序正常运行的整个过程被称为容器编排。现在不要陷入技术细节中。
此时,你必须认识到管理现实生活中的应用程序需要不止一个容器,并且管理所有基础设施以保持容器正常运行是繁琐、手动且具有行政负担的。
这就引出了Kubernetes。
什么是Kubernetes?
Kubernetes是由谷歌于2014年开发的用于管理容器化应用程序的开源系统。简单来说,Kubernetes是一个用于在机群中运行和协调容器化应用程序的系统。

虽然Kubernetes是由谷歌开发的开源系统,几乎所有主要的云服务提供商都提供Kubernetes作为托管服务。例如:由亚马逊提供的Amazon Elastic Kubernetes Service (EKS),由�谷歌提供的Google Kubernetes Engine (GKE),以及由微软提供的Azure Kubernetes Service (AKS)。
到目前为止,我们已经讨论和了解了:
✔️ 一个容器
✔️ Docker
✔️ Kubernetes
在介绍AWS Fargate之前,还有一件事要讨论,那就是亚马逊自己的容器编排服务Amazon Elastic Container Service (ECS)。
AWS Elastic Container Service (ECS)
Amazon Elastic Container Service (Amazon ECS)是亚马逊自主开发的容器编排平台。ECS的理念与Kubernetes类似(它们都是编排服务)。
ECS是一项AWS原生服务,意味着它只能在AWS基础设施上使用。另一方面,EKS基于Kubernetes,这是一个开源项目,可供在多云(AWS、GCP、Azure)甚至本地运行的用户使用。
亚马逊还提供了基于Kubernetes的容器编排服务,称为Amazon Elastic Kubernetes Service (Amazon EKS)。尽管ECS和EKS的目的非常相似,即编排容器化应用程序,但在定价、兼容性和安全性方面存在一些差异。没有最佳答案,解决方案的选择取决于具体的用例。
无论你使用的是ECS还是EKS这样的容器编排服务,你都可以通过以下两种方式实现底层基础设施:
- 手动管理集群和底层基础设施,如虚拟机/服务器(在AWS中也称为EC2实例)。
- 无服务器——完全不需要管理任何东西。只需上传容器即可。← 这就是AWS Fargate。
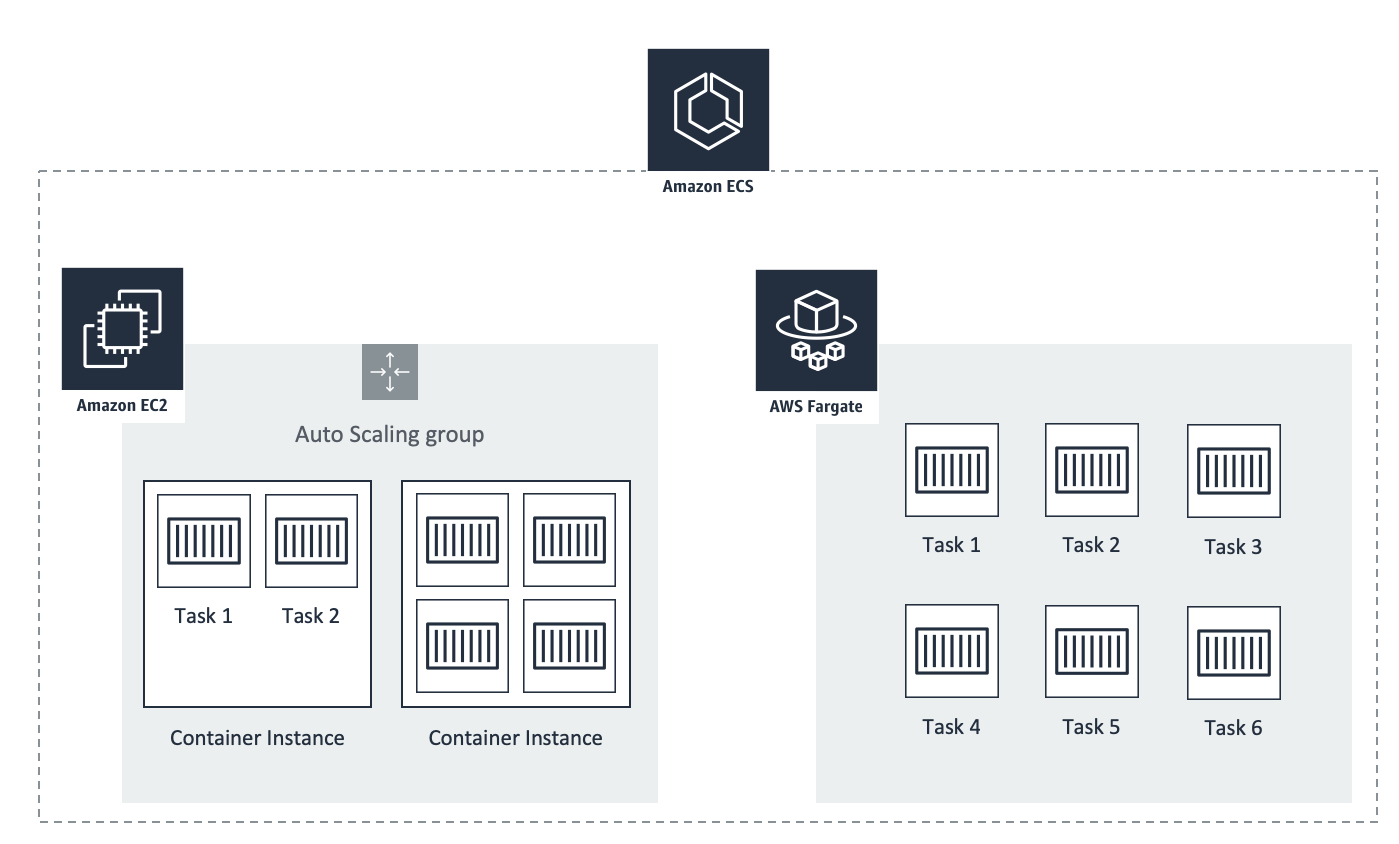
AWS Fargate — 无服务器容器计算
AWS Fargate是一种用于容器的无服务器计算引擎,可与Amazon Elastic Container Service (ECS)和Amazon Elastic Kubernetes Service (EKS)配合使用。Fargate使您可以专注于构建应用程序。Fargate消除了预配和管理服务器的需求,让您可以按应用程序指定和支付资源,并通过设计实现应用程序隔离来提高安全性。
Fargate分配适量的计算资源,无需选择实例和扩展集群容量。您只需支付运行容器所需的资源,因此不会出现过度预配和支付额外服务器的情况。
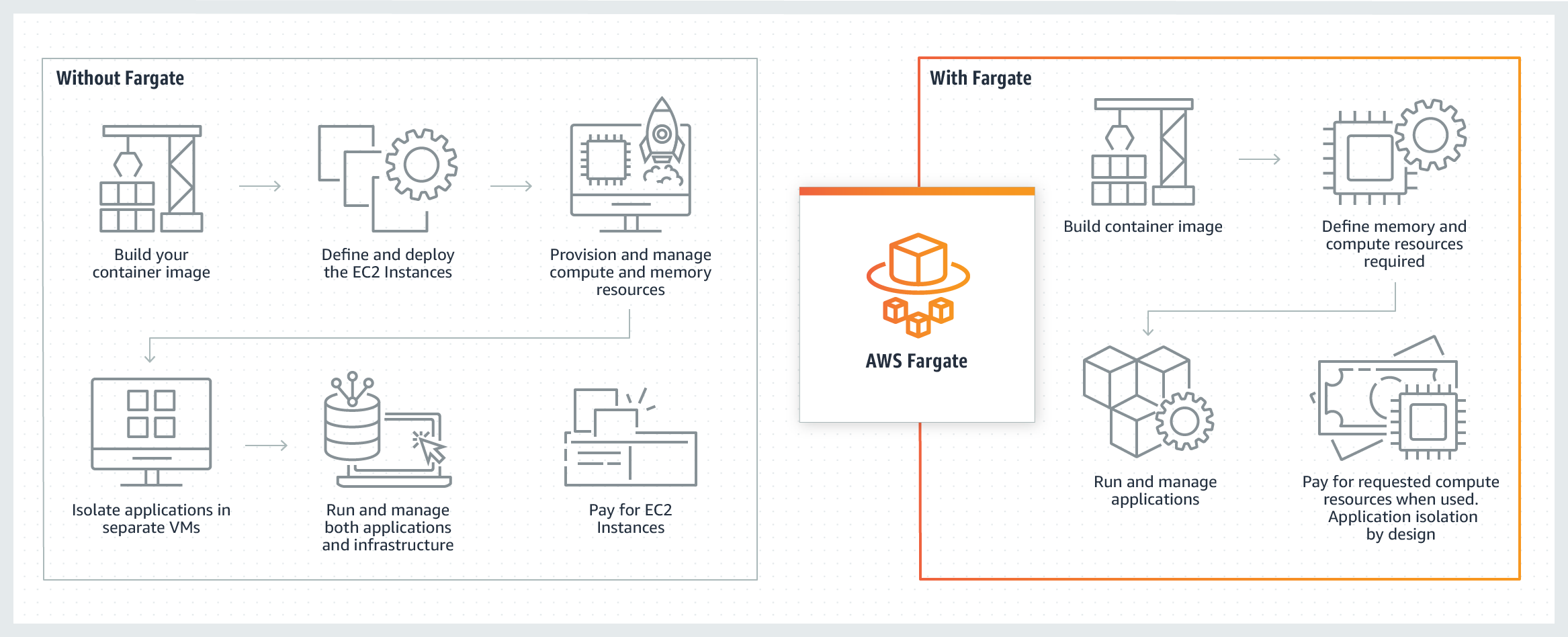
关于哪种方法更好并没有最佳答案。选择是无服务器还是手动管理 EC2 集群取决于具体情况。一些可帮助做出选择的要点包括:
ECS EC2(手动方法)
- 您完全依赖 AWS。
- 您有一个专门的运维团队来管理 AWS 资源。
- 您在 AWS 上已经有一定的存在,即您已经在管理 EC2 实例。
AWS Fargate
- 您没有庞大的运维团队来管理 AWS 资源。
- 您不想要运维责任或想要减少运维责�任。
- 您的应用是无状态的(无状态应用是指一个应用程序不保存在一个会话中生成的客户端数据,以便在下一个与该客户端的会话中使用)。
设定业务背景
一家保险公司希望通过在患者入院时使用人口统计数据和基本患者健康风险指标更好地预测患者费用,从而改善现金流预测。
(数据来源)
目标
构建并部署一个 Web 应用程序,用户可以在 Web 表单中输入患者的人口统计和健康信息,然后输出预测的费用金额。
任务
- 训练和开发一个用于部署的机器学习流水线。
- 使用 Flask 框架构建一个 Web 应用程序。它将使用训练好的机器学习流水线实时生成新数据点的预测。
- 构建并推送一个 Docker 镜像到 Amazon Elastic Container Registry。
- 创建并执行一个任务,使用 AWS Fargate 无服务器基础设施部署应用程序。
由于我们已经在最初的教程中涵盖了前两个任务,我们将快速回顾它们,然后专注于上述列表中的剩余项目。如果您有兴趣了解如何使用 PyCaret 在 Python 中开发机器学习流水线以及如何使用 Flask 框架构建 Web 应用程序,请阅读本教程。
👉 开发一个机器学习流水线
我们在 Python 中使用 PyCaret 进行训练和开发机器学习流水线,这将作为我们 Web 应用程序的一部分。机器学习流水线可以在集成开发环境(IDE)或笔记本中开发。我们已经使用笔记本运行了下面的代码:
当您在 PyCaret 中保存一个模型时,基于 **setup() **函数中定义的配置创建整个转换流水线。所有相互依赖关系都会自动协调。查看存储在 'deployment_28042020' 变量中的流水线和模型:

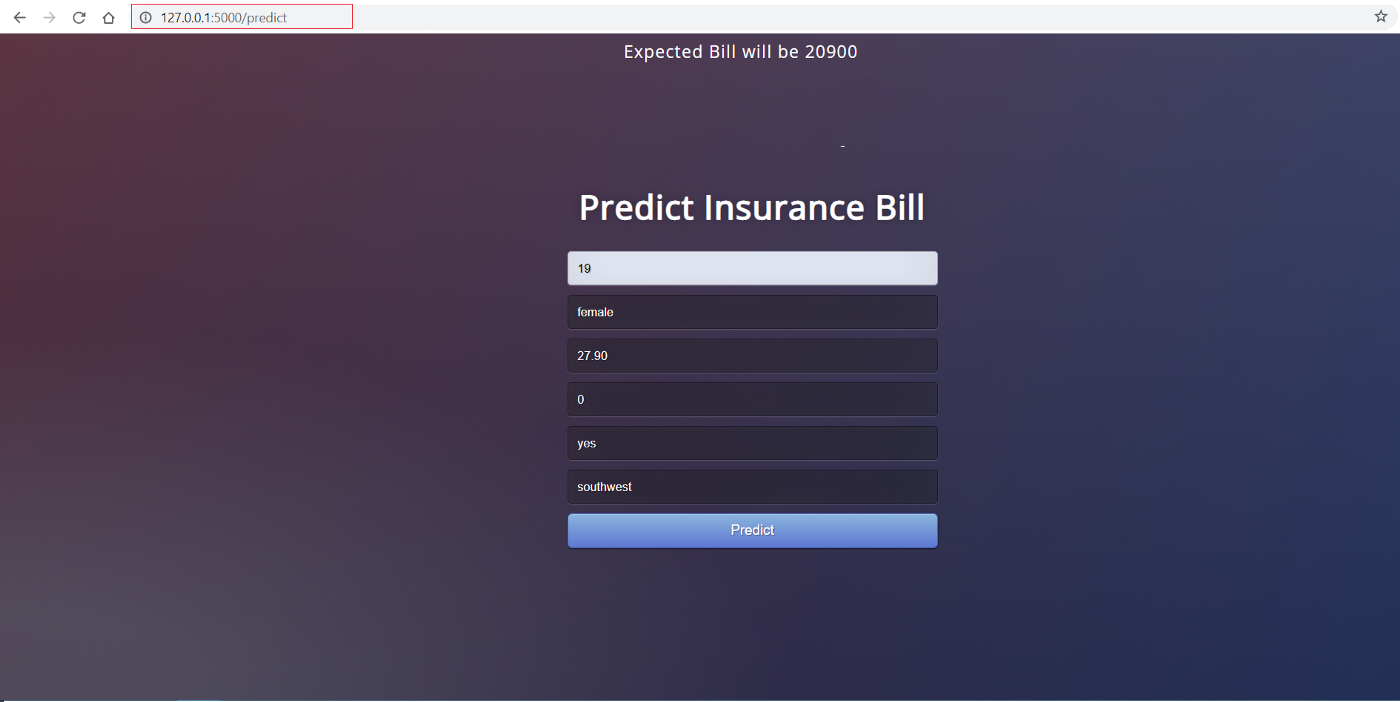
👉 构建一个 Web 应用程序
本教程不侧重于构建 Flask 应用程序。这里仅讨论了一下。现在我们的机器学习流水线已准备就绪,我们需要一个 Web 应用程序,它可以连接到我们训练好的流水线,以实时生成新数据点的预测。我们使用 Python 中的 Flask 框架创建了 Web 应用程序。该应用程序有两部分:
- 前端(使用 HTML 设计)
- 后端(使用 Flask 开发)
这是我们的 Web 应用程序外观:
如果您到目前为止还没有跟随,没问题。您可以简单地从 GitHub 上 fork 这个存储库。此时您的项目文件夹应该如下所示:
使用 AWS Fargate 部署 ML 流水线的 10 步骤:
👉 步骤 1 — 安装 Docker Toolbox(适用于 Windows 10 Home)
为了在本地构建 Docker 镜像,您需要在计算机上安装 Docker。如果您使用的是 Windows 10 64 位:Pro、Enterprise 或 Education(版本号 15063 或更高),您可以从DockerHub下载 Docker Desktop。
但是,如果您使用的是 Windows 10 Home,则需要从Docker 的 GitHub 页面安装最新版本的传统 Docker Toolbox(v19.03.1)。
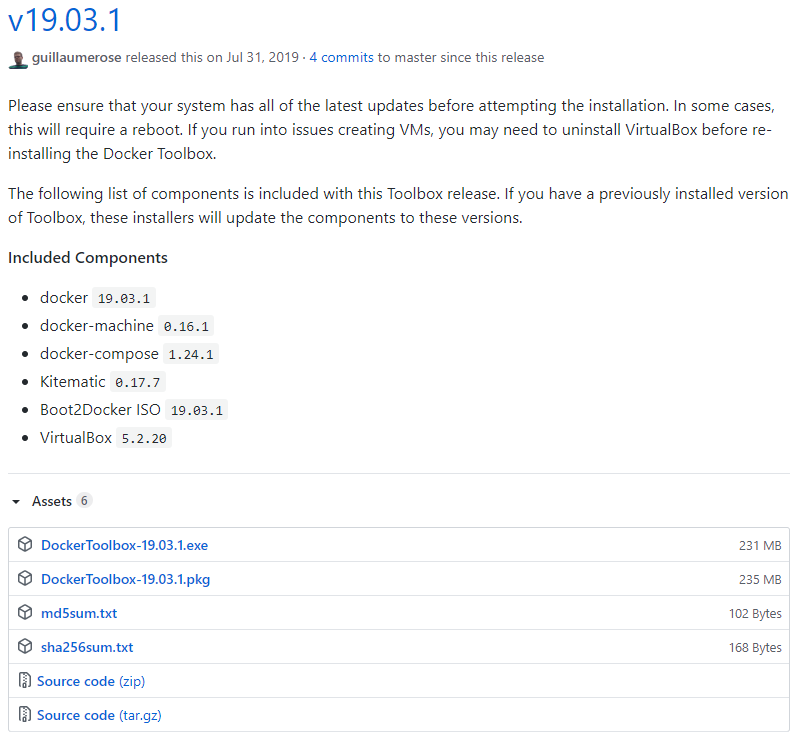
下载并运行 DockerToolbox-19.03.1.exe 文件。
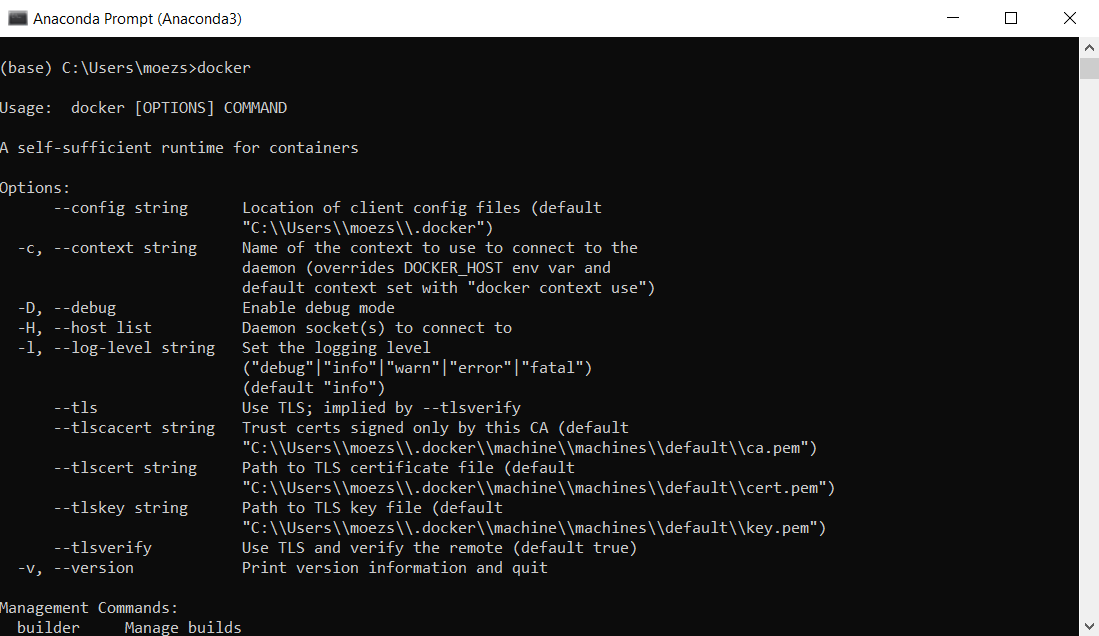
检查安装是否成功的最简单方法是打开命令提示符并键入 'docker'。它应该打印出帮助菜单。
👉 步骤 2 — 创建一个 Dockerfile
创建 Docker 镜像的第一步是在项目目录中创建一个 Dockerfile。Dockerfile 只是一个包含一系列指令的文件。本项目的 Dockerfile 如下所示:
Dockerfile 区分大小写,必须与其他项目文件一起位于项目文件夹中。Dockerfile 没有扩展名,可以使用任何文本编辑器创建。您可以从这个 GitHub 仓库 下载本项目使用的 Dockerfile。
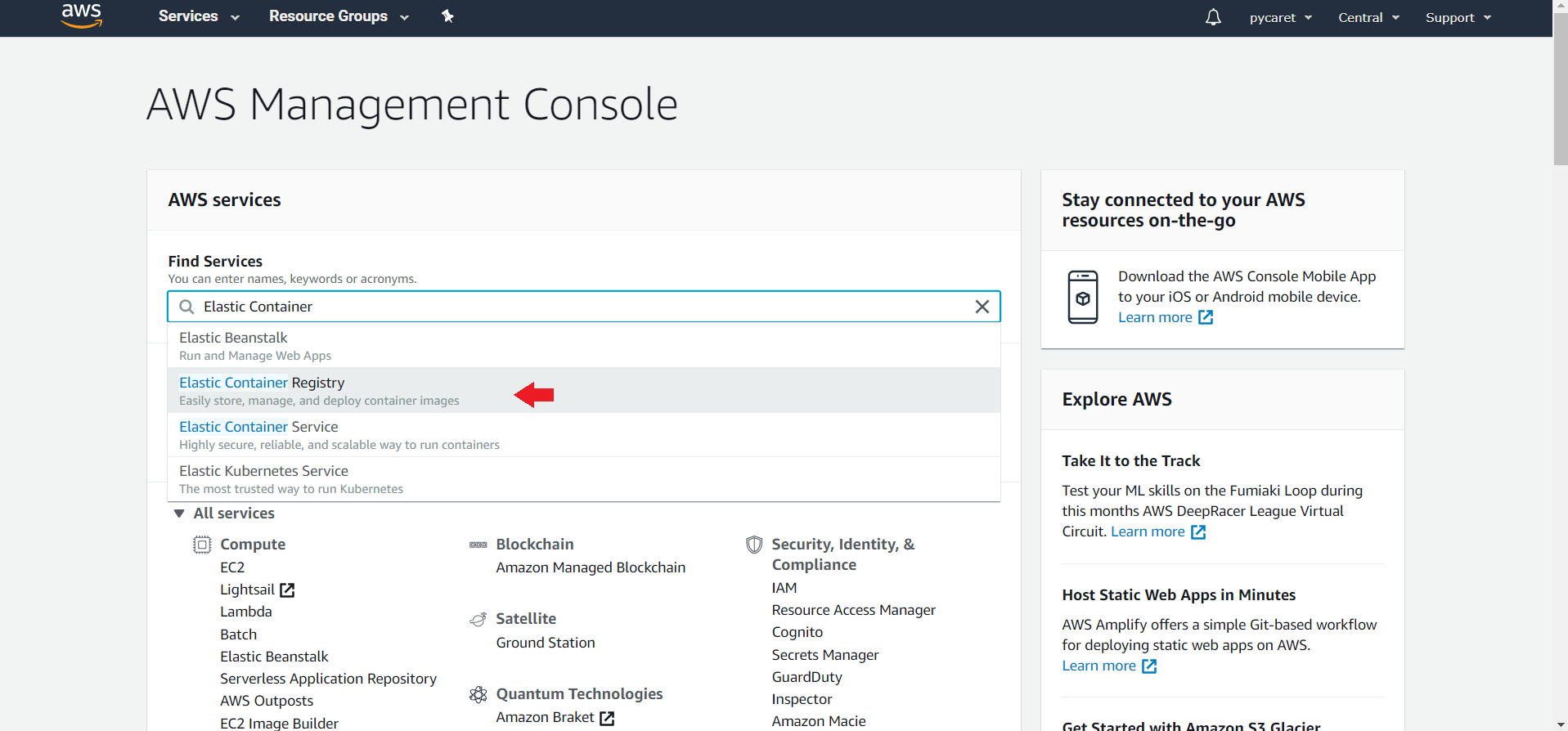
👉 步骤 3— 在 Elastic Container Registry (ECR) 中创建仓库
(a) 登录到您的 AWS 控制台并搜索 Elastic Container Registry:
(b) 创建一个新的仓库:
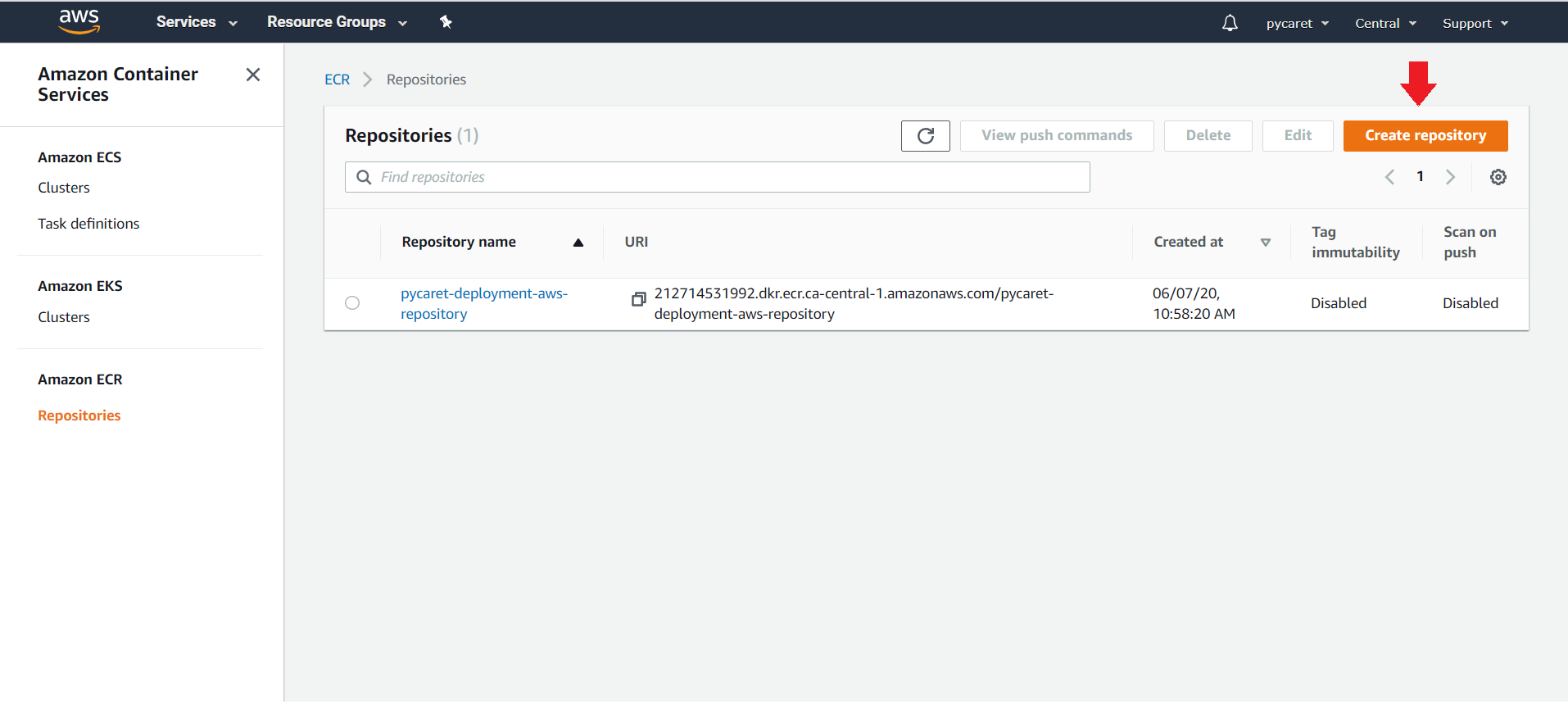
在这个演示中,我们创建了 'pycaret-deployment-aws-repository'。
(c) 点击“查看推送命令”:
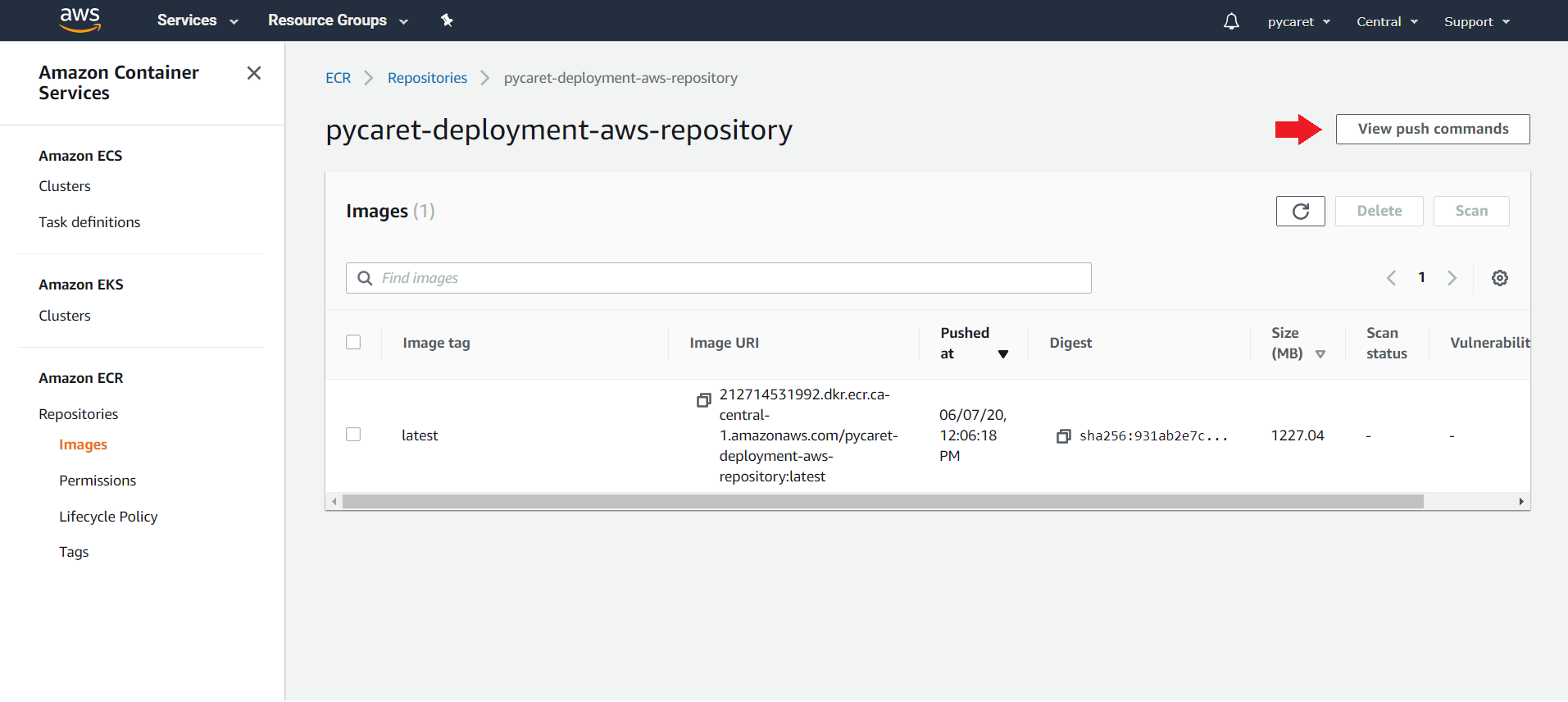
(d) 复制��推送命令:
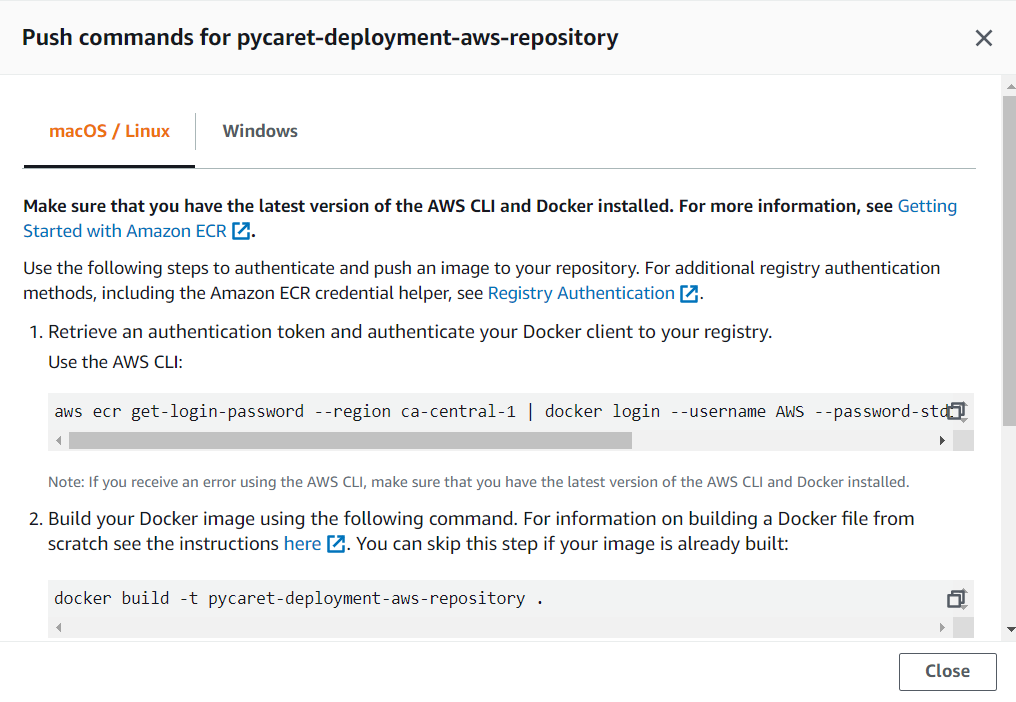
👉 步骤 4— 执行推送命令
使用 Anaconda Prompt 导航到您的项目文件夹,并执行上一步中复制的命令。以下代码仅用于演示,可能无法直接运行。要获取正确的执行代码,您必须从仓库内的“查看推送命令”中获取代码副本。
在执行这些命令之前,您必须位于包含 Dockerfile 和其余代码的文件夹中。
命令 1
aws ecr get-login-password --region ca-central-1 | docker login --username AWS --password-stdin 212714531992.dkr.ecr.ca-central-1.amazonaws.com
命令 2
docker build -t pycaret-deployment-aws-repository .
命令 3
docker tag pycaret-deployment-aws-repository:latest 212714531992.dkr.ecr.ca-central-1.amazonaws.com/pycaret-deployment-aws-repository:latest
命令 4
docker push 212714531992.dkr.ecr.ca-central-1.amazonaws.com/pycaret-deployment-aws-repository:latest
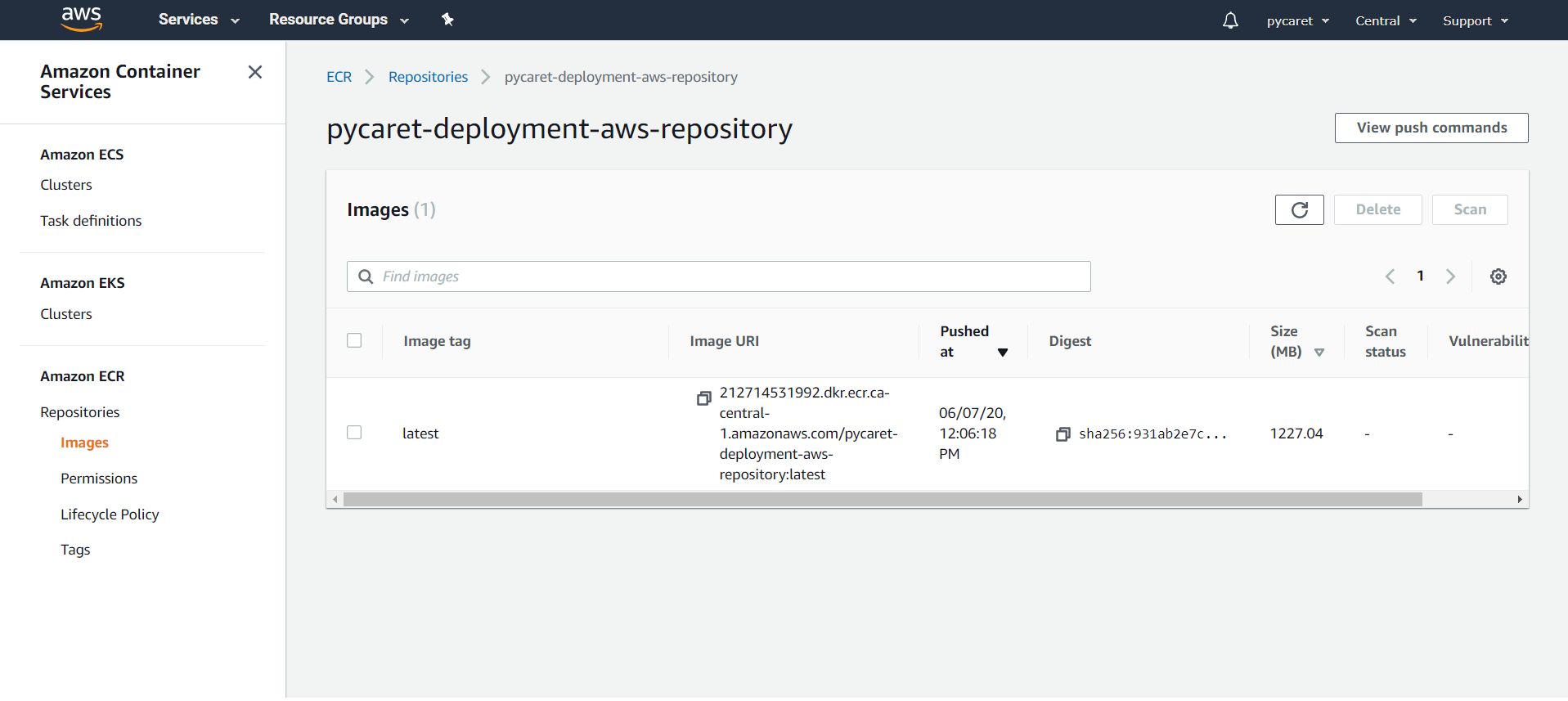
👉 步骤 5— 检查已上传的镜像
点击您创建的仓库,您将看到上一步中上传的镜像的镜像 URI。复制镜像 URI(在下面的步骤 7 中会用到)。
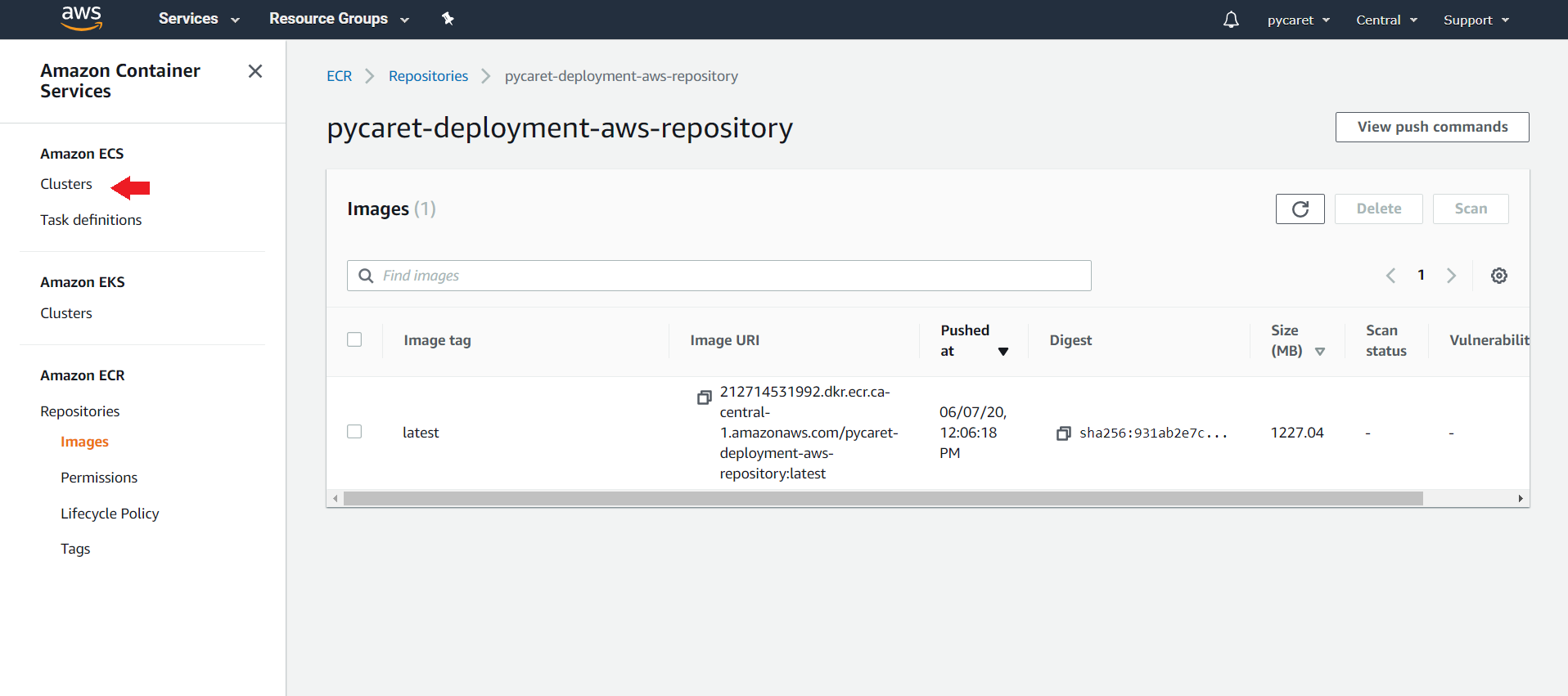
👉 步骤 6 — 创建和配置集群
(a) 点击左侧菜单中的“Clusters”:
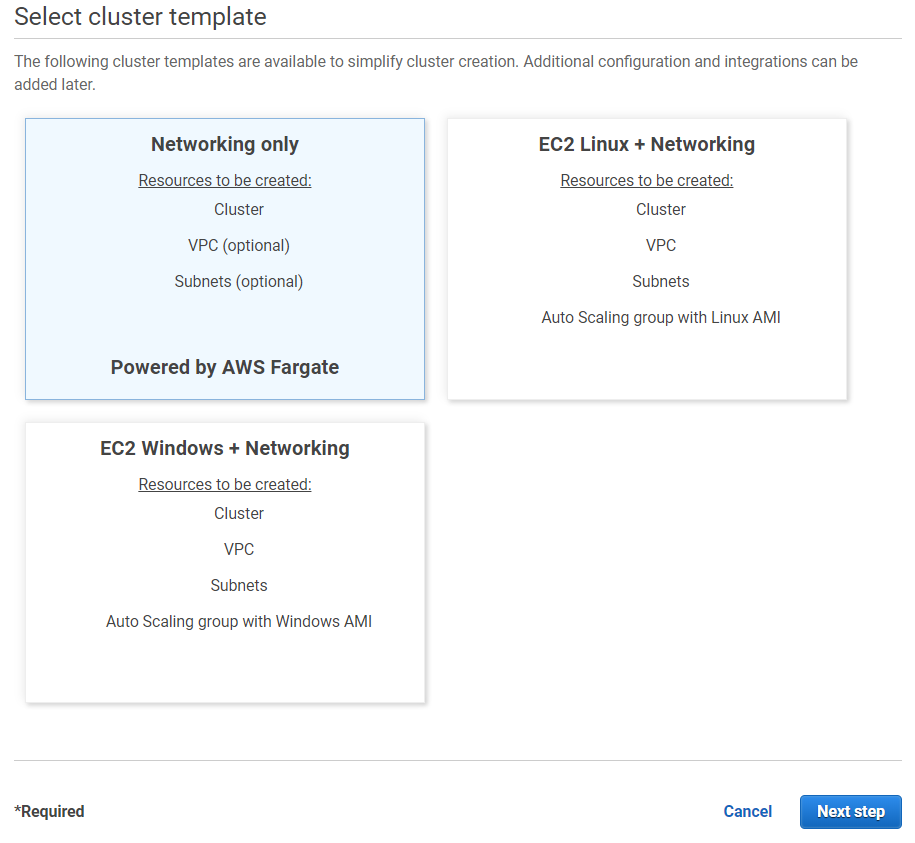
(b) 选择“仅网络”并点击“下一步”:
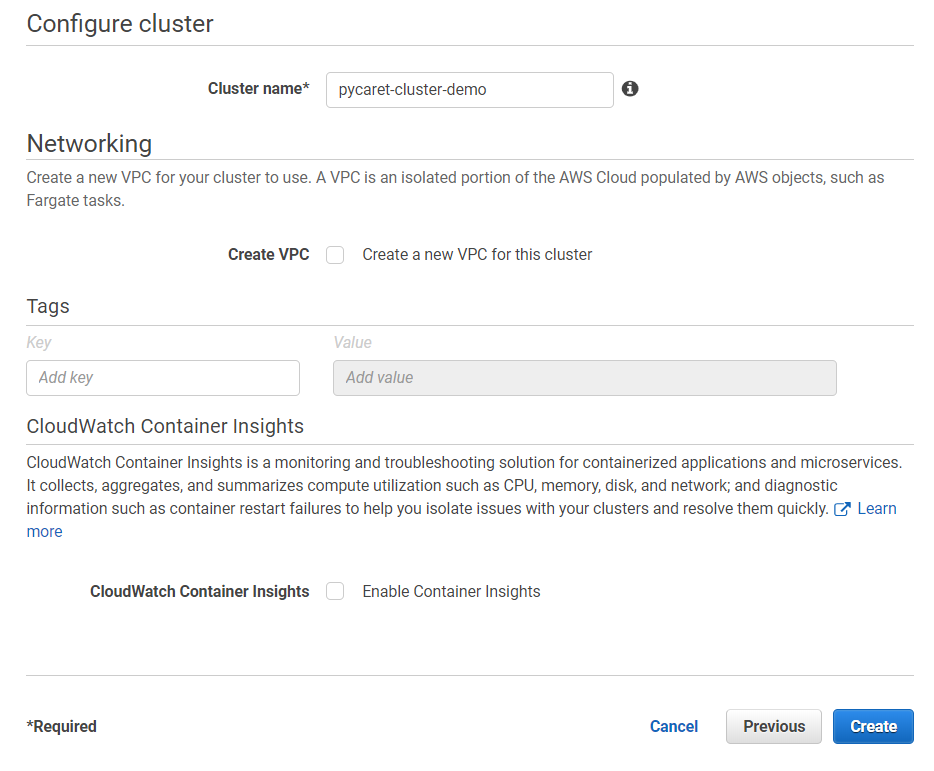
(c) 配置集群(输入集群名称)并点击“创建”:
(d) 集群已创建:

👉 步骤 7— 创建新的任务定义
在 Amazon ECS 中运行 Docker 容器需要一个任务定义。您可以在任务定义中指定的一些参数包括:每个容器在您的任务中使用的 Docker 镜像、每个任务或每个任务中的每个容器使用的 CPU 和内存等。
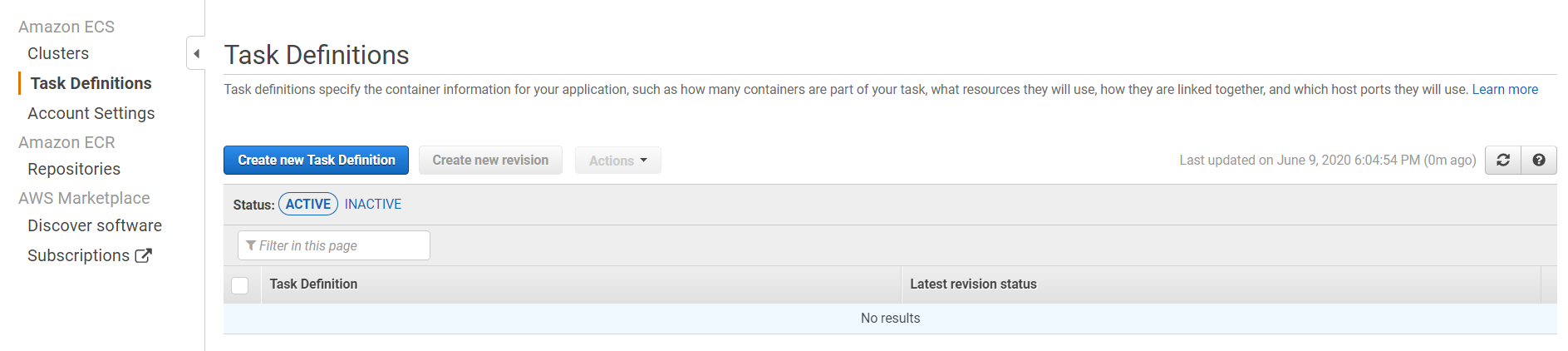
(a) 点击“创建新任务定义”:
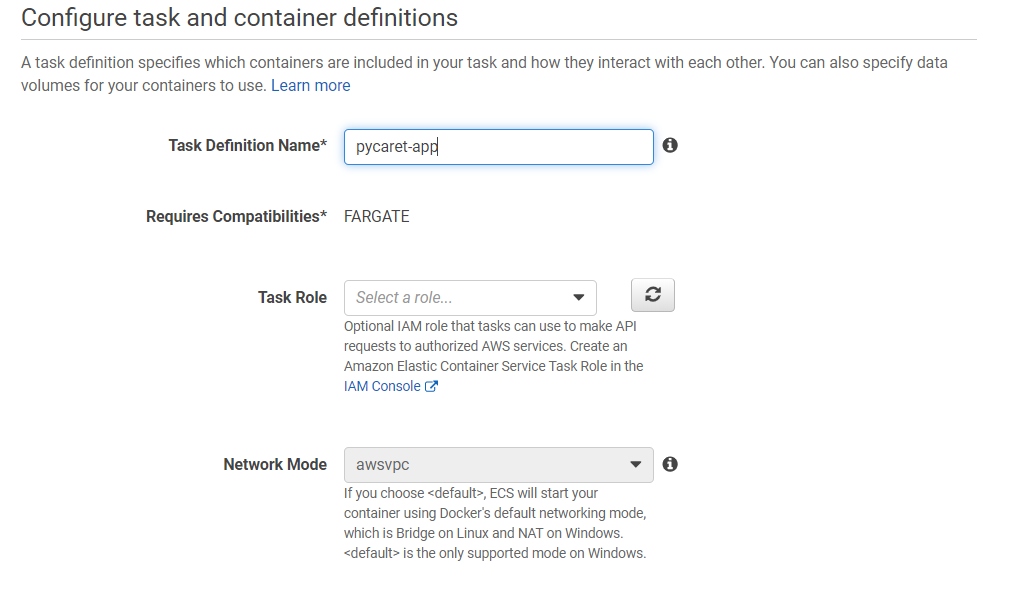
(b) 选择“FARGATE”作为启动类型:

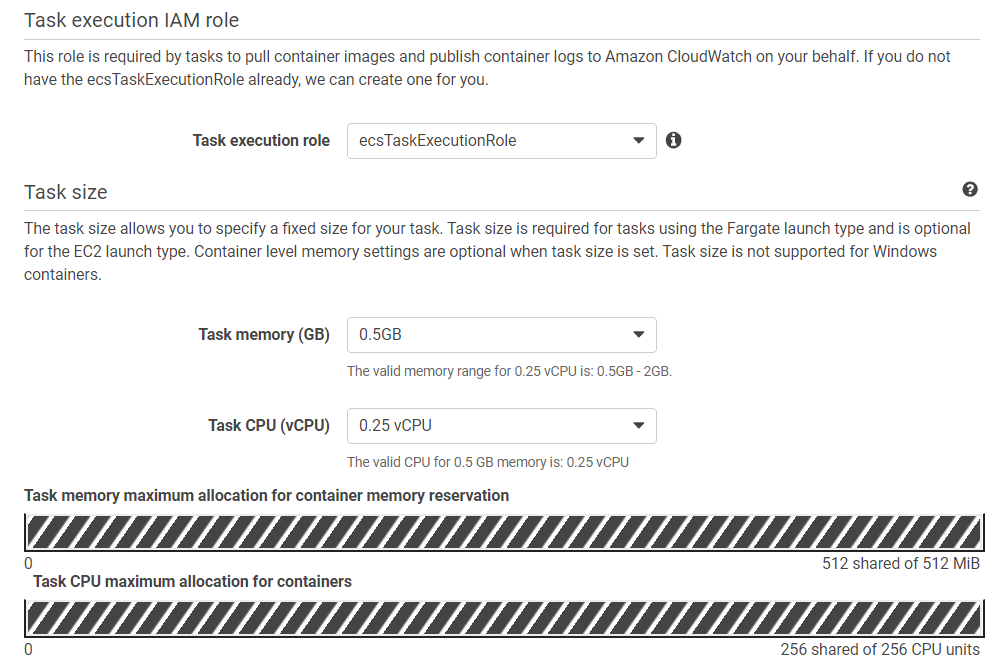
(c) 填写详细信息:
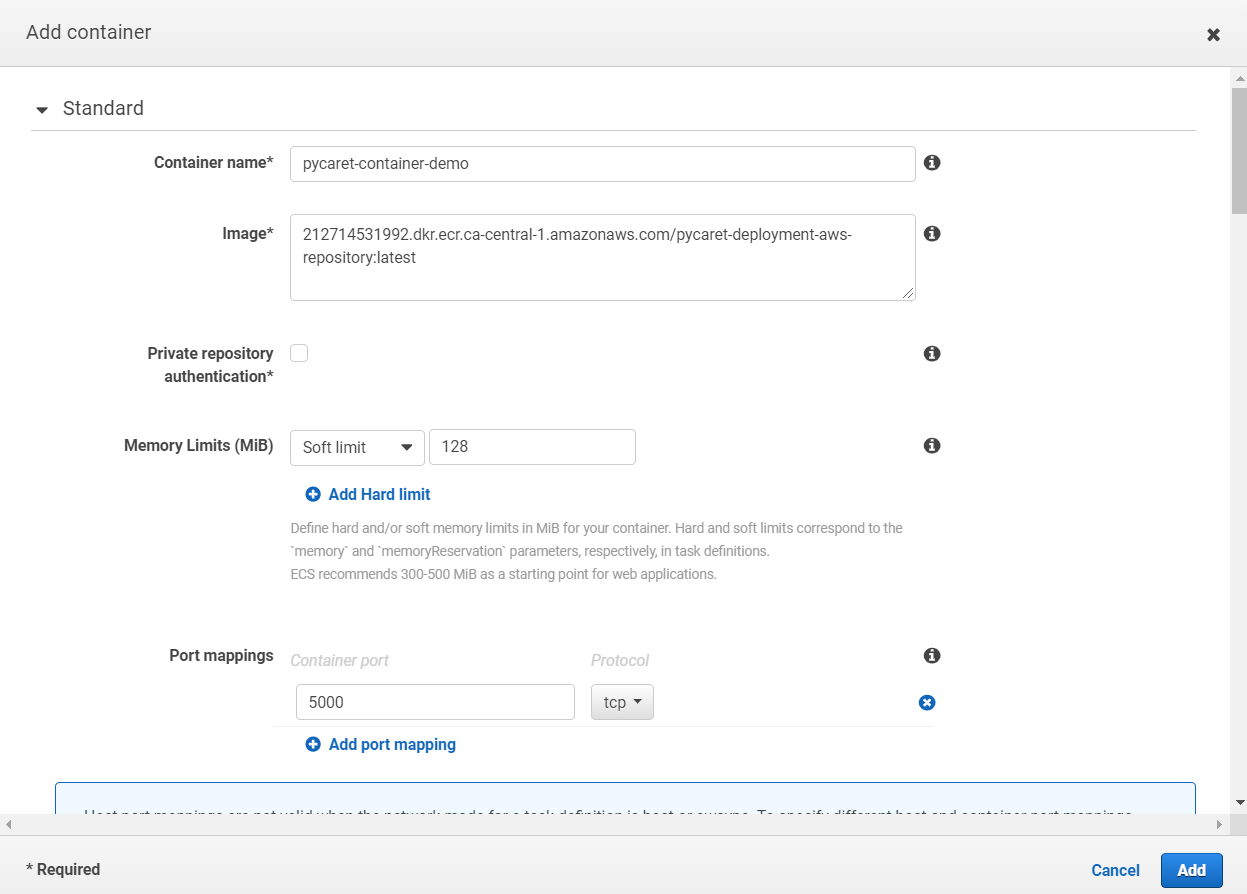
(d) 点击“添加容器”并填写详细信息:
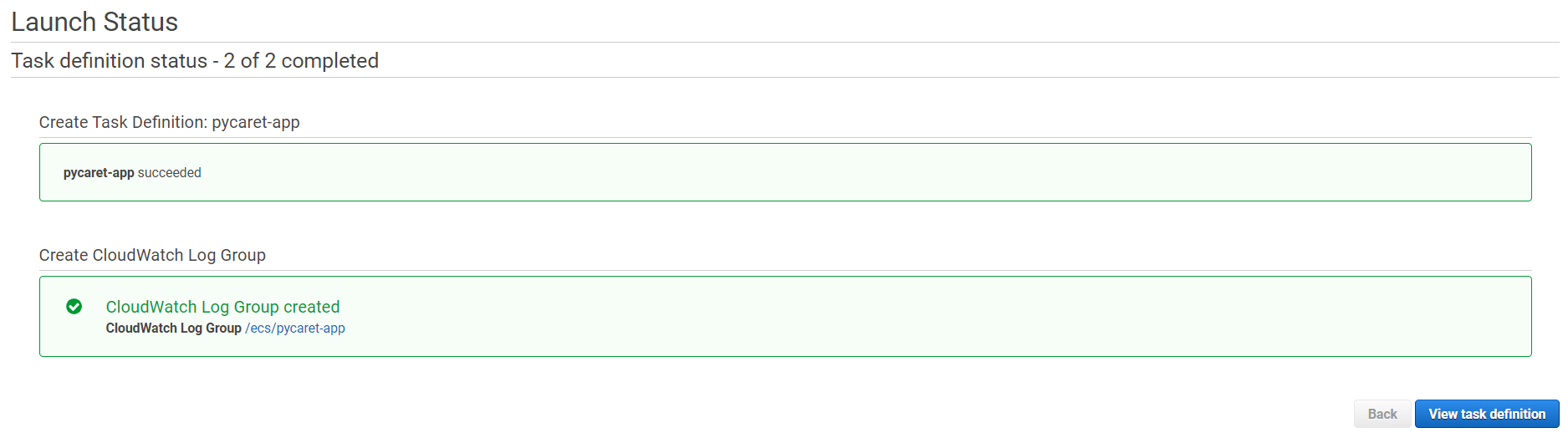
(e) 点击右下角的“创建任务”。
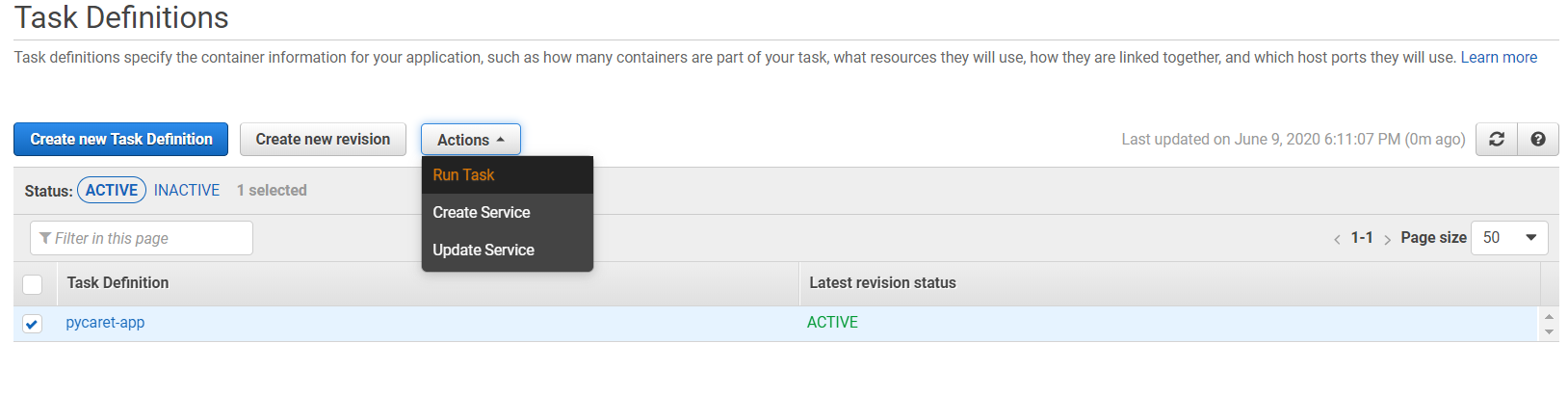
👉 步骤 8 — 执行任务定义
在步骤 7 中,我们创建了一个将启动容器的任务。现在,我们将通过在“操作”下点击“运行任务”来执行任务。
(a) 点击“切换到启动类型”以将类型更改为 Fargate:
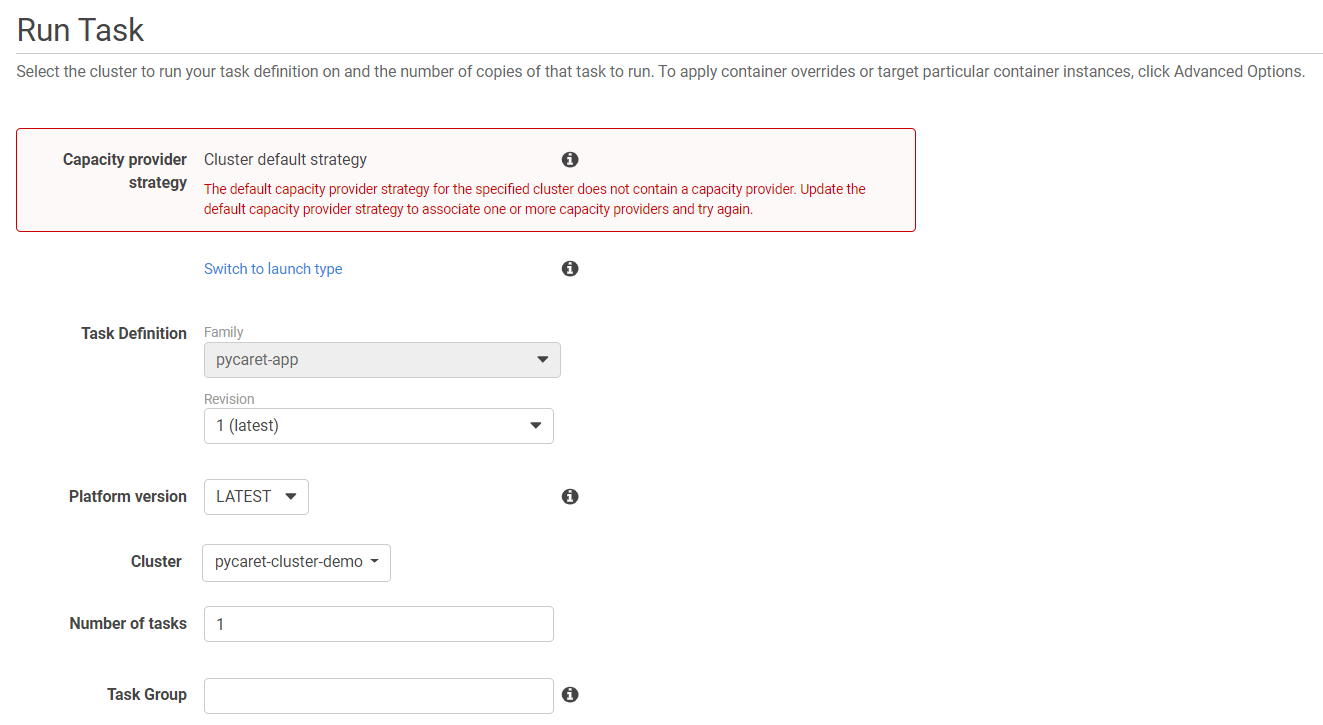
(b) 从下拉菜单中选择 VPC 和子网:
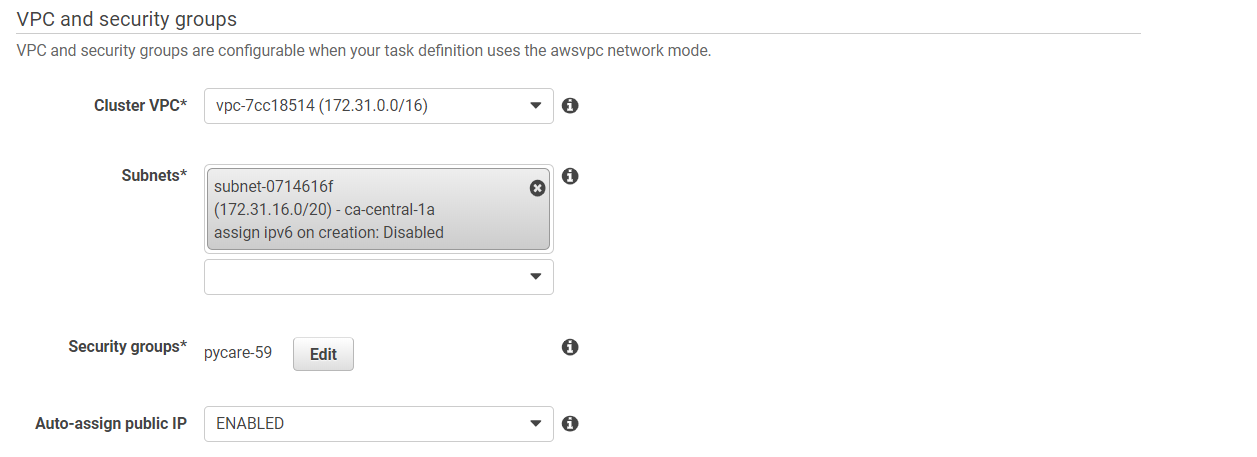 (c) 点击右下角的“运行任务”:
(c) 点击右下角的“运行任务”:
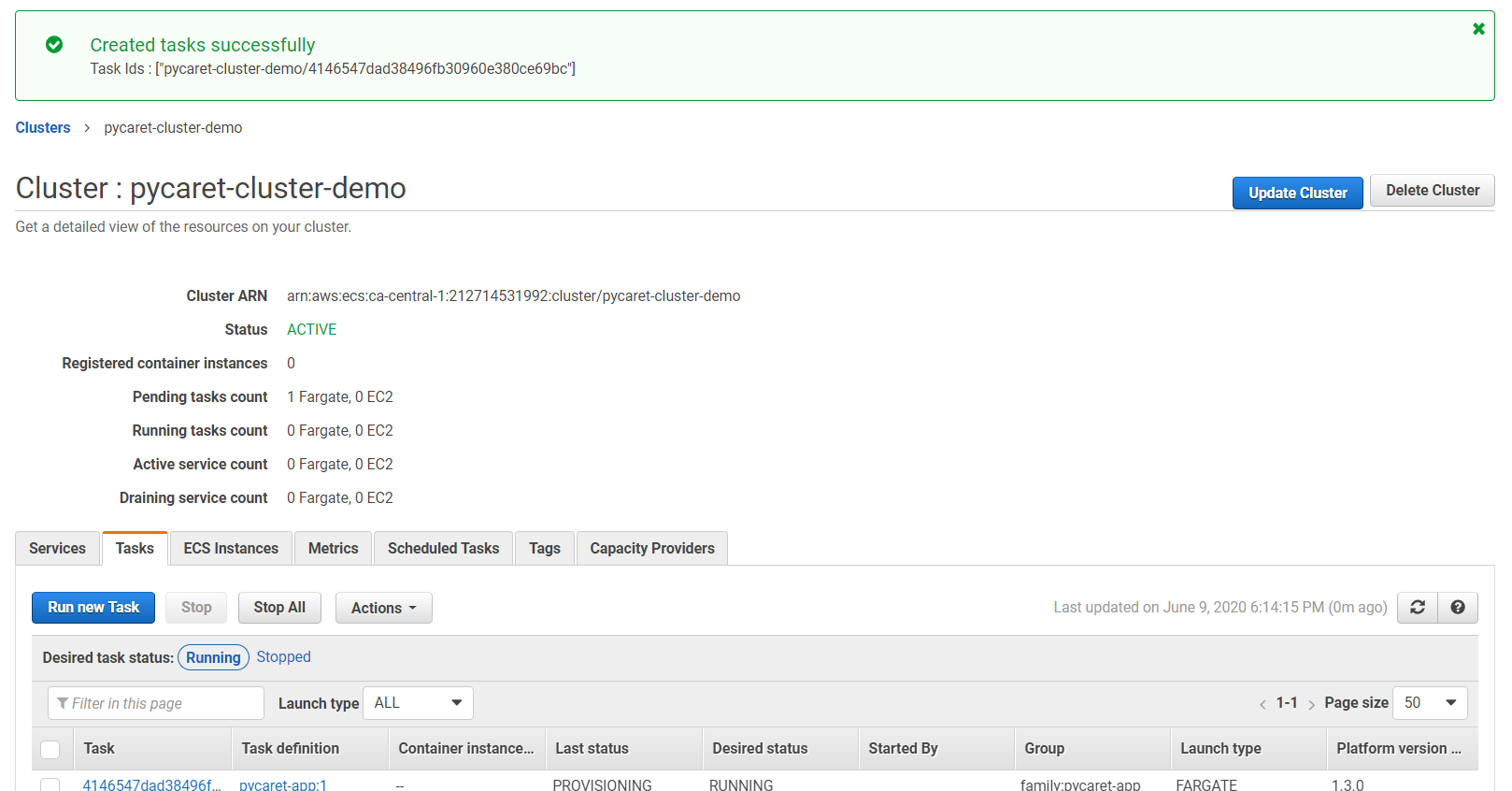
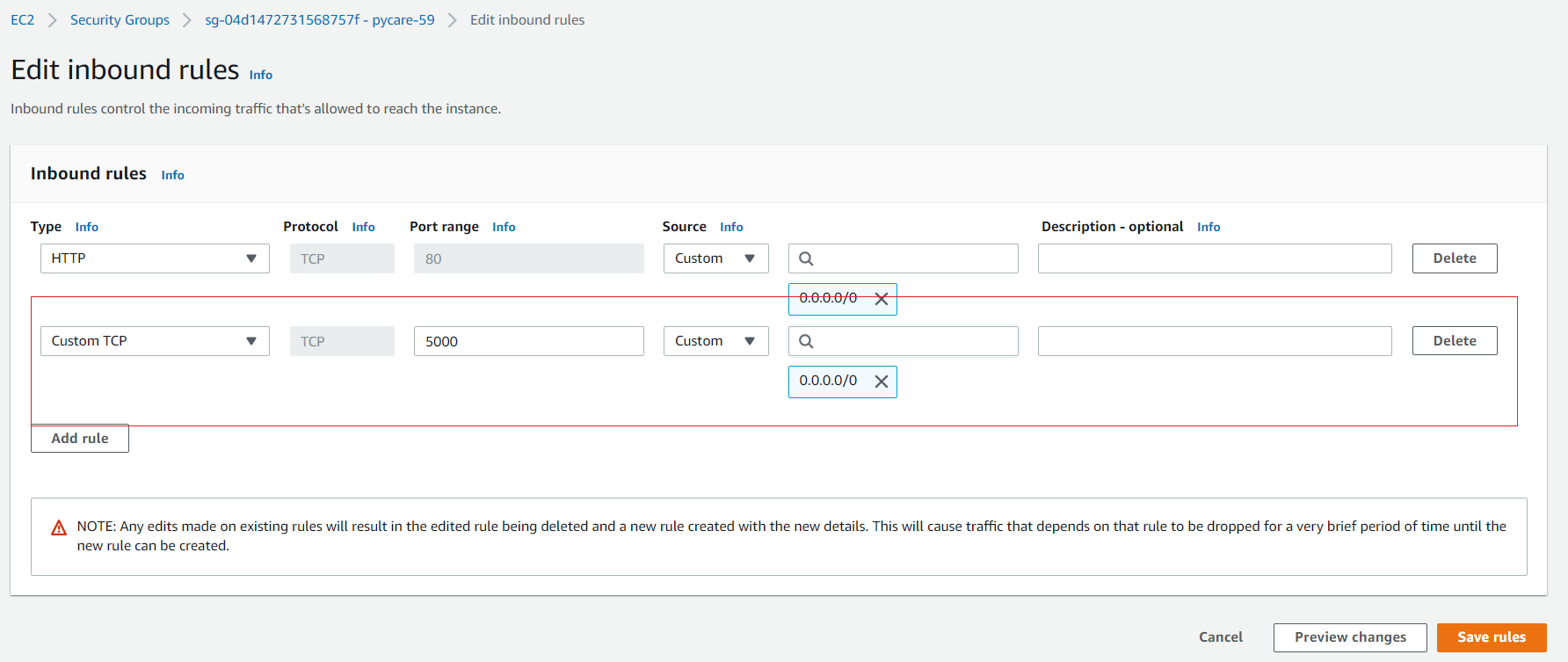
👉 第9步— 允许入站端口5000从网络设置
在我们可以在公共IP地址上看到我们的应用程序运行之前,还有最后一步,那就是允许端口5000通过创建一个新规则。为了做到这一点,请按照以下步骤操作:
(a) 点击任务
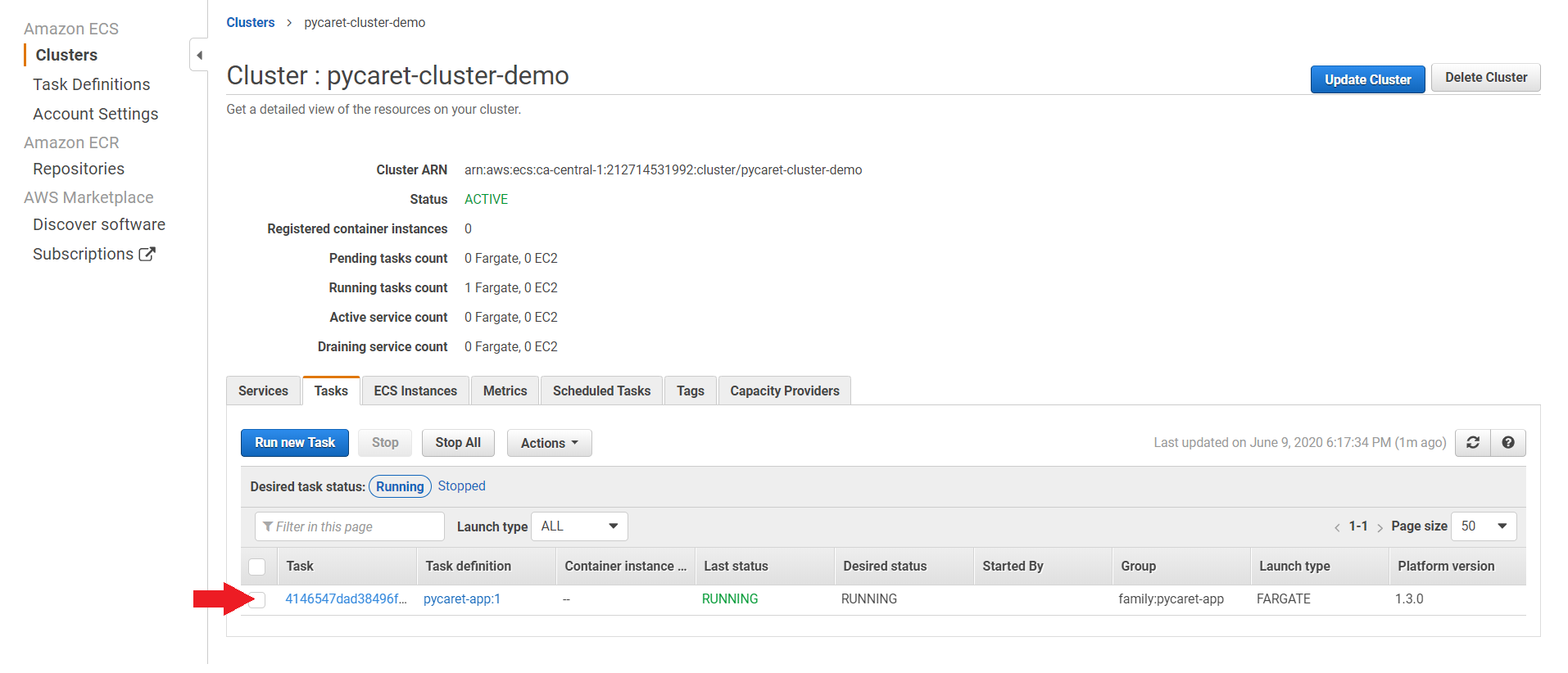
(b) 点击ENI Id:
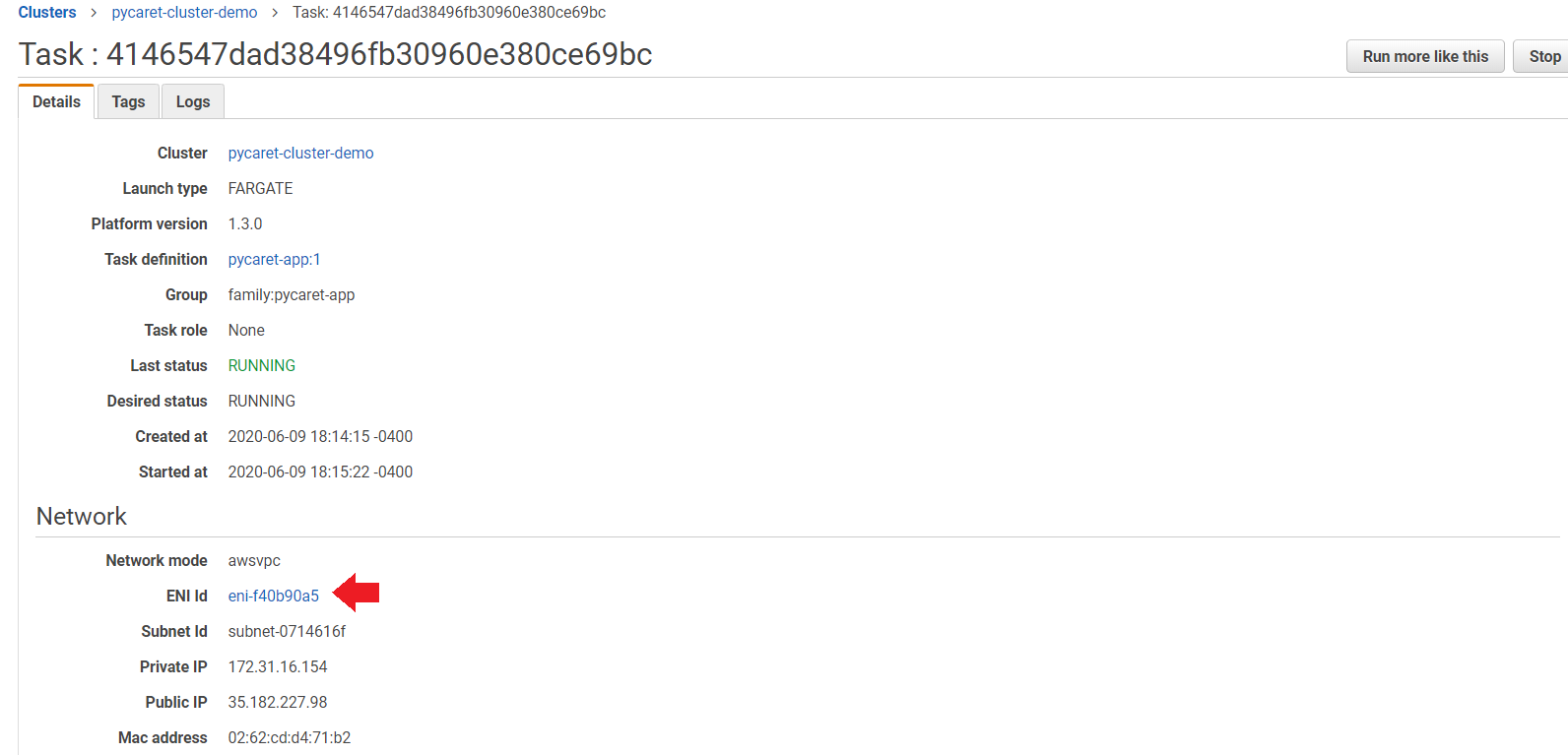
(c) 点击安全组
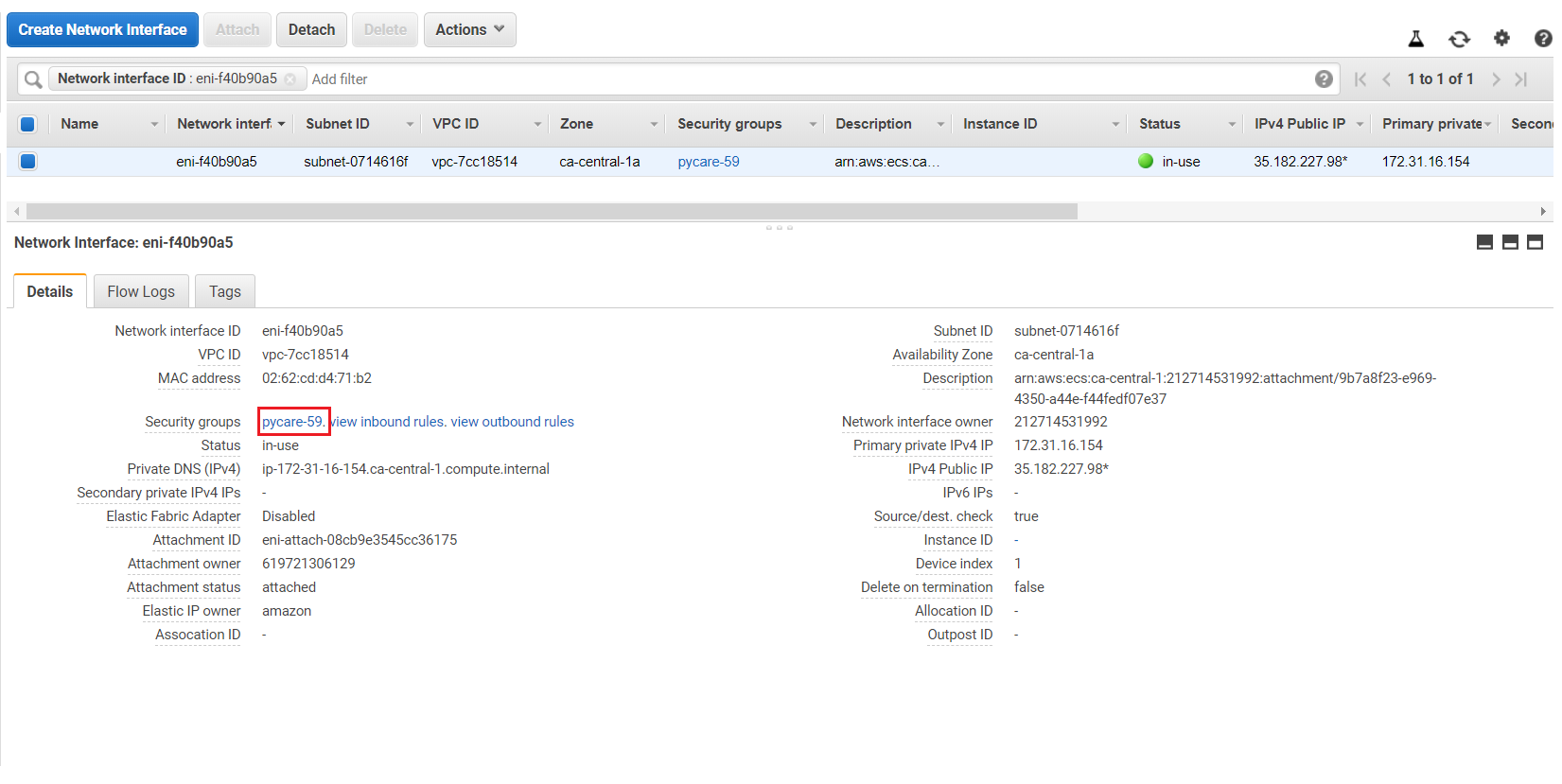
(d) 点击“编辑入站规则”
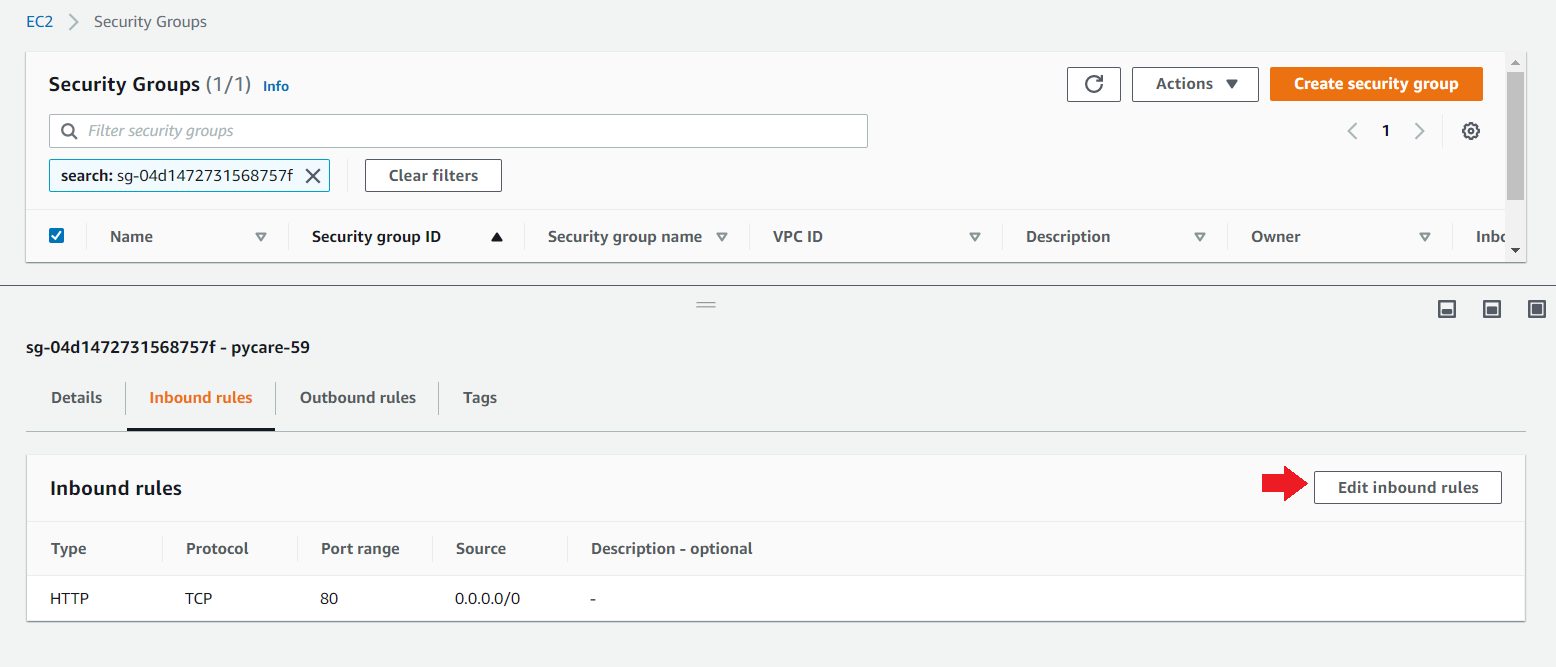
(e) 添加一个自定义TCP规则,端口为5000
👉 第10步 — 查看应用程序运行情况
使用带有端口5000的公共IP地址访问应用程序。
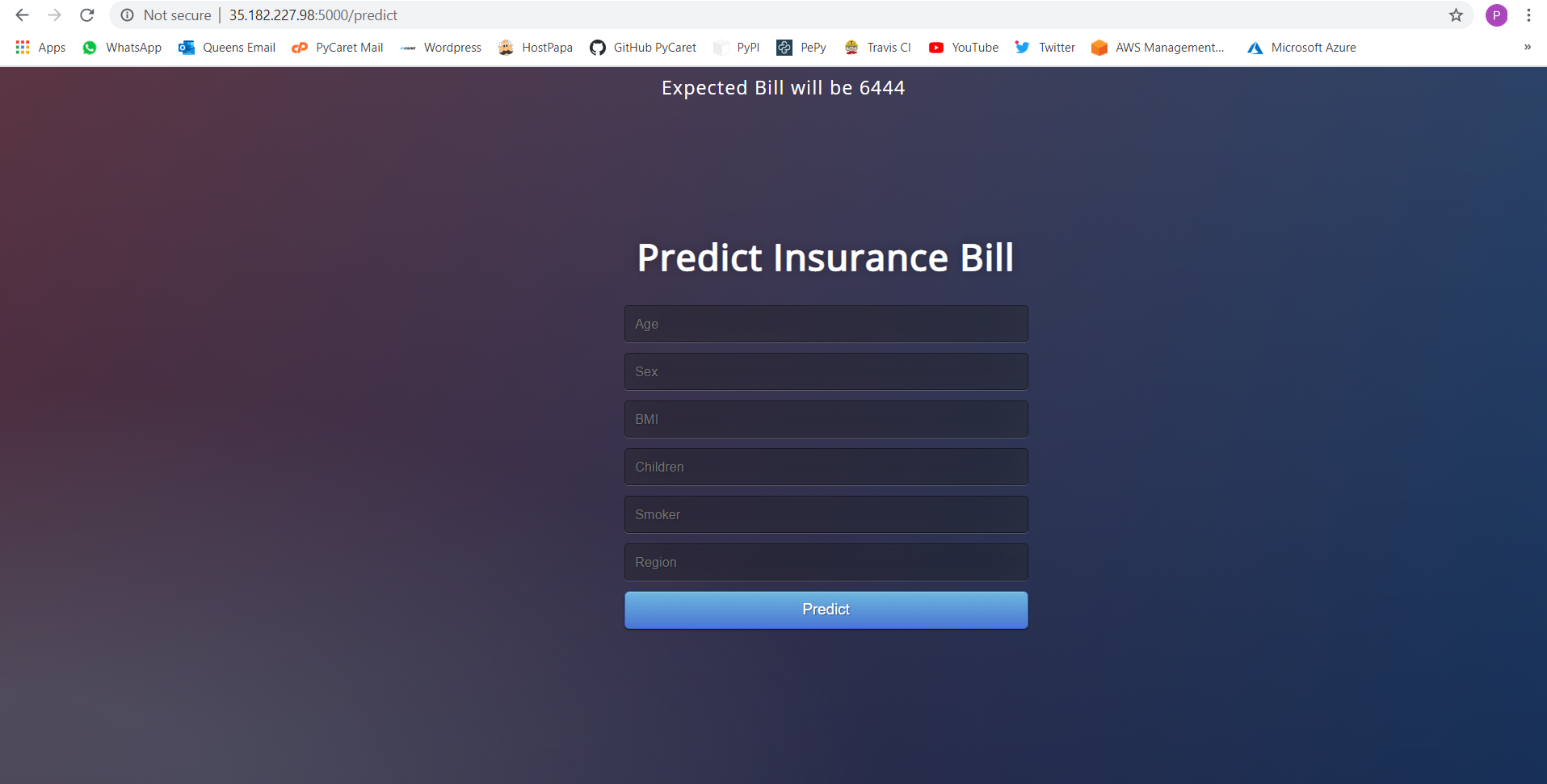
注意�: 在本故事发布时,应用程序将从公共地址中移除,以限制资源消耗。
PyCaret 2.0.0 即将发布!
我们收到了社区的大力支持和反馈。我们正在积极改进 PyCaret 并为下一个版本做准备。PyCaret 2.0.0 将更加强大和优秀。如果您想分享您的反馈并帮助我们进一步改进,您可以在网站上填写此表格,或在我们的GitHub或LinkedIn页面上留下评论。
关注我们的LinkedIn并订阅我们的YouTube频道,以了解更多关于 PyCaret 的信息。
想了解特定模块吗?
截至第一个版本 1.0.0,PyCaret 提供以下可用模块供使用。点击下面的链接查看 Python 中的文档和示例。
还可查看:
在 Notebook 中的 PyCaret 入门教程:
想要贡献吗?
PyCaret 是一个开源项目。欢迎每个人贡献。如果您想贡献,请随时处理开放问题。我们接受带有单元测试的拉取请求,�分支为 dev-1.0.1。
如果您喜欢 PyCaret,请在我们的GitHub 仓库上给我们 ⭐️。
Medium: https://medium.com/@moez_62905/
LinkedIn: https://www.linkedin.com/in/profile-moez/
Twitter: https://twitter.com/moezpycaretorg1